TKE 用戶故事 | 作業幫 Kubernetes 原生調度器優化實踐
作者
呂亞霖,2019年加入作業幫,作業幫架構研發負責人,在作業幫期間主導了雲原生架構演進、推動實施容器化改造、服務治理、GO微服務框架、DevOps的落地實踐。
簡介
調度系統的本質是為計算服務/任務匹配合適的資源,使其能夠穩定高效地運行,以及在此的基礎上進一步提高資源使用密度,而影響應用運行的因素非常多,比如 CPU、內存、IO、差異化的資源設備等等一系列因素都會影響應用運行的表現。同時,單獨和整體的資源請求、硬件/軟件/策略限制、 親和性要求、數據區域、負載間的干擾等因素以及周期性流量場景、計算密集場景、在離線混合等不同的應用場景的交織也帶來了決策上的多變。
調度器的目標則是快速準確地實現這一能力,但快速和準確這兩個目標在資源有限的場景下會往往產生產生矛盾,需要在二者間權衡。
調度器原理和設計
K8s 默認調度器的整體工作框架,可以簡單用下圖概括:
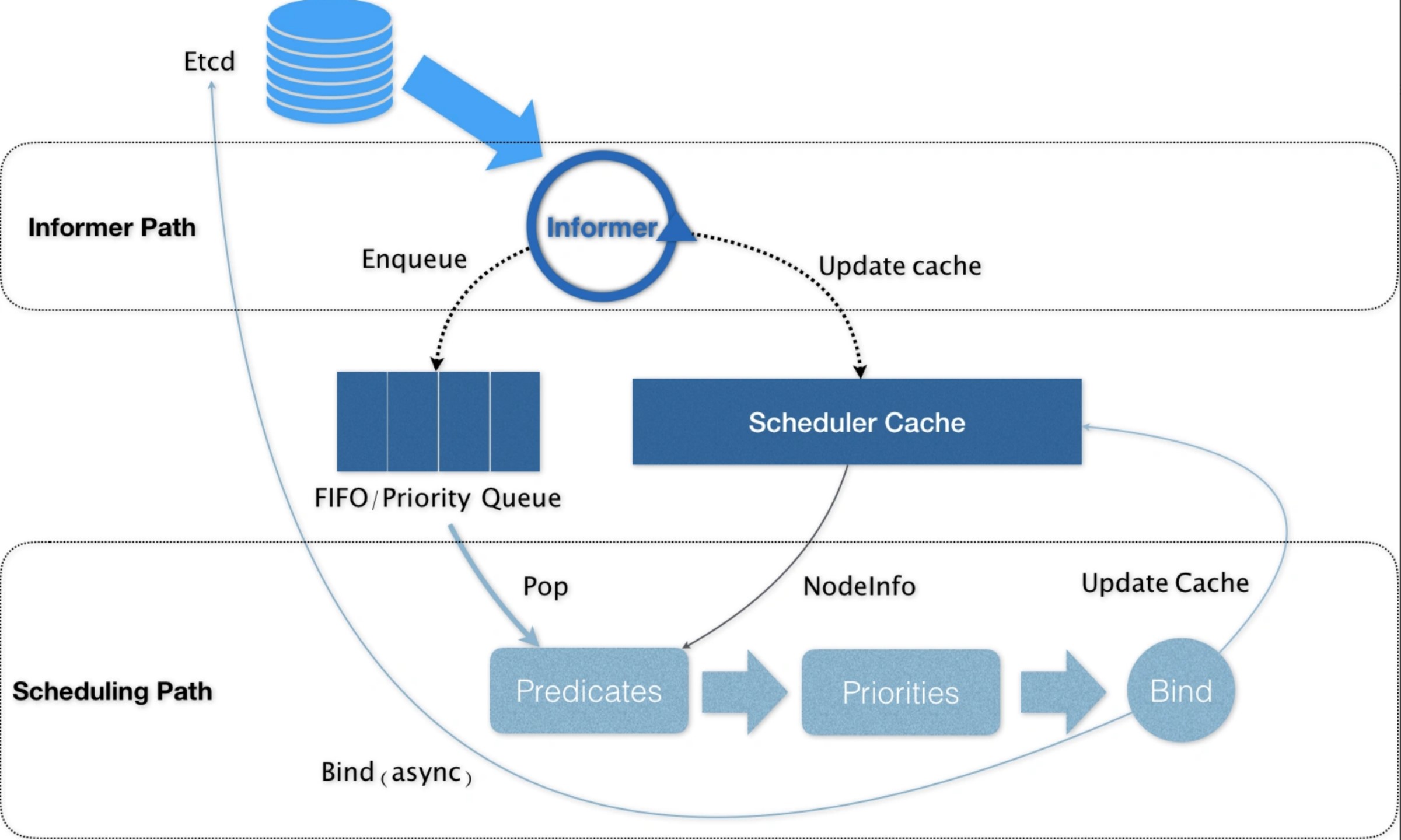
兩個控制循環
-
第一個控制循環,稱為 Informer Path。它的主要工作,是啟動一系列的 Informer,用來監聽(Watch)集群中 Pod、Node、Service 等與調度相關的 API 對象的變化。比如,當一個待調度 Pod 被創建出來之後,調度器就會通過 Pod Informer 的 Handler,將這個待調度 Pod 添加進調度隊列;同時,調度器還要負責對調度器緩存 Scheduler Cache 進行更新,並以這個 cache 為參考信息,來提高整個調度流程的性能。
-
第二個控制循環,即為對 pod 進行調度的主循環,稱為 Scheduling Path。這一循環的工作流程是不斷地從調度隊列中取出待調度的 pod,運行2個步驟的算法,來選出最優 node。
-
在集群的所有節點中,選出所有「可以」運行該 pod 的節點,這一步被稱為 Predicates;
-
在上一步選出的節點中,根據一些列優選算法對節點就行打分,選出「最優」即得分最高的節點,這一步被稱為 Priorities。
