Redis數據結構詳解(2)-redis中的字典dict
- 2022 年 3 月 28 日
- 筆記
前提知識🧀
字典,又被稱為符號表(symbol table)或映射(map),其實簡單地可以理解為鍵值對key-value。
比如Java的常見集合類HashMap,就是用來存儲鍵值對的。
字典中的鍵(key)都是唯一的,由於這個特性,我們可以根據鍵(key)查找到對應的值(value),又或者進行更新和刪除操作。

字典dict的實現
Redis的字典使用了哈希表作為底層實現,一個哈希表裏面可以有多個哈希表節點,每個節點也保存了對應的鍵值對。
Redis的字典dict結構如下:

typedef struct dict {
//類型特定函數
//是一個指向dictType結構的指針,可以使dict的key和value能夠存儲任何類型的數據
dictType *type;
//私有數據
//私有數據指針,不是討論的重點,暫忽略
void *privdata;
//哈希表
dictht ht[2];
//rehash 索引
//當 rehash 不在進行時,值為 -1
int rehashidx;
}
我們重點關注兩個屬性就可以:
- ht 屬性:
可以看到ht屬性是一個 size為2 的 dictht哈希表數組,在平常情況下,字典只用到 ht[0],ht[1] 只會在對 ht[0] 哈希表進行rehash時才會用到。
- rehashidx 屬性:
