《前端運維》一、Linux基礎–10定時任務
- 2022 年 3 月 23 日
- 筆記
一、進程管理
進程(Process)是計算機中的程序關於某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎。在早期面向進程設計的計算機結構中,進程是程序的基本執行實體;在當代面向線程設計的計算機結構中,進程是線程的容器。程序是指令、數據及其組織形式的描述,進程是程序的實體。以上這段話來自百度百科。
簡單來說哈,進程就是運行一段代碼的實體。在linux中,我們可以通過命令來查看系統中所有的進程、判斷服務器的狀態、殺死進程等等。下面我們來看一下相關的命令都有哪些。
1、ps
該命令用來顯示當前進程的狀態,類似於Windows的任務管理器。它的選項非常多,這裡僅簡單說下常用的選項:
- -A,顯示所有進程
- -w,顯示加寬,可以顯示更多的資訊
- -au,顯示較詳細的資訊
- -aux,顯示所有包含其他使用者的行程
然後呢,我們來看下-au(x)命令下顯示信息字段的含義:
| 數據 | 含義 |
|---|---|
| USER | 該進程是由哪個用戶創建的 |
| PID | 進程的ID號 |
| %CPU | 該進程佔用CPU資源的百分比,佔用越高說明越消耗系統資源 |
| %MEM | 該進程佔用物理內存的百分比,佔用越高說明越消耗系統資源 |
| VSZ | 該進程佔用虛擬內存的百分比,單位是KB |
| RSS | 該進程佔用實際物理內存大小,單位是KB |
| TTY | 該進程在哪個終端中運行。tty1~tty7表示本地控制終端,tty1~tty6是字符終端,tty7是圖形終端。pts/0~255代表虛擬終端,?表示此終端是系統啟動的 |
| STAT | 進程狀態 |
| START | 該進程的啟動時間 |
| TIME | 該進程佔用CPU的運算時間,數值越高說明越消耗系統資源 |
| COMMAND | 產生此進程的命令名 |
其中STAT進程狀態對應的字段含義是:
- D: 無法中斷的休眠狀態 (通常 IO 的進程)
- R: 正在執行中
- S: 靜止狀態
- T: 暫停執行
- Z: 不存在但暫時無法消除
- W: 沒有足夠的記憶體分頁可分配
- <: 高優先序的行程
- N: 低優先序的行程
- L: 有記憶體分頁分配並鎖在記憶體內 (實時系統或捱A I/O)
2、pstree
將所有行程以樹狀圖顯示,樹狀圖將會以 pid (如果有指定) 或是以 init 這個基本行程為根 (root),如果有指定使用者 id,則樹狀圖會只顯示該使用者所擁有的行程,常用選項如下:
- -u,顯示用戶名稱
- -p,顯示進程pid
3、top
該命令用於實時顯示process的動態。常用選項如下:
- -d : 改變顯示的更新速度,或是在交談式指令列( interactive command)按 s
- -q : 沒有任何延遲的顯示速度,如果使用者是有 superuser 的權限,則 top 將會以最高的優先序執行
- -c : 切換顯示模式,共有兩種模式,一是只顯示執行檔的名稱,另一種是顯示完整的路徑與名稱
- -S : 累積模式,會將己完成或消失的子行程 ( dead child process ) 的 CPU time 累積起來
- -s : 安全模式,將交談式指令取消, 避免潛在的危機
- -i : 不顯示任何閑置 (idle) 或無用 (zombie) 的行程
- -n : 更新的次數,完成後將會退出 top
- -b : 批次檔模式,搭配 “n” 參數一起使用,可以用來將 top 的結果輸出到檔案內
直接執行top命令顯示如下信息:
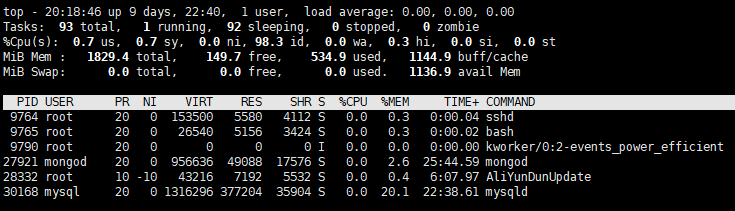
解釋下信息的內容:
第一行是任務隊列信息。
| 內容 | 說明 |
|---|---|
| 12:12:12 | 系統的當前時間 |
