圖解機器學習 | 邏輯回歸算法詳解
- 2022 年 3 月 10 日
- 筆記
- 圖解機器學習算法:從入門到精通系列教程, 機器學習, 算法, 邏輯回歸

作者:韓信子@ShowMeAI
教程地址://www.showmeai.tech/tutorials/34
本文地址://www.showmeai.tech/article-detail/188
聲明:版權所有,轉載請聯繫平台與作者並註明出處
引言
本篇內容我們給大家介紹機器學習領域最常見的模型之一:邏輯回歸。它也是目前工業界解決問題最廣泛作為baseline的解決方案。邏輯回歸之所以被廣泛應用,因為其簡單有效且可解釋性強。
本文的結構如下:
-
第1部分:回顧機器學習與分類問題。回顧機器學習中最重要的問題之一分類問題,不同的分類問題及數學抽象。
-
第2部分:邏輯回歸核心思想。介紹線性回歸問題及邏輯回歸解決方式,講解邏輯回歸核心思想。
-
第3部分:Sigmoid函數與分類器決策邊界。介紹邏輯回歸模型中最重要的Sigmoid變換函數,以及不同分類器得到的決策邊界。
-
第4部分:模型優化使用的梯度下降算法。介紹模型參數學習過程中最常使用到的優化算法:梯度下降。
-
第5部分:模型過擬合問題與正則化。介紹模型狀態分析及過擬合問題,以及緩解過擬合問題可以使用的正則化手段。
-
第6部分:特徵變換與非線性切分。介紹由線性分類器到非線性分類場景,對特徵可以進行的變換如構建多項式特徵,使得分類器得到分線性切分能力。
(本篇邏輯回歸算法的部分內容涉及到機器學習基礎知識,沒有先序知識儲備的寶寶可以查看ShowMeAI的文章 圖解機器學習 | 機器學習基礎知識)。
1.機器學習與分類問題
1)分類問題
分類問題是機器學習非常重要的一個組成部分,它的目標是根據已知樣本的某些特徵,判斷一個樣本屬於哪個類別。分類問題可以細分如下:
-
二分類問題:表示分類任務中有兩個類別新的樣本屬於哪種已知的樣本類。
-
多類分類(Multiclass Classification)問題:表示分類任務中有多類別。
-
多標籤分類(Multilabel Classification)問題:給每個樣本一系列的目標標籤。

2)分類問題的數學抽象
從算法的角度解決一個分類問題,我們的訓練數據會被映射成n維空間的樣本點(這裡的n就是特徵維度),我們需要做的事情是對n維樣本空間的點進行類別區分,某些點會歸屬到某個類別。
下圖所示的是二維平面中的兩類樣本點,我們的模型(分類器)在學習一種區分不同類別的方法,比如這裡是使用一條直線去對2類不同的樣本點進行切分。

常見的分類問題應用場景很多,我們選擇幾個進行舉例說明:
-
垃圾郵件識別:可以作為二分類問題,將郵件分為你「垃圾郵件」或者「正常郵件」。
-
圖像內容識別:因為圖像的內容種類不止一個,圖像內容可能是貓、狗、人等等,因此是多類分類問題。
-
文本情感分析:既可以作為二分類問題,將情感分為褒貶兩種,還可以作為多類分類問題,將情感種類擴展,比如分為:十分消極、消極、積極、十分積極等。
2.邏輯回歸算法核心思想
下面介紹本次要講解的算法——邏輯回歸(Logistic Regression)。邏輯回歸是線性回歸的一種擴展,用來處理分類問題。
1)線性回歸與分類
分類問題和回歸問題有一定的相似性,都是通過對數據集的學習來對未知結果進行預測,區別在於輸出值不同。
-
分類問題的輸出值是離散值(如垃圾郵件和正常郵件)。
-
回歸問題的輸出值是連續值(例如房子的價格)。
既然分類問題和回歸問題有一定的相似性,那麼我們能不能在回歸的基礎上進行分類呢?
可以想到的一種嘗試思路是,先用線性擬合,然後對線性擬合的預測結果值進行量化,即將連續值量化為離散值——即使用『線性回歸+閾值』解決分類問題。
我們來看一個例子。假如現在有一個關於腫瘤大小的數據集,需要根據腫瘤的大小來判定是良性(用數字0表示)還是惡性(用數字1表示),這是一個很典型的二分類問題。

