簡單的線程池(八)
- 2021 年 12 月 29 日
- 筆記
- C++, Thread, thread pool
概要
筆者根據 Anthony Williams 在《C++並發編程實戰》中所述,
某個工作線程在任務隊列的頭部操作,而其它工作線程在任務隊列的尾部操作。這實際上意味着這個隊列對於擁有線程來說是一個後進先出的棧。最近被放到隊列中的任務會最先被取出來執行。從緩存的角度來說這可以提高性能,因為對比之前被放入隊列中的任務,被取出的任務的數據更加有可能在緩存中。
嘗試調整了 《簡單的線程池(七)》 中提及的非阻塞互助式線程池的實現方案,用 std::deque 替換 std::queue 作為存儲工作任務的底層數據結構,並新定義非阻塞線程安全的雙端隊列 Lockwise_Deque<>。
工作任務始終被添加至雙端隊列的尾部。為了驗證從緩存的角度是否可以提高性能,筆者用四種方式實現工作任務的獲取,
- 當前工作線程從自己的任務隊列的頭部獲取任務,如無工作任務則從其他任務隊列的頭部獲取任務(A);
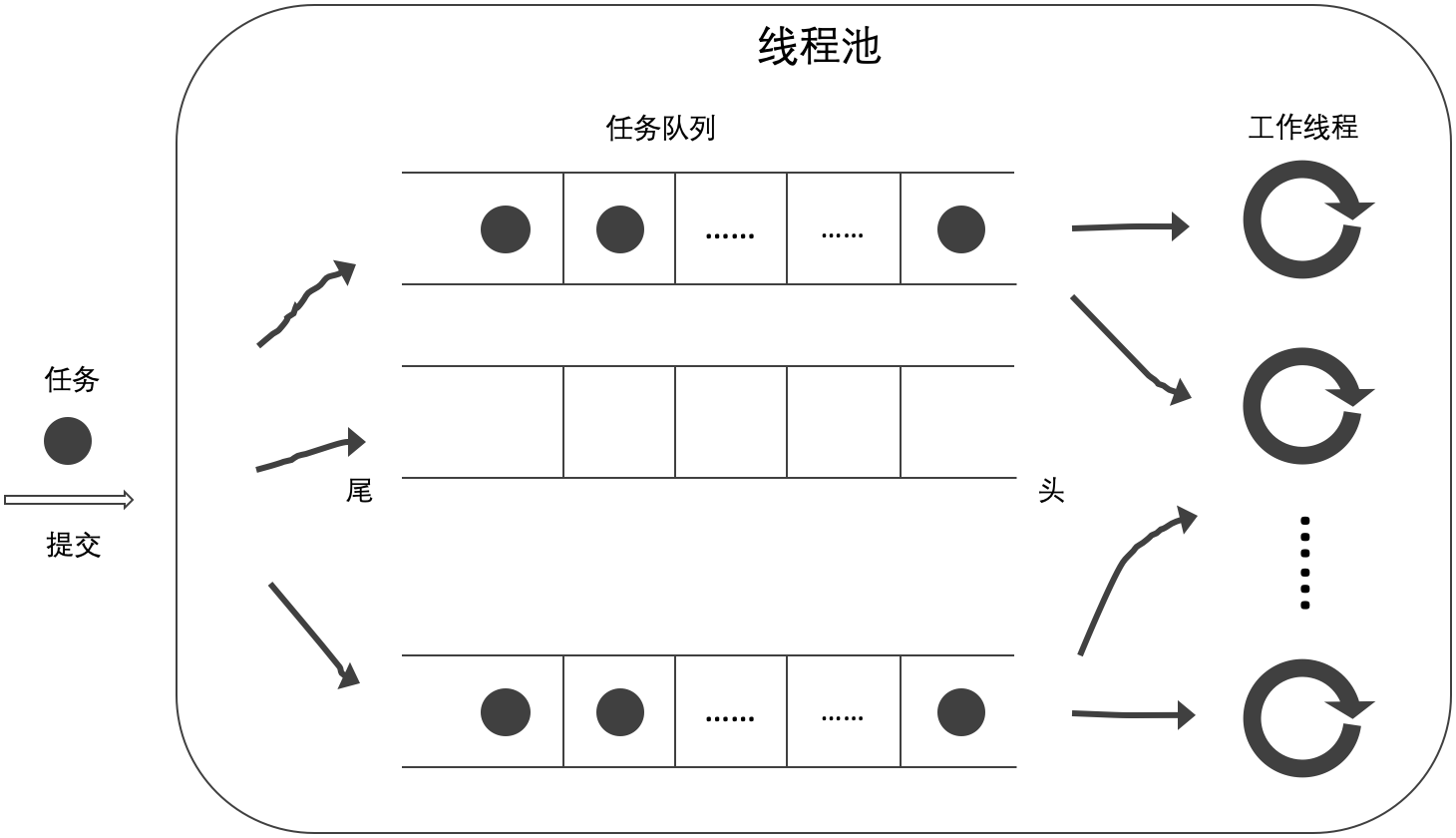
- 當前工作線程從自己的任務隊列的尾部獲取任務,如無工作任務則從其他任務隊列的頭部獲取任務(B);
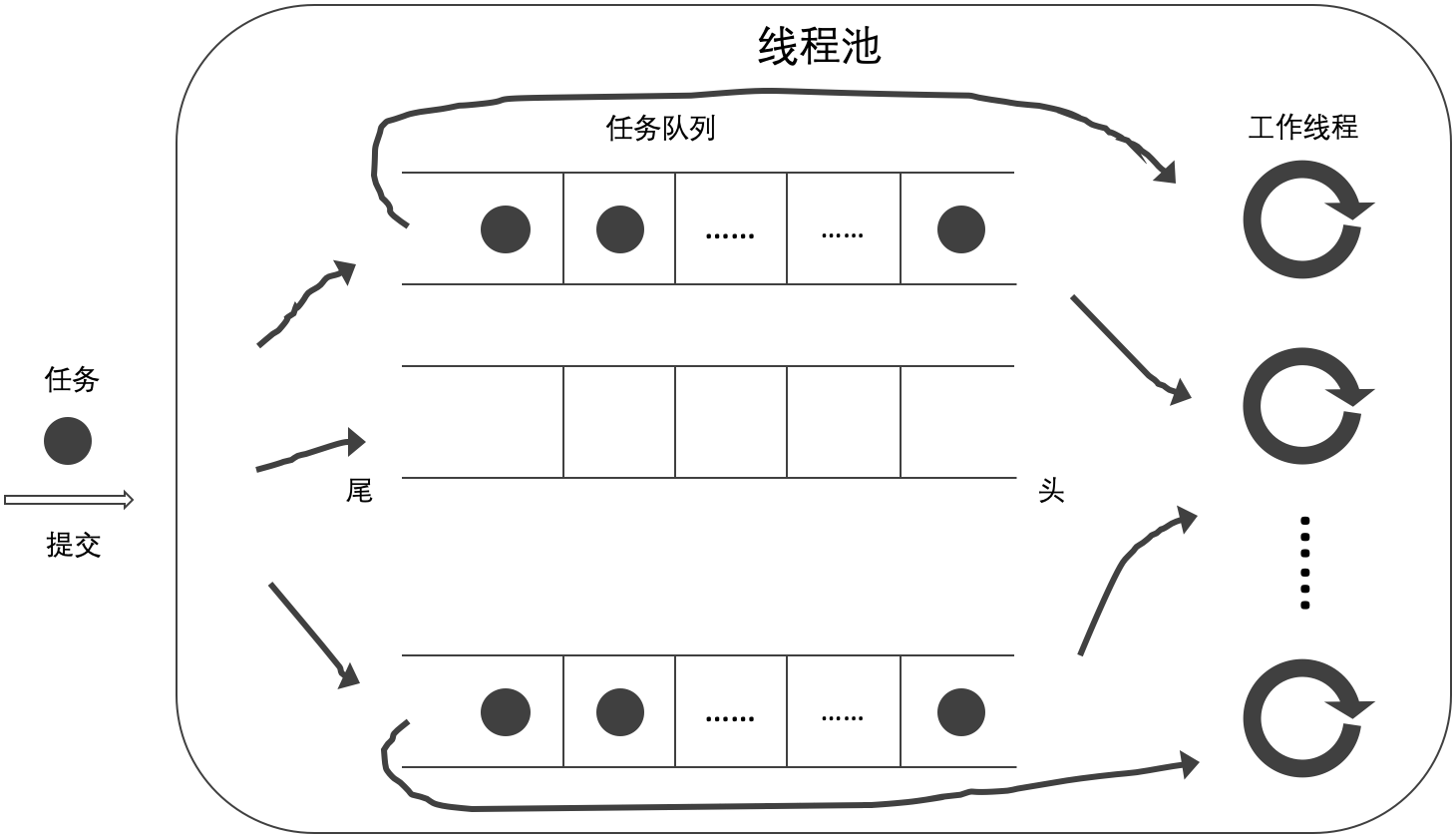
- 當前工作線程從自己的任務隊列的頭部獲取任務,如無工作任務則從其他任務隊列的尾部獲取任務(C);
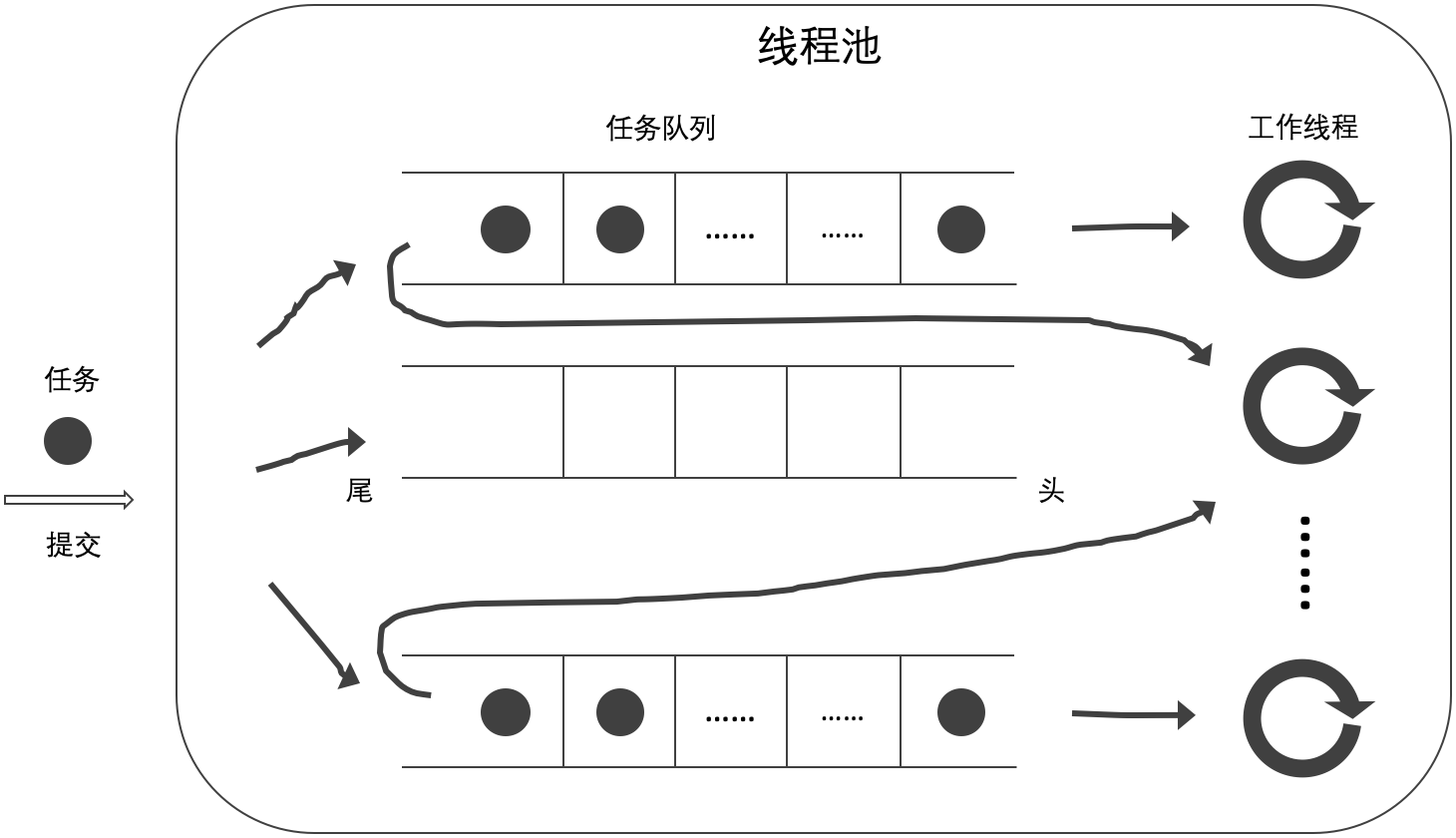
