ElasticSearch7.3學習(十五)—-中文分詞器(IK Analyzer)及自定義詞庫
- 2022 年 3 月 28 日
- 筆記
- 【G】ElasticSearch
1、 中文分詞器
1.1 默認分詞器
先來看看ElasticSearch中默認的standard 分詞器,對英文比較友好,但是對於中文來說就是按照字符拆分,不是那麼友好。
GET /_analyze
{
"analyzer": "standard",
"text": "中華人民共和國"
}我們想要的效果是什麼:「中華人民共和國」作為一整個詞語。
得到的結果是:
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "華",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "國",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
1.2 安裝ik分詞器
安裝我就不詳細說了,教程很多。
1.3 ik分詞器基礎知識
ik_max_word: 會將文本做最細粒度的拆分,比如會將「中華人民共和國人民大會堂」拆分為「中華人民共和國,中華人民,中華,華人,人民共和國,人民大會堂,人民大會,大會堂」,會窮盡各種可能的組合;
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中華人民共和國人民大會堂"
}
{
"tokens" : [
{
"token" : "中華人民共和國",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中華人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中華",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "華人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和國",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和國",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "國人",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "人民大會堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "人民大會",
"start_offset" : 7,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "人民",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "大會堂",
"start_offset" : 9,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "大會",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 13
},
{
"token" : "會堂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 14
}
]
}