如上圖,目前這個簡單的場景我們得到1個直觀的判定:腫瘤的大小大於5,即為惡性腫瘤(輸出為1);腫瘤的大小等於5,即為良性腫瘤(輸出為0)。
下面我們嘗試之前提到的思路,使用一元線性函數\(h(x) = \theta_0+\theta_1x\)去進行擬合數據,函數體現在圖片中就是這條黑色直線。

這樣分類問題就可以轉化為:對於這個線性擬合的假設函數,給定一個腫瘤的大小,只要將其帶入假設函數,並將其輸出值和0.5進行比較:
-
如果線性回歸值大於0.5,就輸出1(惡性腫瘤)。
-
如果線性回歸值小於0.5,就輸出0(良性腫瘤)。

上圖的數據集中的分類問題被完美解決。但如果將數據集更改一下,如圖所示,如果我們還是以0.5為判定閾值,那麼就會把腫瘤大小為6的情況進行誤判為良好。
所以,單純地通過將線性擬合的輸出值與某一個閾值進行比較,這種方法用於分類非常不穩定。
2)邏輯回歸核心思想
因為「線性回歸+閾值」的方式很難得到魯棒性好的分類器,我們對其進行拓展得到魯棒性更好的邏輯回歸(Logistic Regression,有些地方也叫做「對數幾率回歸」)。邏輯回歸將數據擬合到一個logit函數中,從而完成對事件發生概率的預測。
如果線性回歸的結果輸出是一個連續值,而值的範圍是無法限定的,這種情況下我們無法得到穩定的判定閾值。那是否可以把這個結果映射到一個固定大小的區間內(比如0到1),進而判斷呢。
當然可以,這就是邏輯回歸做的事情,而其中用於對連續值壓縮變換的函數叫做Sigmoid函數(也稱Logistic函數,S函數)。

Sigmoid數學表達式為
\]
可以看到S函數的輸出值在0到1之間。
3.Sigmoid函數與決策邊界
剛才大家見到了Sigmoid函數,下面我們來講講它和線性擬合的結合,如何能夠完成分類問題,並且得到清晰可解釋的分類器判定「決策邊界」。
1)分類與決策邊界
決策邊界就是分類器對於樣本進行區分的邊界,主要有線性決策邊界(linear decision boundaries)和非線性決策邊界(non-linear decision boundaries),如下圖所示。

2)線性決策邊界生成
那麼,邏輯回歸是怎麼得到決策邊界的呢,它與Sigmoid函數又有什麼關係呢?
如下圖中的例子:
如果我們用函數g表示Sigmoid函數,邏輯回歸的輸出結果由假設函數\(h_{\theta}(x)=g\left(\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}\right)\)得到。
對於圖中的例子,我們暫時取參數\(\theta_{0}、\theta_{1} 、\theta_{2}\)分別為-3、1和1,那麼對於圖上的兩類樣本點,我們代入一些坐標到\(h_{\theta}(x)\),會得到什麼結果值呢。

