SpringBoot整合Elasticsearch+ik分詞器+kibana
- 2022 年 1 月 14 日
- 筆記
- ES, springboot
話不多說直接開整
首先是版本對應,SpringBoot和ES之間的版本必須要按照官方給的對照表進行安裝,最新版本對照表如下:

(官網鏈接://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#preface.requirements)
1、開始安裝ES:
我本地的SpringBoot版本是2.3.4,所以我採用的ES版本是7.6.2版本,然後前往官網進行下載,小夥伴們也可以直接下載我所用的版本(鏈接://pan.baidu.com/s/1KoRo5h1nHY82c3B5RxfmrA 提取碼:bcov):
ES官方下載鏈接://www.elastic.co/cn/downloads/past-releases#elasticsearch
將下載下來的文件上傳到服務器上,我上傳的目錄是usr/local/es,然後開始解壓:
tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
解壓後修改config目錄下的elasticsearch.yml文件,貼一下我修改的內容:
1 # ======================== Elasticsearch Configuration =========================
2 #
3 # NOTE: Elasticsearch comes with reasonable defaults for most settings.
4 # Before you set out to tweak and tune the configuration, make sure you
5 # understand what are you trying to accomplish and the consequences.
6 #
7 # The primary way of configuring a node is via this file. This template lists
8 # the most important settings you may want to configure for a production cluster.
9 #
10 # Please consult the documentation for further information on configuration options:
11 # //www.elastic.co/guide/en/elasticsearch/reference/index.html
12 #
13 # ---------------------------------- Cluster -----------------------------------
14 #
15 # Use a descriptive name for your cluster:
16 # 這個是名字
17 cluster.name: my-application
18 #
19 # ------------------------------------ Node ------------------------------------
20 #
21 # Use a descriptive name for the node:
22 # 這個是節點名稱
23 node.name: es-node-0
24 #
25 # Add custom attributes to the node:
26 #
27 #node.attr.rack: r1
28 #
29 # ----------------------------------- Paths ------------------------------------
30 #
31 # Path to directory where to store the data (separate multiple locations by comma):
32 # 這個是數據存放的路徑
33 path.data: /usr/local/elasticsearch-7.6.2/data
34 #
35 # Path to log files:
36 # 這個是log存放的路徑
37 path.logs: /usr/local/elasticsearch-7.6.2/logs
38 #
39 # ----------------------------------- Memory -----------------------------------
40 #
41 # Lock the memory on startup:
42 #
43 #bootstrap.memory_lock: true
44 #
45 # Make sure that the heap size is set to about half the memory available
46 # on the system and that the owner of the process is allowed to use this
47 # limit.
48 #
49
50
51 # Elasticsearch performs poorly when the system is swapping the memory.
52 #
53 # ---------------------------------- Network -----------------------------------
54 #
55 # Set the bind address to a specific IP (IPv4 or IPv6):
56 # 註:如果是雲服務器的話需要填寫內外地址,我這裡是內網。
57 network.host: 192.168.0.4
58 http.host: 0.0.0.0
59 #
60 # Set a custom port for HTTP:
61 # 啟動端口號
62 http.port: 9200
63 #
64 # For more information, consult the network module documentation.
65 #
66 # --------------------------------- Discovery ----------------------------------
67 #
68 # Pass an initial list of hosts to perform discovery when this node is started:
69 # The default list of hosts is ["127.0.0.1", "[::1]"]
70 #
71 #discovery.seed_hosts: ["host1", "host2"]
72 #
73 # Bootstrap the cluster using an initial set of master-eligible nodes:
74 # 初始化節點,可以有多個
75 cluster.initial_master_nodes: ["es-node-0"]
76 #
77 # For more information, consult the discovery and cluster formation module documentation.
78 #
79 # ---------------------------------- Gateway -----------------------------------
80 #
81 # Block initial recovery after a full cluster restart until N nodes are started:
82 #
83 #gateway.recover_after_nodes: 3
84 #
85 # For more information, consult the gateway module documentation.
86 #
87 # ---------------------------------- Various -----------------------------------
88 #
89 # Require explicit names when deleting indices:
90 #
91 #action.destructive_requires_name: true
# 開啟賬號驗證
92 xpack.security.enabled: true
93 xpack.license.self_generated.type: basic
94 xpack.security.transport.ssl.enabled: true
95 # 跨域的配置,可配可不配
96 http.cors.enabled: true
97 http.cors.allow-origin: "*"
因為安全問題elasticsearch 不讓用root用戶直接運行,所以要創建新用戶:
useradd es
passwd es
然後輸入密碼,最小8位數,為用戶賦權限:
chown -R es:es /usr/local/es/
切換成es用戶,cd 到bin目錄下啟動,第一種是前台啟動,第二種是後台啟動:
./elasticsearch
./elasticsearch -d

如果啟動提示了這個錯誤需要在/etc/sysctl.conf文件最後添加一行
vm.max_map_count=262144
執行/sbin/sysctl -p 立即生效,之後再重新啟動就好了;
在上面ES的yml配置中,我們配置了賬號驗證,所以我們需要重置一下ES賬號的密碼(確保es已經成功啟動才能重置;在es的bin目錄下執行):
./elasticsearch-setup-passwords interactive
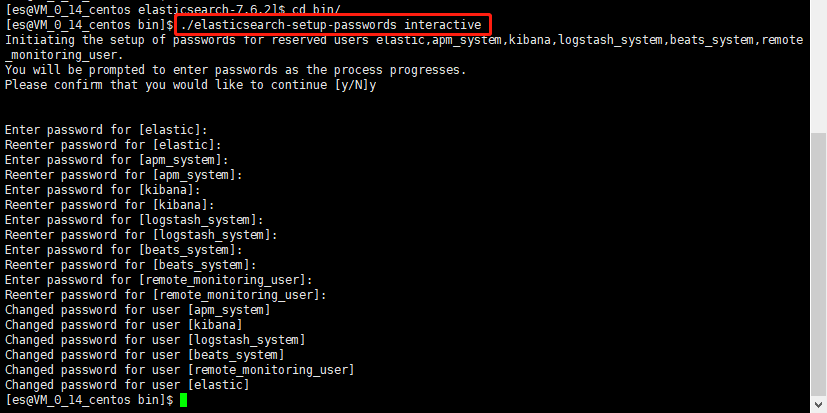
建議設置成相同的密碼,方便記憶,設置成功後就可以直接打開網頁去訪問了,訪問地址是ip:9200,然後輸入賬號:「elastic」,密碼:「123456」

能看到這些就代表ES已經成功啟動了!!!
(註:如果小夥伴們是雲服務器的話要注意開放服務器的安全組,不然訪問不到,開放9200和9300端口,下面的Kibana也需要開放5601的端口!!!)
