以小25倍參數量媲美GPT-3的檢索增強自回歸語言模型:RETRO
- 2022 年 3 月 3 日
- 筆記
©NLP論文解讀 原創•作者 | 吳雪夢Shinemon
研究方向 | 計算機視覺
導讀說明:
一個具有良好性能的語言模型,一定量的數據樣本必不可少。現有的各種語言模型中,例如GPT3具有1750億的參數量,前不久發佈的源1.0單體模型參數量達2457億,DeepMind團隊一起新發佈的語言模型Gopher[1]也具有2800億參數量,更有巨無霸模型MT-NLP參數量高達5300億(如圖2所示)!
為了獲得更高的性能,同時增加了如此龐大的數據量,從最初的萬級,到達現在的千億級,這種方式雖有效,但是難免會有如數據集難理解、增加模型偏差等一系列問題。
為了解決如此龐大數據量帶來的困擾,DeepMind團隊研發一種帶有互聯網規模檢索的高效預訓練模型,RETRO(Retrieval-Enhanced Transformer )模型,打破了模型越大準確度越高的假設。
論文解讀:
Improving language models by retrieving from trillions of tokens
論文地址:
//arxiv.org/pdf/2112.04426.pdf
研發團隊:

圖1. RETRO模型研發團隊
Fig1. Research Team of RETRO
01 研究背景
近年來,通過增加Transformer模型中的參數數量,自回歸語言建模的性能得到了顯著提高。
這也導致了訓練成本的增加,併產生了具有千億個參數的密集大型語言模型;同時,為了方便這些模型的訓練,收集了大量的數據集,其中包含了數萬億的單詞,詳情如圖2所示。
為減少計算量,論文作者探索了改進語言模型的另一種途徑:通過檢索包括網頁、書籍、新聞和代碼在內的文本段落數據庫來增強檢索,生成了一種新的語言模型RETRO。
RETRO模型利用從大型語料庫中檢索到的文檔塊,基於與前面標記的局部相似性來增強自回歸語言模型。該模型可以從零開始訓練,也可以快速改裝帶檢索的預訓練Transformer,仍然取得良好的性能。
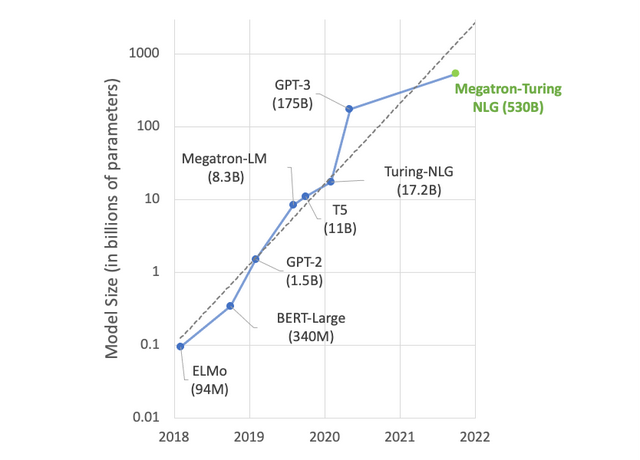
圖2. 語言模型參數量[2]
Fig2. Size of Language Model
02 RETRO模型
RETRO模型使用一個基於 MassiveText 多語言數據集的2萬億token數據庫,數據庫由一個鍵值內存(key-value memory)組成,每個值由兩個連續的標記塊( neighbour chunk:用於計算 key;its continuation:原文件文本的延續)組成,長度為64 token。
在數據庫進行查找時,模型利用嵌入算子BERT句子嵌入來預先計算所有近似最近鄰,並將結果保存為數據(RETRO 輸入)的一部分。
RETRO模型架構由一個編碼器堆棧(處理近鄰)和一個解碼器堆棧(處理輸入)組成,如下圖3所示。
編碼器堆棧由標準的 Transformer 編碼器塊組成;解碼器堆棧包含了Transformer解碼器塊和RETRO 解碼器塊(ATTN + Chunked cross attention (CCA) + FFNN)。

圖3. RETRO架構編碼器與解碼器[3]
Fig3. Encoder and Decoder of RETRO
編碼器堆棧會處理檢索到的近鄰,並生成鍵值矩陣;Transformer解碼器塊處理輸入文本,它對提示token應用自注意力,然後通過FFNN層;到達RETRO解碼器時,進行合併檢索到的信息。
在RETRO解碼器中應用分塊交叉注意力機制(Chunked cross-attention)[4],這樣模型就可以同時利用輸入的提示信息和記憶信息來完成布置的各種NLP任務,結構如圖4所示。