調度完成之後,調度器就會為 pod 的 spec.NodeName 賦值這個節點,這一步稱為 Bind。而為了不在主流程路徑中訪問 Api Server 影響性能,調度器只會更新 Scheduler Cache 中的相關 pod 和 node 信息:這種基於樂觀的假設的 Api 對象更新方式,在 K8s 中稱為 Assume。之後才會創建一個 goroutine 來異步地向 Api Server 發起更新 Bind 操作,這一步就算失敗了也沒有關係,Scheduler Cache 更新後就會一切正常。
大規模集群調度帶來的問題和挑戰
K8s 默認調度器策略在小規模集群下有着優異的表現,但是隨着業務量級的增加以及業務種類的多樣性變化,默認調度策略則逐漸顯露出了局限性:調度維度較少,無並發,存在性能瓶頸,以及調度器越來越複雜。
迄今為止,我們當前單個集群規模節點量千級,pod 量級則在 10w 以上,整體資源分配率超過60%,其中更是包含了 gpu,在離線混合部署等複雜場景;在這個過程中,我們遇到了不少調度方面的問題。
問題1:高峰期的節點負載不均勻
默認調度器,參考的是 workload 的 request 值,如果我們針對 request 設置的過高,會帶來資源的浪費;過低則有可能帶來高峰期 CPU 不均衡差異嚴重的情況;使用親和策略雖然可以一定程度避免這種,但是需要頻繁填充大量的策略,維護成本就會非常大。而且服務的 request 往往不能體現服務真實的負載,帶來差異誤差。而這種差異誤差,會在高峰時體現到節點負載不均上。
實時調度器,在調度的時候獲取各節點實時數據來參與節點打分,但是實際上實時調度在很多場景並不適用,尤其是對於具備明顯規律性的業務來說;比如我們大部分服務晚高峰流量是平時流量的幾十倍,高低峰資源使用差距劇大,而業務發版一般選擇低峰發版,採用實時調度器,往往發版的時候比較均衡,到晚高峰就出現節點間巨大差異,很多實時調度器,往往在出現巨大差異的時候會使用再平衡策略來重新調度,高峰時段對服務 POD 進行遷移,服務高可用角度來考慮是不現實的。顯然實時調度是遠遠無法滿足業務場景的。
我們的方案:高峰預測時調度
所以針對這種情況,需要預測性調度,根據以往高峰時候 CPU、IO、網絡、日誌等資源的使用量,通過對服務在節點上進行最優排列組合回歸測算,得到各個服務和資源的權重係數,基於資源的權重打分擴展,也就是使用過去高峰數據來預測未來高峰節點服務使用量,從而干預調度節點打分結果。