然後我們現在配置一下ik分詞器(中文分詞):
ik分詞器也是同理,版本必須一致!!!然後把文件上傳到ES的plugins目錄下,創建ik目錄,解壓到ik目錄下即可。
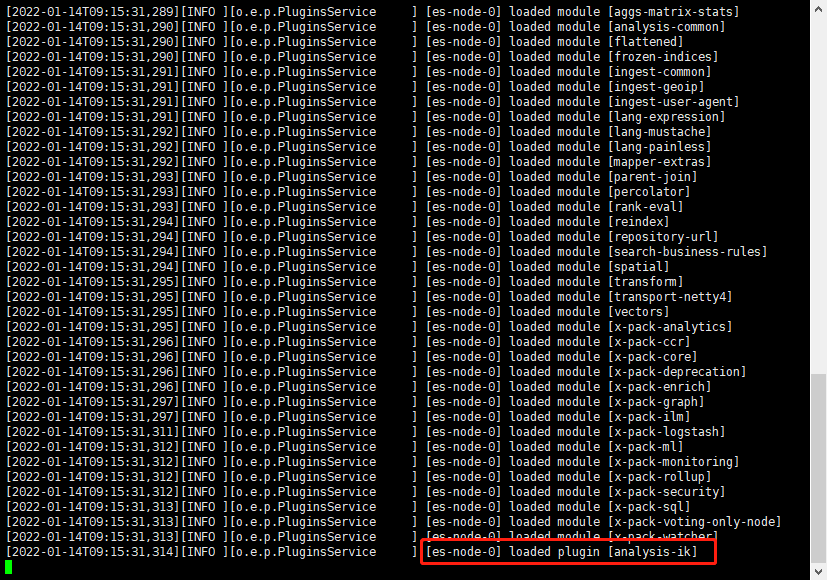
啟動的時候出現這個就代表配置成功了。
2、接下來我們開始配置Kibana:
Kibana的版本也需要和ES對應才行(官方地址://www.elastic.co/cn/support/matrix#matrix_compatibility):


下載好的Kibana上傳後進行解壓縮(官方下載地址://www.elastic.co/cn/downloads/kibana#ga-release):
tar -zxvf kibana-7.6.2-linux-x86_64.tar.gz
修改config目錄下的kibana.yml文件:
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
#server.host: "localhost"
# 代表都能訪問
server.host: "0.0.0.0"
# Enables you to specify a path to mount Kibana at if you are running behind a proxy.
# Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath
# from requests it receives, and to prevent a deprecation warning at startup.
# This setting cannot end in a slash.
#server.basePath: ""
# Specifies whether Kibana should rewrite requests that are prefixed with
# `server.basePath` or require that they are rewritten by your reverse proxy.
# This setting was effectively always `false` before Kibana 6.3 and will
# default to `true` starting in Kibana 7.0.
#server.rewriteBasePath: false
# The maximum payload size in bytes for incoming server requests.
#server.maxPayloadBytes: 1048576
# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"
# The URLs of the Elasticsearch instances to use for all your queries.
# 配置ES的地址
elasticsearch.hosts: ["//192.168.0.4:9200"]
# When this setting's value is true Kibana uses the hostname specified in the server.host
# setting. When the value of this setting is false, Kibana uses the hostname of the host
# that connects to this Kibana instance.
#elasticsearch.preserveHost: true
# Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
#kibana.index: ".kibana"
# The default application to load.
#kibana.defaultAppId: "home"
# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
# ES的賬號密碼
elasticsearch.username: "elastic"
elasticsearch.password: "123456"
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key
# Optional settings that provide the paths to the PEM-format SSL certificate and key files.
# These files are used to verify the identity of Kibana to Elasticsearch and are required when
# xpack.security.http.ssl.client_authentication in Elasticsearch is set to required.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]
# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
#elasticsearch.shardTimeout: 30000
# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
#elasticsearch.startupTimeout: 5000
# Logs queries sent to Elasticsearch. Requires logging.verbose set to true.
#elasticsearch.logQueries: false
# Specifies the path where Kibana creates the process ID file.
#pid.file: /var/run/kibana.pid
# Enables you specify a file where Kibana stores log output.
#logging.dest: stdout
# Set the value of this setting to true to suppress all logging output.
#logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages.
#logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information
# and all requests.
#logging.verbose: false
# Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to 5000.
#ops.interval: 5000
# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English - en , by default , Chinese - zh-CN .
# 配置中文
i18n.locale: "zh-CN"
配置完成後啟動ES,再輸入命令啟動kibana(在bin目錄下輸入該命令) :
nohup ./kibana &
如果不想後台啟動的直接輸入:
./kibana
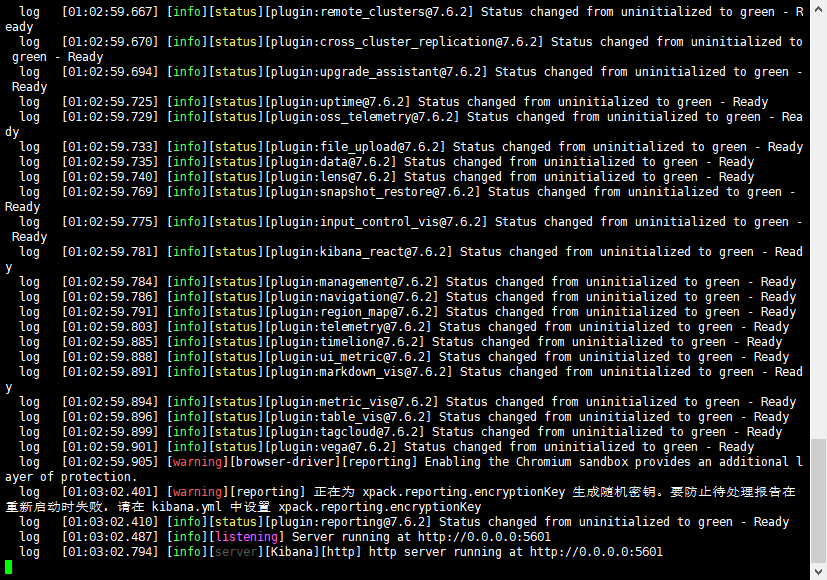
沒有出現error就可以直接ip:5601去訪問了,然後輸入之前ES設置的賬號:elastic 密碼:123456,然後大功告成!!!
