「數據分析」2種常見的反爬蟲策略,信息驗證和動態反爬蟲
- 2022 年 2 月 23 日
- 筆記
©作者 | leo
01 什麼是爬蟲?
爬蟲,見名知義,就好似一個探索的小機械人,模擬人的行為,擴散到網絡的各個角落,按照一定的規則搜集整理數據,並且將他們反饋回來。這是一個很形象的方式來描述爬蟲的原理。
技術角度,爬蟲主要是根據一定的程序規則或者技術指標,通過網絡請求的方式來獲取資源,然後對獲取的資源通過一定的解析手段提取所要信息並存儲的過程。
02 為什麼會產生反爬蟲?
你見過的最變態的驗證碼是什麼呢?是要考察小學數學的驗證碼,還是考察人文知識的驗證碼,現在越來越多的奇葩驗證碼的出現,在一定程度上給我們這些訪客帶來了很多不便,但是它們的出現真正的目的並不是給用戶增加使用難度,而是為了防止大多數的無節制訪問的爬蟲程序。
爬蟲程序的訪問速度和目的是很容易被發現與正常用戶的區別的,大多數爬蟲具有無節制,大批量對訪問目標進行爬取的行為,這些訪問請求會對訪問目標帶來巨大的服務器壓力和不必要的資源投入,因此常被運營者定義為『垃圾流量』。
因此,為了更好的維護自身的利益,營業者就會針對爬蟲的特點應用不同的手段來防止大批量爬蟲的訪問。
根據反爬的出發點,可以將反爬限制手段分為:
• 主動型限制:開發者會通過技術手段主動的限制爬蟲的訪問請求,如:驗證請求頭信息,限制同ip的重複訪問,驗證碼技術等等
• 被動型限制:開發者為了節省訪問資源的同時也不降低用戶體驗,採用了間接的技術手段限制爬蟲訪問的方法,如:網頁動態加載,數據分段加載,鼠標懸停預覽數據等等。
• 而從具體的反爬蟲實現手段上來進行劃分,則可大致分為:信息驗證型反爬蟲,動態渲染型反爬蟲,文本混淆型反爬蟲,特徵識別型反爬蟲。爬蟲與反爬蟲無異於一場攻防博弈,既有競爭關係,也有相互促進的可能。
常見的反爬策略以及應對措施:
信息校驗型爬蟲:
a. User-Agent發爬蟲:
基本原理:能夠向服務器端發送請求的客戶端形式多種多樣,既可以是不同型號的個人電腦,手機,平板電腦,編程程序,也可以是網絡請求軟件,那麼服務器該如何識別這些不同的客戶端呢?
User-Agent便是這樣一個用戶發送請求時附帶的請求信息的記錄。它的主要格式包括如下幾個部分:
**瀏覽器標識(操作系統標識,加密等級標識;瀏覽器語言)渲染引擎標識 版本信息**
例如:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