- 當前工作線程從自己的任務隊列的尾部獲取任務,如無工作任務則從其他任務隊列的尾部獲取任務(D)。
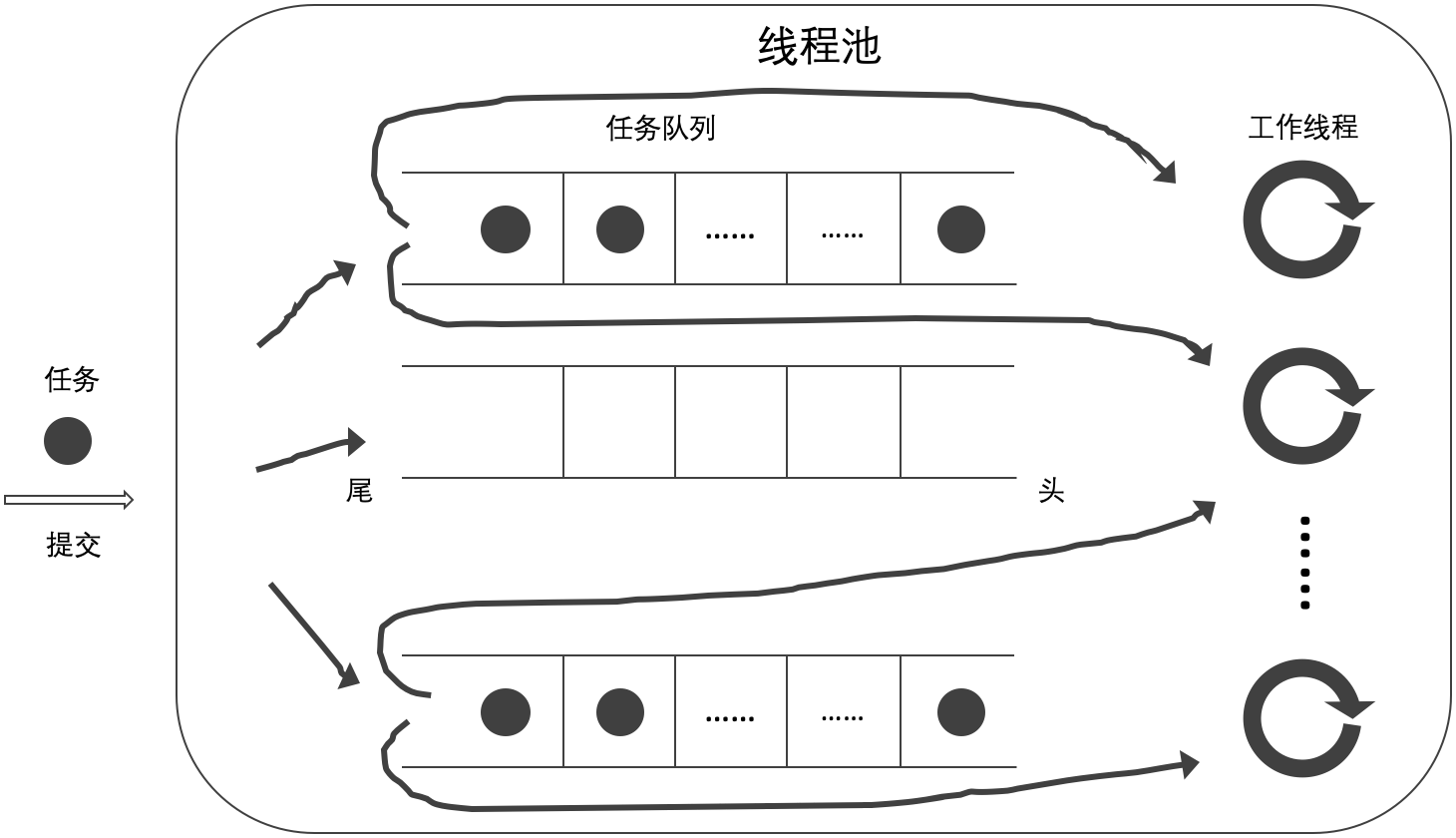
A 方式即為最初的非阻塞互助式,差別在於底層數據結構由 std::queue 更改為 std::deque;B 方式即按照 Anthony 所述的實現;C 和 D 是筆者為了全面確認緩存對性能的影響而增加的方式。
本文不再贅訴與 《簡單的線程池(七)》 相同的內容。如有不明之處,請參考該博客。
實現
以下代碼給出了非阻塞線程安全雙端隊列的實現,(lockwise_deque.h)
template<class T>
class Lockwise_Deque {
private:
struct Spinlock_Mutex { ...
} mutable _m_;