| up 1 day 5:33 | 系統的運行時間,本機已經運行了1天5小時33分 |
| 2 users | 當前登錄了二個客戶端 |
| load average 0 0 0 | 系統在之前1分鐘、5分鐘、15分鐘的平均負載。一般認為小於1小時負載較小,大於1超過負載 |
第二行是行為進程信息。
| 內容 | 說明 |
|---|---|
| Tasks: 100 total | 系統中的進程總數 |
| 1 running | 正在運行的進程數 |
| 94 sleeping | 睡眠的進程 |
| 0 stopped | 正在停止的進程 |
| 0 zombie | 殭屍進程。如果不是0的話要進行檢查 |
第三行是行為CPU信息。
| %Cpu(s): 0.1us | 用戶模式佔用的CPU百分比 |
| 0.1sy | 系統模式佔用的CPU百分比 |
| 0.0ni | 改變過優先級的用戶進程 佔用的CPU百分比 |
| 99.7id | 空閑CPU的CPU百分比 |
| 0.1wa | 等待輸入/輸出的進程的佔用CPU百分比 |
| 0.1hi | 硬中斷請求服務佔用的CPU百分比 |
| 0.1si | 軟中斷請求服務佔用的CPU百分比 |
| 0.0st | st(Steal time)虛擬時間百分比,就是當有 |
第四行是行為物理內存信息。
| 內容 | 說明 |
|---|---|
| Mem: 1030720k total | 物理內存的問題,單位是KB |
| 551860k used | 已經使用的物理內存數量 |
| 478860k free | 空閑的物理內存數量,虛擬機分配了1024M內存,使用了538M,空閑467M |
| 43180k buffers | 作為緩衝的內存數量,可以存放需要寫入硬盤的數據,用來加速數據的寫入 |
第五行為交換分區信息。
| 內容 | 說明 |
|---|---|
| Swap: 2047992k total | 總計的交換分區(虛擬內存)大小 |
| 536k used | 已經使用的交換分區大小 |
| 2047456k free | 空閑的交換分區大小 |
| 368164k cached | 把需要經常讀取的數據從硬盤讀到內存中,加速了數據的讀取 |
另外我們需要學習的就是一些交互式命令:
| 選項 | 含義 |
|---|---|
| ?或h | 顯示交互模式的幫助 |
| P | 按CPU使用率排序,默認就是此選項 |
| M | 以內存的使用率排序 |
| N | 以PID排序 |
| q | 退出top |
4、kill
該命令用於刪除執行中的程序或工作。kill 可將指定的信息送至程序。預設的信息為 SIGTERM(15),可將指定程序終止。若仍無法終止該程序,可使用 SIGKILL(9) 信息嘗試強制刪除程序。程序或工作的編號可利用 ps 指令或 jobs 指令查看。常用選項如下:
- -l <信息編號> 若不加<信息編號>選項,則 -l 參數會列出全部的信息名稱。
- -s <信息名稱或編號> 指定要送出的信息。
- [程序] [程序]可以是程序的PID或是PGID,也可以是工作編號。
常用的信息編號如下:
- 1 (HUP):重新加載進程。
- 9 (KILL):殺死一個進程。
- 15 (TERM):正常停止一個進程。
下面我們來看一個小栗子:
我們創建一個sh文件,並將它存儲在/demo下,文件的內容如下:
#!/bin/bash i=0 while [ $i -le 1000 ] do echo $(date) sleep 1s done
很簡單,就是循環執行1000次,打印當前日期。然後我們重新開個窗口來執行這段腳本。然後他就一直打印了:
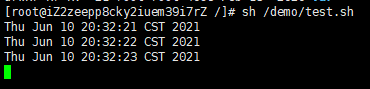
我們來殺死他,殺死他之前需要知道他的信息編號,我們來看下:
第一種方法是這樣執行腳本:

