使用加強堆結構解決topK問題
作者:Grey
原文地址: 使用加強堆結構解決topK問題
題目描述
LintCode 550 · Top K Frequent Words II
思路
由於要統計每個字符串的次數,以及字典序,所以,我們需要把用戶每次add的字符串封裝成一個對象,這個對象中包括了這個字符串和這個字符串出現的次數。
假設我們封裝的對象如下:
public class Word {
public String value; // 對應的字符串
public int times; // 對應的字符串出現的次數
public Word(String v, int t) {
value = v;
times = t;
}
}
topk的要求是: 出現次數多的排前面,如果次數一樣,字典序小的排前面
很容易想到用有序表+比較器來做。
比較器的規則定義成和topk的要求一樣,然後把元素元素加入使用比較器的有序表中,如果要返回topk,直接從這個有序表彈出返回給用戶即可。比較器的定義如下:
public class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次數大的排前面,次數一樣字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
有序表配置這個比較器即可
TreeSet<Word> topK = new TreeSet<>(new TopKComparator());
所以topk()方法很簡單,只需要從有序表裏面把元素拿出來返回給用戶即可
public List<String> topk() {
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
時間複雜度 O(K)
以上步驟不複雜,接下來是add的邏輯,add的每次操作都有可能對前面我們設置的topK有序表造成影響,
所以在每次add操作的時候需要有一個機制可以告訴topK這個有序表,需要淘汰什麼元素,需要新加哪個元素,讓topK這個有序表時時刻刻只存topk個元素,
這樣就可以確保topK()方法比較單純,時間複雜度保持在O(K)
所以接下來的問題是:如何告訴topK這個有序表,需要淘汰什麼元素,需要新加哪個元素?
我們可以通過堆來維持一個門檻,堆頂元素表示最先要淘汰的元素,所以堆中的比較策略定為:
次數從小到大,字典序從大到小,這樣,堆頂元素永遠是:次數相對更少或者字典序相對更大的那個元素。所以如果某個時刻要淘汰一個元素,從堆頂拿出來,然後再到topK這個有序表中查詢是否有這個元素,有的話就從topK這個有序表中刪除這個元素即可。
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 設置堆門檻,堆頂元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o2.value) : (o1.times - o2.times);
}
}
如果使用Java自帶的PriorityQueue做這個堆,無法實現動態調整堆的功能,因為我們需要把次數增加的字符串(Word)在堆上動態調整,自帶的PriorityQueue無法實現這個功能,PriorityQueue只能支持每次新增或者刪除一個節點的時候,動態調整堆(
O(logN),但是如果堆中的節點變化了,PriorityQueue無法自動調整成堆結構,所以我們需要實現一個增強堆,用於節點變化的時候可以動態調整堆結構(保持O(logN)複雜度)。
加強堆的核心是增加了一個哈希表,
private Map<Word, Integer> indexMap;
用於存放每個節點所在堆上的位置,在節點變化的時候,可以通過哈希表查出這個節點所在的位置,然後從所在位置進行heapify/heapInsert操作,且這兩個操作只會走一個,
這樣就動態調整好了這個堆結構,以下resign方法就是完成這個工作
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
除了這個resign方法,自定義堆中的其他方法和常規的堆沒有區別,在每次進行heapify和heapInsert操作的時候,如果涉及到交換兩個元素,需要將indexMap中的兩個元素的位置也互換
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
由於自定義堆和有序表topk只存top k個數據,所以TopK結構中還需要一個哈希表來記錄所有的字符串出現與否:
private Map<String, Word> map;
自此,TopK結構中的add方法需要的前置條件已經具備,整個add方法的流程如下:
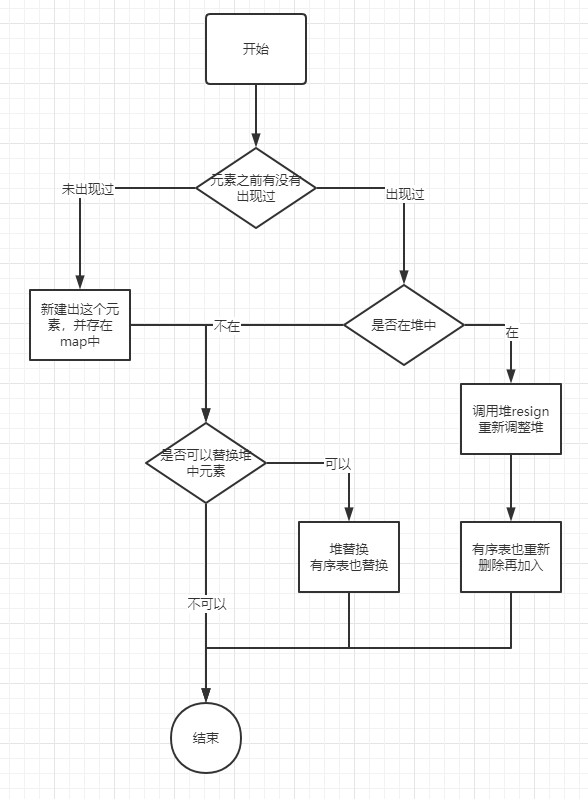
關於複雜度,add方法,時間複雜度O(log K), topk方法,時間複雜度O(K)。
完整代碼
class TopK {
private TreeSet<Word> topK;
private Heap heap;
private Map<String, Word> map;
private int k;
public TopK(int k) {
this.k = k;
topK = new TreeSet<>(new TopKComparator());
heap = new Heap(k, new ThresholdComparator());
map = new HashMap<>();
}
public void add(String str) {
if (k == 0) {
return;
}
Word word = map.get(str);
if (word == null) {