deque<T> _q_;
public:
void push(T&& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
_q_.push_back(std::move(element)); // #1
}
bool pop(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.front()); // #2
_q_.pop_front();
return true;
}
bool pull(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.back()); // #3
_q_.pop_back();
return true;
}
...
};
push(T&&) 函數實現從雙端隊列尾部添加任務(#1),pop(T&) 函數實現從雙端隊列頭部獲取任務(#2),pull(T&) 函數實現從雙端隊列尾部獲取任務(#3)。
以下代碼給出 A 方式的實現,(lockwise_mutual_2a_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
當前工作線程從自己的任務隊列的頭部獲取工作任務(#1),如無工作任務則從其他任務隊列的頭部獲取任務(#2)。
以下代碼給出 B 方式的實現,(lockwise_mutual_2b_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
當前工作線程從自己的任務隊列的尾部獲取工作任務(#1),如無工作任務則從其他任務隊列的頭部獲取任務(#2)。
以下代碼給出 C 方式的實現,(lockwise_mutual_2c_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
當前工作線程從自己的任務隊列的頭部獲取工作任務(#1),如無工作任務則從其他任務隊列的尾部獲取任務(#2)。
以下代碼給出 D 方式的實現,(lockwise_mutual_2d_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
當前工作線程從自己的任務隊列的尾部獲取工作任務(#1),如無工作任務則從其他任務隊列的尾部獲取任務(#2)。
邏輯
以下類圖展現了此線程池的代碼主要邏輯結構。
