©原創作者 | 蘇菲
論文來源:
//aclanthology.org/2020.emnlp-main.668/
論文題目:
Text Graph Transformer for Document Classification (文本圖Tranformer在文本分類中的應用)
論文作者:
Haopeng Zhang Jiawei Zhang
01 引言
文本分類是自然語言處理中的基本任務之一,而圖神經網絡(GNN)技術可以描述詞語、文本以及語料庫,最近研究者將GNN應用到抓取語料庫中單詞全局共現關係中。但此前的圖神經網絡引用存在不能擴展到大型語料庫、且忽略文本圖異質性的缺陷。
在此背景下,本文作者引入了一個基於異質性圖神經網絡的新Transformer方法(文本圖Transformer,或者TG-Transformer)。
深度學習模型如卷積神經網絡(CNN)、循環神經網絡(RNN)已經被用於文本特徵的學習中,取代了一些傳統的特徵生成(如n元語法特徵、詞袋特徵)。
最近,一些學者又把圖神經網絡(GNN)用於文本分類的研究中,但論文作者指出了其中的一些缺陷,並提出使用文本圖Transformer,一個異質性的圖神經網絡用於文本分類問題。而且這是一種可擴展的基於圖的方法。
02 方法論
作者首先用圖表示一個已知語料庫的異質性文本圖,然後引入文本圖的採樣方法(Sampling)從文本圖中生成小批量子圖。這些小批量子圖可以送入TG-Transformer中,用於學習文本分類的有效節點特徵,總體框架如圖1所示。
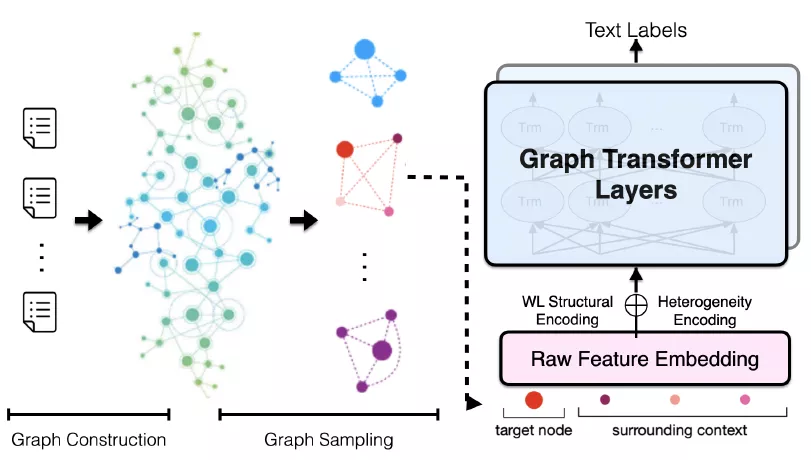
圖1 TG-Tranformer的總體框架
(1)建立文本圖(Text Graph)
為了獲得語料庫中詞語的全局共現,論文作者建立了一個異質性文本圖G(異質圖比同質圖更貼近於現實世界),G =(U; V; E;F)。 所謂異質性就是圖中不只包含一種類型的節點或邊(nodes or edges)。
在G中建立了兩種類型的節點,一種是文本節點(U),代表語料庫中的所有文檔;另一種是詞語節點(V),代表語料庫詞彙表中的所有詞語。一種是詞語節點(U),代表語料庫詞彙表中的所有詞語;另一種是文檔節點(V),代表語料庫中的所有文檔。
文本圖中也包含了兩種類型的邊:一種是詞語-文檔邊,用大寫E來表示;另一種是詞語-詞語邊,用大寫字母F來表示。詞語-文檔邊的權重由TF-IDF方法來計算得到。而詞語-詞語邊的權重通過計算點間互信息(point-wise mutual information)得到,該互信息基於在語料庫中滑動窗口的局部詞語共現來獲得。點間互信息的計算公式如下:
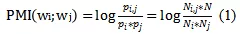
其中,
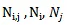
分別是語料庫中滑窗的數目,
即只含詞語

只含詞語
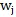
既包含詞語
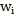
又包含詞語
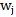
N是在語料庫中滑窗的總數目。
(2)文本圖的採樣
為了減少計算成本和內存成本,論文作者提出了一種文本圖的採樣方法,而不是用整個文本圖去學習。TG-Transformer的訓練輸入是小批量的採樣子圖,這種採樣方法是作為無監督學習的一個預處理步驟,以控制模型的學習時間成本,並可以擴展到大規模語料庫中。