它會打印信息編號後再執行。於是我們就可以:

然後,另一個窗口運行的代碼就停止了。
另一種查詢的方法是這樣的:

也可以查到信息編號。好了,小栗子就到這裡,我們繼續往下學習。
二、系統資源查看
1、vmstat
監控系統資源使用狀態,vmstat [刷新延時] [刷新次數]。比如vmstat 1 3。就是每秒刷新一次,刷新三次後停止。

其中字段的含義如下:
1)procs:進程信息字段
| 分類 | 參數 | 含義 |
|---|---|---|
| procs | r | 等待運行的進程數,數量越大,系統就越繁忙 |
| procs | b | 不可被喚醒的進程數量,數量越大,系統越繁忙 |
2)memory:內存信息字段
| 分類 | 參數 | 含義 |
|---|---|---|
| memory | swpd | 使用的Swap空間的大小,單位KB |
| memory | free | 空閑的內存容量,單位KB |
| memory | buff | 緩衝的內存容量,單位KB |
| memory | cache | 緩存的內存容量,單位KB |
3)swap:交換分區字段,如果說si和so數越大說明數據經常要在磁盤和內存之間數據交換,系統性能就會越差
| 分類 | 參數 | 含義 |
|---|---|---|
| swap | si(in) | 從磁盤中交換到內存中的數據的數量,單位KB |
| swap | so(out) | 從內存中交換到硬盤中的數據的數量,單位KB |
4)io:磁盤讀寫,bi和bo數越大,說明磁盤的I/O越繁忙。
| 分類 | 參數 | 含義 |
|---|---|---|
| io | bi(in) | 從塊設備讀入數據的問題,單位是塊 |
| io | bo(out) | 寫到塊設備的數據的總量,單位是塊 |
5)system:系統信息字段,in和cs數越大說明系統與接口設備的通信越頻繁。
| 分類 | 參數 | 含義 |
|---|---|---|
| system | in(interrupt) | 每秒被中斷的進程次數 |
| system | cs(switch) | 每秒鐘進行的事件切換次數 |
6)CPU:CPU信息字段
| 分類 | 參數 | 含義 |
|---|---|---|
| CPU | us(user) | 非內核進程消耗CPU運算時間的百分比 |
| CPU | sy(system) | 內核進程消耗CPU運算時間的百分比 |
| CPU | id(idea) | 空閑CPU的百分比 |
| CPU | wa(wait) | 等待I/O所消耗的CPU百分比 |
| CPU | st(steal) | 被虛擬機偷走的CPU百分比 |
2、free
該命令用於顯示內存狀態。free指令會顯示內存的使用情況,包括實體內存,虛擬的交換文件內存,共享內存區段,以及系統核心使用的緩衝區等。常用選項如下:
- -b, 以位元組為單位
- -k ,以KB位元組為單位
- -m ,以MB位元組為單位
- -g ,以GB位元組為單位
- -h ,以合適的單位顯示內存使用情況,最大為三位數,自動計算對應的單位值。單位有:B = bytes,K = kilos,M = megas,G = gigas,T = teras
- -o ,不顯示緩衝區調節列。
- -s <間隔秒數> ,持續觀察內存使用狀況。
- -t ,內存總和列。
- -V ,顯示版本信息。
比如我們試一下free -m命令,顯示如下:

3、uname
用來查看內核相關信息,常用選項如下:
- -a或–all 顯示全部的信息。
- -m或–machine 顯示電腦類型。
- -n或–nodename 顯示在網絡上的主機名稱。
- -r或–release 顯示操作系統的發行編號。
- -s或–sysname 顯示操作系統名稱。
- -v 顯示操作系統的版本。
- –help 顯示幫助。
- –version 顯示版本信息。
4、file
該指令用於辨識文件類型。常用選項如下:
- -b 列出辨識結果時,不顯示文件名稱。
- -c 詳細顯示指令執行過程,便於排錯或分析程序執行的情形。
- -f<名稱文件> 指定名稱文件,其內容有一個或多個文件名稱時,讓file依序辨識這些文件,格式為每列一個文件名稱。
- -L 直接顯示符號連接所指向的文件的類別。
- -m<魔法數字文件> 指定魔法數字文件。
- -v 顯示版本信息。
- -z 嘗試去解讀壓縮文件的內容。
- [文件或目錄…] 要確定類型的文件列表,多個文件之間使用空格分開,可以使用shell通配符匹配多個文件。
通過file命令,可以查看/bin/ls來查看操作系統位數。
5、其他
可以通過lsb_release -a命令查看發行版本。可以通過lsb_release -v命令查看發行版本。
三、定時任務
1、crontab
該命令可以用來定期執行程序。當安裝完成操作系統之後,默認便會啟動此任務調度命令。crond 命令每分鍾會定期檢查是否有要執行的工作,如果有要執行的工作便會自動執行該工作。
注意:新創建的 cron 任務,不會馬上執行,至少要過 2 分鐘後才可以,當然你可以重啟 cron 來馬上執行。而 linux 任務調度的工作主要分為以下兩類:
- 1、系統執行的工作:系統周期性所要執行的工作,如備份系統數據、清理緩存
- 2、個人執行的工作:某個用戶定期要做的工作,例如每隔10分鐘檢查郵件服務器是否有新信,這些工作可由每個用戶自行設置
可以通過下面的命令重啟cron:
systemctl restart crond.service
然後可以通過ps -ef | grep crond來查看是否啟動了crond:

crontab命令常用的選項如下:
- -e : 執行文字編輯器來設定時程表,內定的文字編輯器是 VI,如果你想用別的文字編輯器,則請先設定 VISUAL 環境變數來指定使用那個文字編輯器(比如說 setenv VISUAL joe)
- -r : 刪除目前的時程表
- -l : 列出目前的時程表
說明:
crontab 是用來讓使用者在固定時間或固定間隔執行程序之用,換句話說,也就是類似使用者的時程表。
-u user 是指設定指定 user 的時程表,這個前提是你必須要有其權限(比如說是 root)才能夠指定他人的時程表。如果不使用 -u user 的話,就是表示設定自己的時程表。
crontab的語法如下:
crontab [ -u user ] file # 或者 crontab [ -u user ] { -l | -r | -e }
循環任務還有時間格式,如下:
f1 f2 f3 f4 f5 program
- 其中 f1 是表示分鐘,f2 表示小時,f3 表示一個月份中的第幾日,f4 表示月份,f5 表示一個星期中的第幾天。program 表示要執行的程序。
- 當 f1 為 * 時表示每分鐘都要執行 program,f2 為 * 時表示每小時都要執行程序,其餘類推
- 當 f1 為 a-b 時表示從第 a 分鐘到第 b 分鐘這段時間內要執行,f2 為 a-b 時表示從第 a 到第 b 小時都要執行,其餘類推
- 當 f1 為 */n 時表示每 n 分鐘個時間間隔執行一次,f2 為 */n 表示每 n 小時個時間間隔執行一次,其餘類推
- 當 f1 為 a, b, c,… 時表示第 a, b, c,… 分鐘要執行,f2 為 a, b, c,… 時表示第 a, b, c…個小時要執行,其餘類推
* * * * * - - - - - | | | | | | | | | +----- 星期中星期幾 (0 - 6) (星期天 為0) | | | +---------- 月份 (1 - 12) | | +--------------- 一個月中的第幾天 (1 - 31) | +-------------------- 小時 (0 - 23) +------------------------- 分鐘 (0 - 59)
額外的,表示時間還有些特殊符號,我們要注意一下:
| 符號 | 含義 | 例子 |
|---|---|---|
| * | 代表任意時間 | 比如第一個星就代表一個小時中每分鐘都執行一次 |
| , | 代表不連續的時間 | 比如”1,2,3 “,就代表每小時的1分、2分、3分執行命令 |
| – | 代表連續的時間範圍 | 比如 ” 1-5 * ** “,代表每小時的第1分到第5分執行命令 |
| */n | 代表每隔多久執行一次 | 比如 “/10 ” 就代表每隔10分鐘就執行一次命令 |
| 0 0 1,10 * 1 | 每月1號和10號,每周1的0點0分都會執行 |
僅僅羅列語法有點模糊,我們來看個例子吧:
首先,我們通過定時任務的編輯模式命令,編輯一個定時任務:
crontab -e
然後再vi的指令模式下點擊鍵盤的i,這個就不多說了,在vi的那一章有詳細的講,然後我們編輯一個定時任務:
* * * * * echo `date` >> /root/date.log
什麼意思呢,就是每分鐘打印日期並輸入到date.log文件中。要注意,定時任務中的時間最小單位是分鐘,最大單位是天,另外,無論是寫命令還是腳本都需要使用絕對路徑。額外要說明的是:
crontab -e是用戶執行的命令,不同的用戶身份可以執行自己的定時任務- 如果需要系統執行定時任務,可以編輯
/etc/crontab文件 /etc/crontab可以指定shell、路徑、郵件發送和家目錄
我們繼續上面的例子:
寫完定時任務後,我們保存並推出退出。然後就會出現如下的提示:

即,安裝了新的定時任務。另外,我們也可以通過crontab -l命令查看當前的定時任務:

然後呢,我們看看date.log文件:

發現任務確實是在跑的。就讓它先跑着吧…。
四、定時任務實戰
還記得之前我們安裝了nginx、mysql等工具,下面我們通過這章的學習內容,來監控下各工具的運行狀態。
1、監控nginx狀態
監控的代碼如下:
#!/bin/bash #設置本地變量 #變量nginx的結果是查詢nginx的進程,不包含grep自身 nginx=`ps -ef |grep /user/sbin/nginx|grep -v grep|wc -l` # 然後下面的意思大家都懂了吧,不懂就回頭複習一遍 if [ $nginx -gt 2 ];then echo "your nginx is running" exit 0 else echo "your nginx is ready to rerunning" /bin/systemctl start nginx.service exit 1 fi
然後我們跑一下這個命令試一下,還是之前demo的位置,這個位置其實無所謂,就是你放置腳本的位置就對了:

然後,我們可以:
curl http://localhost
就可以看到了結果了。欸?你這是手動的啊,也沒定時啊。沒錯。但是,我們可以把命令按照前面的例子加進去就可以了,這裡不再演示,大家要自己動手了哦。
2、監控mysql狀態
這回大家都知道怎麼用了吧,這回僅展示下定時任務的腳本,別的就不說啦:
#!/bin/bash PortNum=`netstat -lnt|grep 3306|wc -l` if [ $PortNum -gt 0 ] then echo "mysqld is running." else echo "mysqld is stoped." fi
3、mysql備份
#!/bin/bash DATE=$(date +%F_%H-%M-%S) HOST=127.0.0.1 DB=test USER=root PASS=abcd1#EFG MAIL="[email protected]" BACKUP_DIR=/data/db_backup if [ ! -d "$BACKUP_DIR" ];then mkdir -p $BACKUP_DIR fi SQL_FILE=${DB}_FULL_$DATE.sql BAK_FILE=${DB}_FULL_$DATE.zip cd $BACKUP_DIR if mysqldump -h$HOST -u$USER -p$PASS -B $DB > $SQL_FILE; then zip $BAK_FILE $SQL_FILE && rm -rf $SQL_FILE if [ ! -s $BAK_FILE ]; then echo "$DATE 備份失敗" | mail -s "備份失敗" $MAIL fi else echo "$DATE 備份失敗" | mail -s "備份失敗" $MAIL fi find $BACKUP_DIR -name '*.zip' -ctime +14 -exec rm {} \;
到此這篇文章就結束了哦。