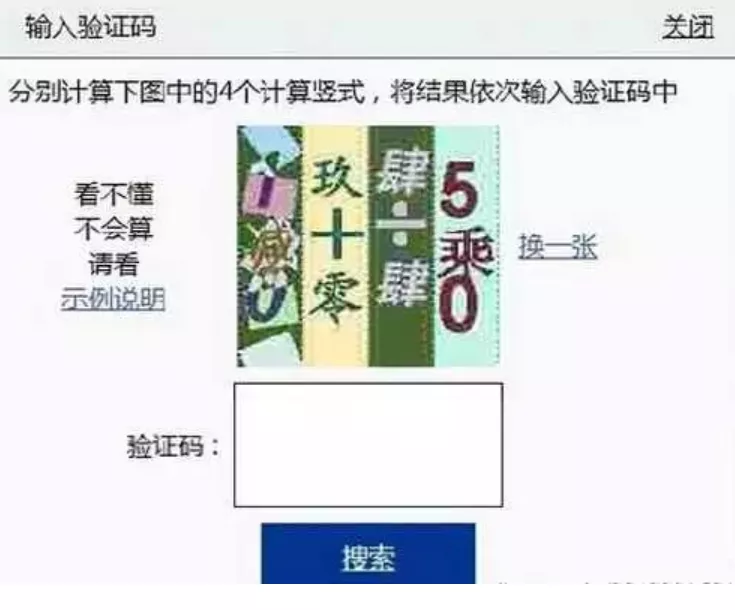
而User-Agent的反爬主要就是通過對User-Agent的頭域值進行校驗,如果存在黑名單中的值,就會被服務器端封殺。
例如我們Python中常用的Requests庫,如果在發送請求時不做Headers參數設置,則服務器讀取User-Agent的值就是python-requests/2.21.0
b. Cookies反爬蟲
Cookies不僅能夠用於存儲Web用戶的身份信息或者保持登錄狀態,此外也會被用作反爬蟲的識別信息。
主要的原理是客戶端訪問服務器時,服務器會返回Set-Cookie頭域,客戶端會將該信息進行存儲,再次進行訪問服務器時會攜帶對應的Cookie信息,這時服務器端只要驗證該Cookie是否符合規則就可以了,如果不符合,則會被重定向到其他頁面,並在響應中添加Set-Cookie頭域和Cookie值。
以上驗證Cookie的方法僅僅是比較簡單的反爬機制,爬蟲工程師僅僅需要在瀏覽器的請求頭中複製該Cookie即可輕鬆規避,這時Cookie驗證常常要結合javascript文件,生成隨機Cookie值進行校驗:
**Cookie名稱+3位小於9的隨機正整數+5位隨機大寫字母+6位小於9的正整數+3位隨機大寫字母**
該機制還是有可以反覆使用的可能性,即使加上Cookie過期時間也不能完全保證Cookie的復用,這時需要引入時間戳結合上述方法進行進一步判定,當Cookie值取出時的時間戳和當前時間戳進行差值計算,超過一定時間,就會被認定為偽造。
c. 簽名驗證反爬蟲:
主要原理時通過客戶端生成的一些隨機數和不可逆的MD5加密字符串,在發送請求時發送給服務器,服務器端使用相同方式進行隨機值運算並做MD5加密,如果服務器端得到的MD5值和前端的MD5值相等,則表示請求正常,否則返回403.
目前該反爬蟲方式廣泛應用於各類大型網站,繞過它不僅需要從XHR信息中找到相關的請求信息,此外還要在Javacript代碼中尋找加密的方式。
動態渲染反爬蟲:
動態網頁往往是為了提升用戶體驗,節約資源消耗,提升響應速度而應用的技術,並非直接針對爬蟲程序來進行的反爬措施,但是在不經意間產生了反爬蟲的效果,爬蟲程序不具備頁面渲染功能,而一旦遇到動態渲染頁面,則不能完整的返回需要的信息。
