Python數據分析 | Numpy與1維數組操作
- 2022 年 2 月 25 日
- 筆記
- numpy, Python, 圖解數據分析 | 從入門到精通系列, 數據分析

作者:韓信子@ShowMeAI
教程地址://www.showmeai.tech/tutorials/33
本文地址://www.showmeai.tech/article-detail/142
聲明:版權所有,轉載請聯繫平台與作者並註明出處
n維數組是NumPy的核心概念,大部分數據的操作都是基於n維數組完成的。本系列內容覆蓋到1維數組操作、2維數組操作、3維數組操作方法,本篇講解Numpy與1維數組操作。
一、向量初始化
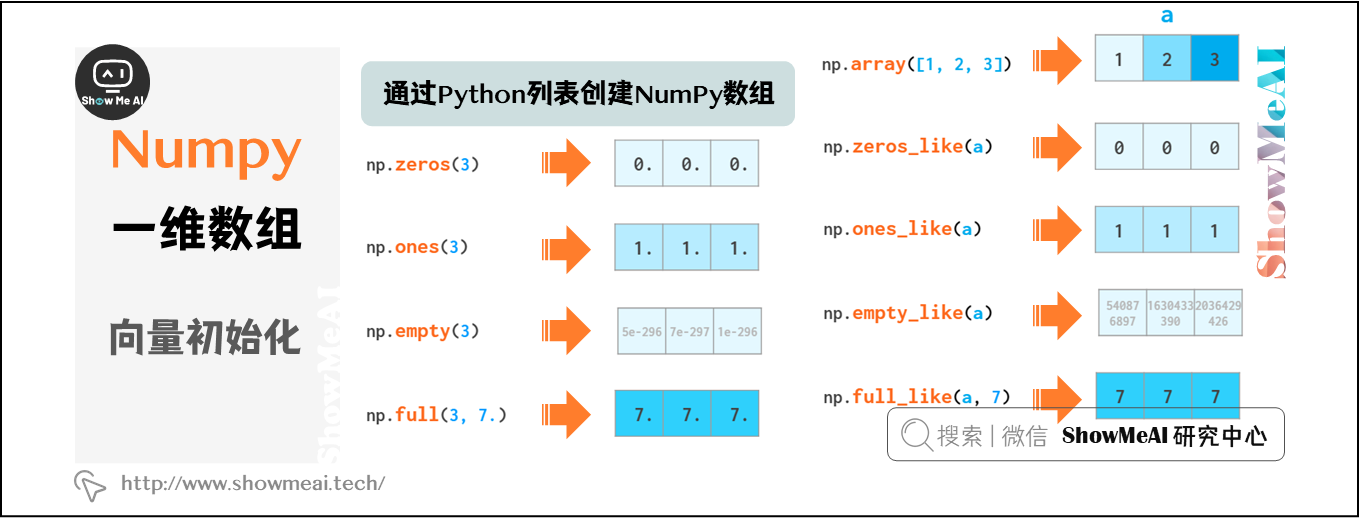
可以通過Python列表創建NumPy數組。

如圖中(a),將列表元素轉化為一維數組。注意,這裡一般會確保列表元素類型相同,否則默認dtype=』object',會影響後續運算,甚至產生語法錯誤。