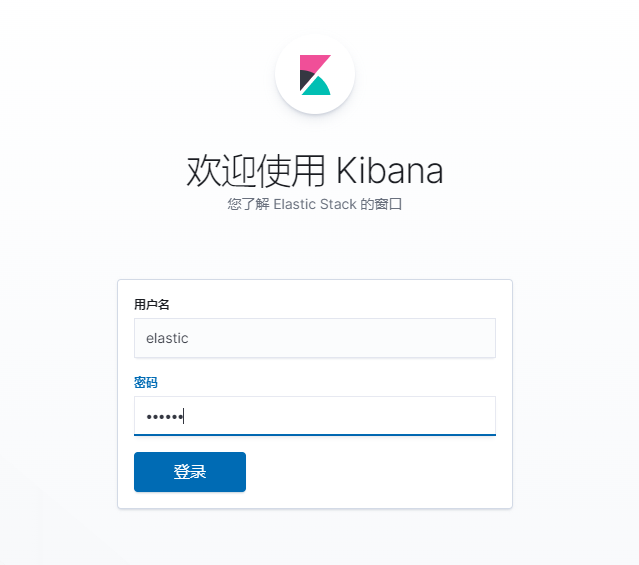
kibana的操作後面集成了spring boot後再做簡單的介紹。
3、最後開始集成到我們的spring boot項目中去,我本地的spring boot版本是2.3.4版本
下面是需要引用的jar包,在pom文件中添加以下依賴:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
一般情況下spring boot會自動對應相應的ES版本,下載好jar包後可以看項目下的jar包的版本,確認一下,版本是否正確,我這邊是7.6.2的版本。
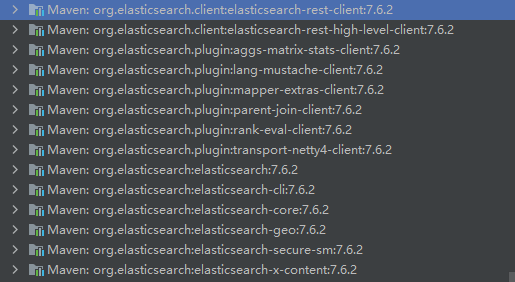
如果版本不正確的話可以手動修改一下版本,在pom.xml文件中的<properties>添加如下代碼:
<properties>
<elasticsearch.version>7.6.2</elasticsearch.version>
</properties>
配置ES連接bean:
package com.zsi.geek_insight.config;
import com.zsi.geek_insight.util.EsUtils;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchConfiguration {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.username}")
private String USERNAME;
@Value("${elasticsearch.password}")
private String PASSWORD;
@Bean(destroyMethod = "close", name = "client")
public RestHighLevelClient restHighLevelClient() {
//如果沒配置密碼就可以不用下面這兩部
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(USERNAME, PASSWORD));
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port, "http"))
.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
});
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);
// 這裡我寫了一個靜態的工具類,所以笨笨的寫了一個ES的初始化,
// 有大佬可以麻煩幫忙指點一下看有什麼更好的方案讓靜態的工具類能拿到注入到spring中的bean
new EsUtils().init(restHighLevelClient);
return restHighLevelClient;
}
}
ES操作工具類:
package com.zsi.geek_insight.util;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BackoffPolicy;
import org.elasticsearch.action.bulk.BulkProcessor;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.ByteSizeUnit;
import org.elasticsearch.common.unit.ByteSizeValue;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.function.BiConsumer;
@Slf4j
public class EsUtils {
private static RestHighLevelClient restHighLevelClient;
public void init(RestHighLevelClient restHighLevelClient) {
this.restHighLevelClient = restHighLevelClient;
}
/**
* @description: 創建索引
* @param: indexName 索引名
* @return: boolean 返回對象*/
public static boolean createIndex(String indexName) {
//返回結果
boolean exists = true;
try {
// 1、創建索引請求
CreateIndexRequest request = new CreateIndexRequest(indexName);
// 2、客戶端執行請求 indexResponse, 請求後獲得相應
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
//判斷響應對象是否為空
if (createIndexResponse.equals("") || createIndexResponse != null) {
exists = false;
}
} catch (IOException e) {
exists = false;
}
return exists;
}
/**
* @description: 測試獲取索引,只能判斷其是否存在
* @param: indexName 需要判斷的對象
* @return: 執行結果*/
public static boolean isIndexExists(String indexName) {
boolean exists = true;
try {
GetIndexRequest request = new GetIndexRequest(indexName);
exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
} catch (IOException e) {
exists = false;
}
return exists;
}
/**
* @description: 刪除索引
* @param: indexName 需要刪除的索引對象
* @return: 執行結果*/
public static boolean delIndex(String indexName) {
