Python多線程、線程池及實際運用
我們在寫python爬蟲的過程中,對於大量數據的抓取總是希望能獲得更高的速度和效率,但由於網絡請求的延遲、IO的限制,單線程的運行總是不能讓人滿意。因此有了多線程、異步協程等技術。
下面介紹一下python中的多線程及線程池技術,並通過一個具體的爬蟲案例實現具體運用。
多線程
先來分析單線程。寫兩個測試函數
def func1():
for i in range(500000):
print("func1", i)
def func2():
for i in range(500000):
print("func2", i)
在主函數中調用
if __name__ == "__main__":
func1()
func2()
當程序執行時,按照主程序中的執行順序,func1全部運行完畢後才會運行func2,這就是單線程的效果。
接下來測試多線程。
先導包
from threading import Thread
改造主函數
thread1 = Thread(target=func1)
thread1.start()
thread2 = Thread(target=func2)
thread2.start()
thread1.join()
thread2.join()
這裡的thread.join()是阻塞進程,因為這裡主函數中沒有
執行效果如下:
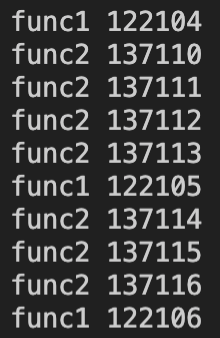
可以看到func1和func2函數分為兩個不同的線程同時工作、互不干擾。
線程池
以此類推,如果同時開着20個這樣的線程,是否可以同時執行呢?但手動分配這麼多線程顯然是不可能的,因此引入線程池這一概念,一次開闢一些進程,我們用戶直接給線程池提交任務,線程任務的調度交給線程池來完成。這樣一來,就能十分方便的分配線程的任務了。
首先導包
from concurrent.futures import ThreadPoolExecutor
改造一下子函數
def func(url):
for i in range(1000):
print(url)
主函數
if __name__ == "__main__":
# 創建線程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(func, url=f"線程{i}")
print("over")
我們建立一個線程池,分配50個線程,提交100個任務,讓他們去自由分配。現有的50個線程先去拿到了1-50這些任務,當誰先完成就去拿到51個任務,以此類推。相當於50個工人一起幹活,互不干涉,顯然效率較單人更高一些。
再來看運行結果

線程鎖
了解了線程池的基本概念之後就可以去改造我們的爬蟲了。但是在此之前該需要了解一個線程鎖的概念。先看下面這個例子
from threading import Thread
num = 0
def add():
global num
for i in range(100000):
num += 1
def minus():
global num
for i in range(100000):
num -= 1
if __name__=="__main__":
thread1 = Thread(target=add)
thread2 = Thread(target=minus)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(num)
開闢兩個線程,一個做自增一個做自減,他們兩個同時運行,按常理num最終的值應為0,但實際運行結果是不穩定的。

由於每個線程運行速度極快,因此在他們的臨界點都想對全局變量num操作時會出現競爭狀態,有可能出現數值丟失、自增失敗的情況,因此需要加入線程鎖來控制每次只允許有一個線程對全局變量num進行操作。
import threading
lock = threading.Lock()
lock.acquire()
num += 1
lock.release()
在線程中的關鍵操作加上線程鎖,再跑起來就不會出現競爭狀態了。

爬蟲實戰
要在爬蟲中運用到線程池,基本的思路很簡單,
1.如何抓取到單個頁面的數據
2.上線程池批量抓取
目標://www.dydytt.net/html/gndy/dyzz/list_23_1.html
這裡僅做線程池的基本實驗,具體案例移步這裡
先隨便寫個爬蟲拿到第一頁的所有電影標題數據
import requests
from lxml import etree
filmNameList = []
def download(url):
global filmNameList
resp = requests.get(url)
resp.encoding="gb2312"
html = etree.HTML(resp.text)
filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')
for each in filmName:
filmNameList.append(each)
pass
if __name__=="__main__":
url = "//www.dydytt.net/html/gndy/dyzz/list_23_1.html"
download(url)
for i in filmNameList:
print(i)
非常輕鬆的拿到了第一頁的數據

接下來上線程池
import requests
import threading
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
filmNameList = []
lock = threading.Lock()
def download(url):
global filmNameList
resp = requests.get(url)
resp.encoding="gb2312"
html = etree.HTML(resp.text)
filmName = html.xpath('//table[@class="tbspan"]/tr[2]/td[2]/b/a/text()')
for each in filmName:
lock.acquire()
filmNameList.append(each)
lock.release()
resp.close()
if __name__=="__main__":
with ThreadPoolExecutor(5) as t:
for i in range(1, 11):
url = f"//www.dydytt.net/html/gndy/dyzz/list_23_{i}.html"
t.submit(download, url=url)
for i in filmNameList:
print(i)
print(f"total_len is {len(filmNameList)}")
我們給線程池分配了5個線程,抓了前10頁共250條數據。
 ****
****


