RelationNet++:基於Transformer融合多種檢測目標的表示方式 | NeurIPS 2020
論文提出了基於注意力的BVR模塊,能夠融合預測框、中心點和角點三種目標表示方式,並且能夠無縫地嵌入到各種目標檢測算法中,帶來不錯的收益
來源:曉飛的算法工程筆記 公眾號
論文: RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder

Introduction
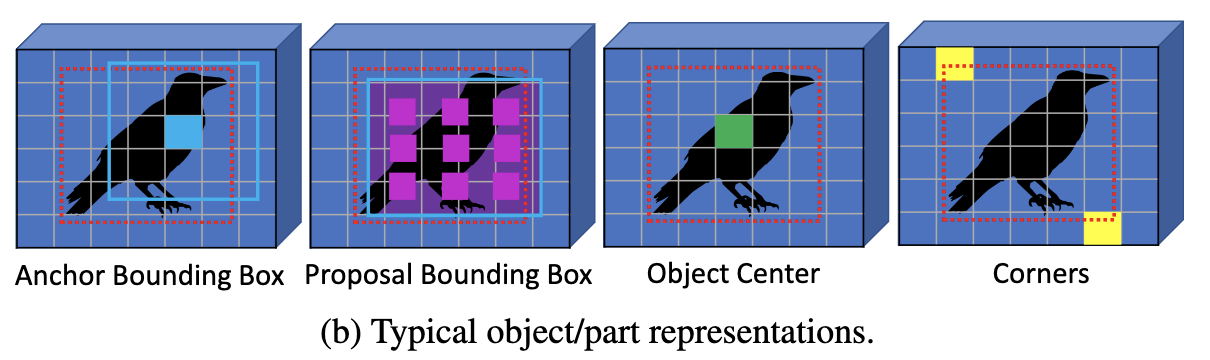
目標檢測算法有很多種目標表示方法,如圖b所示,有基於矩形框的也有基於關鍵點的。不同的表示方法使得檢測算法在不同的方面表現更優,比如矩形框能更好的對齊標註信息,中心點更利於小目標識別,角點則能夠更精細地定位。論文探討能否將多種表示方式融合到單框架中,最終提出了基於注意力的解碼模塊BVR(bridging visual representations),該模塊與Transformer的注意力機制類似,通過加權其它目標特徵來增強當前目標特徵,能夠融合不同表示方式的異構特徵。

以BVR嵌入anchor-based方法為例,如圖a所示,表示方式acnhor作為query,其它表示方式中心點和角點作為key,計算query和key間關聯性權重,基於權重整合key的特徵來增強query的特徵。針對目標檢測的場景,論文對權重計算進行了加速,分別為key sampling和shared location embedding,用於減少key的數量以及權重計算量。除了嵌入到anchor-based方法外,BVR也可嵌入到多種形式的目標檢測算法中。
論文的貢獻如下:
- 提出通用模塊BVR,可融合不同目標表示方式的異構特徵,以in-place的方式嵌入到各種檢測框架,不破壞原本的檢測過程。
- 提出BVR模塊的加速方法,key sampling和shared location embedding。
- 經測試,在ReinaNet、Faster R-CNN、FCOS和ATSS四個檢測器上有明顯的提升。
Bridging Visual Representations

使用不同表示方式的檢測算法有不同的檢測流程,如圖2所示,BVR注意力模塊以算法原本的表示方式為主特徵,加入其它表示方式作為輔助特徵。將主特徵query和輔助特徵key作為輸入,注意力模塊根據關聯性加權輔助特徵來增強主特徵:

f^q_i,f^{‘q}_i,g^q_i為第i個query實例的輸入特徵,輸出特徵和幾何向量,f^k_j,g^k_j為第j個key實例的輸入特徵和幾何向量,T_v(\cdot)為線性變化,S(\cdot)為i和j實例間的關聯性計算:

S^A(f^q_i, f^k_j)為外觀特徵相似度,計算方法為scaled dot product。S^G(g^q_i, g^k_j)為幾何位置相關的項,先將相對的幾何向量進行cosine/sine位置embedding,再通過兩層MLP計算關聯度。由於不同表示方式的幾何向量(4-d預測框與2-d點)不同,需從4-d預測框提取對應的2-d點(中心或角點),這樣兩種不同表示方式的幾何向量就對齊了。
在實現時,BVR模塊採用了類似multi-head attention的機制,head數量默認為8,即公式1的+號後面改為Concate多個關聯特徵的計算,每個關聯特徵的維度為輸入特徵的1/8。
BVR for RetinaNet