首先,基於PpageRrank算法,計算了圖的親密矩陣S(intimacy matrix),公式如下:
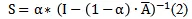
其中,
因子
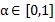
之間,通常設為0.15。
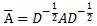
是標準化的對稱鄰接矩陣,
是標準化的對稱鄰接矩陣,A是文本圖的鄰接矩陣,D是相應的對角矩陣。
因此,
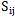
測度了節點i和節點j間的親密分數。
對於文檔詞語節點
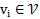
採樣大小為k的子圖
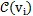
即通過選擇前k個最親密的鄰接文檔節點
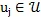
對於詞語文檔節點
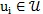
首先計算兩種類型的關聯邊(incident edge)的比。
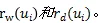
計算公式如下:
其中,
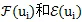
和分別是關聯的
詞語-詞語邊集合、詞語-文本邊集合,
且親密分數大於閾值
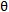
採樣大小為k個大小的情景圖
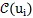
即選擇前
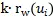
個親密鄰居詞語節點
即選擇前k個親密鄰居詞語節點
和前
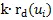
個親密鄰居文檔節點。
(3)文本圖Transformer模型
基於採樣的小批量子圖,TG-Transformer(文本圖Transformer模型)可以遞歸更新文本圖的節點的特徵並用於分類問題。
該模型的輸入是經過兩種結構編碼的批量子圖中節點的原始特徵詞向量。這兩種結構編碼分別是異質性編碼和WL結構編碼:
1)異質性編碼:異質性編碼能刻畫文本圖中的文檔和詞語兩種類型。類似於2018年Devlin等人論文中的分割編碼,分別用0和1對文檔節點和詞語節點進行編碼。
2) WL結構編碼:論文作者採用了圖理論中著名的WL結構編碼(WEISFEILER-Lehman) 去刻畫文本圖的結構。WL算法能根據圖中的結構角色標註節點,
可以用
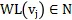
來表示, 編碼公式如下:
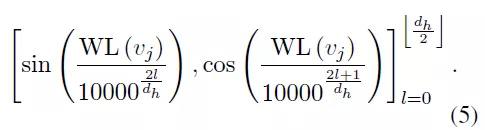
公式(5)中的兩個編碼具有相同的維度,
即
作為原始特徵的嵌入,論文作者把它們加起來作為輸入子圖的初始節點特徵,
用

表示。
在圖Transformer層,可以加總批量子圖的信息,以學習目標節點的特徵。每一個圖Transformer層包含三個可訓練的矩陣,分別是查詢權重、關鍵詞權重和值權重
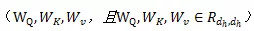