它記錄了rehash目前的進度,如果現在沒有進行rehash,那麼它的值為-1,可以理解為rehash狀態的標識。
下圖就是一個普通狀態下的字典:
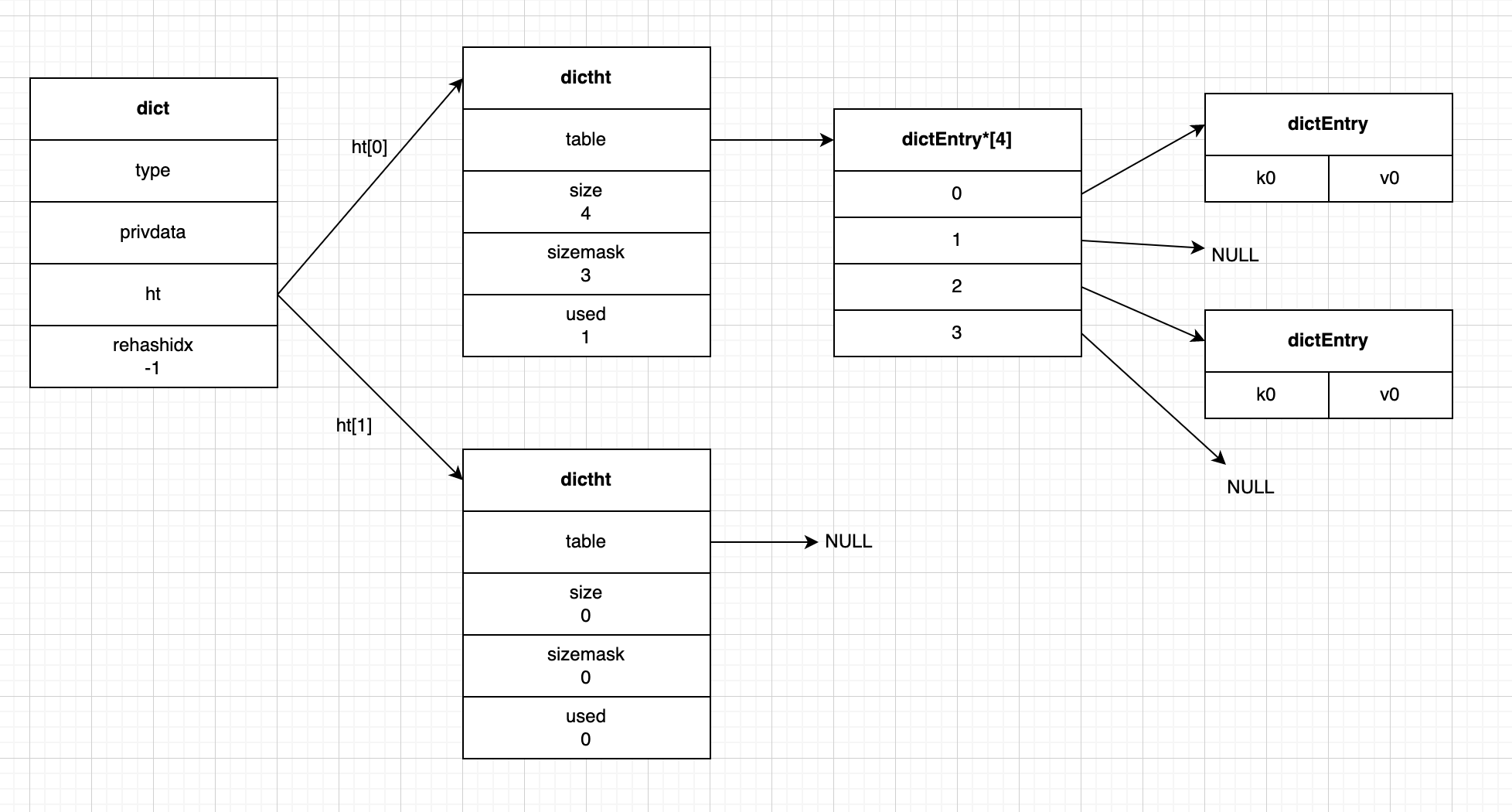
實際的數據在 ht[0] 中存儲;ht[1] 起輔助作用,只會在進行rehash時使用,具體作用包括rehash的內容我們會在後面進行詳細介紹。

哈希算法定位索引
PS:如果你有HashMap的相關知識,知道如何計算索引值,那麼你可以跳過這一部分。
假如我們現在模擬將 hash值從0到5的哈希表節點 放入 size為4的哈希表數組 中,也就是將包含鍵值對的哈希表節點放在哈希表數組的指定索引上。
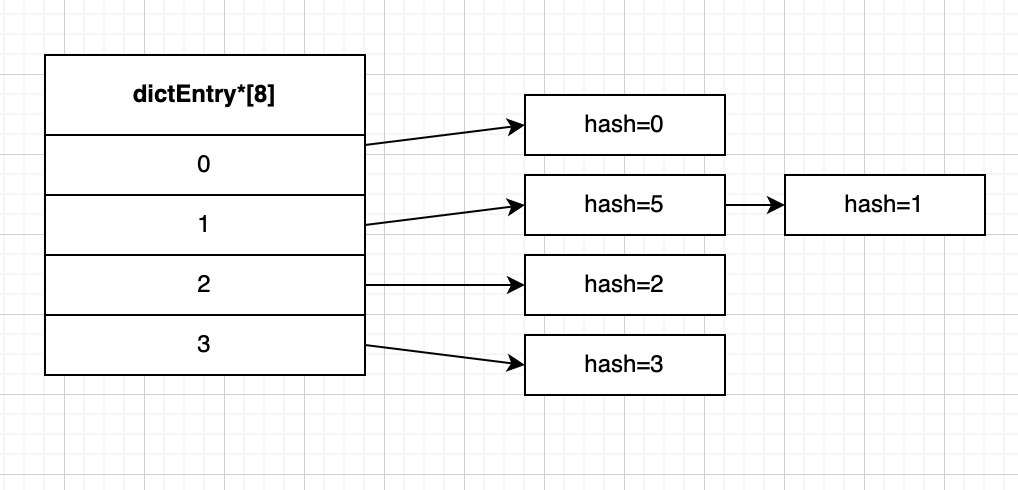
對應索引的計算公式:
index = hash & ht[x].sizemask
看不懂沒關係,可以簡單的理解為hash值對哈希表數組的size值求余;
比如上面 hash值為0的節點,0 % 4 = 0,所以放在索引0的位置上,
hash值為1的節點,1 % 4 = 1,所以放在索引1的位置上,
hash值為5的節點,5 % 4 = 1,也等於1,也會被分配在索引1的位置上,並且因為dictEntry節點組成的鏈表沒有指向鏈表表尾的指針,所以會將新節點添加在鏈表的表頭位置,排在已有節點的前面。
我們把上面索引相同從而形成鏈表的情況叫鍵衝突,而且因為形成了鏈表!那麼就意味着查找等操作的複雜度變高了!
