vivo 評論中台的流量及數據隔離實踐
一、背景
vivo評論中台通過提供評論發表、點贊、舉報、自定義評論排序等通用能力,幫助前台業務快速搭建評論功能並提供評論運營能力,避免了前台業務的重複建設和數據孤島問題。目前已有vivo短視頻、vivo瀏覽器、負一屏、vivo商城等10+業務接入。這些業務的流量大小和波動範圍不同,如何保障各前台業務的高可用,避免因為某個業務的流量暴增導致其他業務的不可用?所有業務的評論數據都交由中台存儲,他們的數據量大小不同、db壓力不同,作為中台,應該如何隔離各個業務的數據,保障整個中台系統的高可用?
本文將和大家一起分享下vivo評論中台的解決方案,主要是從流量隔離和數據隔離兩部分進行了處理。
二、流量隔離
2.1 流量分組
vivo瀏覽器業務億級日活,實時熱點新聞全網push,對於這類用戶量大、流量大的重要業務,我們提供了單獨的集群為他們提供服務,避免受到其他業務的影響。
vivo評論中台是通過Dubbo接口對外提供服務,我們通過Dubbo標籤路由的方式對整個服務集群做了邏輯上的劃分,一次 Dubbo 調用能夠根據請求攜帶的 tag 標籤智能地選擇對應 tag 的服務提供者進行調用。如下圖所示:
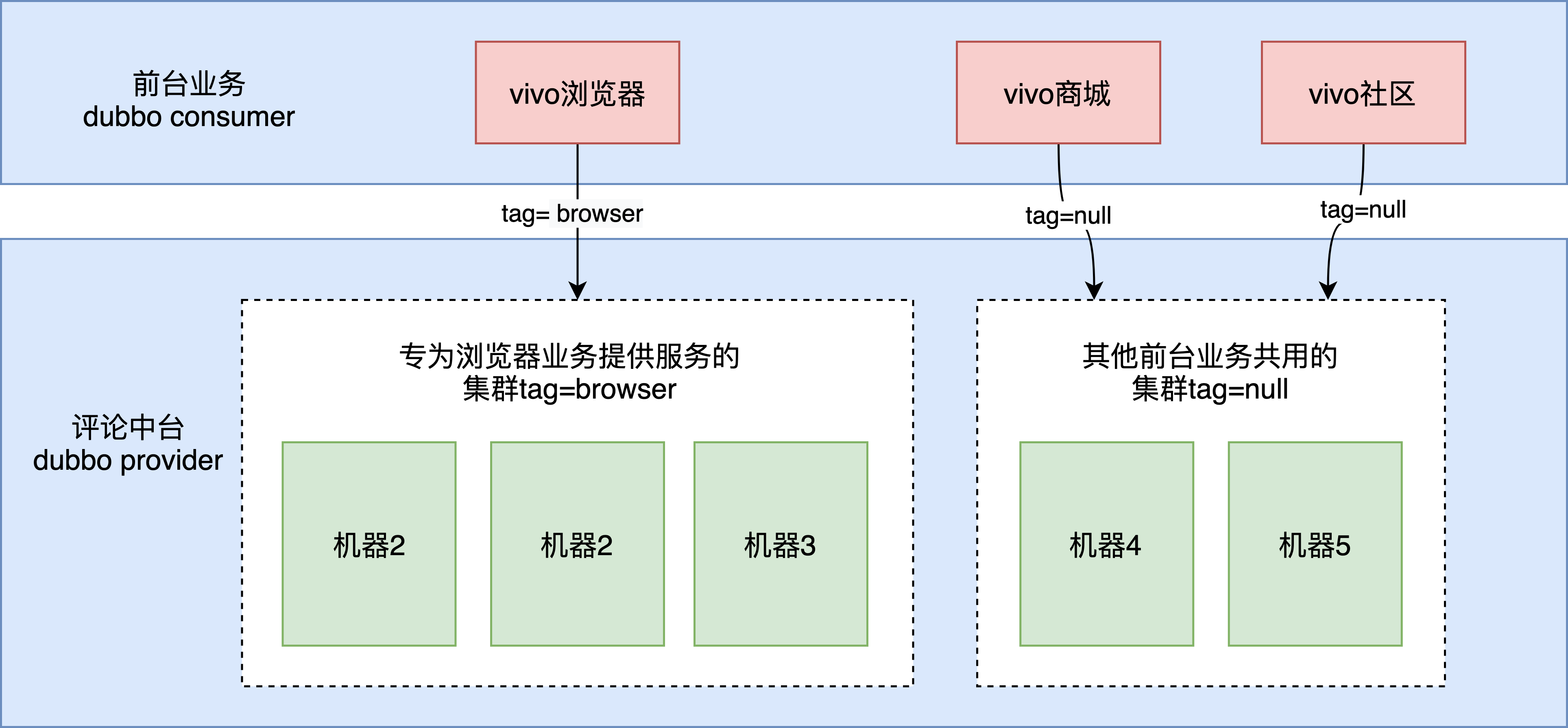
1)provider打標籤:目前有兩種方式可以完成實例分組,分別是動態規則打標和靜態規則打標,其中動態規則相較於靜態規則優先級更高,而當兩種規則同時存在且出現衝突時,將以動態規則為準。公司內部的運維繫統很好的支持了動態打標,通過對指定ip的機器打標即可(非docker容器,機器ip是固定的)。

2)前台consumer指定服務標籤:發起請求時設置,如下;
前台指定中台的路由標籤
RpcContext.getContext().setAttachment(Constants.REQUEST_TAG_KEY,"browser");
請求標籤的作用域為每一次 invocation,只需要在調用評論中台服務前設置標籤即可,前台業務調用其他業務的provider並不受該路由標籤的影響。
2.2 多租戶限流
大流量的業務我們通過單獨的集群隔離出去了。但是獨立部署集群成本高,不能為每個前台業務都獨立部署一套集群。大部分情況下多個業務還是需要共用一套集群的,那麼共用集群的服務遇到了突發流量如何處理呢?沒錯,限流唄!但是目前很多限流都是一刀切的方式對接口整體QPS做限流,這樣的話某一前台業務的流量暴增會導致所有前台業務的請求都被限流。
這就需要多租戶限流登場了(這裡的一個租戶可以理解為一個前台業務),支持對同一接口不同租戶的流量進行限流處理,效果如下圖:
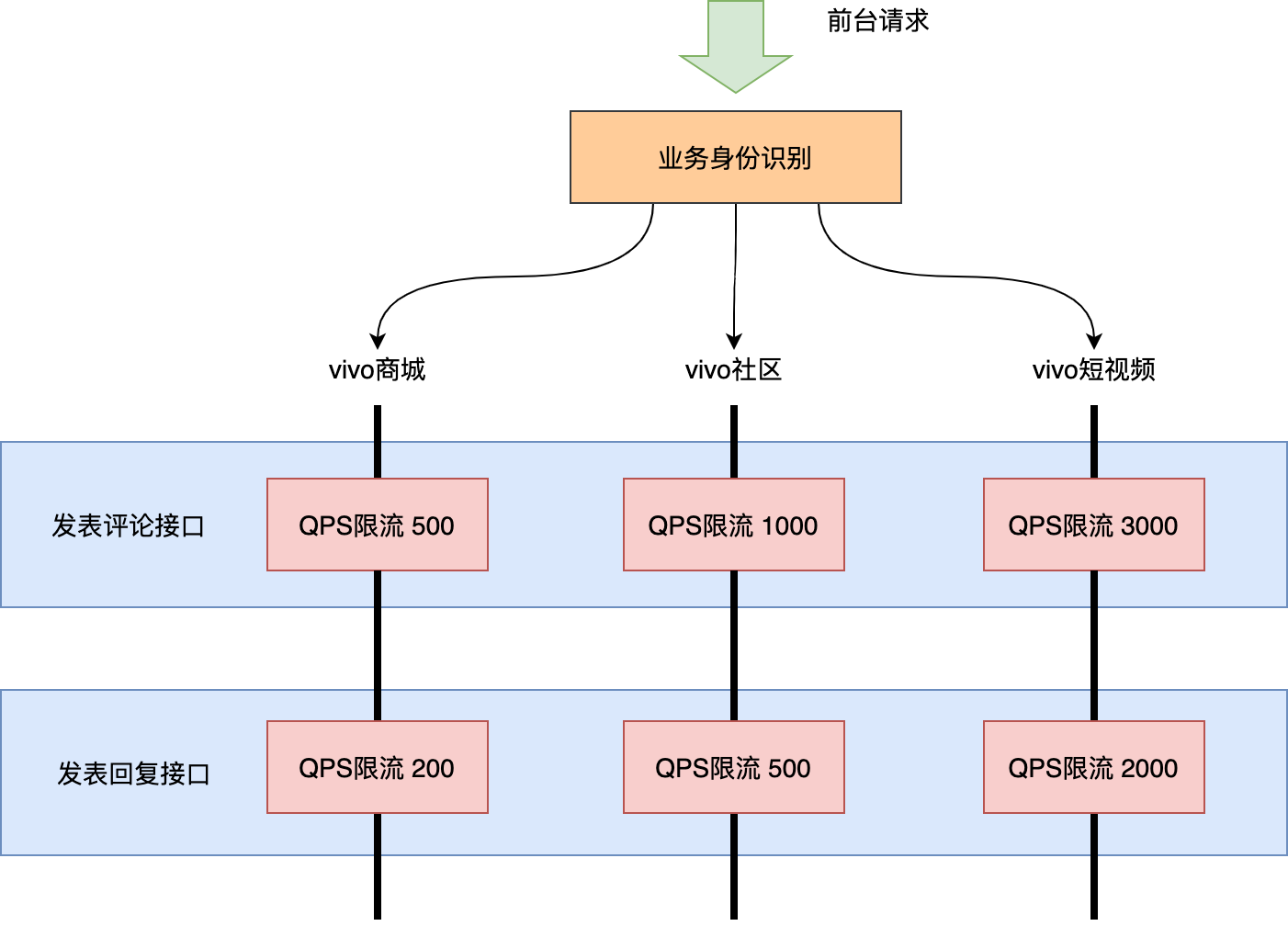
實現過程:
我們使用sentinel的熱點參數限流特性,使用業務身份編碼作為熱點參數,為各業務配置不同的流控大小。
那麼何為熱點參數限流?首先得說下什麼是熱點,熱點即經常訪問的數據。很多時候我們希望統計某個熱點數據中訪問頻次最高的 Top n數據,並對其訪問進行限制。比如:
-
商品 ID 為參數,統計一段時間內最常購買的商品 ID 並進行限制。
-
用戶 ID 為參數,針對一段時間內頻繁訪問的用戶 ID 進行限制。
熱點參數限流會統計傳入參數中的熱點參數,並根據配置的限流閾值與模式,對包含熱點參數的資源調用進行限流。熱點參數限流可以看做是一種特殊的流量控制,僅對包含熱點參數的資源調用生效。Sentinel 利用 LRU 策略統計最近最常訪問的熱點參數,結合令牌桶算法來進行參數級別的流控。下圖為評論場景示例:
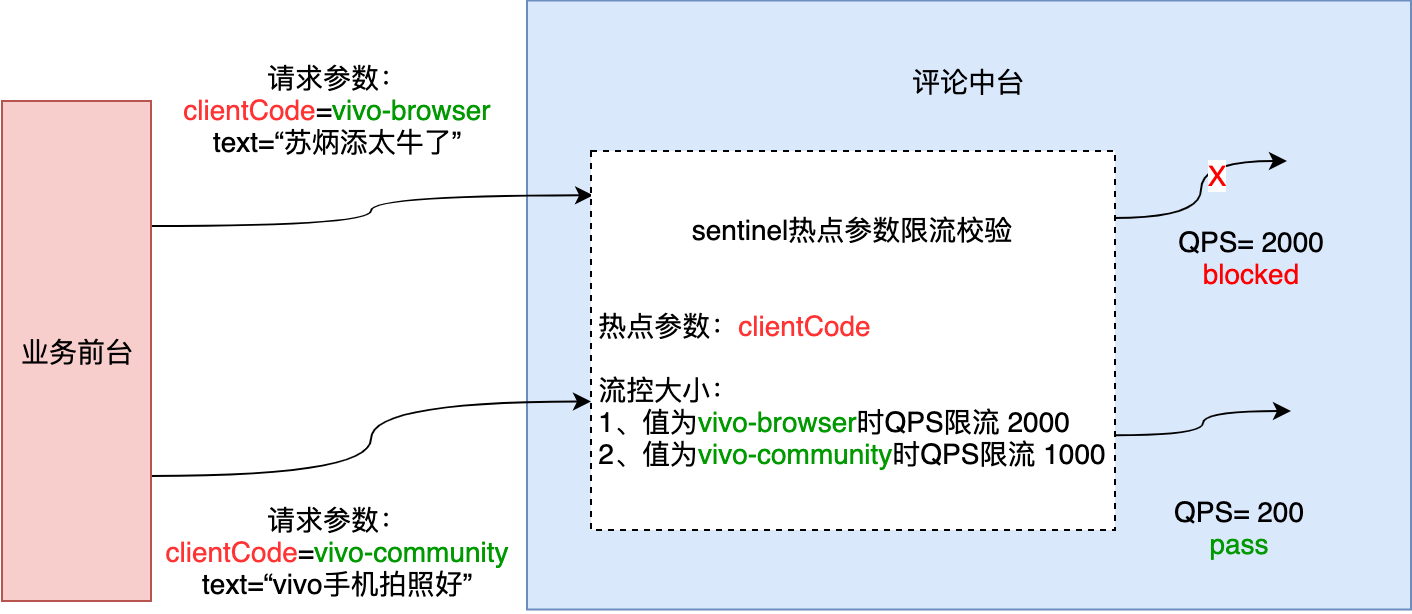
使用 Sentinel 來進行資源保護,主要分為幾個步驟:定義資源、定義規則、規則生效處理。
1)定義資源:
在這裡可以理解為各個中台API接口路徑。
2)定義規則:
Sentienl支持規則很多QPS流控、自適應限流、熱點參數限流、集群限流等等,這裡我們用的是單機熱點參數限流。
熱點參數限流配置
{
"resource": "com.vivo.internet.comment.facade.comment.CommentFacade:comment(com.vivo.internet.comment.facade.comment.dto.CommentRequestDto)", // 需要限流的接口
"grade": 1, // QPS限流模式
"count": 3000, // 接口默認限流大小3000
"clusterMode": false, // 單機模式
"paramFieldName": "clientCode", // 指定熱點參數名即業務方編碼字段,這裡是我們對sentinel組件做了優化,增加了該配置屬性,用來指定參數對象的屬性名作為熱點參數key
"paramFlowItemList": [ // 熱點參數限流規則
{
"object": "vivo-community", // 當clientCode為該值時,匹配該限流規則
"count": 1000, // 限流大小為1000
"classType": "java.lang.String"
},
{
"object": "vivo-shop", // 當clientCode為該值時,匹配該限流規則
