5分鐘了解數據結構
老外真的很喜歡創造新名詞。春節的時候我給我姐選顯示器,因為我姐是做設計的,我特地研究了一下顯示器的色域。我發現除了我們常用的sRGB外,還有個Adobe RGB。後來經過了解,原來是Photoshop的工程師在參考其他色彩標準的時候搞錯了參數,後來懶得改了,便自己申請了專利,搞成了一個新的色彩標準,後來隨着Adobe軟件的流行現在已經變成了行業標準。因為老外不厭其煩的創造新名詞,給我們造成了不小的困擾。比如面試的時候,面試官問你AVL樹,你知道什麼是平衡二叉樹,不知道什麼是AVL樹,面試官知道問AVL樹,卻不知道問平衡二叉樹,結果大家面面相覷。世界上最遠的距離,莫過於你跟面試官背的不是同一套八股文。以後遇到這樣的面試官,不妨問下他什麼是基數樹。基數樹不知道嗎,那trie樹總該知道吧,trie樹也不知道的話字典樹總該知道吧,字典樹也不知道那前綴樹總該知道吧。相信面試官會被問的懷疑人生。
言歸正傳,來講一下數據結構,下面是百度百科對數據結構的定義:
數據結構(data structure)是帶有結構特性的數據元素的集合,它研究的是數據的邏輯結構和數據的物理結構以及它們之間的相互關係,並對這種結構定義相適應的運算,設計出相應的算法,並確保經過這些運算以後所得到的新結構仍保持原來的結構類型。簡而言之,數據結構是相互之間存在一種或多種特定關係的數據元素的集合,即帶「結構」的數據元素的集合。「結構」就是指數據元素之間存在的關係,分為邏輯結構和存儲結構。
數據的邏輯結構和物理結構是數據結構的兩個密切相關的方面,同一邏輯結構可以對應不同的存儲結構。算法的設計取決於數據的邏輯結構,而算法的實現依賴於指定的存儲結構。
不知道大家覺得好不好理解,簡單說來,計算機基本上就做兩件事:存儲數據和處理數據。數據結構,是老外總結出來的一套行之有效的數據存儲方式,並圍繞着這些存儲方式設計出了一些高效的操作算法。藉助數據結構,我們可以高效地管理多個數據,進而完成更複雜的功能。下圖列舉了一些常見的數據結構,後面會逐個進行講解:
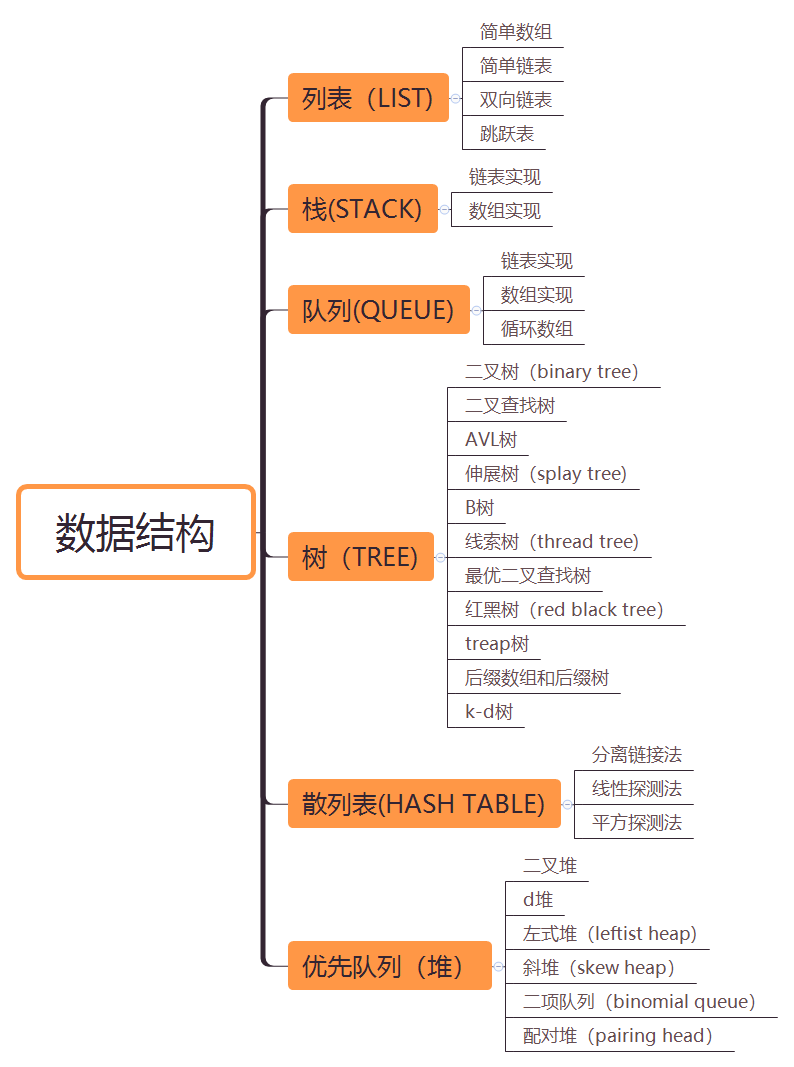
列表

通常一系列數據A0,A1,A2,A3,…,AN-1 可以採用表來存儲。表一般支持幾種操作,尋找某元素所在位置,在表的某個位置插入和刪除某元素,返回某個位置上的元素等。
棧