ik_smart: 會做最粗粒度的拆分,比如會將「中華人民共和國人民大會堂」拆分為「中華人民共和國,人民大會堂」。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中華人民共和國人民大會堂"
}{
"tokens" : [
{
"token" : "中華人民共和國",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "人民大會堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 1
}
]
}
1.4 ik分詞器的使用
存儲時,使用ik_max_word,搜索時,使用ik_smart,原因也很容易想到:存儲時,盡量存儲多的可能性,搜索時做粗粒度的拆分
例如,創建以下映射
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}2、ik配置文件
ik配置文件地址:插件的config目錄下
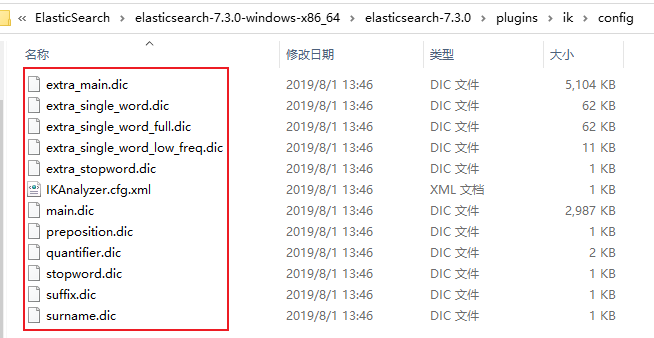
部分文件內容如下:
- IKAnalyzer.cfg.xml:用來配置自定義詞庫
- main.dic:ik原生內置的中文詞庫,總共有27萬多條,只要是這些單詞,都會被分在一起,都會按照這個裏面的詞語去分詞,ik原生最重要的兩個配置文件之一
- preposition.dic: 介詞
- quantifier.dic:放了一些單位相關的詞,量詞
- suffix.dic:放了一些後綴
- surname.dic:中國的姓氏
- stopword.dic:包含了英文的停用詞,a the and at but等。會在分詞的時候,直接被幹掉,不會建立在倒排索引中。ik原生最重要的兩個配置文件之一
3、自定義詞庫
3.1 自定義分詞詞庫
每年都會湧現一些特殊的流行詞,內卷,耗子尾汁,不講武德等,這些詞一般不會出現在ik的原生詞典里,分詞的時候也不會把這些詞彙當作整個詞彙來進行分詞。所以需要我們自己補充自己的最新的詞語,到ik的詞庫裏面。
就拿耗子尾汁來說,不做自定義分詞的效果如下。

在實際的搜索過程中,肯定不希望把它分詞,而是希望把它作為一個整體的詞彙。
(1)首先在IK插件的config目錄下,有一個IKAnalyzer.cfg.xml文件。
(2)使用Notepad++打開該文件
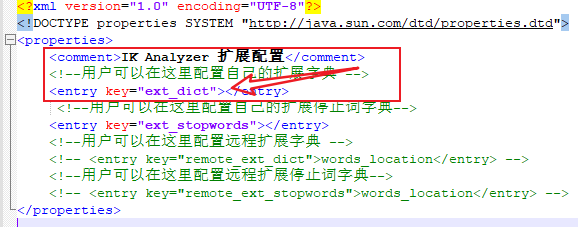
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "//java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴展配置</comment>
<!--用戶可以在這裡配置自己的擴展字典 -->
<entry key="ext_dict"></entry>
<!--用戶可以在這裡配置自己的擴展停止詞字典-->
<entry key="ext_stopwords"></entry>
<!--用戶可以在這裡配置遠程擴展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用戶可以在這裡配置遠程擴展停止詞字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
(3)可以看到上面的提示
(4)於是我們創建一個名為mydict.dic的文件,內容如下
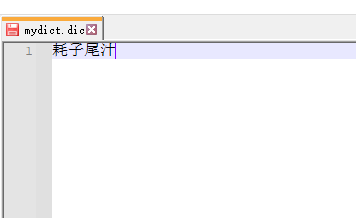
(5)注意如果多個詞語,就着下一行接著錄入,然後把這個文件放在與配置文件的相同目錄下。