"count": 2000, // 限流大小為2000
"classType": "java.lang.String"
}
]
}
3)規則生效處理:
當觸發了限流規則後sentinel會拋出ParamFlowException異常,直接將異常拋給前台業務去處理是不優雅的。sentinel給我們提供了統一的異常回調處理入口DubboAdapterGlobalConfig,支持我們將異常轉換為業務自定義結果返回。
自定義限流返回結果;
DubboAdapterGlobalConfig.setProviderFallback((invoker, invocation, ex) ->
AsyncRpcResult.newDefaultAsyncResult(FacadeResultUtils.returnWithFail(FacadeResultEnum.USER_FLOW_LIMIT), invocation));
我們做了哪些額外的優化:
1)公司內部的限流控制台尚不支持熱點參數限流配置,因此我們增加了新的限流配置控制器,支持通過配置中心中動態下發限流配置。整體流程如下:
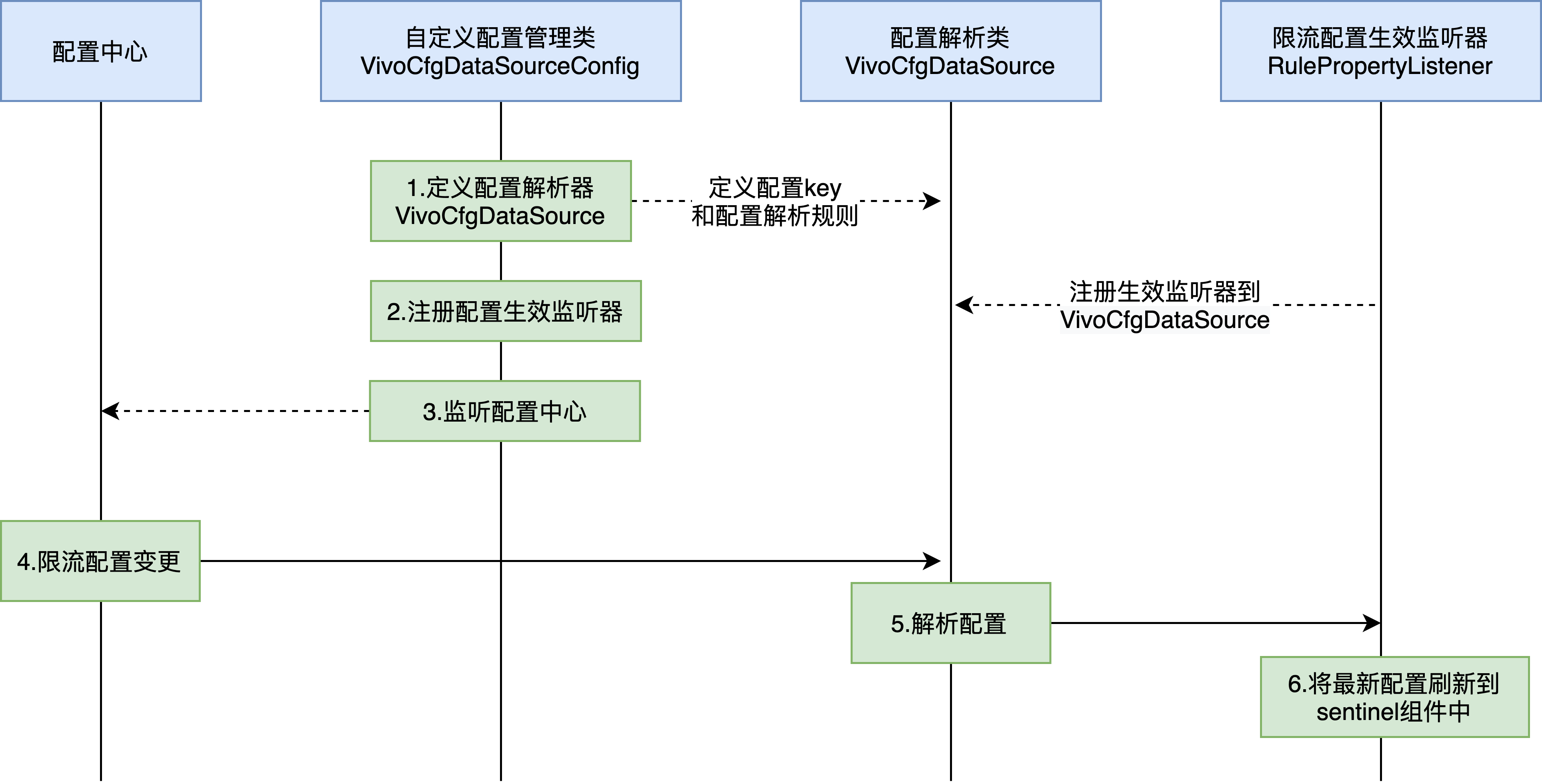
限流配置動態下發;
public class VivoCfgDataSourceConfig implements InitializingBean {
private static final String PARAM_FLOW_RULE_PREFIX = "sentinel.param.flow.rule";
@Override
public void afterPropertiesSet() {
// 定製配置解析對象
VivoCfgDataSource<List<ParamFlowRule>> paramFlowRuleVivoDataSource = new VivoCfgDataSource<>(PARAM_FLOW_RULE_PREFIX, sources -> sources.stream().map(source -> JSON.parseObject(source, ParamFlowRule.class)).collect(Collectors.toList()));
// 註冊配置生效監聽器
ParamFlowRuleManager.register2Property(paramFlowRuleVivoDataSource.getProperty());
// 初始化限流配置
paramFlowRuleVivoDataSource.init();
