淺談軟件性能提升相關的概念
淺談軟件性能提升相關的概念
原文鏈接為<Making your program run faster: the key concepts of software performance – Johny’s Software Lab>
所有的工程師在其職業生涯的某個階段都不得不處理軟件性能問題——讓程序運行得更快。在大學時代,我們認為程序的性能主要是算法性能。但在實際上還有很多其他方面的內容讓你的程序或你的系統運行得更快。下面我將介紹一下軟件性能工程的一些概念。
提高軟件性能的時機
我們需要思考的第一個問題是何時需要我們去考慮提高軟件性能?當寫下第一行代碼時?或者當產品已經上線了,但有性能問題時才考慮?
回答這個問題之前,我們需要考慮以下幾件事情。第一件事情就是你要開發什麼樣的軟件,程序要處理的數據量是多少。如果寫的是一個 Word 轉 PDF 的工具,即使最大的文件有幾千頁,而大部分文件只有幾百頁。那麼就沒必要太過關注性能問題。遵循良好的開發實踐是正確的做法,將你的精力集中在代碼的可讀性、可維護性和可移植性上。
但是,如果你的程序將處理大量的數據集,或者有延遲要求,程序必須在一定的時間範圍內做出反應,或者程序可能會在非常慢的計算機上運行,那麼從一開始就應該考慮性能問題。
例如,如果一款遊戲的幀率很低,就無法發售。這就是為什麼許多遊戲開發者使用一種不同的編程範式——面向數據的設計,以實現良好的性能。在這種模式下的編程與在面向對象模式下的編程是完全不同的,但是會給遊戲帶來倍數的性能。
當確實有性能提升方面的需求時,你需要提前考慮一些事情:使用應用程序通常架構來避免不必要的操作和具有較大延遲的操作,高質量的數據結構和算法,用來避免性能問題。在編寫技術規範和進行代碼審查時,你應該考慮到性能問題。並非每行代碼都很關鍵,但有些性能問題如果不事先考慮到,就會非常困難,甚至無法解決。
找到瓶頸
當出現性能問題時,開發人員通常使用 *profilers 工具來找到瓶頸在地方。profilers *的輸出是一份報告,它告訴你哪些函數或源代碼是你的程序花費時間最多的地方。性能提升應當從這些瓶頸着手:這是提高性能最有可能帶來速度改進的地方。
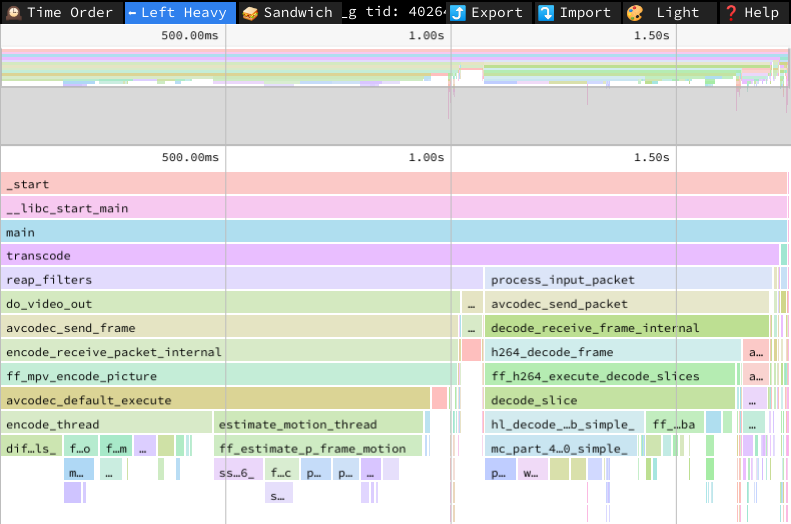
*profiler *會指出花了太多時間的代碼,但它所指示的內容不一定準確。在一個簡單的、單線程的應用程序中,花費時間最多的函數或循環是明顯的瓶頸。在多線程或多進程應用中,情況不一定如此。看起來是瓶頸的函數實際上可能是在等待其他操作的完成。因此,需要在其他地方尋找瓶頸。有專門的 *profiler *用於多線程和多處理器應用程序——Coz。
性能問題的種類
當發現瓶頸時,並不總是很清楚可以做什麼。導致一個功能緩慢的原因可能有很多:架構方面(例如,不必要地多次調用該函數)、性能差的算法 (例如,線性搜索而不是二分查找)、對操作系統資源的使用效率低下(例如,在一個循環中 lock 和 unlock 一個 mutex 會導致其他線程的飢餓)、 過度使用系統內存分配器(例如,內存碎片化)、對標準庫的低效率的使用(例如,沒有在哈希圖中預留足夠的空間,導致了代價高昂的 rehash)、沒有充分的使用編程語言的一些特性 (在C++中通過值而不是通過引用來移動大類)、 內存子系統的使用效率低下 (例如,太多的指針解除引用,也就是 chasing pointer)、 對CPU單元的使用效率不高 (例如,熱循環不使用CPU的矢量引擎)、編譯器參數選擇錯誤 (例如,禁用內聯)等等。
這裡提到的一些類型比其他類型更容易被發現。例如,不必要地調用一個函數太多次,會被團隊中的大多數工程師發現。但是,沒有最佳地使用內存子系統的問題,通常只有那些對軟件性能非常熟悉的人才能發現。
峰值性能
有時,熱循環是以最高性能運行的。它正在以最佳方式使用硬件,而且只做必要的操作。檢查熱循環是否以峰值性能運行是了解是否存在性能改進空間的另一種方法。
在科學計算中,他們使用 Roofline 模型來衡量一個算法對硬件資源的使用效率。這些信息具有一定的局限性:很多時候,最佳的硬件效率是不可能的,那麼問題來了,什麼是峰值?