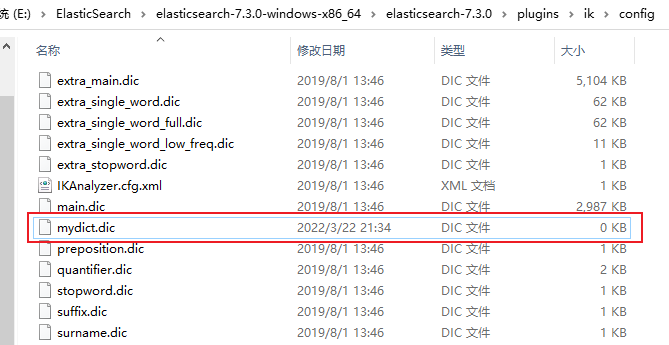
(6)然後再把文件名mydict.dic添加在IKAnalyzer.cfg.xml文件中,然後保存
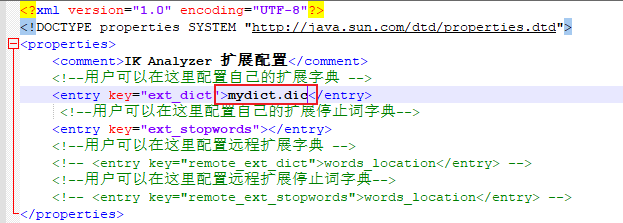
(7)然後重啟es,查看效果
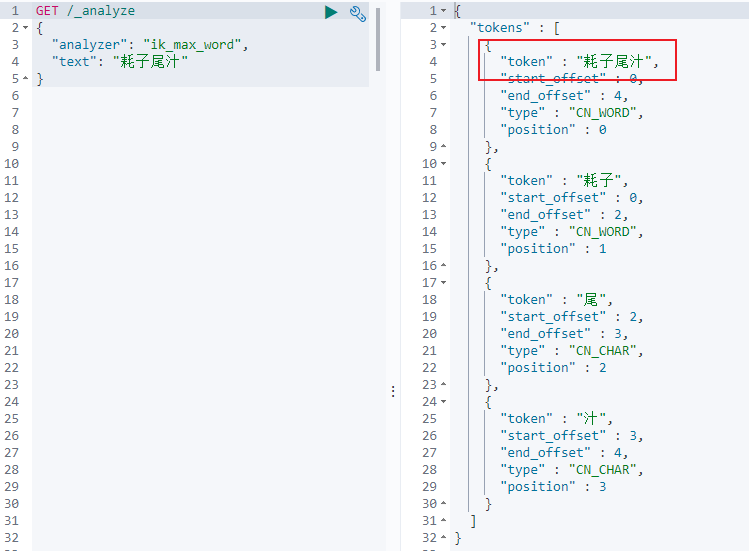
(9)可以看到,耗子尾汁這個詞已經能夠作為一個整體的詞語來做分詞了。
3.2 自定義停用詞庫
比如了,的,啥,么,我們可能並不想去建立索引,讓人家搜索。
做法與上面自定義詞庫類似,這裡只是簡單的說一下,比方說建立一個mystop.dic文件,把不想建立的索引的詞寫進文件,把文件與配置文件放在同一個目錄,然後在把文件名寫進配置文件對應的位置,如下所示
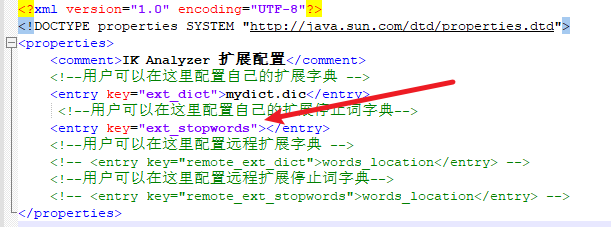
然後在重啟es,就可以查看效果了。
這樣做的一個好處就是,已經有了常用的中文停用詞,但是可以補充自己的停用詞。
4、熱更新詞庫
4.1 熱更新
每次都是在es的擴展詞典中,手動添加新詞語,很坑
(1)每次添加完,都要重啟es才能生效,非常麻煩
(2)es是分佈式的,可能有數百個節點,你不能每次都一個一個節點上面去修改
所以引出熱更新的解決方案。es不停機,直接我們在外部某個地方添加新的詞語,es中立即熱加載到這些新詞語
熱更新的方案
(1)基於ik分詞器原生支持的熱更新方案,部署一個web服務器,提供一個http接口,通過modified和tag兩個http響應頭,來提供詞語的熱更新,這種方式在官網也提到過。//github.com/medcl/elasticsearch-analysis-ik

修改了插件配置之後需要重啟,如果之後對遠程的詞庫.txt文件修改就不需要再重啟ES了,該插件支持熱更新分詞。
(2)修改ik分詞器源碼,然後手動支持從數據庫中每隔一定時間,自動加載新的詞庫
一般來說採用第二種方案,第一種,ik git社區官方都不建議採用,覺得不太穩定
4.2 步驟
1、下載源碼,//github.com/medcl/elasticsearch-analysis-ik/releases
ik分詞器,是個標準的java maven工程,直接導入idea就可以看到源碼
2、修改源
org.wltea.analyzer.dic.Dictionary類,160行Dictionary單例類的初始化方法,在這裡需要創建一個我們自定義的線程,並且啟動它
org.wltea.analyzer.dic.HotDictReloadThread類:就是死循環,不斷調用Dictionary.getSingleton().reLoadMainDict(),去重新加載詞典
Dictionary類,399行:this.loadMySQLExtDict(); 加載mysql字典。
Dictionary類,609行:this.loadMySQLStopwordDict();加載mysql停用詞
config下jdbc-reload.properties。mysql配置文件
3、mvn package打包代碼
target\releases\elasticsearch-analysis-ik-7.3.0.zip
4、解壓縮ik壓縮包
將mysql驅動jar,放入ik的目錄下
5、修改jdbc相關配置
6、重啟es
觀察日誌,日誌中就會顯示我們打印的那些東西,比如加載了什麼配置,加載了什麼詞語,什麼停用詞
7、在mysql中添加詞庫與停用詞
8、分詞實驗,驗證熱更新生效
這裡只是大概的一個步驟,具體情況按照自己的業務邏輯進行開發。