// 新增元素
word = new Word(str, 1);
// 是否到達門檻可以替換堆中元素
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
} else {
if (heap.contains(word)) {
topK.remove(word);
word.times++;
topK.add(word);
heap.resign(word);
} else {
word.times++;
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
}
}
map.put(str, word);
}
public List<String> topk() {
if (k == 0) {
return new ArrayList<>();
}
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
private class Word {
public String value;
public int times;
public Word(String v, int t) {
value = v;
times = t;
}
}
private class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次數大的排前面,次數一樣字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 設置堆門檻,堆頂元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o1.value) : (o1.times - o2.times);
}
}
private class Heap {
private Word[] words;
private Comparator<Word> comparator;
private Map<Word, Integer> indexMap;
public Heap(int k, Comparator<Word> comparator) {
words = new Word[k];
indexMap = new HashMap<>();
this.comparator = comparator;
}
public boolean isEmpty() {
return indexMap.isEmpty();
}
public boolean isFull() {
return indexMap.size() == words.length;
}
public boolean isReachThreshold(Word word) {
if (isEmpty() || indexMap.size() < words.length) {
return true;
} else {
if (comparator.compare(words[0], word) < 0) {
return true;
}
return false;
}
}
public void add(Word word) {
int size = indexMap.size();
words[size] = word;
indexMap.put(word, size);
heapInsert(size);
}
private void heapify(int i) {
int size = indexMap.size();
int leftChildIndex = 2 * i + 1;
while (leftChildIndex < size) {
Word weakest = leftChildIndex + 1 < size
? (comparator.compare(words[leftChildIndex], words[leftChildIndex + 1]) < 0
? words[leftChildIndex]
: words[leftChildIndex + 1])
: words[leftChildIndex];
if (comparator.compare(words[i], weakest) < 0) {
break;
}
int weakestIndex = weakest == words[leftChildIndex] ? leftChildIndex : leftChildIndex + 1;
swap(weakestIndex, i);
i = weakestIndex;
leftChildIndex = 2 * i + 1;
}
}
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
private void heapInsert(int i) {
while (comparator.compare(words[i], words[(i - 1) / 2]) < 0) {
swap(i, (i - 1) / 2);
i = (i - 1) / 2;
}
}
public boolean contains(Word word) {
return indexMap.containsKey(word);
}
public Word poll() {
Word result = words[0];
swap(0, indexMap.size() - 1);
indexMap.remove(result);
heapify(0);
return result;
}
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
}
}