例如你要查找hash=1的節點,你就只能先根據hash值找到索引為1的位置,然後找到hash=5的節點,再通過next指針才能找到最後的結果,也就意味着鍵衝突發生得越多,查找等操作花費的時間也就更多。

如果解決鍵衝突?rehash!
其實rehash操作很好理解,可以簡單地理解為哈希表數組擴容或收縮操作,即將原數組的內容重新hash放在新的數組裡。
比如還是上面的數據,我們這次把它們放在 size等於8的哈希表數組 里。
如下圖,此時size = 8,hash為5的鍵值對,重新計算索引:5 % 8 = 5,所以這次會放在索引5的位置上。
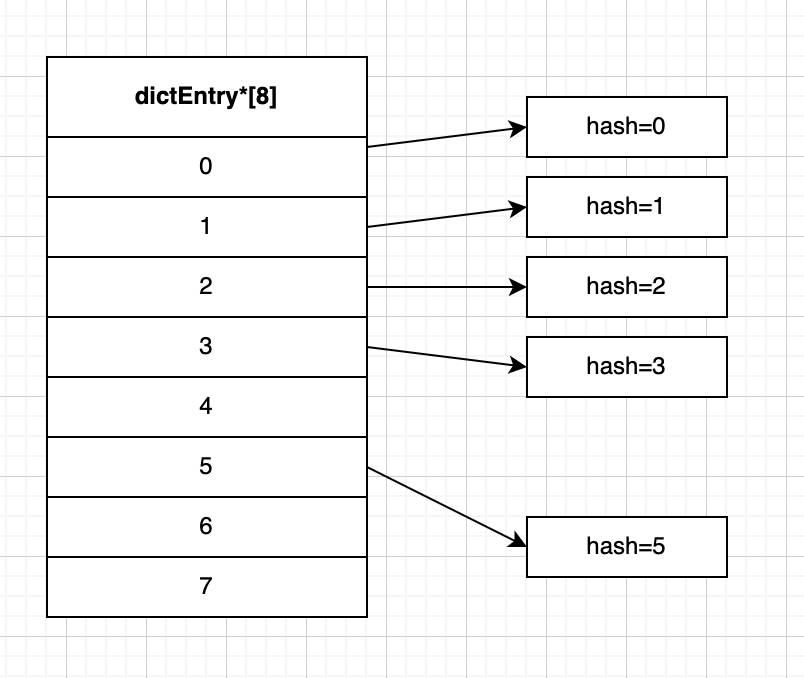
那麼假如我們還要找hash=1的節點,因為沒有鍵衝突,自然也沒有鏈表,我們可以直接通過索引來找到對應節點。
可以看到,因為rehash操作數組擴容的緣故,鍵衝突的情況少了,進而我們可以更高效地進行查找等操作。
觸發rehash操作的條件
首先我們先引入一個參數,叫做負載因子(load_factor),要注意的是:它與HashMap中的負載因子代表的含義不同;在HashMap里負載因子loadFactor作為一個默認值為0.75f的常量存在,而在redis的dict這裡,它是一個會動態變化的參數,等於哈希表的 used屬性值/size屬性值,也就是 實際節點數/哈希表數組大小。假如一個size為4的哈希表有4個哈希節點,那麼此時它的負載因子就是1;size為8的哈希表有4個哈希節點,那麼此時它的負載因子就是0.5。
滿足下面任一條件,程序就會對哈希表進行rehash操作:
- 擴容操作條件:
- 服務器目前沒有執行 BGSAVE 或者 BGREWRITEAOF 命令,負載因子大於等於1。
- 服務器目前正在執行 BGSAVE 或者 BGREWRITEAOF 命令,負載因子大於等於5。
- 收縮操作條件:
- 負載因子小於0.1時。
BGSAVE 和 BGREWRITEAOF 命令可以統一理解為redis的實現持久化的操作。
- BGSAVE 表示通過fork一個子進程,讓其創建RDB文件,父進程繼續處理命令請求。
- BGREWRITEAOF 類似,不過是進行AOF文件重寫。
漸進式rehash?rehash的過程是怎麼樣的?