boolean exists = true;
try {
DeleteIndexRequest request = new DeleteIndexRequest(indexName);
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
exists = delete.isAcknowledged();
} catch (IOException e) {
exists = false;
}
return exists;
}
/**
* @description: 創建文檔
* @param: indexName 索引名稱
* @param: obj 文檔對象
* @param: id 文檔對象id (不可重複)
* @return: 執行結果*/
public static boolean addDocument(String indexName, Object obj, String id) {
boolean exists = true;
IndexResponse indexResponse = null;
try {
// 創建請求
IndexRequest request = new IndexRequest(indexName);
// 規則 put /kuang_index/_doc/1
request.id(id);
request.timeout(TimeValue.timeValueDays(1));
// 將我們的數據放入請求 json
request.source(JSON.toJSONString(obj), XContentType.JSON);
// 客戶端發送請求,獲取響應結果
indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
if (!indexResponse.equals("CREATED")) {//判斷響應結果對象是否為CREATED
exists = false;
}
} catch (IOException e) {
exists = false;
}
return exists;
}
/**
* @description: 獲取文檔,判斷是否存在
* @param: indexName 索引名稱
* @param: id 文檔對象id
* @return: 執行結果*/
public static boolean isExists(String indexName, String id) {
boolean exists = true;
try {
GetRequest request = new GetRequest(indexName, id);
// 不獲取返回的 _source 的上下文了
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* @description: 根據id獲取文檔信息
* @param: indexName 索引名稱
* @param: id 文檔對象id
* @return: 執行結果*/
public static Map getDocument(String indexName, String id) {
Map strToMap = null;
try {
GetRequest request = new GetRequest("testspringboot", "1");
GetResponse getResponse = restHighLevelClient.get(request, RequestOptions.DEFAULT);
strToMap = JSONObject.parseObject(getResponse.getSourceAsString());
} catch (IOException e) {
e.printStackTrace();
}
return strToMap;
}
/**
* @description: 更新文檔的信息
* @param: indexName 索引名稱
* @param: obj 文檔對象
* @param: id 文檔對象id (不可重複)
* @return: 執行結果*/
public static boolean updateDocument(String indexName, Object obj, String id) {
boolean exists = true;
try {
UpdateRequest updateRequest = new UpdateRequest(indexName, id);
updateRequest.timeout("1s");
updateRequest.doc(JSON.toJSONString(obj), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
if (!updateResponse.status().equals("OK")) {
exists = false;
}
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* @description: 刪除文檔記錄
* @param: indexName 索引名稱
* @param: id 文檔對象id (不可重複)
* @return: 執行結果*/
public static boolean deleteRequest(String indexName, String id) {
boolean exists = true;
try {
DeleteRequest request = new DeleteRequest(indexName, id);
request.timeout("1s");
DeleteResponse delete = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
if (!delete.status().equals("OK")) {
exists = false;
}
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* @description: 批量插入
* @param: indexName 索引名稱
* @param: objectArrayList 需要添加的數據
* @return:*/