-
對於直線上方的點\(\left ( x_{1}, x_{2} \right )\)(例如\(\left ( 100, 100 \right )\)),代入\(-3+ x_{1}+ x_{2}\),得到大於0的取值,經過Sigmoid映射後得到的是大於0.5的取值。
-
對於直線下方的點\(\left ( x_{1}, x_{2} \right )\)(例如\(\left ( 0, 0 \right )\)),代入\(-3+ x_{1}+ x_{2}\),得到小於0的取值,經過Sigmoid映射後得到的是小於0.5的取值。
如果我們以0.5為判定邊界,則線性擬合的直線\(-3+ x_{1}+ x_{2} = 0\)變換成了一條決策邊界(這裡是線性決策邊界)。
3)非線性決策邊界生成
其實,我們不僅僅可以得到線性決策邊界,當\(h_{\theta}(x)\)更複雜的時候,我們甚至可以得到對樣本非線性切分的非線性決策邊界(這裡的非線性指的是無法通過直線或者超平面把不同類別的樣本很好地切分開)。
如下圖中另外一個例子:如果我們用函數g表示Sigmoid函數,邏輯回歸的輸出結果由假設函數\(h_{\theta}(x)=g\left(\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\theta_{3} x_{1}^{2}+\theta_{4} x_{2}^{2}\right)\)得到。
對於圖中的例子,我們暫時取參數\(\theta_{0} 、\theta_{1} 、\theta_{2} 、\theta_{3} 、\theta_{4}\)分別為-1、0、0、1和1,那麼對於圖上的兩類樣本點,我們代入一些坐標到
\(h_{\theta}(x)\),會得到什麼結果值呢。

-
對於圓外部的點\(\left ( x_{1}, x_{2} \right )\)(例如\(\left ( 100, 100 \right )\)),代入\(\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\theta_{3} x_{1}^{2}+\theta_{4} x_{2}^{2}\),得到大於0的取值,經過Sigmoid映射後得到的是大於0.5的取值。
-
對於圓內部的點\(\left ( x_{1}, x_{2} \right )\)(例如\(\left ( 0, 0 \right )\)),代入\(\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\theta_{3} x_{1}^{2}+\theta_{4} x_{2}^{2}\),得到小於0的取值,經過Sigmoid映射後得到的是小於0.5的取值。
如果我們以0.5為判定邊界,則線性擬合的圓曲線\(-1+x_{1}^2+x_{2}^2=0\)變換成了一條決策邊界(這裡是非線性決策邊界)。
4.梯度下降與優化
1)損失函數
前一部分的例子中,我們手動取了一些參數θ的取值,最後得到了決策邊界。但大家顯然可以看到,取不同的參數時,可以得到不同的決策邊界。
哪一條決策邊界是最好的呢?我們需要定義一個能量化衡量模型好壞的函數——損失函數(有時候也叫做「目標函數」或者「代價函數」)。我們的目標是使得損失函數最小化。
我們如何衡量預測值和標準答案之間的差異呢,最簡單直接的方式是數學中的均方誤差。它的計算方式很簡單,對於所有的樣本點\(x_{i}\),預測值\(h_{\theta}(x_{i})\)與標準答案\(y_{i}\)作差後平方,求均值即可,這個取值越小代表差異度越小。
\]
均方誤差對應的損失函數:均方誤差損失(MSE)在回歸問題損失定義與優化中廣泛應用,但是在邏輯回歸問題中不太適用。sigmoid函數的變換使得我們最終得到損失函數曲線如下圖所示,是非常不光滑凹凸不平的,這種數學上叫做非凸的損失函數(關於損失函數與凸優化更多知識可以參考ShowMeAI的文章 圖解AI數學基礎 | 微積分與最優化),我們要找到最優參數(使得函數取值最小的參數)是很困難的。

解釋:在邏輯回歸模型場景下,使用MSE得到的損失函數是非凸的,數學特性不太好,我們希望損失函數如下的凸函數。凸優化問題中,局部最優解同時也是全局最優解,這一特性使得凸優化問題在一定意義上更易於解決,而一般的非凸最優化問題相比之下更難解決。
我們更希望我們的損失函數如下圖所示,是凸函數,我們在數學上有很好優化方法可以對其進行優化。

在邏輯回歸模型場景下,我們會改用對數損失函數(二元交叉熵損失),這個損失函數同樣能很好地衡量參數好壞,又能保證凸函數的特性。對數損失函數的公式如下:
\]
其中\(y^{(i)}\)表示樣本取值,在其為正樣本時取值為1,負樣本時取值為0,我們分這兩種情況來看看:

-\log \left(h_{\theta}(x)\right) & \text { if } y=0 \\
-\log \left(1-h_{\theta}(x)\right) & \text { if } y=1
\end{array}\right.
\]
–\(y^{(i)}=0\):當一個樣本為負樣本時,若\(h_{\theta}(x)\)的結果接近1(即預測為正樣本),那麼\(- \log \left(1-h_{\theta}\left(x\right)\right)\)的值很大,那麼得到的懲罰就大。
–\(y^{(i)}=1\):當一個樣本為正樣本時,若\(h_{\theta}(x)\)的結果接近0(即預測為負樣本),那麼\(- \log \left(h_{\theta}\left(x\right)\right)\)的值很大,那麼得到的懲罰就大。
2)梯度下降
損失函數可以用于衡量模型參數好壞,但我們還需要一些優化方法找到最佳的參數(使得當前的損失函數值最小)。最常見的算法之一是「梯度下降法」,逐步迭代減小損失函數(在凸函數場景下非常容易使用)。如同下山,找准方向(斜率),每次邁進一小步,直至山底。

梯度下降(Gradient Descent)法,是一個一階最優化算法,通常也稱為最速下降法。要使用梯度下降法找到一個函數的局部極小值,必須向函數上當前點對應梯度(或者是近似梯度)的反方向的規定步長距離點進行迭代搜索。

上圖中,α稱為學習率(learning rate),直觀的意義是,在函數向極小值方向前進時每步所走的步長。太大一般會錯過極小值,太小會導致迭代次數過多。

(關於損失函數與凸優化更多知識可以參考ShowMeAI的文章 圖解AI數學基礎 | 微積分與最優化//www.showmeai.tech/article-detail/165,關於監督學習的更多總結可以查看ShowMeAI總結的速查表手冊 AI知識技能速查 | 機器學習-監督學習)
5.正則化與緩解過擬合
1)過擬合現象
在訓練數據不夠多,或者模型複雜又過度訓練時,模型會陷入過擬合(Overfitting)狀態。如下圖所示,得到的不同擬合曲線(決策邊界)代表不同的模型狀態:
-
擬合曲線1能夠將部分樣本正確分類,但是仍有較大量的樣本未能正確分類,分類精度低,是「欠擬合」狀態。
-
擬合曲線2能夠將大部分樣本正確分類,並且有足夠的泛化能力,是較優的擬合曲線。
-
擬合曲線3能夠很好的將當前樣本區分開來,但是當新來一個樣本時,有很大的可能不能將其正確區分,原因是該決策邊界太努力地學習當前的樣本點,甚至把它們直接「記」下來了。