// 監聽配置中心
VivoConfigManager.addListener(((item, type) -> {
if (item.getName().startsWith(PARAM_FLOW_RULE_PREFIX)) {
paramFlowRuleVivoDataSource.updateValue(item, type);
}
}));
}
}
2)原生sentinel指定限流熱點參數的方式是兩種:
-
第一種是指定接口方法的第n個參數;
-
第二種是方法參數繼承ParamFlowArgument,實現ParamFlowKey方法,該方法返回值為熱點參數value值。
這兩種方式都不是特點靈活,第一種方式不支持指定對象屬性;第二種方式需要我們改造代碼,如果上線後某個接口參數沒有繼承ParamFlowArgument又想配置熱點參數限流,那麼只能通過改代碼發版的方式解決了。因此我們對sentinel組件的熱點參數限流源碼做了些優化,增加「 指定參數對象的某個屬性 」作為熱點參數,並且支持對象層級的嵌套。很小的代碼改動,卻大大方便了熱點參數的配置。
改造後的熱點參數校驗邏輯;
public static boolean passCheck(ResourceWrapper resourceWrapper, /*@Valid*/ ParamFlowRule rule, /*@Valid*/ int count,
Object... args) {
// 忽略部分代碼
// Get parameter value. If value is null, then pass.
Object value = args[paramIdx];
if (value == null) {
return true;
}
// Assign value with the result of paramFlowKey method
if (value instanceof ParamFlowArgument) {
value = ((ParamFlowArgument) value).paramFlowKey();
}else{
// 根據classFieldName指定的熱點參數獲取熱點參數值
if (StringUtil.isNotBlank(rule.getClassFieldName())){
// 反射獲取參數對象中的classFieldName屬性值
value = getParamFieldValue(value, rule.getClassFieldName());
}
}
// 忽略部分代碼
}
三、MongoDB數據隔離