比如我們要爬取英雄聯盟裏面的英雄名稱和下載對應圖片時,按照原有的爬取方式,使用requests庫來進行爬取,會發現獲取的字段均為空值,這主要的原因是該網站使用了javacript動態加載技術,只有找到核心的js傳輸代碼,才能找到對應信息。
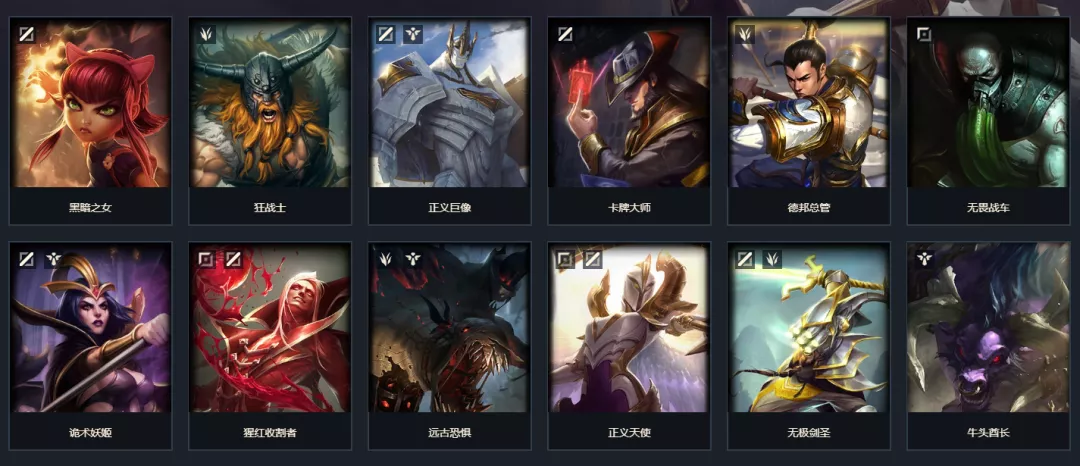
通過網頁檢查工具我們可以清晰的看到,hero_list.js這個文件存儲了所有的英雄信息,以及對應的英雄圖片鏈接和詳情頁信息。
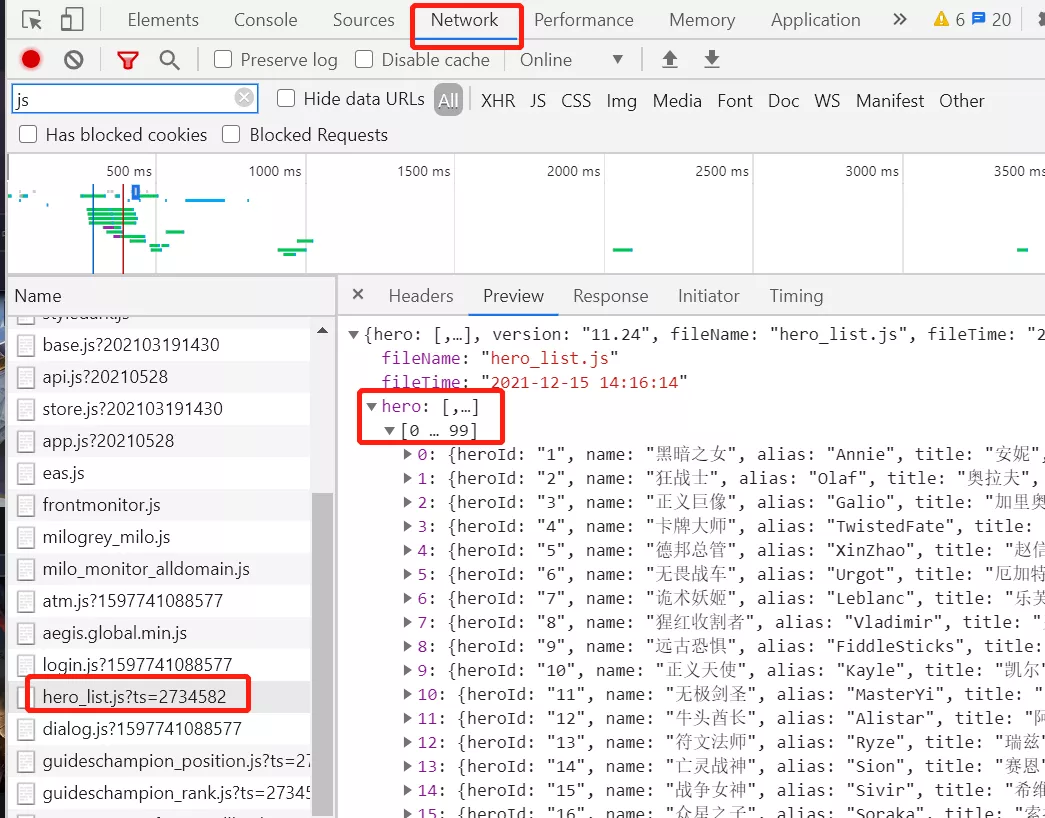
那麼我們在進行信息解析時,就需要針對該js文件進行。
動態渲染的主要解決思路:
動態渲染技術組合非常靈活,如果每次遇到這樣的網站,我們都要去分析接口,參數和javascript代碼邏輯,那麼耗費的時間成本就會高很多。那麼能夠直接的提取渲染後的結果頁面對於爬蟲分析就會簡單很多,目前主要的渲染提取工具包括:Puppeter,Selenium,Splash。
2.1 Selenium
Selenium是我們最為常用的一種解決動態渲染的技術。
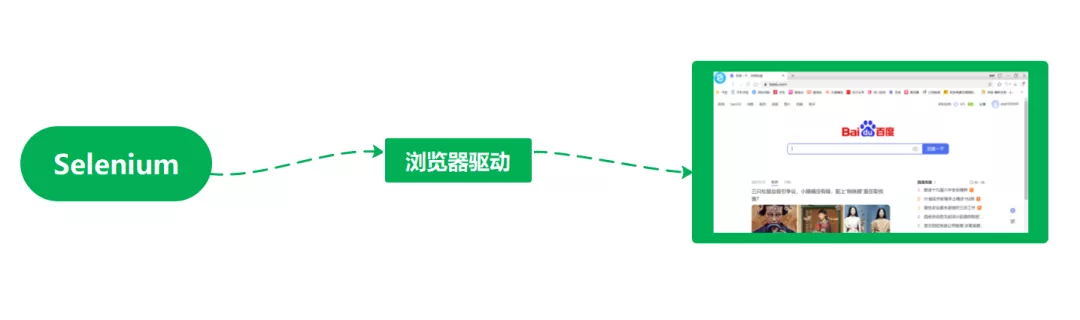
瀏覽器驅動是Selenium對瀏覽器發送指令或者傳遞渲染結果的主要工具。
目前該驅動一般是通過下面網址下載的:
[//npm.taobao.org/mirrors/chromedriver/](//npm.taobao.org/mirrors/chromedriver/)
我們通過簡單的代碼就可以實現對應信息的提取。
from selenium import webdriver
url = '//www.udemy.com/course/network-security-course/'
driver = webdriver.Chrome()
res = driver.get(url)
course = driver.find_element_by_css_selector('.clp-lead__title').text.replace('\n','')
print(course)
driver.quit()
2.2 Puppeter
在使用Selenium進行數據爬取時,如果遇到大批量任務執行時,顯然要花費較長時間,這時我們會引入異步加載提取數據的方法,那就是Puppeter方法,它是google開源的Node庫,除了擁有一套高級的API來控制瀏覽器,還提供了很多替代手動執行的操作方法,最重要的是它還支持異步。