棧也叫LIFO(後進先出)表,元素的插入和訪問、刪除都只能從一個方向進行。通常支持入棧操作、出棧操作以及返回當前棧頂元素。
隊列

隊列插入時再一端進行,刪除時只能在另一端進行,也叫FIFO(先進先出)表。通常支持入隊操作,出隊操作和返回對頭元素。
樹
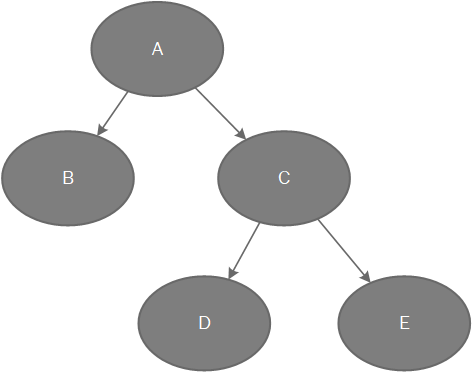
樹是數據結構考核的重點,涉及了很多的概念,也發展出來很多的變種,需要花大力氣去學習。樹是一些節點的集合,這個集合可以是空集;如果不是空集,則樹由稱作根(root)的節點r和0個或者多個非空的(子)樹T1,T2,…,Tk組成,這些子樹中每一棵的根都被來自根r的一條有向邊(edge)所連接。每一棵子樹的根叫做根r的兒子(child),而r是每棵子樹的根的父親(parent)。沒有兒子的節點稱為樹葉(leaf),具有相同父親的節點為兄弟(siblings)。在上圖,A是B和C的父親,B和C是A的兒子,B和C是兄弟,D和F沒有兒子所以叫葉子。
從節點n1到nk的路徑(path)定義為節點n1,n2,…,nk的一個序列,使得對於1<=i<k的節點ni是ni+1的父親。這條路徑的長(length)是該路徑上的邊的條數,即k-1。從每一個節點到他自己有一條長為0的路徑。注意,在一棵樹中從根到每個節點恰好存在一條路徑。對任意節點ni,ni的深度(depth)為從根到ni的唯一路徑的長。因此,根的深度為0。節點ni的高(height)是從ni到一片樹葉的最長路徑的長。一棵樹的高度(height of a tree)等於它的根的高。一棵樹的深度(depth of a tree)等於其最深的樹葉的深度,該深度總是等於這棵樹的高。
樹經常被考核到的點是他的幾種遍歷策略,分別是先序遍歷、後序遍歷和中序遍歷,三種遍歷策略的區別主要是根節點是在什麼時候處理的。先序遍歷是先處理根節點,再處理他的兒子節點;後序遍歷是等他所有的子節點處理完後再處理根節點。中序遍歷只會出現在二叉樹中,二叉樹每個根節點最多有左右兩個兒子節點,處理順序分別是左二子節點、根節點、右兒子節點。
散列表

散列表(hash table)常常也會根據英文音譯成哈希表。散列表不像普通的表,數據都是一個跟一個緊密存儲的,而是根據一個散列算法計算出元素存儲的位置再存儲。這樣做的好處是對應每個特定元素,散列表都能夠在O(1)的時間複雜度內通過散列算法算出元素所在位置,從而實現元素的快速訪問。散列表關鍵的技術細節在於衝突的處理。散列函數給兩個不同的元素計算出來的位置值是相同時,我們稱作衝突(collision)。衝突的解決有幾種方式,分別是分離鏈接法(separate chaining,也叫拉鏈法,鏈地址法)、探測散列表(probing hash table,也叫開放定址散列法,open addressing hashing,包括線性探測法、平方探測法和雙散列)。網上還有各種各樣的衝突解決方法,如果大家感興趣可以留言評論,我會在後續的博客詳細講解。
優先隊列

優先隊列設計的目的是找出、返回並刪除最小的元素,支持插入操作,刪除最小者操作。
這是Wikipedia上各種數據結構的時間複雜度對比,選擇數據結構時可以參考一下:

注:插入未排序數組有時被引用為O ( n ),因為假設要插入的元素必須插入到數組的一個特定位置,這需要將所有後續元素移動一個位置。然而,在經典數組中,數組用於存儲任意未排序的元素,因此任何給定元素的確切位置無關緊要,插入是通過將數組大小增加 1 並將元素存儲在末尾來執行的數組,這是一個O (1) 操作。同樣,刪除操作有時被引用為O ( n) 由於假設必須移動後續元素,但在經典的未排序數組中,順序並不重要(儘管元素是按插入時間隱式排序的),因此可以通過將要刪除的元素與最後一個元素交換來執行刪除數組中的元素,然後將數組大小減 1,這是一個O (1) 操作。
那麼多的數據結構我們要如何選擇呢?數據結構終究是服務於你的程序的,學習數據結構關鍵還是理解數據結構的設計思路,不用過於拘泥。以前上大學的時候我自己開發了一個電子詞典程序,當時並沒有學習過字典樹,但是根據電子詞典的需要設計出來的數據結構就是字典樹。現在的面試官很喜歡問各種術語各種概念,卻不知道最重要的其實還是問題的解決本身。當然也不是說不需要學習數據結構,既然我們要站在巨人的肩膀前進,至少我們得知道巨人的肩膀在哪是不是。下面總結了常用數據結構的一些權衡:

引用:
- //baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1450?fr=aladdin
- //en.wikipedia.org/wiki/Search_data_structure
- //en.wikipedia.org/wiki/Skip_list
- 《數據結構與算法分析——C++語言描述(第四版)》Mark Allen Weiss著