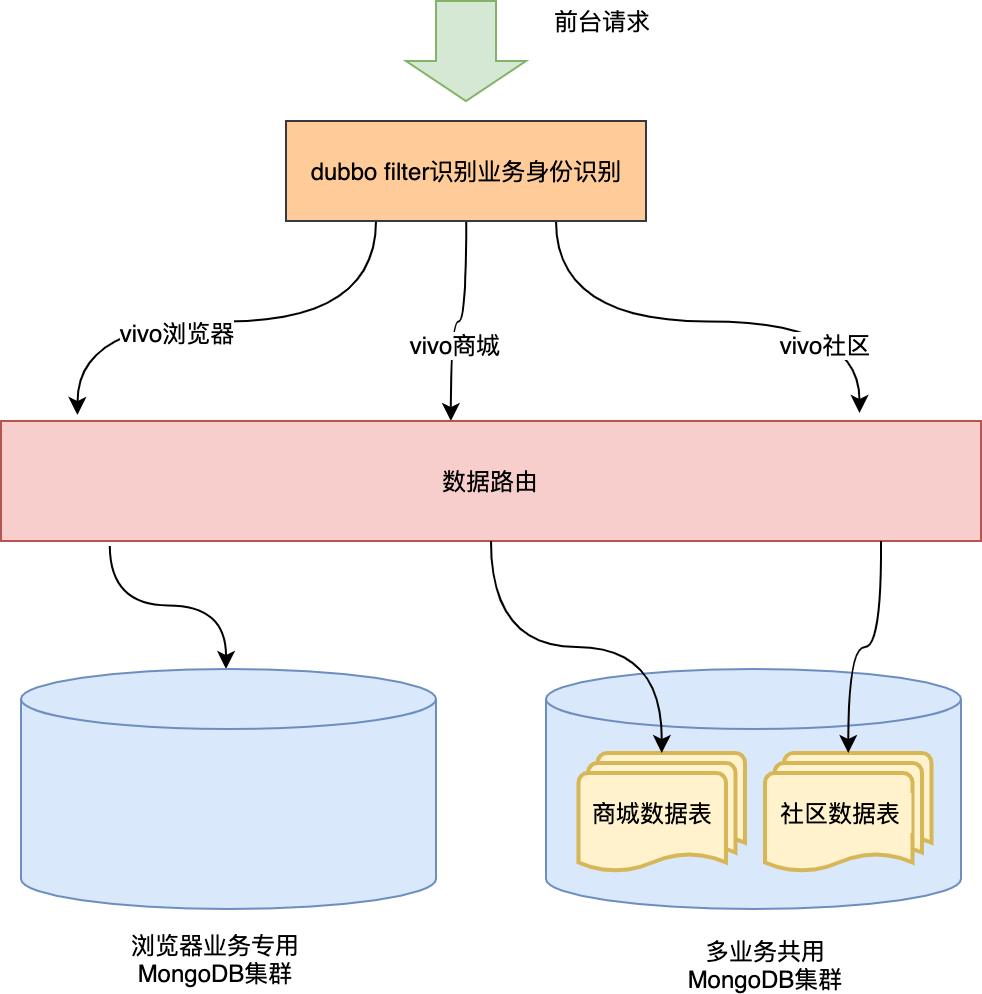
為什麼要做數據隔離?這其中有兩點原因,第一點:中台存儲了前台不同業務的數據,在數據查詢時各業務數據不能相互影響,不能A業務查詢到B業務的數據。第二點:各業務的數據量級不同、對db操作的壓力不同,如流量隔離中我們單獨提供了一套服務集群給瀏覽器業務使用,那麼瀏覽器業務使用的db同樣需要單獨配置一套,這樣才能徹底和其他業務的服務壓力隔離開。
vivo評論中台使用了MongoDB作為存儲介質(關於數據庫選型及Mongodb應用的細節有興趣的同學可以看下我們之前的介紹《MongoDB 在評論中台的實踐》),為了隔離不同業務方的數據,評論中台提供了兩種數據隔離方案:物理隔離、邏輯隔離。
3.1 物理隔離
不同業務方的數據存儲在不同的數據庫集群中,這就需要我們系統支持MongoDB的多數據源。實現過程如下:
1) 尋找合適的切入點
通過分析spring-data-mongodb的執行過程的源碼發現,在執行所有語句前都會去做一個getDB()獲取數據庫連接實例的動作,如下。
spring-data-mongodb db操作源碼;
private <T> T executeFindOneInternal(CollectionCallback<DBObject> collectionCallback,
DbObjectCallback<T> objectCallback, String collectionName) {
try {
//關鍵代碼getDb()
T result = objectCallback
.doWith(collectionCallback.doInCollection(getAndPrepareCollection(getDb(), collectionName)));
return result;
} catch (RuntimeException e) {
throw potentiallyConvertRuntimeException(e, exceptionTranslator);
}
}
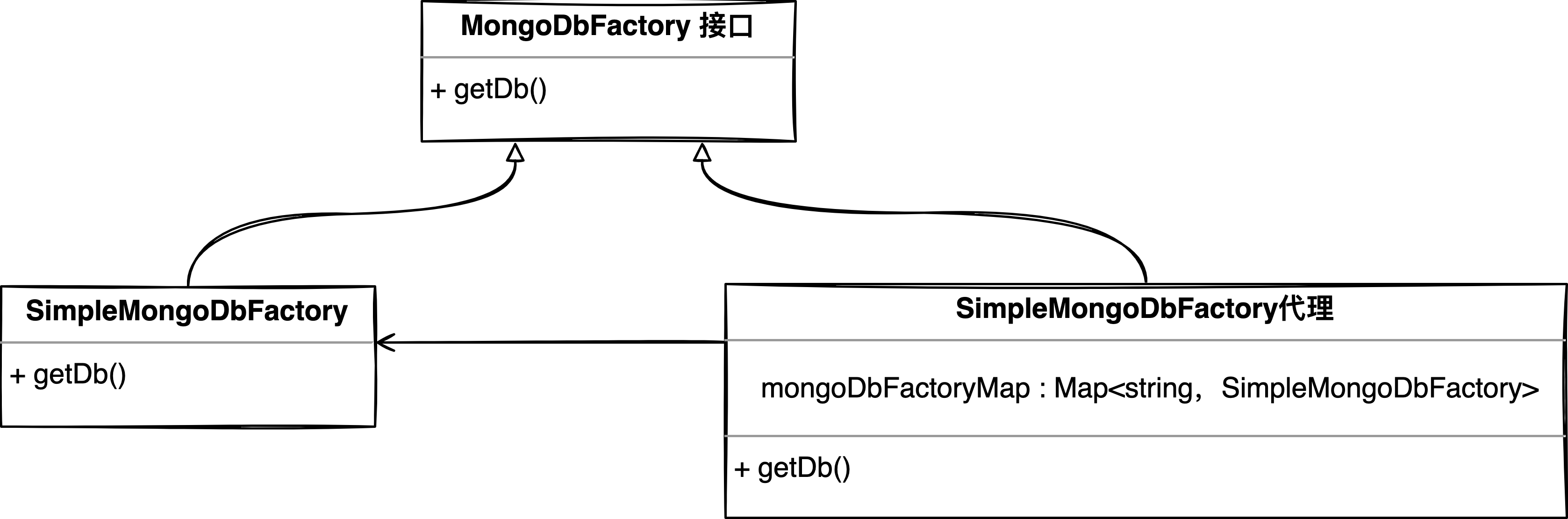
getDB()會執行org.springframework.data.mongodb.MongoDbFactory接口的getDb( )方法,默認情況下使用MongoDbFactory的SimpleMongoDbFactory實現,看到這裡我們很自然的就能想到運用「代理模式」,用SimpleMongoDbFactory代理對象去替換SimpleMongoDbFactory,並在代理對象內部為每個MongoDB集配創建一個SimpleMongoDbFactory實例。