import asyncio
from pyppeter import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('//www.udemy.com/course/network-security-course/')
res = await page.xpath("//*[@class='clp-lead__title']")
text = await(await res[0].getProperty('textContent')).jsonValue()
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2.3 分佈式渲染服務Splash
Splash應用於分佈式爬取需求,假設我們要在更多個機器中運行爬蟲程序,還能否通過安裝Puppeter和Selenium組件來完成呢?顯然是否定的。
Splash是一個異步的Js渲染服務,自帶輕量級web瀏覽器,當我們將它部署在雲端時,就可以通過同個API使多個爬蟲程序訪問渲染的頁面了。
動態網頁的廣泛應用除了為了提高用戶體驗,也在一定程度限制了爬蟲程序的使用,而結合動態渲染技術進行頁面解析解決了80%以上的複雜頁面的爬取,但是效率卻遠不及直接解析javascript文件快速,而尋找網站入口、js文件的定位往往也會耗費大量的時間,因此具體的技術使用需要根據實際情況靈活使用。
03 文本混淆反爬蟲
文本混淆可以有效的避免爬蟲獲取Web應用中的文字數據,通過混淆文本信息來限制爬蟲獲取數據的技術手段稱為文本混淆反爬蟲。
文本混淆反爬蟲的前提是不影響正常用戶的使用體驗,因此文本混淆不能直接的展現出來,所以開發者通常是利用CSS特性來實現混淆。
常見的文本混淆方法包括:圖片偽裝、文字映射和自定義字體
3.1 圖片偽裝
該方法是使用圖片來替換原有的文字信息,使得直接的文字提取方法失效。比如:電話
<table>
<tbody>
<tr>
<td> 電話</td>
<td><img src='phonenumber.png' class='pn'></td>
</tr>
</tbody>
</table>
該段代碼為某網站截取代碼,通過圖片的方式將原本為文本的電話號碼進行了偽裝,因此如果想要獲取該信息,簡單的爬蟲手段是不可能實現的,那麼主要的應對措施是什麼呢?