圖4. 高層次的RETRO架構
Fig4. A high-level overview of RETRO
這一新式架構為我們的模型預測都帶來什麼呢?簡言之就是將語言事實信息從世界知識信息中分離開來。
我們知道,為了保存住訓練數據中的信息,各類大型語言模型將它們所知道的一切都部署並編碼到模型參數中,但是對於事實信息是無效的。
當使用這種基於檢索的框架後,語言模型可以縮小很多,模型的參數量很小就可以包含更多的文本信息,模型運行的速度也有很大的提升,同時模型的可解釋性也能有很大的提高。
在文本生成過程中,神經數據庫就能幫助模型檢索它需要的事實信息,並能根據具體需要進行調整。
關於Chunked cross-attention(CCA)塊詳細內容見下圖5右圖,推導過程請見原論文。
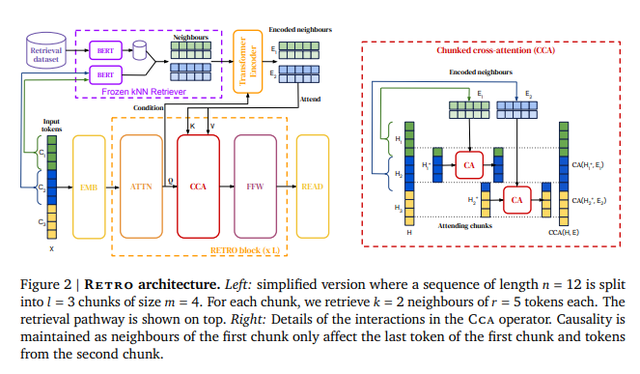
圖5. RETRO語言框架
Fig5. RETRO Architecture
03 解決數據泄露問題
在現階段模型發展中,幾乎所有的語言模型都存在數據泄露這個問題,更為關鍵的是,在檢索增強的語言模型中褎然舉首,因為檢索的過程就能直接訪問訓練集。
為此論文作者提出了一種衡量測試文檔與訓練集接近程度的評估方式,解決了測試集數據泄漏的問題[5]。
使用這種方法實驗後結果表明,提升RETRO性能來自顯式近鄰複製(explicit neighbor copying)和通用知識提取(general knowledge extraction),評估測試文檔和訓練數據集之間重疊函數如下圖6,具體推導詳情及評估指標請見原論文。

圖6. 重疊函數
Fig6. Function of the Overlap
04 模型間對比分析
在RETRO之前就有許多優秀檢索方法模型,如REALM、FID和KNN-LM等。
RETRO與KNN-LM和DPR共享組件,因為它使用Frozen檢索表示;與FID類似,RETRO在編碼器中分別處理檢索到的近鄰,並將它們組合在分塊交叉注意力機制中;使用塊可以在生成序列的同時重複檢索,而不是根據提示信息只檢索一次;
此外,RETRO檢索是在整個訓練前的過程中完成的,而不是簡單地為解決某個下游任務而插入其中,RETRO與現有方法的詳細區別如圖7所示。

圖7. RETRO與其他檢索方法對比
Fig7. Comparison of Retro with existing retrieval approaches
05 RETRO模型實驗結果
論文作者在C4 (Colossal Clean Crawled Corpus,web爬行語料庫,數據經過清理)、Wikitext103 (超過 1 億個語句的數據)、Curation Corpus (新聞文章摘要數據集)、Lambada (敘述性段落)和Pile (825GB,開源)數據集和一組手動選擇的維基百科文章上評估了RETRO模型,並評估了整個文檔的語言建模性能,測量了位元組位數(bpb)。
如圖8所示評估結果,每種數據集評估詳情請見原論文。
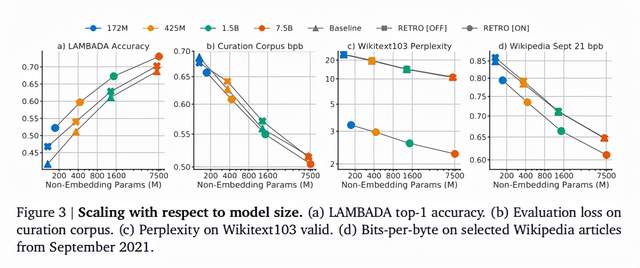
圖8. RETRO評估結果
Fig8. Evaluation Results of RETRO
在只使用4%的參數量的基礎上,RETRO模型獲得了與Gopher和 Jurassic-1 模型相當的性能,在大多數測試集上表現優異。
在Wikitext103上,RETRO的表現優於以前在大規模數據集上訓練的模型,並且在檢索密集型下游任務(如Q&A任務)上具有競爭力。

圖9. RETRO評估結果Ⅱ
Fig9. Evaluation Results of RETRO Ⅱ
06 小結
● 檢索記憶機制:RETRO不僅利用當下的知識,還會利用到記憶檢索這一機制;
● 半參數化方法:不需要增加模型的大小和訓練更多的數據,而讓模型在執行預測時能夠直接訪問大型數據庫;
● 應用在塊水平上的BERT句子嵌入檢索器;
● 應用基於查詢條件的可微編碼器:可根據實際需要自行調整;
● 與之前的塊檢索集進行分塊交叉注意力機制;
● 無測試集數據泄漏的問題;
● 消融結果顯示檢索對任務大有幫助。
07 未來展望
Transformer體系結構已經在許多NLP任務上提高了技術水平。然而這些性能改進依賴於大規模的擴展,從而導致了大量的內存和計算負擔。
但RETRO模型及OpenAI的WebGPT [6]可以證明,一味增大模型並不是提升性能的唯一路徑。
現如今,對信息的獲取是無止境的,對於我們人類來說,搜索網絡和分析給定的信息比記住所有的東西要直觀得多,那麼為什麼模型不能做同樣的事情呢?這項工作為通過前所未有的記憶檢索來改進語言模型開闢了一條新的途徑。
未來是否為一大趨勢呢?Days will tell you. 請期待……
參考文獻
[1] Scaling Language Models: Methods, Analysis& Insights from Training Gopher,arXiv:2112. 04426v1,2021
[2] //developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model
[3] //jalammar.github.io/illustrated-retrieval-transformer
[4] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
[5] K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison-Burch, and N. Carlini. Deduplicating training data makes language models better. arXiv preprint arXiv:2107.06499, 2021.
//arxiv.org/pdf/2112.09332.pdf