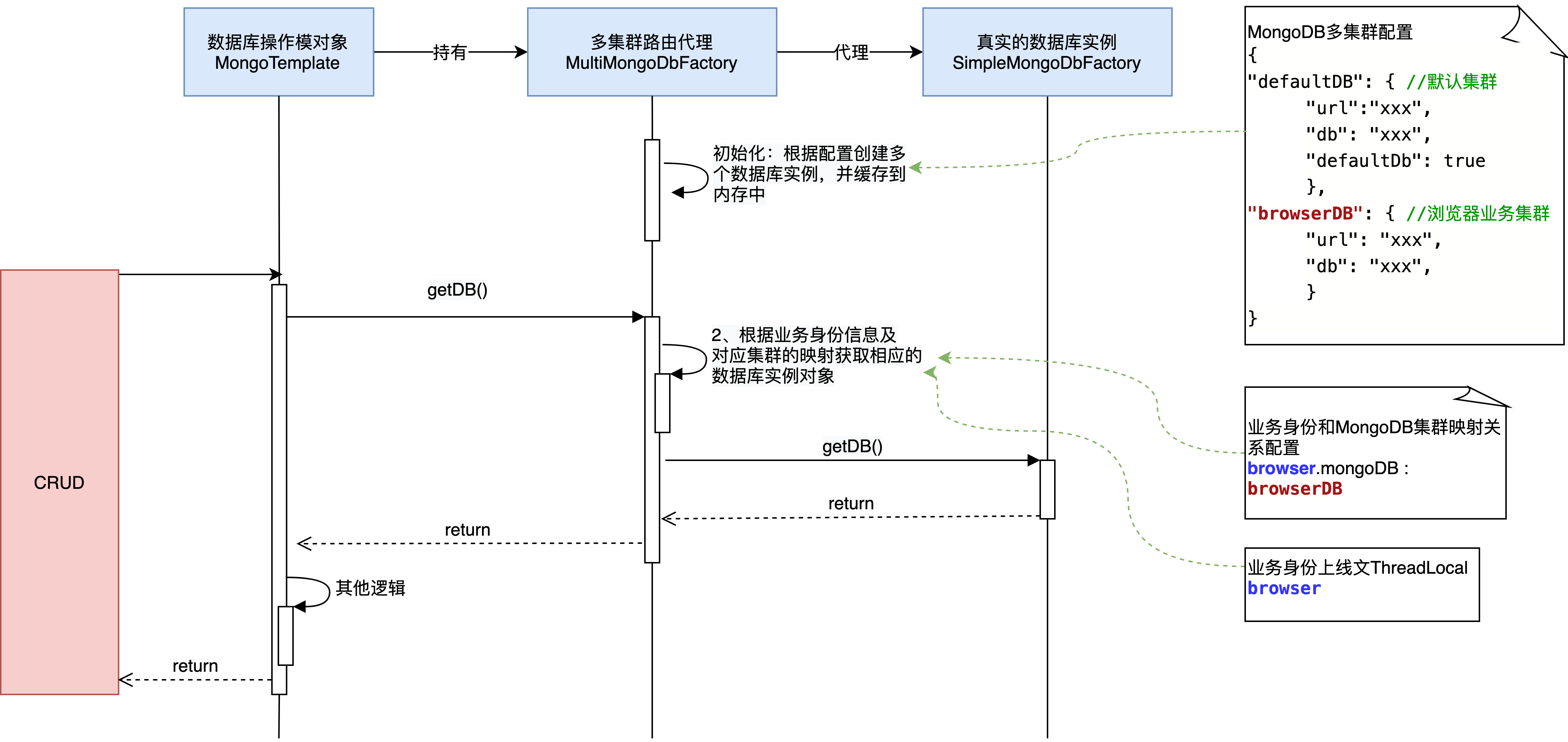
在執行db操作時執行代理對象的getDb( )操作,它只需要做兩件事;
-
找到對應集群的SimpleMongoDbFactory對象
-
執行SimpleMongoDbFactory.getdb( )操作。
類關係圖如下。
整體的執行過程如下:
3.1.2 核心代碼實現
Dubbo filter獲取業務身份並設置到上下文;
private boolean setCustomerCode(Object argument) {
// 從string類型參數中獲取業務身份信息
if (argument instanceof String) {
if (!Pattern.matches("client.*", (String) argument)) {
return false;
}
// 設置業務身份信息到上下文中
CustomerThreadLocalUtil.setCustomerCode((String) argument);
return true;
} else {
// 從list類型中獲取參數對象
if (argument instanceof List) {
List<?> listArg = (List<?>) argument;
if (CollectionUtils.isEmpty(listArg)) {
return false;
}
argument = ((List<?>) argument).get(0);
}
// 從object對象中獲取業務身份信息
try {
Method method = argument.getClass().getMethod(GET_CLIENT_CODE_METHOD);
Object object = method.invoke(argument);
// 校驗業務身份是否合法
ClientParamCheckService clientParamCheckService = ApplicationUtil.getBean(ClientParamCheckService.class);
clientParamCheckService.checkClientValid(String.valueOf(object));
// 設置業務身份信息到上下文中
CustomerThreadLocalUtil.setCustomerCode((String) object);
return true;