問題2:調度維度多樣化
隨着業務越來越多樣性,需要加入更多的調度維度,比如日誌。由於採集器不可能無限速率採集日誌且日誌採集是基於節點維度。需要將平衡日誌採集速率,不能各個節點差異過大。部分服務 CPU 使用量一般但是日誌輸出量很大;而日誌並不屬於默認調度器決策的一環,所以當這些日誌量很大的服務多個服務的 pod 在同一個節點上的時候,該機器上的日誌上報就有可能出現部分延遲。
我們的方案:補全調度決策因子
該問題顯然需要我們對調度決策補全,我們擴展了預測調度打分策略,添加了日誌的決策因子,將日誌也作為節點的一種資源,並根據歷史監控獲取到服務對應的日誌使用量來計算分數。
問題3:大批量服務擴縮導帶來的調度時延
隨着業務的複雜度進一步上升,在高峰時段出現,會有大量定時任務和集中大量彈性擴縮,大批量(上千 POD)同時調度導致調度時延的上漲,這兩者對調度時間比較敏感,尤其對於定時任務來說,調度延時的上漲會被明顯感知到。原因是 K8s 調度 pod 本身是對集群資源的分配,反應在調度流程上則是預選和打分階段是順序進行的;如此一來,當集群規模大到一定程度的時候,大批量更新就會出現可感知到的 pod 調度延遲。
我們的方案:拆分任務調度器,加大並發調度域、批量調度
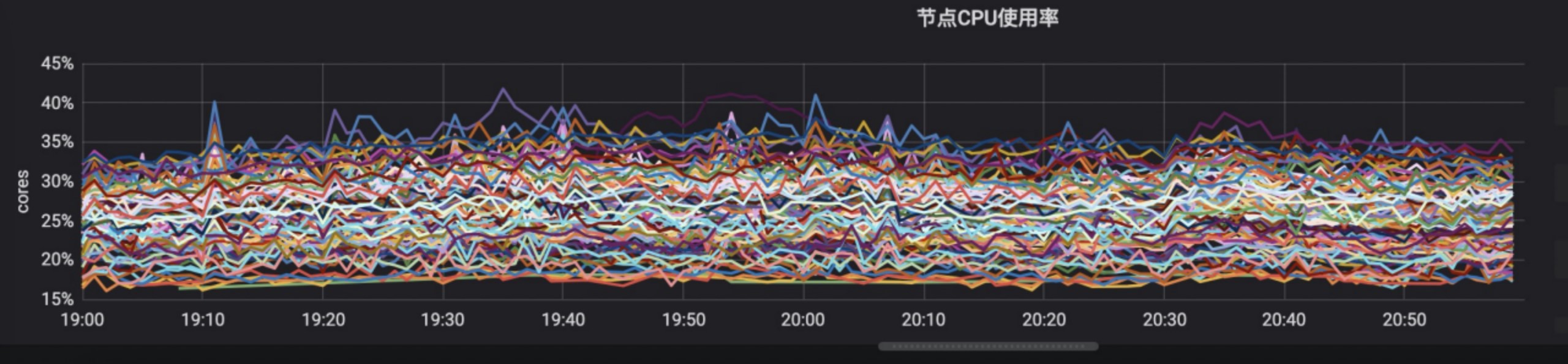
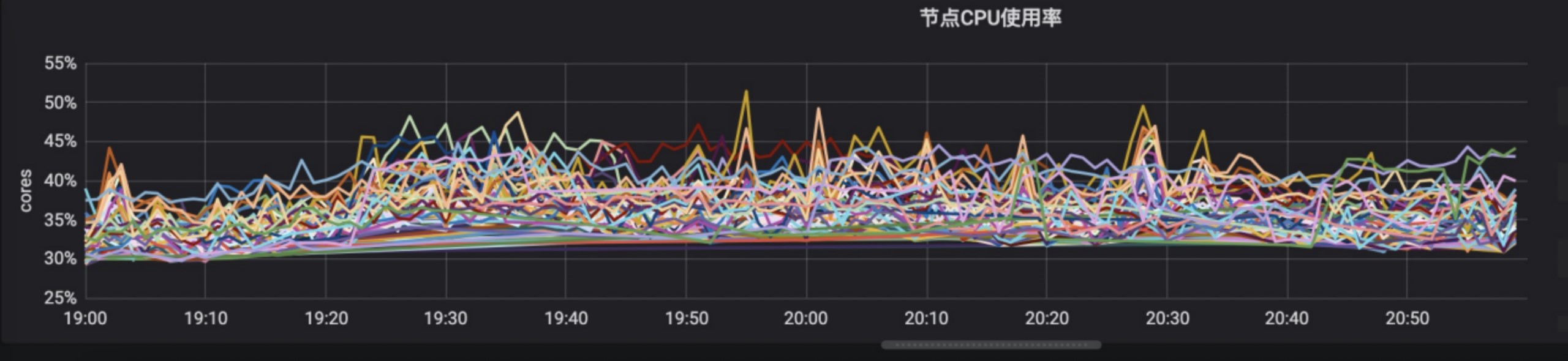
解決吞吐能力低下的最直接的方法就是串行改並行,對於資源搶佔場景,盡量細化資源域,資源域之間並行。給予以上策略,我們拆分出了獨立的 job 調度器,同時使用了 serverless 作為 job 運行的底層資源。K8s serverless 為每一個 JOB POD,單獨申請了獨立的 POD 運行 sanbox,也就是任務調度器,是完整並行。以下對比圖:
原生調度器在晚高峰下節點 CPU 使用率
優化後調度器在晚高峰下節點 CPU 使用率
總結
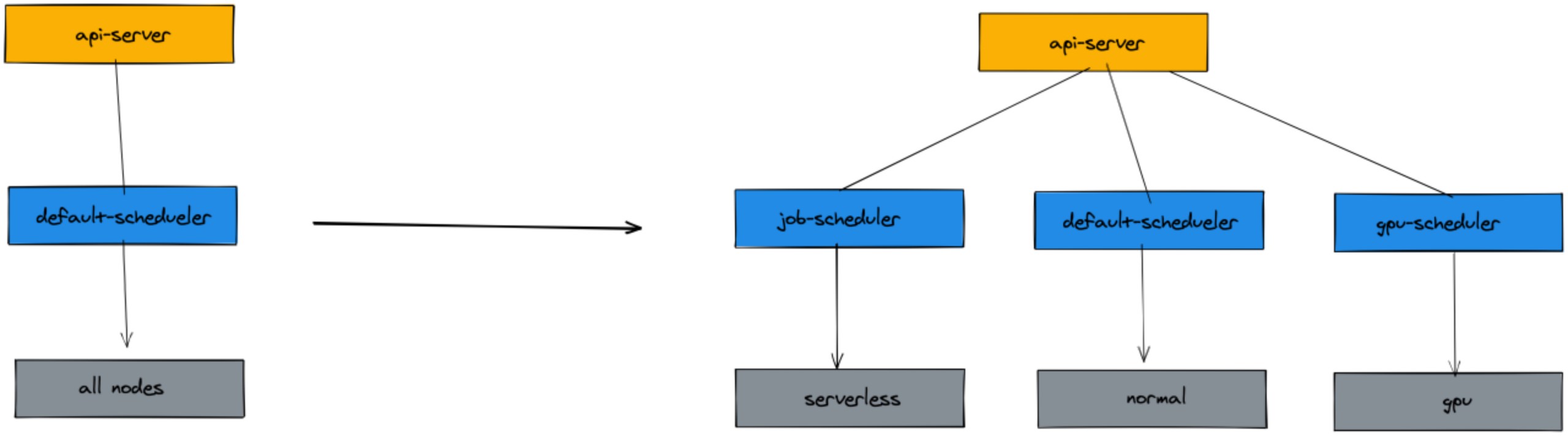