在追求峰值性能的過程中,另一套有用的工具是基於硬件計數器的特殊*profiler *(最著名的是英特爾的 VTUNE 和 pmu-tools )。這些工具將幫助你了解一個循環有什麼樣的硬件瓶頸(計算、內存訪問、條件等),讓你在正確的地方發力。

但是請注意! 硬件效率並不代表一切:線性搜索使用硬件資源的效率比二分查找高得多,但二分查找更快,因為它做的工作更少!
應用性能與系統性能
性能工程的一個重要方面是對應用性能和系統性能進行區分。
當談及應用程序的性能時,我們指的是一個程序或一組程序單獨運行的性能(沒有其他程序在並行運行)。在這種情況下,我們通常使用 *profiler *觀察程序的性能,並通過修改程序的源代碼來解決出現的問題。 本網站上的文章大多涉及應用程序的性能。相反,當談論系統性能時,我們指的是整個系統的性能:所有不同的進程在特定硬件上一起運行。程序可能在無負載的系統中可能運行良好,但有時,當該進程與其他進程一起運行時,問題就會出現。在這種情況下,問題的出現主要是因為某項硬件資源被耗盡了。CPU、內存帶寬、硬盤帶寬或網絡帶寬。例如,如果計算機的物理內存用完了,進程將開始將內存交換到硬盤上。這可以看作是系統性能的急劇下降的原因。
系統性能作為一門學問,在服務器領域非常重要,因為許多不同的進程都在同一硬件上執行。用於調試系統性能的工具與用於調試應用程序性能的工具完全不同:各種可視化的工具,測量 CPU 使用率、CPU 執行中的異常情況、IO 子系統的使用率、內存使用率等。而修復方法也是不同的:改變系統的配置、刪除進程或給 CPU 增加冷卻器都有助於解決問題。
應用和系統性能問題之間的主要區別是應用性能問題持續地再現,而系統性能問題只在適當的情況下再現。一般來說,系統性能問題更難調試,但更容易修復。
延遲和吞吐量
當我們說 “某個東西很慢 “時,取決於上下文,我們可能有兩種意思。可以指我們的程序沒有及時響應其輸入,也可以指我們的程序處理數據的速度不令人滿意。不要理所應當的認為,這兩個句子聽起來可以互換,但在更深層次上,它們是不同的。讓我們用一個例子來說明:一個音頻處理系統必須在其到達輸入端後 20ms 內輸出處理過的音頻。在這裡,我們感興趣的是優化延遲:我們希望系統對輸入作出反應,要麼滿足約定的某個時間,要麼儘快作出反應。
第二個例子是一個訓練神經網絡的高性能系統。在這裡,響應時間並不關鍵。模型可能需要訓練幾個小時,甚至幾天。我們感興趣的是處理率:每單位時間處理的數據量應該是儘可能大的。希望任務能儘快完成,但在給定的時間內做出回應並不是我們的首要任務,我們要提高的是原始速度。
在這種情況下,我們正在優化吞吐量:我們正嘗試在每單位時間內處理儘可能多的數據。對延遲敏感的系統在實時系統(如汽車或航空系統)、高頻交易系統(系統必須儘快對來自市場的數據作出反應)或遊戲中很常見。吞吐量敏感的系統在其他地方也很常見:視頻渲染、神經網絡訓練等。
延遲敏感的系統建立在吞吐量敏感的系統之上。在實現最大吞吐量之後,整個系統,包括硬件、操作系統、網絡堆棧等,都會針對延遲進行優化。
在結束這個話題之前還有一件事:延遲和吞吐量在一定程度上是並存的,超過一定的階段它們開始分道揚鑣。你不可能同時擁有它們。如果你將系統配置為高延遲,你的一些工作將被打斷,這將降低系統的吞吐量。
現在的大多數操作系統都是為高吞吐量而配置的。對於那些想要創建優化的高延遲系統的人來說,需要對操作系統進行特殊配置。(如. Low Latency Performance Tuning for Red Hat Enterprise Linux 7, Configuring and tuning HPE ProLiant Servers for low-latency applications)。
如果你對延遲相關的性能話題感興趣,我強烈推薦Mark Dawson的博客。
最後提一下
性能提升並不是獨立的。在設計軟件系統時還有其他考慮因素:可維護性、可移植性、可讀性、可擴展性、可靠性、安全性、上線時間,等等。其中有些是與業務相關聯的,一些則不是。每個軟件項目都有自己的具體需求,而性能也只是一部分。有時它是一個非常重要的部分,有時則不是這樣。因此,每個軟件團隊都需要做出決策,需要在性能上花費多少時間。