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {
log.debug("反射獲取clientCode失敗,入參為:{}", argument.getClass().getName(), e);
return false;
}
}
}
MongoDB集群的路由代理類;
public class MultiMongoDbFactory extends SimpleMongoDbFactory {
// 不同集群的數據庫實例緩存:key為MongoDB集群配置名,value為對應業務的MongoDB集群實例
private final Map<String, SimpleMongoDbFactory> mongoDbFactoryMap = new ConcurrentHashMap<>();
// 添加創建好的MongoDB集群實例
public void addDb(String dbKey, SimpleMongoDbFactory mongoDbFactory) {
mongoDbFactoryMap.put(dbKey, mongoDbFactory);
}
@Override
public DB getDb() throws DataAccessException {
// 從上下文中獲取前台業務編碼
String customerCode = CustomerThreadLocalUtil.getCustomerCode();
// 獲取該業務對應的MongoDB配置名
String dbKey = VivoConfigManager.get(ConfigKeyConstants.USER_DB_KEY_PREFIX + customerCode);
// 從連接緩存中獲取對應的SimpleMongoDbFactory實例
if (dbKey != null && mongoDbFactoryMap.get(dbKey) != null) {
// 執行SimpleMongoDbFactory.getDb()操作
return mongoDbFactoryMap.get(dbKey).getDb();
}
return super.getDb();
}
}
自定義MongoDB操作模板;
@Bean
public MongoTemplate createIgnoreClass() {
// 生成MultiMongoDbFactory代理
MultiMongoDbFactory multiMongoDbFactory = multiMongoDbFactory();