public static boolean bulkRequest(ArrayList<Map<String, Object>> objectArrayList, String indexName, String value) {
boolean exists = true;
BulkProcessor bulkProcessor = getBulkProcessor(restHighLevelClient);
try {
for (int i = 0; i < objectArrayList.size(); i++) {
bulkProcessor.add(new IndexRequest(indexName)
.id(objectArrayList.get(i).get(value).toString())
.source(JSON.toJSONString(objectArrayList.get(i)), XContentType.JSON));
}
// 將數據刷新到es, 注意這一步執行後並不會立即生效,取決於bulkProcessor設置的刷新時間
bulkProcessor.flush();
} catch (Exception e) {
log.error(e.getMessage());
} finally {
try {
boolean terminatedFlag = bulkProcessor.awaitClose(150L, TimeUnit.SECONDS);
log.info(String.valueOf(terminatedFlag));
} catch (Exception e) {
log.error(e.getMessage());
}
}
return exists;
}
/**
* 創建bulkProcessor並初始化
*
* @param client
* @return
*/
private static BulkProcessor getBulkProcessor(RestHighLevelClient client) {
BulkProcessor bulkProcessor = null;
try {
BulkProcessor.Listener listener = new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId, BulkRequest request) {
log.info("Try to insert data number : " + request.numberOfActions());
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
log.info("************** Success insert data number : " + request.numberOfActions() + " , id: "
+ executionId);
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
log.error("Bulk is unsuccess : " + failure + ", executionId: " + executionId);
}
};
BiConsumer<BulkRequest, ActionListener<BulkResponse>> bulkConsumer = (request, bulkListener) -> client
.bulkAsync(request, RequestOptions.DEFAULT, bulkListener);
BulkProcessor.Builder builder = BulkProcessor.builder(bulkConsumer, listener);
// 設置最大的上傳數量
builder.setBulkActions(1000);
builder.setBulkSize(new ByteSizeValue(100L, ByteSizeUnit.MB));
// 設置最多的線程並發數
builder.setConcurrentRequests(2);
builder.setFlushInterval(TimeValue.timeValueSeconds(100L));
builder.setBackoffPolicy(BackoffPolicy.constantBackoff(TimeValue.timeValueSeconds(1L), 3));
// 注意點:在這裡感覺有點坑,官網樣例並沒有這一步,而筆者因一時粗心也沒注意,在調試時注意看才發現,上面對builder設置的屬性沒有生效
bulkProcessor = builder.build();
} catch (Exception e) {
e.printStackTrace();
try {
bulkProcessor.awaitClose(100L, TimeUnit.SECONDS);
client.close();
} catch (Exception e1) {
log.error(e1.getMessage());
}
}
return bulkProcessor;
}
/**
* @description: 模糊查詢
* @param: indexName 索引名
* @param: key 字段名
* @param: value 查詢值
* @return:*/
public static List<Map<String, Object>> searchMatch(String indexName, String key, String value) throws IOException {
List<Map<String, Object>> map = new ArrayList<>();
SearchRequest searchRequest = new SearchRequest(indexName);
// 構建搜索條件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder termQueryBuilder = new MatchQueryBuilder(key, value);
termQueryBuilder.fuzziness(Fuzziness.AUTO);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