work 節點資源、GPU 資源、serverless 資源這就是我們集群異構資源分屬於這三類資源域,這三種資源上運行的服務存在天然的差異性,我們使用 forecast-scheduler、gpu-scheduler、job-schedule 三個調度器來管理這三種資源域上的 pod 的調度情況。
預測調度器管理大部分在線業務,其中擴展了資源維度,添加了預測打分策略。
GPU 調度器管理 GPU 資源機器的分配,運行在線推理和離線訓練,兩者的比例處於長期波動中,高峰期間離線訓練縮容、在線推理擴容;非高峰期間離線訓練擴容、在線推理縮容;同時處理一些離線圖片處理任務來複用 GPU 機器上比較空閑的 CPU 等資源
Job 調度器負責管理我們定時任務的調度,定時任務量大且創建銷毀頻繁,資源使用非常碎片化,而且對實效性要求更高;所以我們將任務盡量調度到 Serverless 服務上,壓縮集群中為了能容納大量的任務而冗餘的機器資源,提升資源利用率。
未來的演進探討
更細粒度的資源域劃分
將資源域劃分至節點級別,節點級別加鎖來進行。
資源搶佔和重調度
正常場景下,當一個 pod 調度失敗的時候,這個 pod 會保持在 pending 的狀態,等待 pod 更新或者集群資源發生變化進行重新調度,但是 K8s 調度器依然存在一個搶佔功能,可以使得高優先級 pod 在調度失敗的時候,擠走某個節點上的部分低優先級 pod 以保證高優 pod 的正常,迄今為止我們並沒有使用調度器的搶佔能力,即使我們通過以上多種策略來加強調度的準確性,但依然無法避免部分場景下由於業務帶來的不均衡情況,這種非正常場景中,重調度的能力就有了用武之地,也許重調度將會成為日後針對異常場景的一種自動修復的方式。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後台回復【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後台回復【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列。
③公眾號後台回復【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!