首先我們知道redis是單線程,並且對性能的要求很高,但是rehash操作假如碰到了數量多的情況,比如需要遷移百萬、千萬的鍵值對,龐大的計算量可能會導致服務器在一段時間裏掛掉!
為了避免rehash對服務器性能造成影響,redis會分多次、漸進式地進行rehash,即漸進式rehash。
(可以理解粗略地理解為程序有空閑再來進行rehash操作,不影響其他命令的正常執行)
對哈希表進行漸進式rehash的步驟如下:
- 首先為 ht[1] 哈希表分配空間,size的大小取決於要執行的操作,以及 ht[0] 當前的節點數量(即ht[0]的used屬性值):
- 擴展操作,ht[1]的size值為第一個大於等於ht[0].used屬性值乘以2的 2^n
- 收縮操作,ht[1]的size值為第一個小於ht[0].used屬性值的 2^n
(有沒有很熟悉,其實跟Java中的HashMap、ConcurrentHashMap操作類似)
- 將哈希表的rehashidx值從-1置為0,表示rehash工作開始。
- 節點轉移,重新計算鍵的hash值和索引值,再將節點放置到ht[1]哈希表的對應索引位置上。
- 每次rehash工作完成後,程序會將rehashidx值加一。
(這裡的每次rehash就指漸進式rehash)
- 當ht[0]的所有節點都轉移到ht[1]之後,釋放ht[0],將ht[1]設置為ht[0],並在ht[1]新創建一個空白的hash表,等待下次rehash再用到。(其實就是數據轉移到ht[1]後,再恢復為 ht[0]儲存實際數據,ht[1]為空白表的狀態)
- 最後程序會將rehashidx的值重置為-1,代表rehash操作已結束。
進行漸進式rehash的時候會影響字典的其他操作嗎?
因為在進行漸進式rehash的時候,字典會同時用到ht[0]和ht[1]這兩個哈希表,所以在這期間,字典的刪除(delete)、查找(find)、更新(update)等操作會在兩個哈希表進行;而進行添加操作時,會直接插入到ht[1]。
比如查找一個鍵時,程序會先在ht[0]裏面查找,沒找到的話再去ht[1]里進行查找。
搜資料的時候還看到好多評論,都對邏輯產生了疑問,還舉了例子說有問題,但我仔細看了下,其實都是忽略了刪除和更新都會在兩個哈希表進行的前提條件。

寫在最後的最後
我是蘇易困,大家也可以叫我易困,一名Java開發界的小學生,文章可能不是很優質,但一定會很用心。
距離上次更新都過去了好久,一是因為上海的疫情有點嚴重,一直沒靜下心來好好整理知識,還有就是發現自己得先很好地消化完知識才能夠整理出來,不然其實各方面收穫不大;所以後面也會自己先認真消化後再整理分享,不會追求速度,但會認真總結整理。
因為疫情要一直封到4月1號,我們小區還有1例陽性,更不知道到什麼時候了,每天早上也要定鬧鐘搶菜,但還搶不到,因為沒有綠葉菜的補給,我感覺已經得口腔潰瘍了,還好買到了維C泡騰片,感覺可以稍微緩緩。
疫情掰扯這麼多,其實我和大家一樣,我有想吃的美食,有想去的地方,更有馬上想見到的人,所以最後還是希望疫情能夠趕緊好起來~