map.add(documentFields.getSourceAsMap());
}
return map;
}
/**
* @description: 精確查詢
* @param: indexName 索引名
* @param: key 字段名
* @param: value 查詢值
* @return:*/
public static List<Map<String, Object>> searchQuery(String indexName, String key, String value) throws IOException {
List<Map<String, Object>> map = new ArrayList<>();
SearchRequest searchRequest = new SearchRequest(indexName);
// 構建搜索條件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery(key, value);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
map.add(documentFields.getSourceAsMap());
}
return map;
}
}
準備查詢的Entity:
package com.zsi.geek_insight.model.FinancialRegulations;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@AllArgsConstructor
@NoArgsConstructor
// 參數依次數:索引名稱,主分片區個數,拷貝分區個數
@Document(indexName = "financialregulations", shards = 1, replicas = 0)
public class FinancialRegulationsES {
@Id
private String regulationsId;
// 需要分詞、查詢的字段需要加上這個註解
// 字符串類型(text:支持分詞,全文檢索,支持模糊、精確查詢,不支持聚合,排序操作;text類型的最大支持的字符長度無限制,適合大字段存儲;),
// 存儲時的分詞器、搜索時用的分詞器(這裡用的都是ik分詞器,IK提供了兩個分詞算法: (ik_smart和ik_max_word ),其中ik_smart為最少切分,ik_max_word為最細粒度劃分!)
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")
private String regulationsName;
private String timeliness;
private String IssuedNumber;
private String releaseDate;
@Field(type = FieldType.Text ,analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")
private String textContent;
private String implementationDate;
private String file;
}
準備調用的Controller:
package com.zsi.geek_insight.controller;
import com.zsi.geek_insight.model.FinancialRegulations.FinancialRegulationsES;
import com.zsi.geek_insight.util.EsUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Controller
@RequestMapping(value = "/financialRegulationsData")
public class FinancialRegulationsDataController {
@Autowired
private ElasticsearchRestTemplate elasticsearchTemplate;
/**
* 根據名稱進行查詢
*/
@RequestMapping(value = "/getByName", method = RequestMethod.GET)
@ResponseBody
public List<FinancialRegulationsES> getByName(@RequestParam String name) throws IOException {
//根據一個值查詢多個字段 並高亮顯示 這裡的查詢是取並集,即多個字段只需要有一個字段滿足即可
//需要查詢的字段
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("regulationsName", name));
//構建高亮查詢
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
//設置查詢條件
.withHighlightFields(new HighlightBuilder.Field("regulationsName"))
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
//設置分頁查詢
.withPageable(PageRequest.of(0, 10))
.build();
SearchHits<FinancialRegulationsES> search = elasticsearchTemplate.search(searchQuery, FinancialRegulationsES.class);
//得到查詢返回的內容
List<SearchHit<FinancialRegulationsES>> searchHits = search.getSearchHits();
//設置一個最後需要返回的實體類集合
List<FinancialRegulationsES> users = new ArrayList<>();
//遍歷返回的內容進行處理
for (SearchHit<FinancialRegulationsES> searchHit : searchHits) {
//高亮的內容