if (multiMongoDbFactory == null) {
return null;
}
MappingMongoConverter converter = new MappingMongoConverter(new DefaultDbRefResolver(multiMongoDbFactory), new MongoMappingContext());
converter.setTypeMapper(new DefaultMongoTypeMapper(null));
// 使用multiMongoDbFactory代理生成MongoDB操作模板
return new MongoTemplate(multiMongoDbFactory, converter);
}
3.2 邏輯隔離
物理隔離是最徹底的數據隔離,但是我們不可能為每一個業務都去搭建一套獨立的MongoDB集群。當多個業務共用一個數據庫時,就需要做數據的邏輯隔離。
邏輯隔離一般分為兩種:
-
一種是表隔離:不同業務方的數據存儲在同一個數據庫的不同表中,不同的業務操作不同的數據表。
-
一種是行隔離:不同業務方的數據存儲在同一個表中,表中冗餘業務方編碼,在讀取數據時通過業務編碼過濾條件來實現隔離數據目的。
從實現成本及評論業務場景考慮,我們選擇了表隔離的方式。實現過程如下:
1 )初始化數據表
每次有新業務對接時,我們都會為業務分配一個唯一的身份編碼,我們直接使用該身份編碼作為業務表表名的後綴,並初始化表,例如:商城評論表comment_info_vshop、社區評論表comment_info_community。
2) 自動尋表
直接利用spring-data-mongodb @Document註解支持Spel的能力,結合我們的業務身份信息上下文,實現自動尋表。
自動尋表
@Document(collection = "comment_info_#{T(com.vivo.internet.comment.common.utils.CustomerThreadLocalUtil).getCustomerCode()}")
public class Comment {
// 表字段忽略
}
兩種隔離方式結合後的整體效果:
四、最後
通過上文的這些實踐,我們很好的的支撐了不同量級的前台業務,並且做到了對業務代碼無入侵,較好的解耦了技術和業務間的複雜度。另外我們對項目中使用到的Redis集群、ES集群對不同業務也做了隔離,大體思路和MongoDB的隔離類似,都是做一層代理,這裡就不一一介紹了。
作者:vivo官網商城開發團隊-Sun Daoming