這裡主要需要的是光學字符識別技術,對於沒有像素干擾的純文本信息可以很容易實現,在python中我們主要使用PyTesseract庫來實現圖片文字的提取。
3.2 SVG映射反爬蟲
SVG是一種基於XML描述圖形的二維矢量圖形格式,對該圖形放大縮小都不會影響圖形質量。這個特點被廣泛應用於Web網站中。
使用SVG映射反爬蟲主要原理是通過不同字符串與不同數字進行映射,服務器在進行數據解析時,做相關處理,再由瀏覽器進行渲染,最終實現隱藏信息的目的。
而繞過SVG映射可以通過提取相關信息進行數據對應的方法來解決,如下圖,我們通過找到html代碼中類對映數字的映射關係,最終得到了電話號碼信息。
mappings = {
'vhk08k':0, 'vhk6zl':1,'vhk9or':2,'vhkfln':3,'vhkbvu':4,'vhk84t':5,'vhkvxd':6,
'vhkqsc':7,'vhkkj4':8,'vhk0f1':9,
}
html_class = ['vhkbvu','vhk08k','vhkfln','vhk0f1']
phone_num = [mappings.get(i) for i in html_class]
print(phone_num)
目前主流反爬蟲技術展現:
除了以上的爬蟲技術,目前還包括了常見的驗證碼識別反爬蟲,它的主要實現機理就是通過各種動態生成的驗證碼,來阻止爬蟲訪問網頁信息,那麼繞過驗證碼也是目前的一個技術難點,傳統的字符圖形驗證碼可以通過光學識別來解決,而對於動態滑塊驗證碼、邏輯運算驗證碼則要結合多種技術才能夠實現。
另外一種比較常見的反爬蟲是特徵識別反爬蟲,如果你嘗試過爬取Boss直聘網頁信息,就會發現無論你使用常規的爬取方法或者使用Selenium動態渲染工具,亦或者分析Javascript文件,基本不能夠有效的提取相關數據,返回值都是空值,這主要的原因就是目標站採用WebDriver特徵識別,主要原理就是反爬蟲程序能夠識別發送請求的客戶端的webdriver屬性是否是通過webdriver驅動瀏覽器來進行訪問的,那麼繞過方法也是圍繞這個屬性展開,對於webdriver檢測主要的結果有三種:true,false,undefined,當我們使用渲染工具具有webdriver屬性時,返回值就是true,那麼我在觸發驗證該屬性前將它修改為false或者underfined就可以規避這種識別。
以上就是對目前主流常見的反爬技術和繞過策略的簡單闡述,在這場攻守博弈中,核心思想都是如何去分析對方的實現機理,才能更好的想到解決方案,當然裏面也涉及很多深入的理論知識,同時也有大量的人為邏輯陷阱在其中,因此掌握爬蟲技術,實踐和理論學習都是同等重要的。
目前主流反爬蟲技術展現:
除了以上的爬蟲技術,目前還包括了常見的驗證碼識別反爬蟲,它的主要實現機理就是通過各種態生成的驗證碼,來阻止爬蟲訪問網頁信息,那麼繞過驗證碼也是目前的一個技術難點,傳統的字符圖形驗證碼可以通過光學識別來解決,而對於動態滑塊驗證碼、邏輯運算驗證碼則要結合多種技術才能夠實現。
另外一種比較常見的反爬蟲是特徵識別反爬蟲,如果你嘗試過爬取Boss直聘網頁信息,就會發現無論你使用常規的爬取方法或者使用Selenium動態渲染工具,亦或者分析Javascript文件,基本不能夠有效的提取相關數據,返回值都是空值。
這主要的原因就是目標站採用WebDriver特徵識別,主要原理就是反爬蟲程序能夠識別發送請求的客戶端的webdriver屬性是否是通過webdriver驅動瀏覽器來進行訪問的。
那麼繞過方法也是圍繞這個屬性展開,對於webdriver檢測主要的結果有三種:true,false,undefined,當我們使用渲染工具具有webdriver屬性時,返回值就是true,那麼我在觸發驗證該屬性前將它修改為false或者underfined就可以規避這種識別。
以上就是對目前主流常見的反爬技術和繞過策略的簡單闡述,在這場攻守博弈中,核心思想都是如何去分析對方的實現機理,才能更好的想到解決方案,當然裏面也涉及很多深入的理論知識,同時也有大量的人為邏輯陷阱在其中,因此掌握爬蟲技術,實踐和理論學習都是同等重要的。