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
//將高亮的內容填充到content中
searchHit.getContent().setTextContent(highlightFields.get("regulationsName") == null ? searchHit.getContent().getRegulationsName() : highlightFields.get("regulationsName").get(0));
//放到實體類中
users.add(searchHit.getContent());
}
return users;
}
/**
* 添加數據
*/
@RequestMapping(value = "/addAll", method = RequestMethod.GET)
@ResponseBody
public String addAll() {
List<Map<String, Object>> content = new ArrayList<>();
Map<String, Object> map = new HashMap<>();
map.put("regulationsId","1");
map.put("regulationsName","中國銀保監會消費者權益保護局關於安心財險、輕鬆保經紀、津投經紀、保多多經紀侵害消費者權益案例的通報");
map.put("timeliness","現行有效");
map.put("IssuedNumber","銀保監消保發〔2020〕14號");
map.put("releaseDate","2020-12-02");
map.put("textContent","中國銀保監會消費者權益保護局關於安心財險、輕鬆保經紀、津投經紀、保多多經紀侵害消費者權益案例的通報\n" +
"\n" +
"\n" +
"中國銀保監會消費者權益保護局關於安心財險、輕鬆保經紀、津投經紀、保多多經紀侵害消費者權益案例的通報\n" +
"銀保監消保發〔2020〕14號\n" +
"各銀保監局,各政策性銀行、大型銀行、股份制銀行,外資銀行,各保險集團(控股)公司、保險公司,各會管單位:\n" +
"為踐行以人民為中心的發展思想,落實依法監管理念,切實維護銀行保險消費者合法權益,我會對安心財產保險有限責任公司(以下簡稱安心財險)開展了專項檢查,並根據檢查線索,對廣東輕鬆保保險經紀有限公司(原名廣東宏廣安保險經紀有限公司,以下簡稱輕鬆保經紀)、天津津投保險經紀有限公司(以下簡稱津投經紀)、保多多保險經紀有限公司(以下簡稱保多多經紀)開展了延伸檢查。\n" +
"檢查發現,上述機構在宣傳銷售短期健康險產品中,存在「首月0元」「首月0.1元」等不實宣傳(實際是將首月保費均攤至後期保費),或首月多收保費等問題。上述行為涉嫌違反《保險法》中「未按照規定使用經批准或者備案的保險條款、保險費率」「欺騙投保人」等相關規定。現將有關問題通報如下: \n" +
"一、欺騙投保人問題\n" +
"(一)安心財險\n" +
"經查,2019年1月至6月,安心財險通過輕鬆保經紀微信平台公眾號「輕鬆保官方」銷售「安享一生尊享版」產品時,宣傳頁面顯示「首月0元」「限時特惠 首月立減**元」等內容,實際是首月不收取保費,將全年應交保費均攤至後11個月,消費者並未得到保費優惠。涉及保單16879筆,保費收入396.34萬元。\n" +
"(二)輕鬆保經紀(第三方網絡平台為輕鬆保)\n" +
"經查,2019年4月至10月,輕鬆保經紀在微信平台公眾號「輕鬆保官方」銷售眾惠財產相互保險社「年輕保·600萬醫療保障」產品時,銷售頁面顯示「首月0.1元」「首月3元」「會員日補貼」等內容,實際是將全年應交保費扣除首月0.1元或3元的保費後,將剩餘保費均攤至後11個月,消費者並未得到保費優惠。涉及保單377489筆,保費收入5188.97萬元。\n" +
"上述通過「限時特惠」「會員日補貼」等宣傳,以「零首付」等方式,給投保人優惠(豁免或減少)應交保費錯覺、誘導投保人購買保險的行為,屬於虛假宣傳、欺騙投保人。\n" +
"二、未按照規定使用經批准或者備案的保險條款、保險費率問題\n" +
"(一)津投經紀(第三方網絡平台為京東)\n" +
"經查,2018年10月至2019年6月,津投經紀在京東金融APP銷售華泰財產保險有限公司「京英百萬醫療險(福利版)」產品時,宣傳頁面顯示「首月1元」等內容,實際是將首月應交的其餘保費均攤到剩餘的11期保費中收取,涉及保單16874筆,保費收入417.72萬元。\n" +
"2019年1月至2019年6月,津投經紀在京東金融APP銷售華泰財產保險有限公司「京享重疾輕症險(福利版)」時,宣傳頁面顯示「首月1元」等內容,實際是將首月應交的其餘保費均攤到剩餘11期保費中收取,涉及保單3601筆,保費收入30.74萬元。\n" +
"(二)保多多經紀(第三方網絡平台為水滴)\n" +
"經查,2019年3月至2019年6月,保多多經紀在微信平台公眾號及「水滴保險商城」APP銷售太平財產保險有限公司「太平綜合醫療保險」產品時,首期保費按「首月3元」活動收取,但該產品在銀保監會報備的條款費率表中僅有「按月繳費(首月投保0元,其餘分11期支付)」描述。該行為涉及保單1547267筆,保費12682.91萬元。\n" +
"安心財險、輕鬆保經紀、津投經紀、保多多經紀等保險機構的上述行為,嚴重侵害了消費者的知情權、公平交易權等基本權利,損害了消費者的合法權益。我局將嚴格依法依規進行處理。各銀行保險機構要引起警示,圍繞營銷宣傳、產品銷售等方面侵害消費者權益亂象開展自查自糾,嚴格按照相關法律法規和監管規定,依法、合規開展經營活動,切實保護消費者合法權益。\n" +
"中國銀保監會消費者權益保護局\n" +
"2020年12月2日\n" +
"\n");
map.put("implementationDate","2020-12-02");
content.add(map);
map = new HashMap<>();
map.put("regulationsId","2");
map.put("regulationsName","全國人民代表大會常務委員會關於修改《中華人民共和國個人所得稅法》的決定(2011)");
map.put("timeliness","現行有效");
map.put("IssuedNumber","中華人民共和國主席令第48號");
map.put("releaseDate","2011-06-30");