以RetinaNet為例,RetinaNet在特徵圖的每個位置設置9個anchor,共有$9\times H\times W個預測框,BVR模塊將C\times 9\times H\times W特徵圖作為輸入(C為特徵圖維度),生成相同大小的增強特徵。如圖a所示,BVR使用中心點和角點作為輔助的key$特徵,關鍵點通過輕量級的Point Head網絡預測,然後選擇少量的點輸入到注意力模塊中增強分類特徵和回歸特徵。
Auxiliary (key) representation learning
Point Head網絡包含兩層共享的$3\times 3卷積,然後接兩個獨立的子網($3\times 3卷積+sigmoid),預測特徵圖中每個位置為中心點(或角點)的概率及其相應的偏移值。如果網絡包含FPN,則將所有GT的中心點和角點賦予各層進行訓練,不需根據GT大小指定層,這樣能夠獲取更多的正樣本,加快訓練。
Key selection
由於BVR模塊使用了角點和中心作為輔助表示方式,特徵圖的每個位置會輸出其為關鍵點的概率。如果將特徵圖的每個位置都作為角點和中心點的候選位置,會生成超大的key集,帶來大量的計算消耗。此外,過多的背景候選者也會抑制真正的角點和中心點。為了解決上述問題,論文提出top-k(默認為50)key選擇策略,以角點選擇為例,使用stride=1的$3\times 3$MaxPool對角點分數圖進行轉換,選取top-k分數位置進行後續計算。對於包含FPN的網絡,則選擇所有層的top-k位置,輸入BVR模塊時不區分層。
Shared relative location embedding
對於每組query和key,公式2的幾何項需要對輸入的相對位置進行cosine/sine embedding以及MLP網絡轉換後再計算關聯度。公式2的幾何項的幾何複雜度和內存複雜度為\mathcal{O}(time)=(d_0+d_0d_1+d_1G)KHW和\mathcal{O}(memory)=(2+d_0+d_1+G)KHW,d_0,d_0,G,K分別為cosine/sine embedding維度,MLP網絡內層的維度、multi-head attention模塊的head數量以及選擇的key數量,計算量和內存佔用都很大。

由於幾何向量的相對位置範圍是有限的,一般都在[-H+1, H-1]\times [-W+1, W-1]範圍內,可以預先對每個可能的值進行embedding計算,生成G維幾何圖,然後通過雙線性採樣獲得key/query對的值。為了進一步降低計算量,設定幾何圖的每個位置代表原圖U=\frac{1}{2}S個像素,S為FPN層的stride,這樣$400\times 400的特徵圖就可表示[-100S, 100S)\times [-100S, 100S)的原圖。計算量和內存消耗也降低為\mathcal{O}(time)=(d_0+d_0d_1+d_1G)\cdot 400^2+GKHW和\mathcal{O}(memory)=(2+d_0+d_1+G)\cdot 400^2+GKHW$。
Separate BVR modules for classification and regression
目標中心點表示方式可提供豐富目標類別信息,角點表示方式則可促進定位準確率。因此,論文分別使用獨立的BVR模塊來增強分類和回歸特徵,如圖a所示,中心點用於增強分類特徵,角點用於增強回歸特徵。
BVR for Other Frameworks

論文也在ATSS、FCOS和Faster R-CNN上嘗試BVR模塊的嵌入,ATSS的接入方式跟RetinaNet一致,FCOS跟RetinaNet也類似,只是將中心點作為query表示方式,而Faster R-CNN的嵌入如圖4所示,使用的是RoI Aligin後的特徵,其它也大同小異。
Experiment



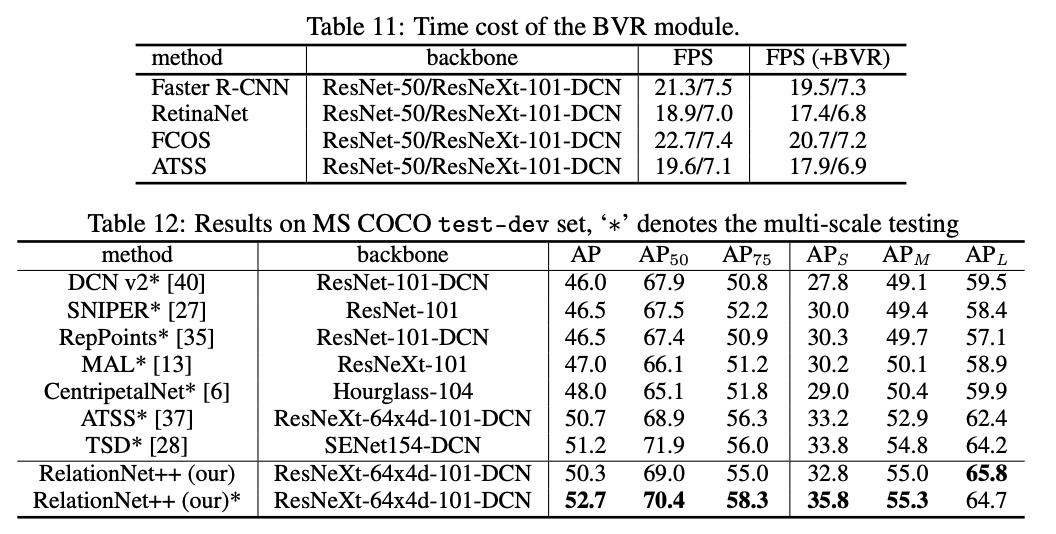
論文進行了充足的對比實驗,可到原文看看具體的實驗步驟和關鍵結論。
Conclusion
論文提出了基於注意力的BVR模塊,能夠融合預測框、中心點和角點三種目標表示方式,並且能夠無縫地嵌入到各種目標檢測算法中,帶來不錯的收益。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的算法工程筆記】