由於在數組末尾沒有預留空間以快速添加新元素,NumPy數組無法像Python列表那樣增長。因此,通常的處理方式包括:
- 在變長Python列表中準備好數據,然後將其轉換為NumPy數組
- 使用
np.zeros或np.empty預先分配必要的空間(圖中b)
通過圖中(c)方法,可以創建一個與某一變量形狀一致的空數組。
不止是空數組,通過上述方法還可以將數組填充為特定值:
在NumPy中,還可以通過單調序列初始化數組:
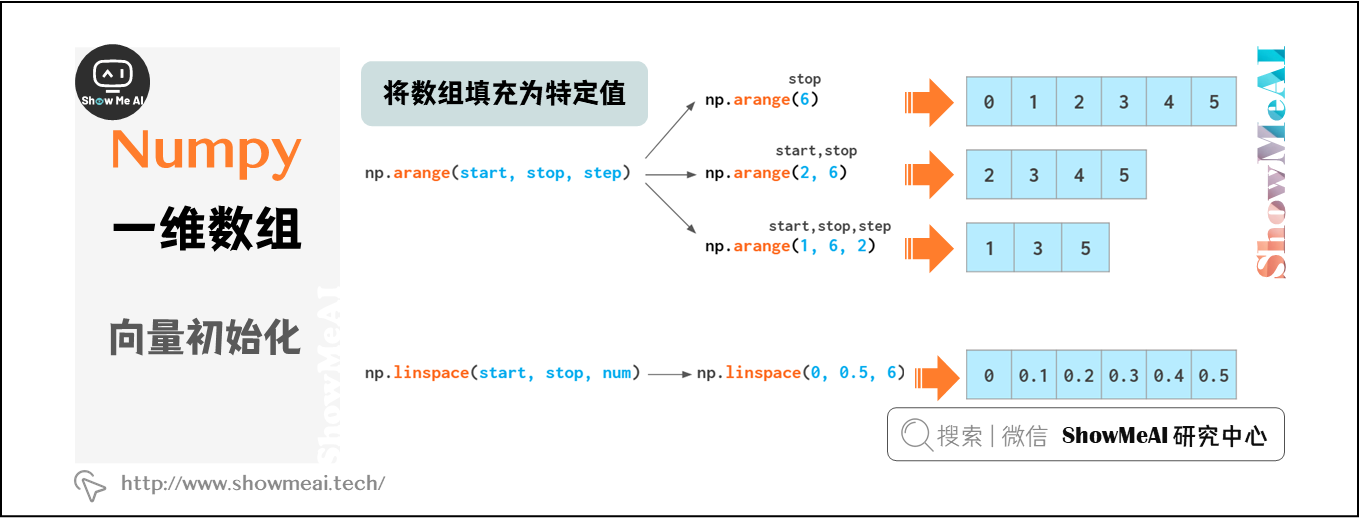
如果我們需要浮點數組,可以使用 arange(3).astype(float) 這樣的操作更改arange輸出的類型,也可以在參數端使用浮點數,比如 arange(4.) 來生產浮點數Numpy數組。
以下是arange浮點類型數據可能出現的一些問題及解決方案:
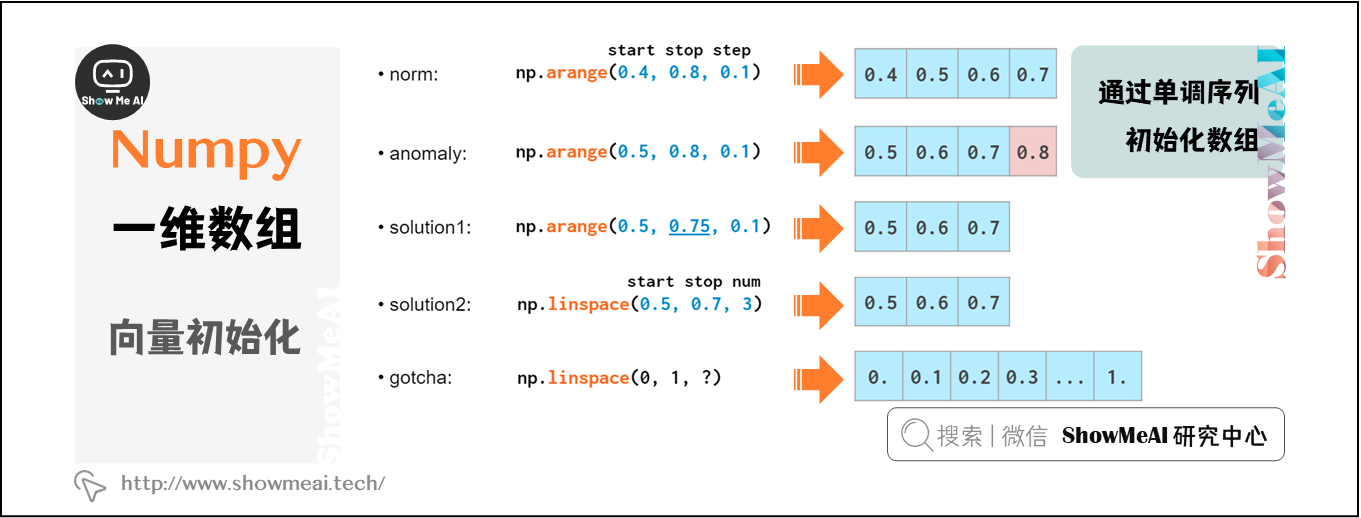