map.put("textContent","全國人民代表大會常務委員會關於修改《中華人民共和國個人所得稅法》的決定(2011)\n" +
"中華人民共和國主席令\n" +
"(第四十八號) \n" +
" 《全國人民代表大會常務委員會關於修改<中華人民共和國個人所得稅法>的決定》已由中華人民共和國第十一屆全國人民代表大會常務委員會第二十一次會議於2011年6月30日通過,現予公布,自2011年9月1日起施行。 \n" +
" 中華人民共和國主席 ***\n" +
"2011年6月30日\n" +
"全國人民代表大會常務委員會關於修改《中華人民共和國個人所得稅法》的決定\n" +
"(2011年6月30日第十一屆全國人民代表大會常務委員會第二十一次會議通過)\n" +
"\n" +
" 第十一屆全國人民代表大會常務委員會第二十一次會議決定對《中華人民共和國個人所得稅法》作如下修改:\n" +
" \n" +
" 一、第三條第一項修改為:「工資、薪金所得,適用超額累進稅率,稅率為百分之三至百分之四十五(稅率表附後)。」\n" +
" 二、第六條第一款第一項修改為:「工資、薪金所得,以每月收入額減除費用三千五百元後的餘額,為應納稅所得額。」\n" +
" 三、第九條中的「七日內」修改為「十五日內」。\n" +
" 四、個人所得稅稅率表一(工資、薪金所得適用)修改為:\n" +
" 級數 全月應納稅所得額 稅率(%)\n" +
"\n" +
" 1 不超過1500元的 3\n" +
"\n" +
" 2 超過1500元至4500元的部分 10\n" +
"\n" +
" 3 超過4500元至9000元的部分 20\n" +
"\n" +
" 4 超過9000元至35000元的部分 25\n" +
"\n" +
" 5 超過35000元至55000元的部分 30\n" +
"\n" +
" 6 超過55000元至80000元的部分 35\n" +
"\n" +
" 7 超過80000元的部分 45\n" +
" (註:本表所稱全月應納稅所得額是指依照本法第六條的規定,以每月收入額減除費用三千五百元以及附加減除費用後的餘額。)\n" +
" 五、個人所得稅稅率表二(個體工商戶的生產、經營所得和對企事業單位的承包經營、承租經營所得適用)修改為:\n" +
" 級數 全年應納稅所得額 稅率(%)\n" +
"\n" +
" 1 不超過15000元的 5\n" +
"\n" +
" 2 超過15000元至30000元的部分 10\n" +
"\n" +
" 3 超過30000元至60000元的部分 20\n" +
"\n" +
" 4 超過60000元至100000元的部分 30\n" +
"\n" +
" 5 超過100000元的部分 35\n" +
" (註:本表所稱全年應納稅所得額是指依照本法第六條的規定,以每一納稅年度的收入總額減除成本、費用以及損失後的餘額。)\n" +
" 本決定自2011年9月1日起施行。\n" +
" 《中華人民共和國個人所得稅法》根據本決定作相應修改,重新公布。\n");
map.put("implementationDate","2011-09-01");
content.add(map);
EsUtils.bulkRequest(new ArrayList<>(content), "financialregulations","regulationsId");
return "ok";
}
/**
* 添加索引
*/
@RequestMapping(value = "/addIndex", method = RequestMethod.GET)
@ResponseBody
public String addIndex() throws IOException {
IndexOperations ops = elasticsearchTemplate.indexOps(FinancialRegulationsES.class);
if (!ops.exists()){
ops.create();
ops.refresh();
ops.putMapping(ops.createMapping());
}
return "ok";
}
}
準備好後啟動服務開始調用接口,先調用添加索引的接口”/financialRegulationsData/addIndex”,成功後前往「//ip:5601/」查看索引是否添加成功:
點擊左上角的默認圖片,點擊管理空間,然後點索引管理就能看到所創建好的索引了:
這個就是我們剛剛創建好的索引:
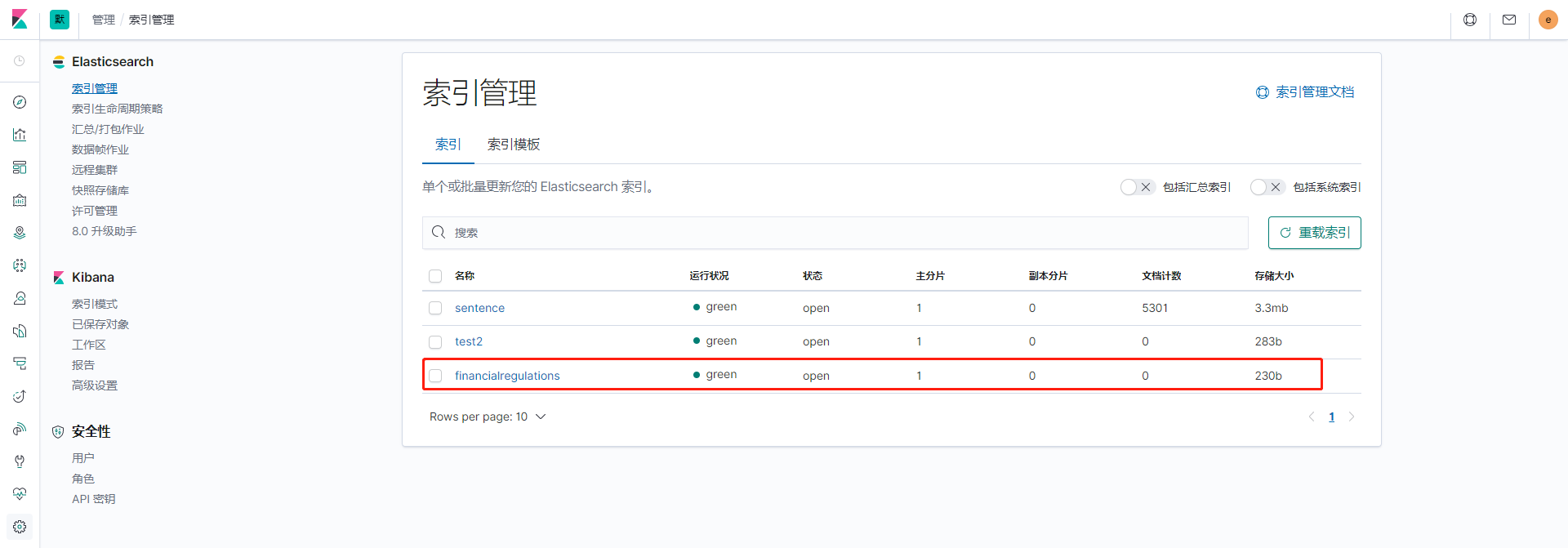
創建好索引後我們添加數據,調用/financialRegulationsData/addAll:
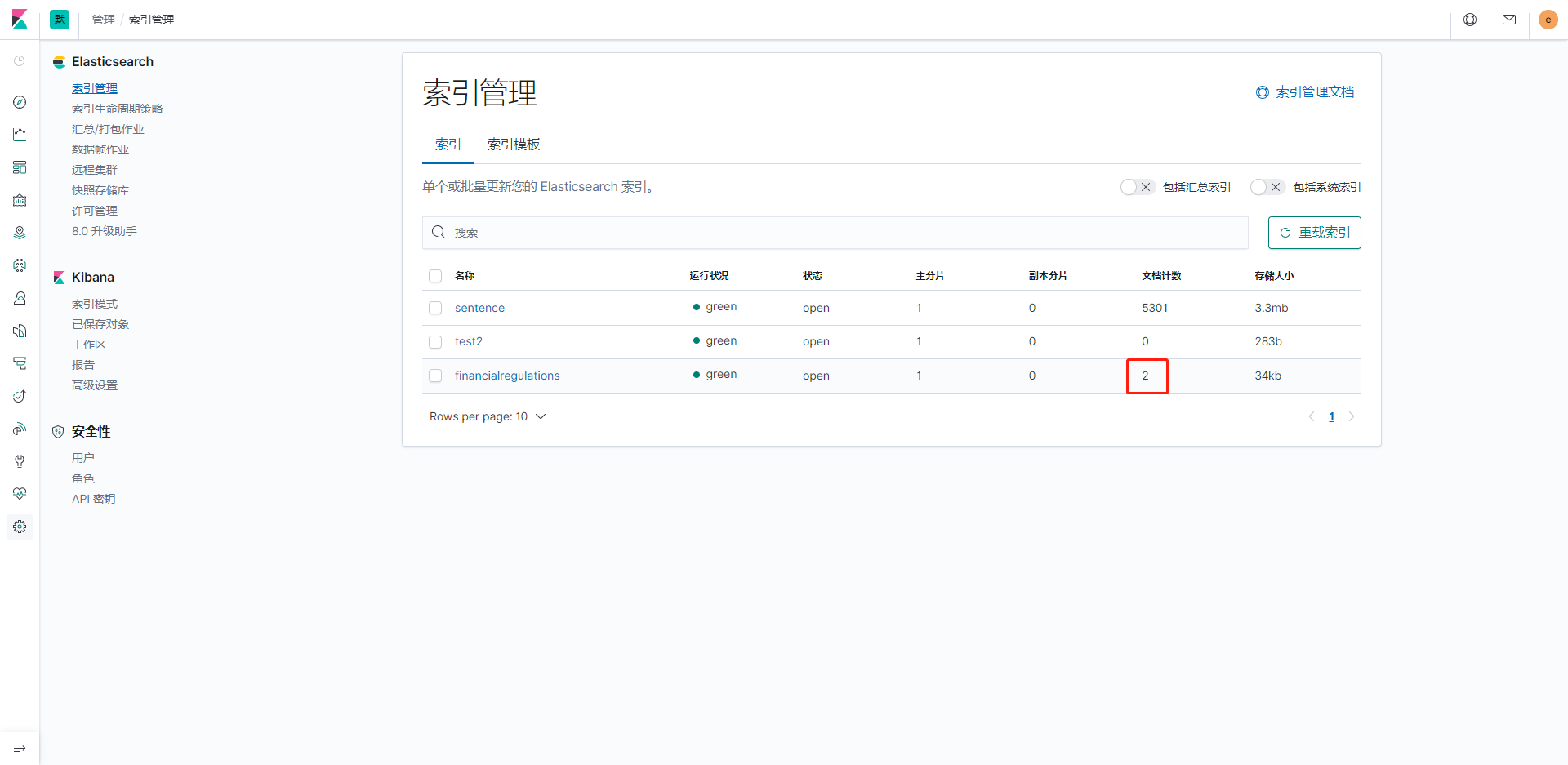
可以發現成功添加了兩條,然後我們現在可以看一下數據是否都添加進去了,點擊索引模式,點擊創建索引模式,根據索引名稱創建一個查詢界面:
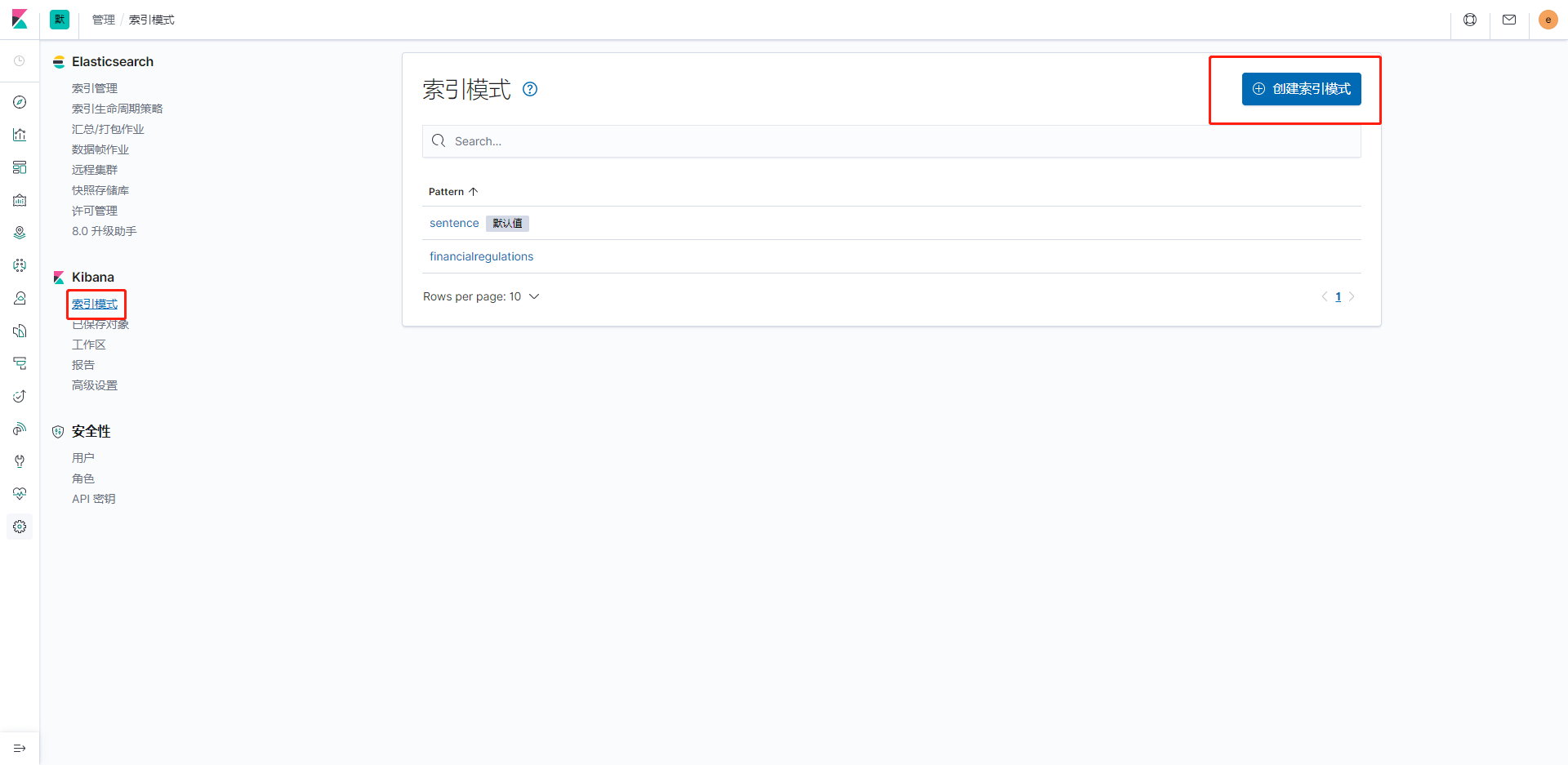
創建成功後點擊左菜單欄的指南針圖標Discover進去頁面查看:
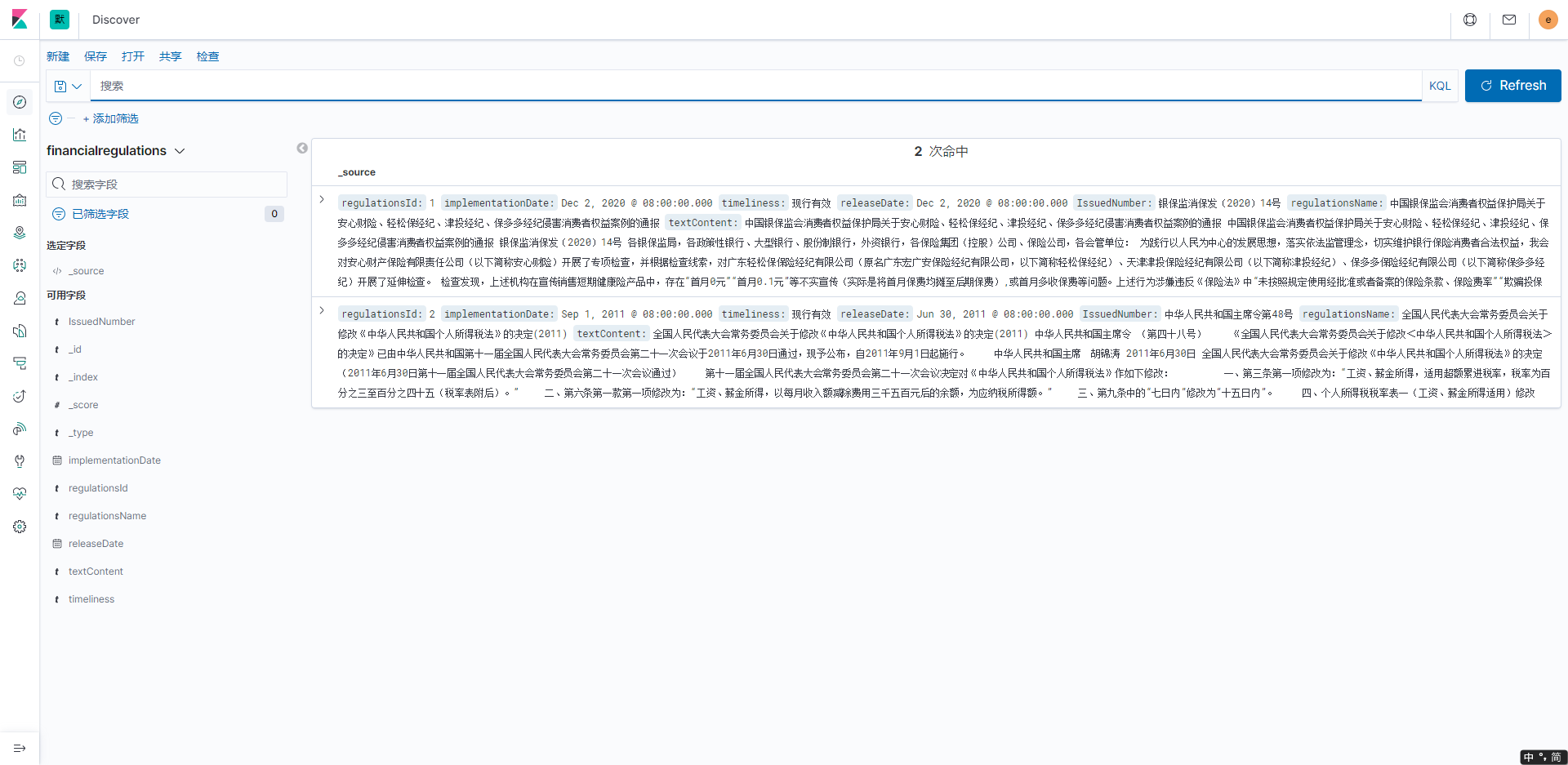
在這裡我們就能看到2條數據已經成功插入到了ES中,最後我們做查詢,輸入「銀保監會保護局」,查詢出來的數據也做了高亮的處理:
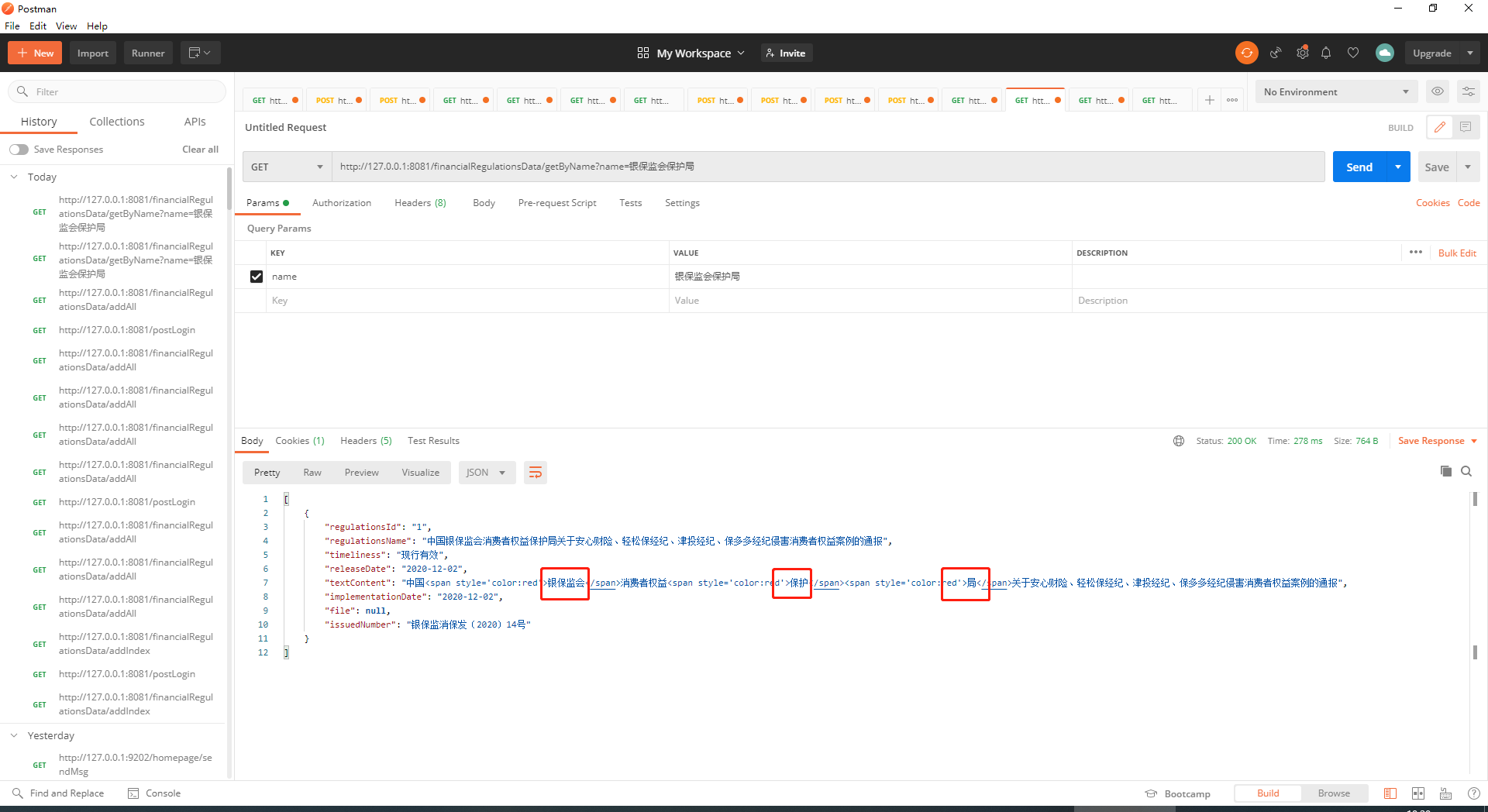
至此SpringBoot集成ES就暫時搞定了,最後提一點,ES的查詢默認不會超過1W條數據,如果需要超過1W條需要在kibana中輸入命令設置一下:
設置ES中最大的返回行數
PUT 索引名稱/_settings
{
"max_result_window":200000
}
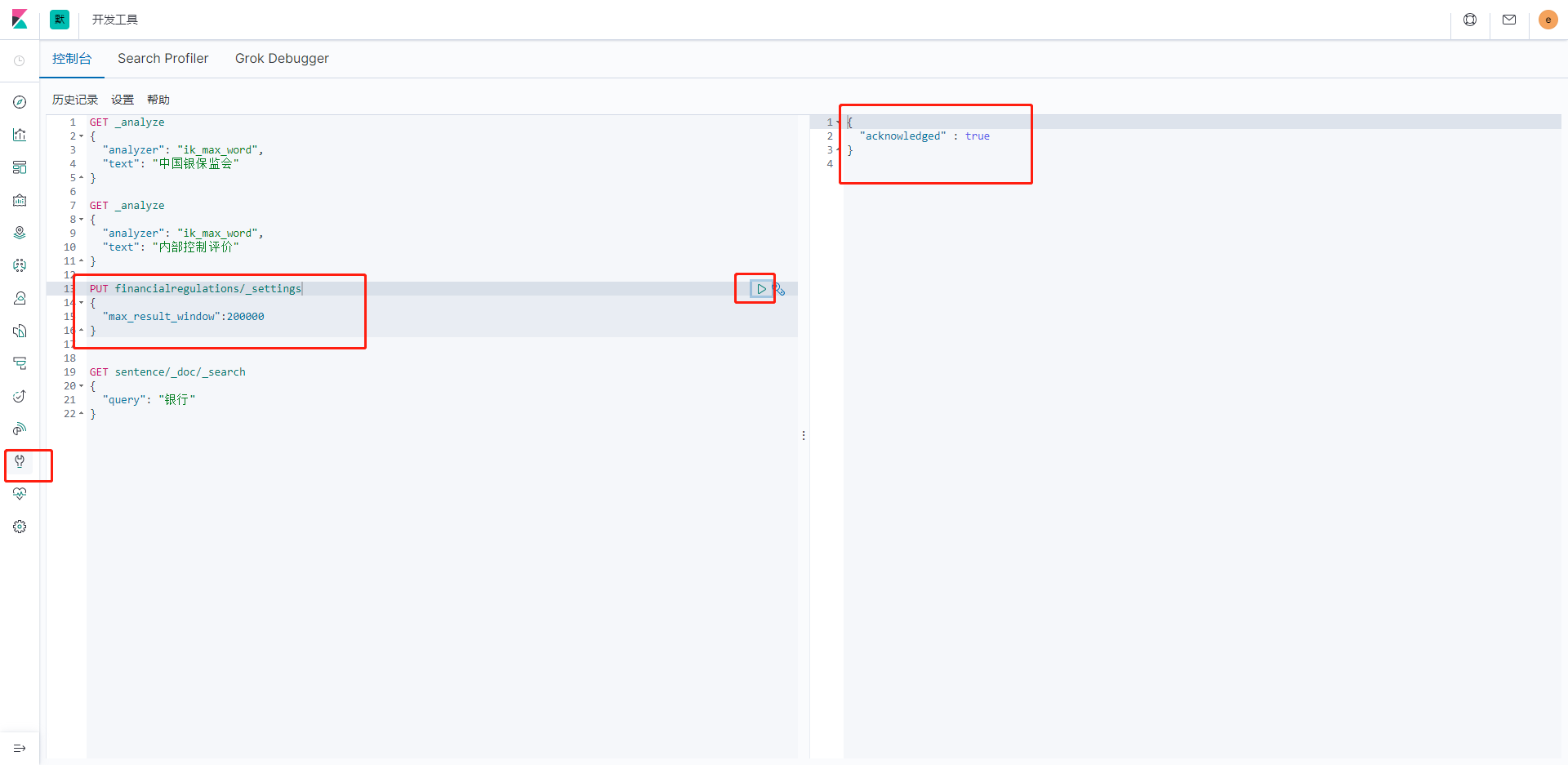
設置成功後就可以查詢超過1w條數據了,其中的數字大家酌情設置。
最後再和大家說一個小秘密,如果數據量較多的話,搜出來的內容越到後面越不準確,這個時候就需要增加一個設置了,需要在這句代碼後面加上一下內容,建議填寫百分比,這樣會稍微準確一點,如果填寫數字的話個人感覺效果不太好。
QueryBuilders.matchQuery("regulationsName", name).minimumShouldMatch("70%")
到這裡以上就是所有內容了,如有問題歡迎指正!
修改、刪除由於篇幅問題如果大家有需要的話我再更新一波。