擬合曲線中的「抖動」,表示擬合曲線不規則、不光滑(上圖中的擬合曲線3),對數據的學習程度深,過擬合了。
2)正則化處理
過擬合的一種處理方式是正則化,我們通過對損失函數添加正則化項,可以約束參數的搜索空間,從而保證擬合的決策邊界並不會抖動非常厲害。如下圖為對數損失函數中加入正則化項(這裡是一個L2正則化項)
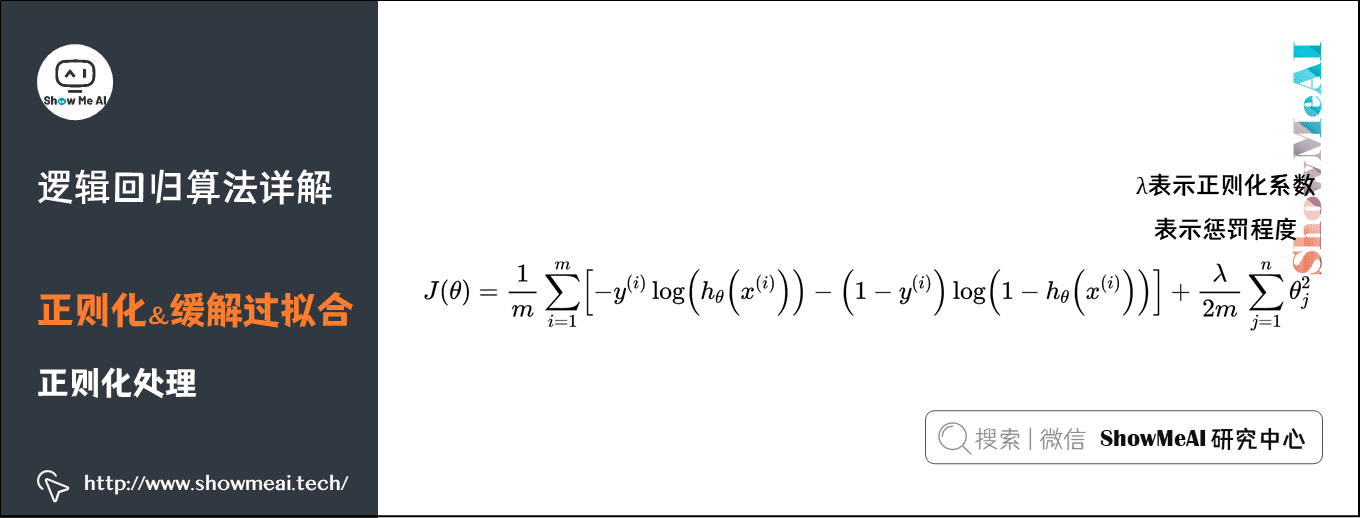
\]
其中\(\lambda\)表示正則化係數,表示懲罰程度,\(\lambda\)的值越大,為使\(J(\theta)\)的值小,則參數\(\theta\)的絕對值就得越小,通常對應于越光滑的函數,也就是更加簡單的函數,因此不易發生過擬合的問題。我們依然可以採用梯度下降對加正則化項的損失函數進行優化。
6.特徵變換與非線性表達
1)多項式特徵
對於輸入的特徵,如果我們直接進行線性擬合再給到Sigmoid函數,得到的是線性決策邊界。但添加多項式特徵,可以對樣本點進行多項式回歸擬合,也能在後續得到更好的非線性決策邊界。

多項式回歸,回歸函數是回歸變量多項式。多項式回歸模型是線性回歸模型的一種,此時回歸函數關於回歸係數是線性的。
在實際應用中,通過增加一些輸入數據的非線性特徵來增加模型的複雜度通常是有效的。一個簡單通用的辦法是使用多項式特徵,這可以獲得特徵的更高維度和互相間關係的項,進而獲得更好的實驗結果。
2)非線性切分
如下圖所示,在邏輯回歸中,擬合得到的決策邊界,可以通過添加多項式特徵,調整為非線性決策邊界,具備非線性切分能力。
–\(Z_{\theta}(x)\)中\(\theta\)是參數,當\(Z_{\theta}(x) = \theta_{0} + \theta_{1}x\)時,此時得到的是線性決策邊界;
–\(Z_{\theta}(x) = \theta_{0} + \theta_{1}x + \theta_{2}x^2\)時,使用了多項式特徵,得到的是非線性決策邊界。

目的是低維線性不可分的數據轉化到高維時,會變成線性可分。得到在高維空間下的線性分割參數映射回低維空間,形式上表現為低維的非線性切分。
更多監督學習的算法模型總結可以查看ShowMeAI的文章 AI知識技能速查 | 機器學習-監督學習。
視頻教程
可以點擊 B站 查看視頻的【雙語字幕】版本
【雙語字幕+資料下載】MIT 6.036 | 機器學習導論(2020·完整版)
ShowMeAI相關文章推薦
- 1.機器學習基礎知識
- 2.模型評估方法與準則
- 3.KNN算法及其應用
- 4.邏輯回歸算法詳解
- 5.樸素貝葉斯算法詳解
- 6.決策樹模型詳解
- 7.隨機森林分類模型詳解
- 8.回歸樹模型詳解
- 9.GBDT模型詳解
- 10.XGBoost模型最全解析
- 11.LightGBM模型詳解
- 12.支持向量機模型詳解
- 13.聚類算法詳解
- 14.PCA降維算法詳解
ShowMeAI系列教程推薦