圖中,0.1對我們來說是一個有限的十進制數,但對計算機而言,它是一個二進制無窮小數,必須四捨五入為一個近似值。因此,將小數作為arange的步長可能導致一些錯誤。可以通過以下兩種方式避免如上錯誤:
- 使間隔末尾落入非整數步數,但這會降低可讀性和可維護性;
- 使用linspace,這樣可以避免四捨五入的錯誤影響,並始終生成要求數量的元素。
- 使用linspace時尤其需要注意最後一個的數量參數設置,由於它計算點數量,而不是間隔數量,因此上圖中數量參數是11,而不是10。
隨機數組的生成方法如下:

二、向量索引
NumPy可以使用非常直接的方式對數組數據進行訪問:
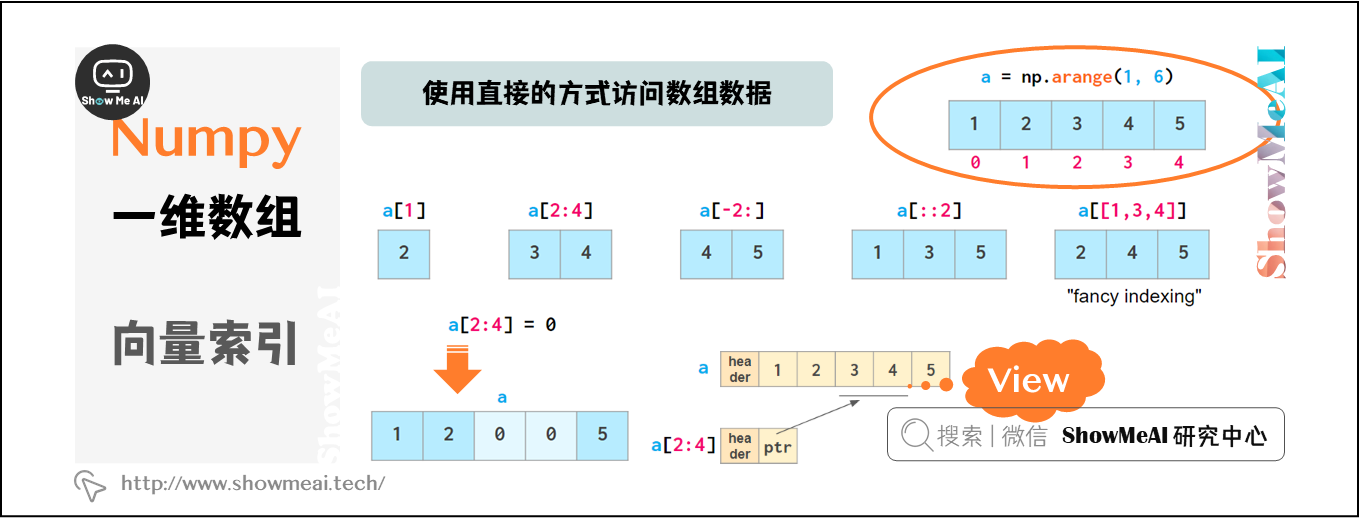
圖中,除「fancy indexing」外,其他所有索引方法本質上都是views:它們並不存儲數據,如果原數組在被索引後發生更改,則會反映出原始數組中的更改。
上述所有這些方法都可以改變原始數組,即允許通過分配新值改變原數組的內容。這導致無法通過切片來複制數組。如下是python列表和NumPy數組的對比:

NumPy數組支持通過布爾索引獲取數據,結合各種邏輯運算符可以有很高級的數據選擇方式,這在Python列表中是不具備的:
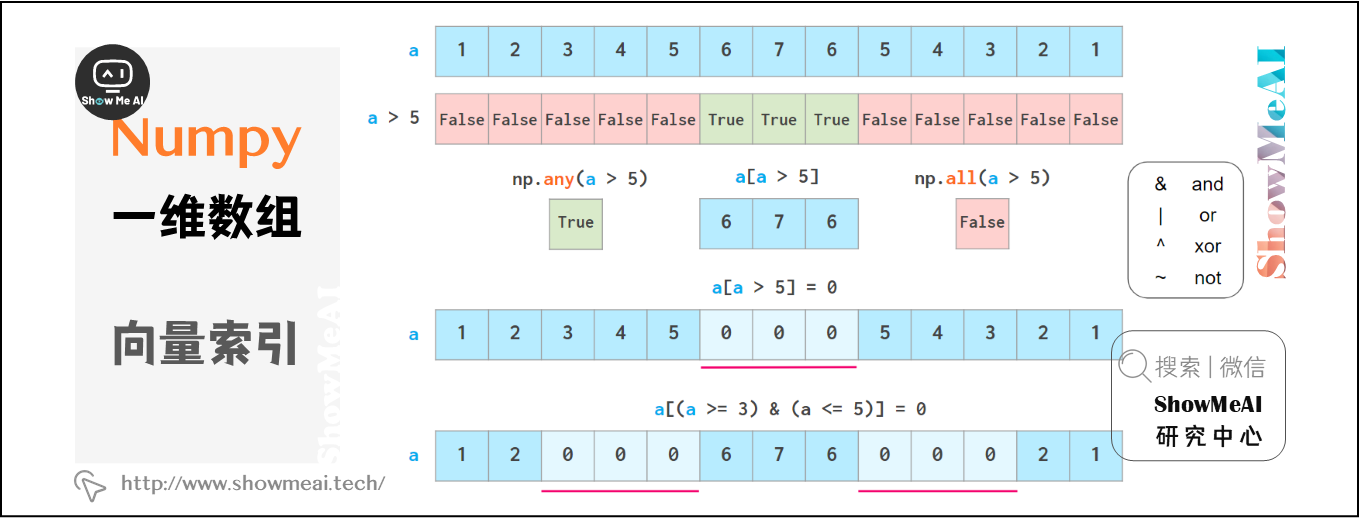
注意,不可以使用3 <= a <= 5這樣的Python「三元」比較。
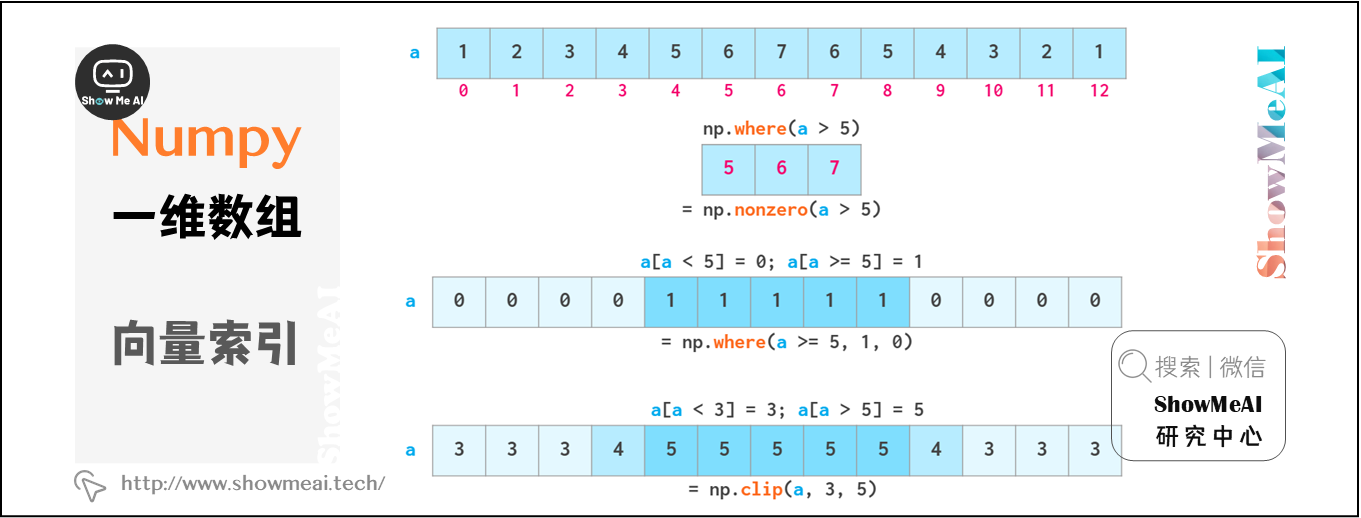
如上所述,布爾索引是可寫的。如下圖 np.where 和 np.clip 兩個專有函數。
三、向量操作
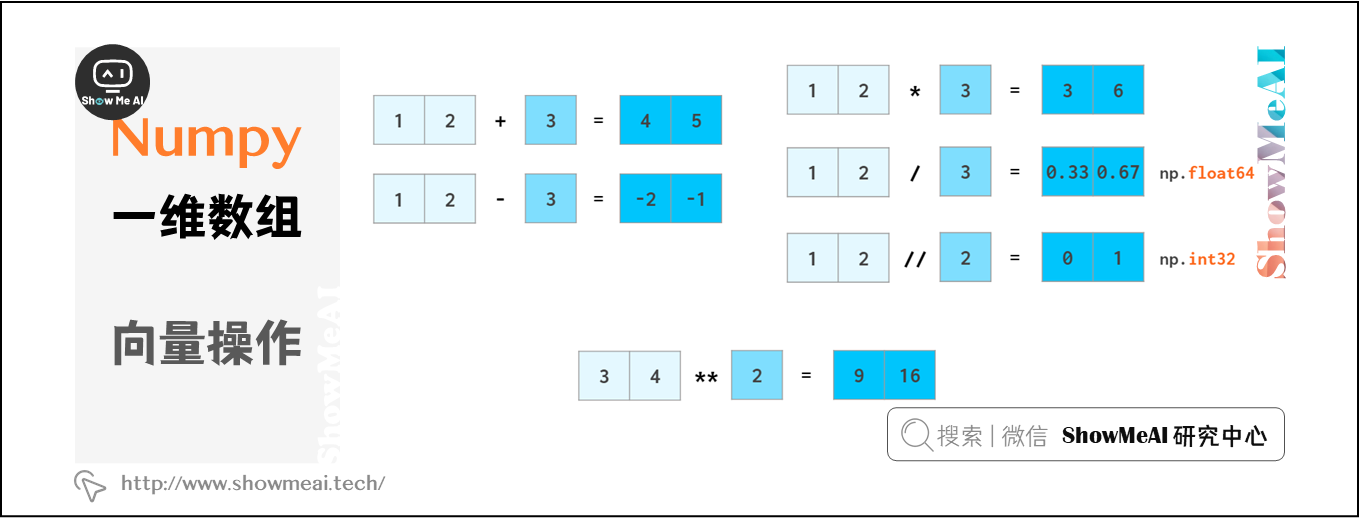
NumPy支持快速計算,向量運算操作接近C++速度級別,並不受Python循環本身計算慢的限制。NumPy允許像普通數字一樣操作整個數組:
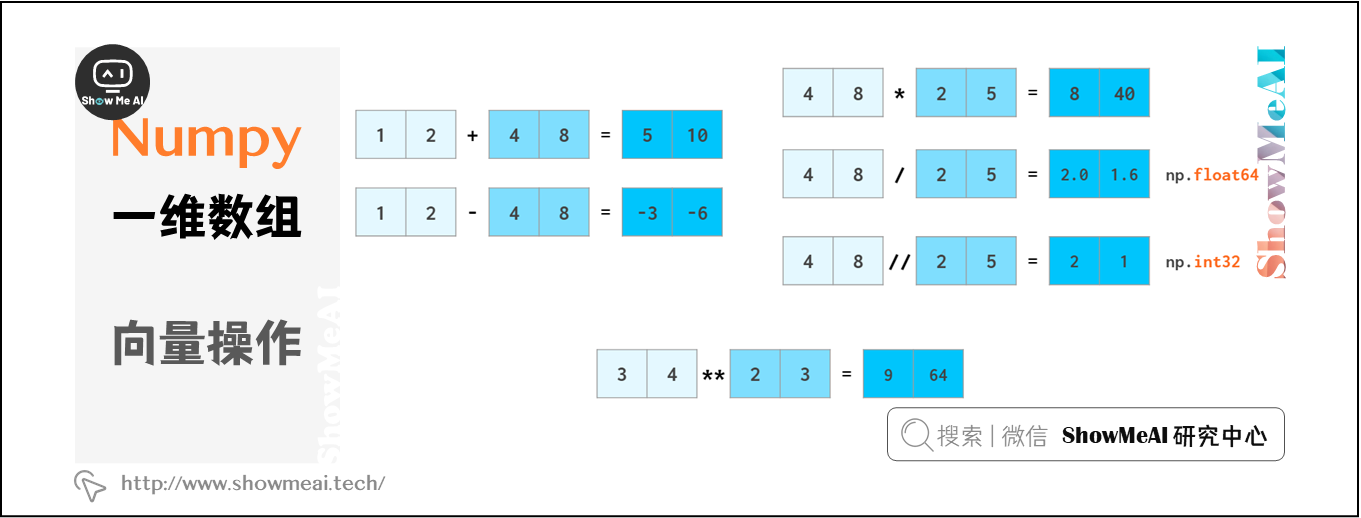
在python中,a//b表示a div b(除法的商),x**n表示 xⁿ
浮點數的計算也是如此,NumPy能夠將標量廣播到數組:
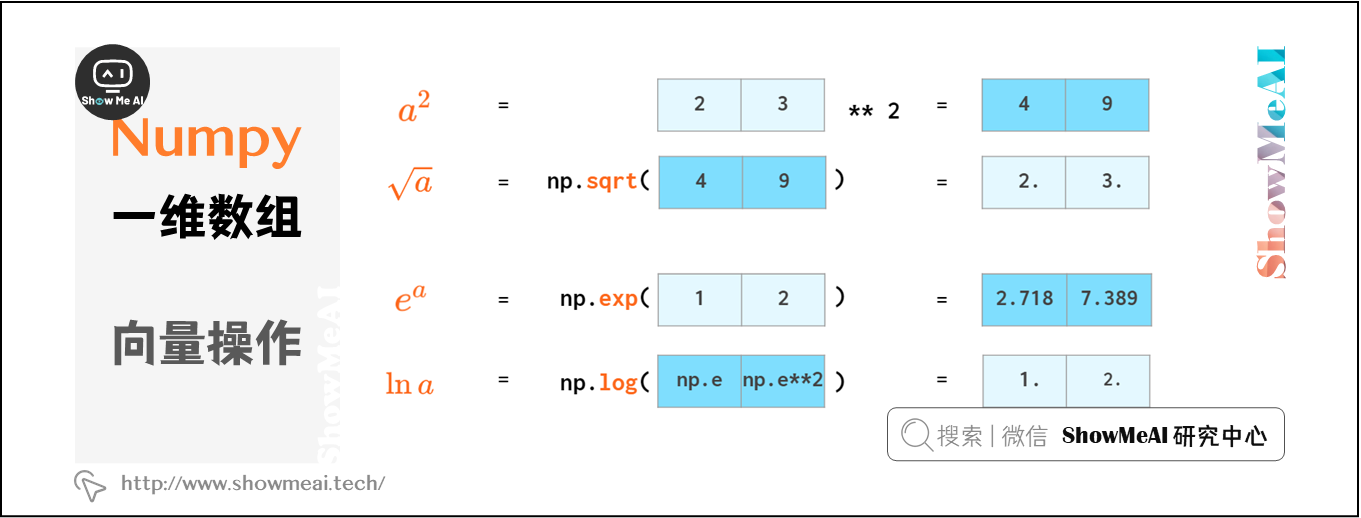
Numpy提供了許多數學函數來處理矢量:
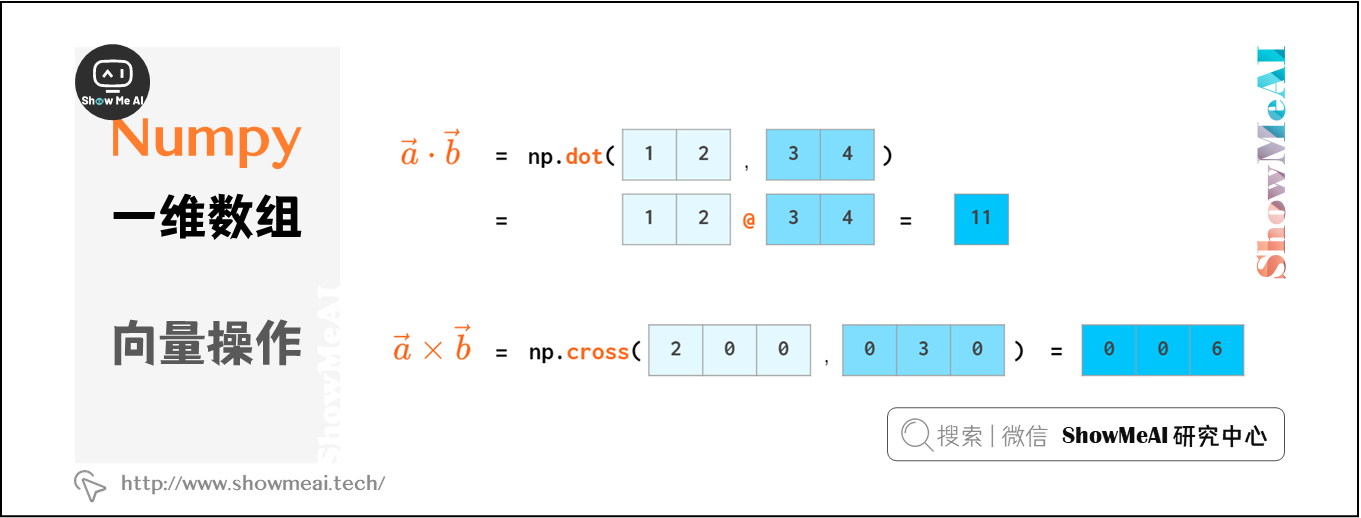
向量點乘(內積)和叉乘(外積、向量積)如下:
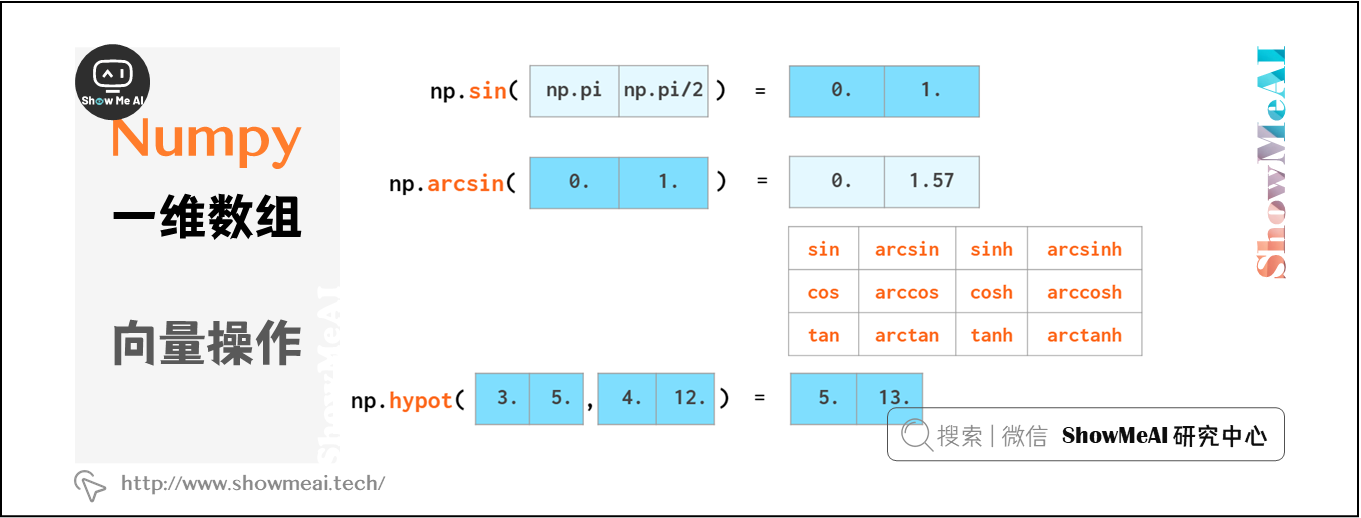
NumPy也提供了如下三角函數運算:
數組整體進行四捨五入:
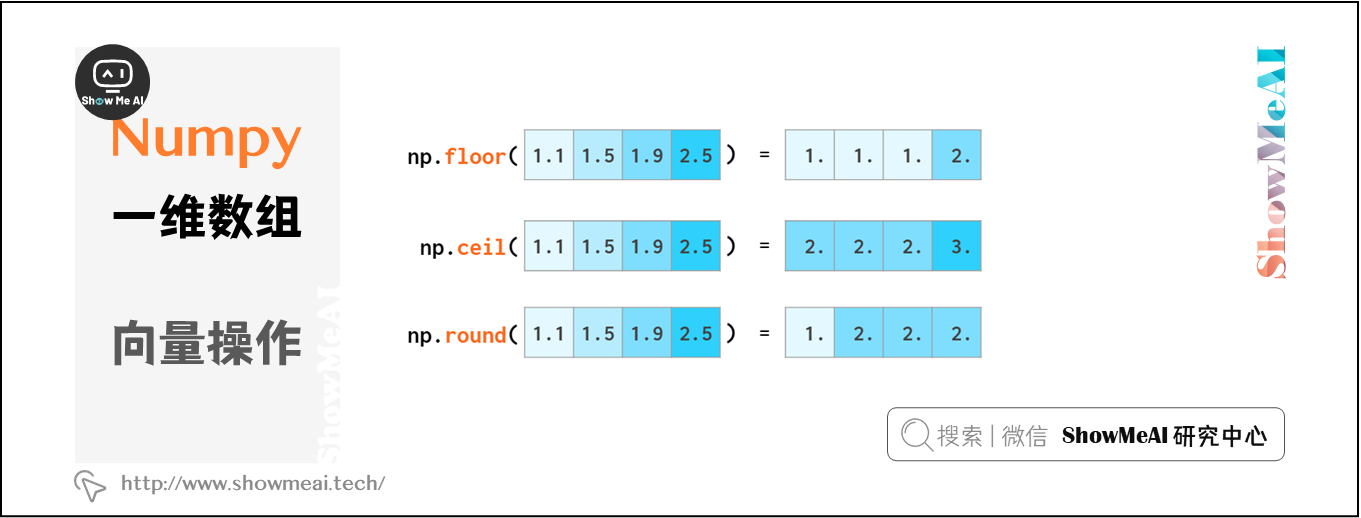
floor向上取整,ceil向下取整,round四捨五入
np.around 與 np.round 是等效的,這樣做只是為了避免 from numpy import * 時與Python around的衝突(但一般的使用方式是import numpy as np)。當然,你也可以使用a.round()。
NumPy還可以實現以下功能:

以上功能都存在相應的nan-resistant變體:例如nansum,nanmax等