查詢Q、關鍵詞K和值V通過其乘以相應的輸入獲得(Q可以理解為信息檢索中的查詢,然後根據Query(查詢)和Key(返回的關鍵特徵)的相似度得到匹配的內容(Value)):
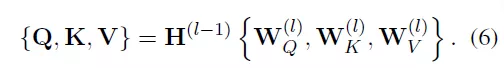
因此,TG-Transformer層可以通過公式(7)得到:
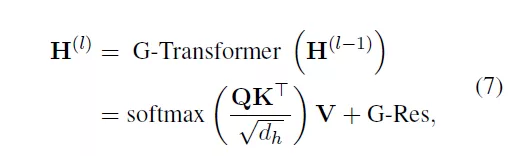
其中,G-Res指殘差網絡中的圖殘差[2],解決GNN的過度平滑問題。
最後一層的輸出
將被平均為
目標節點z的最終特徵,並最後進入softmax分類中。
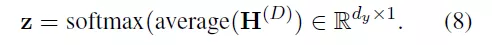
基於對所有節點在訓練樣本中的子圖採樣如,論文作者定義了交叉熵損失函數:
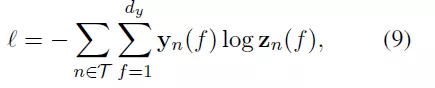
03 實驗
論文作者為了評估模型的有效性,實驗建立在5個數據庫基礎上,分別是:R52和R8路透社新聞文本分類數據庫、用於醫學文獻分類的Ohsumed數據庫、2個大規模的點評數據庫IMDB和Yelp 2014。基線模型是CNN、LSTM和fastTest,使用了詞語/n-元嵌入平均。
論文作者設置節點的特徵維度為300,初始特徵使用Glove詞向量,訓練了兩層的圖Transformer,隱藏層大小為32和4個注意力頭機制。
小批量SGD算法使用了Adam 優化器,dropout為0.5,初始學習率為0.001,decay的權重為5。
decay的權重為
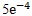
從訓練集中隨機選擇10%作為驗證集,若驗證集的損失在10個連續epoch中沒有下降,就停止訓練。
實驗結果如下:
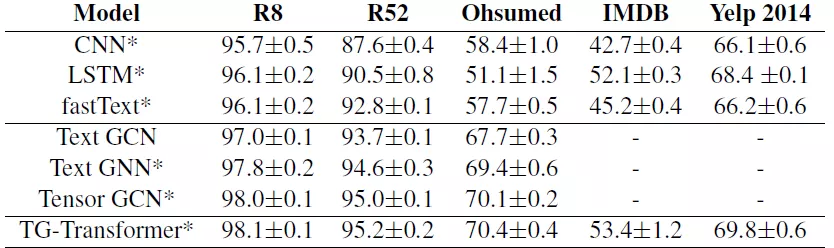
從實驗結果可以看到,基於圖神經網絡模型的結果(無論是TextGCN、TextGNN、TensorGCN還是這篇論文作者用到的TG-Transformer),在不同的數據集中都好於傳統的CNN、LSTM和fastText模型方法。
論文作者為了進一步驗證其方法的有效性,進行了如下消融實驗:
(1)去除2個結構編碼且僅僅使用原始特徵嵌入作為輸入,性能的下降說明結構編碼捕捉到了一些有用的異質性圖結構信息;
(2)去除預訓練詞語嵌入且用隨機向量初始化所有節點,性能下降更大,說明預訓練詞語嵌入和初始化節點特徵在論文模型中的重要性;
(3)訓練了一個新模型去更新和學習批量子圖的節點類型,分類精度只是略微下降,這說明了文本圖模型中的異質性信息的重要性。
04 結論
總之,這篇論文通過從文本圖中獲取結構和異質性,學習得到有效的節點特徵,並通過小批量的文本圖採樣方法大大地降低了在處理大規模語料庫時的計算和存儲成本。
論文的實驗表明TG-Transformer方法要好於目前的文本分類SOTA方法。
作者在論文中介紹了文本圖的建立、文本圖的採樣,如何通過異質性編碼、WL結構編碼和圖Transformer層來得到文本的類別,並在IMDB、Yelp等語料庫進行了實驗,獲得了比傳統圖模型(如Text-GCN)更好的文本分類實驗結果。
該論文的成果可用於未來的圖神經網絡模型預訓練方面的研究。
引用文獻來源
[1] //arxiv.org/abs/1810.04805v2
[2] //arxiv.org/abs/1909.05729
私信我領取目標檢測與R-CNN/數據分析的應用/電商數據分析/數據分析在醫療領域的應用/NLP學員項目展示/中文NLP的介紹與實際應用/NLP系列直播課/NLP前沿模型訓練營等乾貨學習資源。