在NumPy中,排序函數功能有所閹割:

對於一維數組,可以通過反轉結果來解決reversed函數缺失的不足,但在2維數組中該問題變得棘手。
四、查找向量中的元素
NumPy數組並沒有Python列表中的索引方法,索引數據的對比如下:
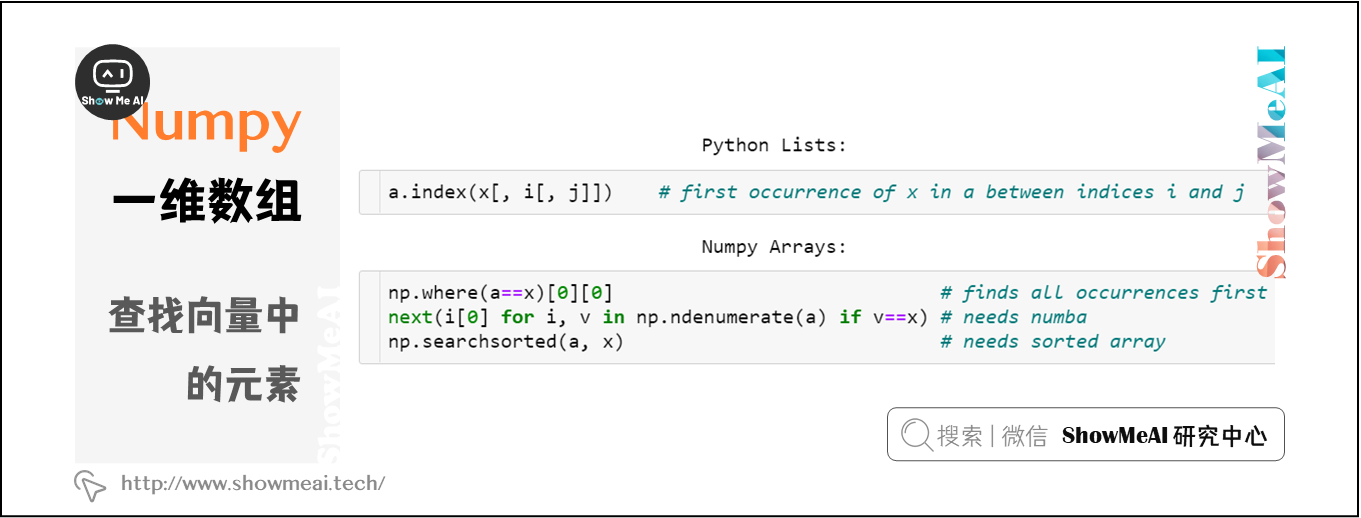
index()中的方括號表示 j 或 i&j 可以省略
- 可以通過
np.where(a==x)[0] [0]查找元素,但這種方法很不pythonic,哪怕需要查找的項在數組開頭,該方法也需要遍歷整個數組。 - 使用Numba實現加速查找,
next((i[0] for i, v in np.ndenumerate(a) if v==x), -1),在最壞的情況下,它的速度要比where慢。 - 如果數組是排好序的,使用
v = np.searchsorted(a, x);return v if a[v]==x else -1時間複雜度為O(log N),但在這之前,排序的時間複雜度為O(N log N)。
實際上,通過C實現加速搜索並不是困難,問題是浮點數據比較。
五、浮點數比較
np.allclose(a, b)用於容忍誤差之內的浮點數比較。
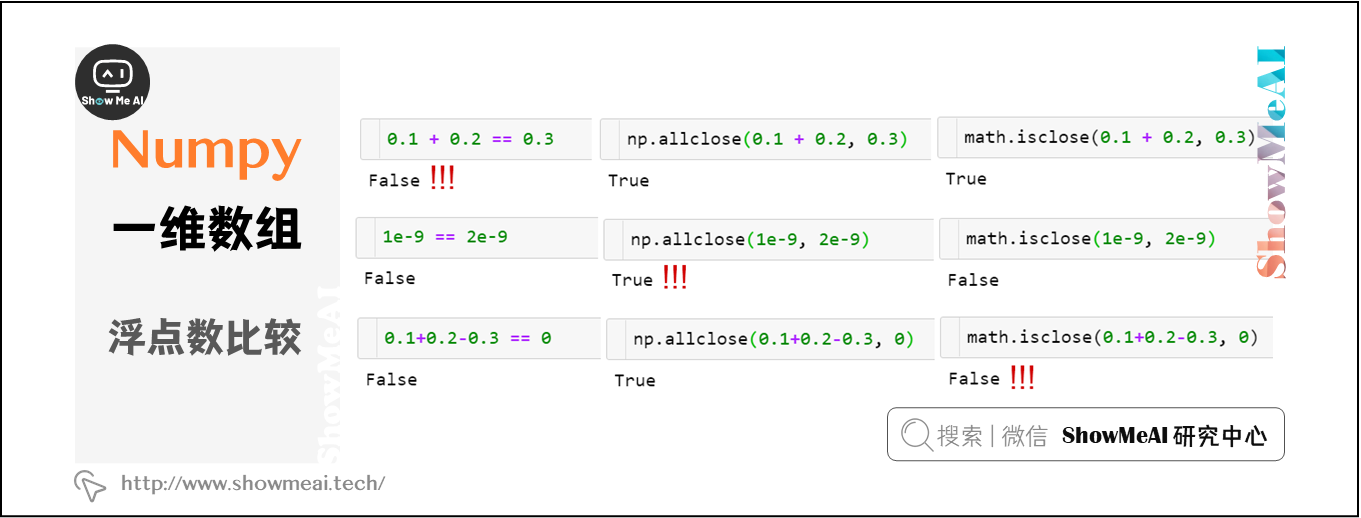
np.allclose假定所有比較數字的尺度為1。如果在納秒級別上,則需要將默認atol參數除以1e9:np.allclose(1e-9,2e-9, atol=1e-17)==False。math.isclose不對要比較的數字做任何假設,而是需要用戶提供一個合理的abs_tol值(np.allclose默認的atol值1e-8足以滿足小數位數為1的浮點數比較,即math.isclose(0.1+0.2–0.3, abs_tol=1e-8)==True。
此外,對於絕隊偏差和相對偏差,np.allclose依然存在一些問題。例如,對於某些值a、b, allclose(a,b)!=allclose(b,a),而在math.isclose中則不存在這些問題。查看GitHub上的浮點數據指南和相應的NumPy問題了解更多信息。
資料與代碼下載
本教程系列的代碼可以在ShowMeAI對應的github中下載,可本地python環境運行,能訪問Google的寶寶也可以直接藉助google colab一鍵運行與交互操作學習哦!
本系列教程涉及的速查表可以在以下地址下載獲取:
拓展參考資料
ShowMeAI相關文章推薦
- 數據分析介紹
- 數據分析思維
- 數據分析的數學基礎
- 業務認知與數據初探
- 數據清洗與預處理
- 業務分析與數據挖掘
- 數據分析工具地圖
- 統計與數據科學計算工具庫Numpy介紹
- Numpy與1維數組操作
- Numpy與2維數組操作
- Numpy與高維數組操作
- 數據分析工具庫Pandas介紹
- 圖解Pandas核心操作函數大全
- 圖解Pandas數據變換高級函數
- Pandas數據分組與操作
- 數據可視化原則與方法
- 基於Pandas的數據可視化
- seaborn工具與數據可視化
ShowMeAI系列教程推薦