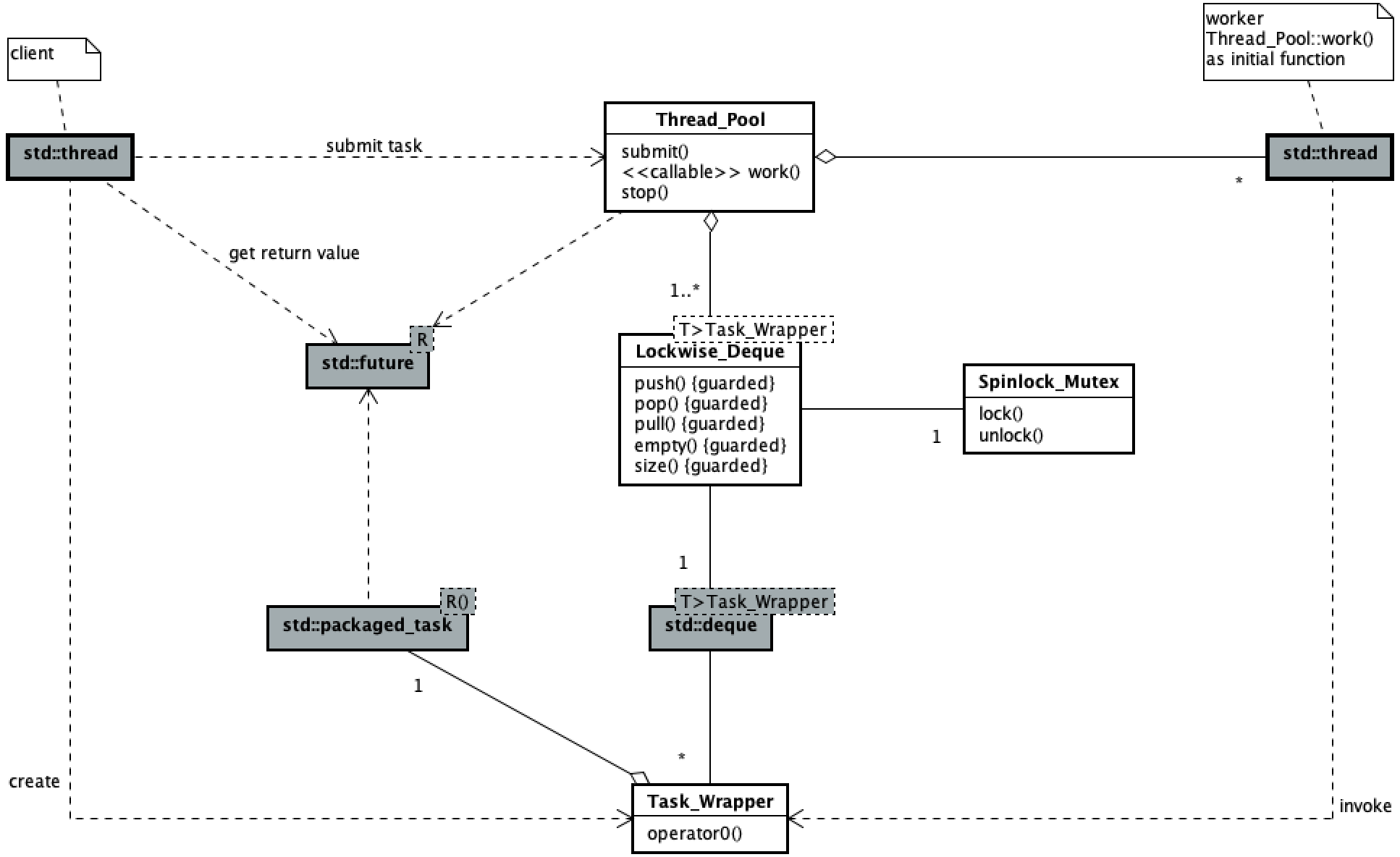
線程池用戶提交任務與工作線程執行任務的並發過程與 《簡單的線程池(一)》 中的一致,此處略。
驗證
驗證過程採用了 《簡單的線程池(三)》 中定義的的測試用例。筆者對比了測試結果與 《簡單的線程池(七)》 的數據,結果如下,
圖1 列舉了 吞吐量1的差異 在 0.5 分鐘、1 分鐘和 3 分鐘的提交周期內不同思考時間上的對比。
【注】四種非阻塞線程安全的雙端隊列略稱為 LM2A、LM2B、LM2C 和 LM2D,下同。
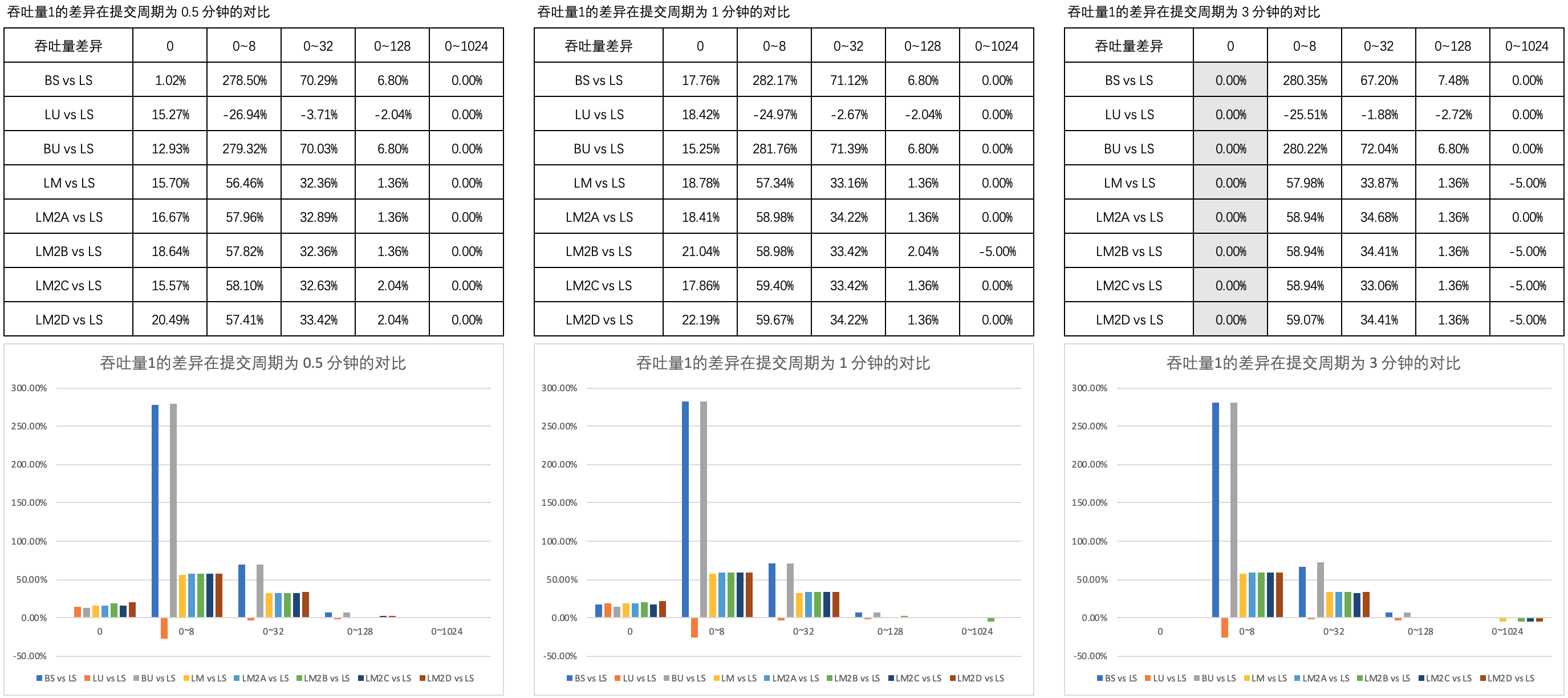
圖2 列舉了 吞吐量2的差異 在 0.5 分鐘、1 分鐘和 3 分鐘的提交周期內不同思考時間上的對比。
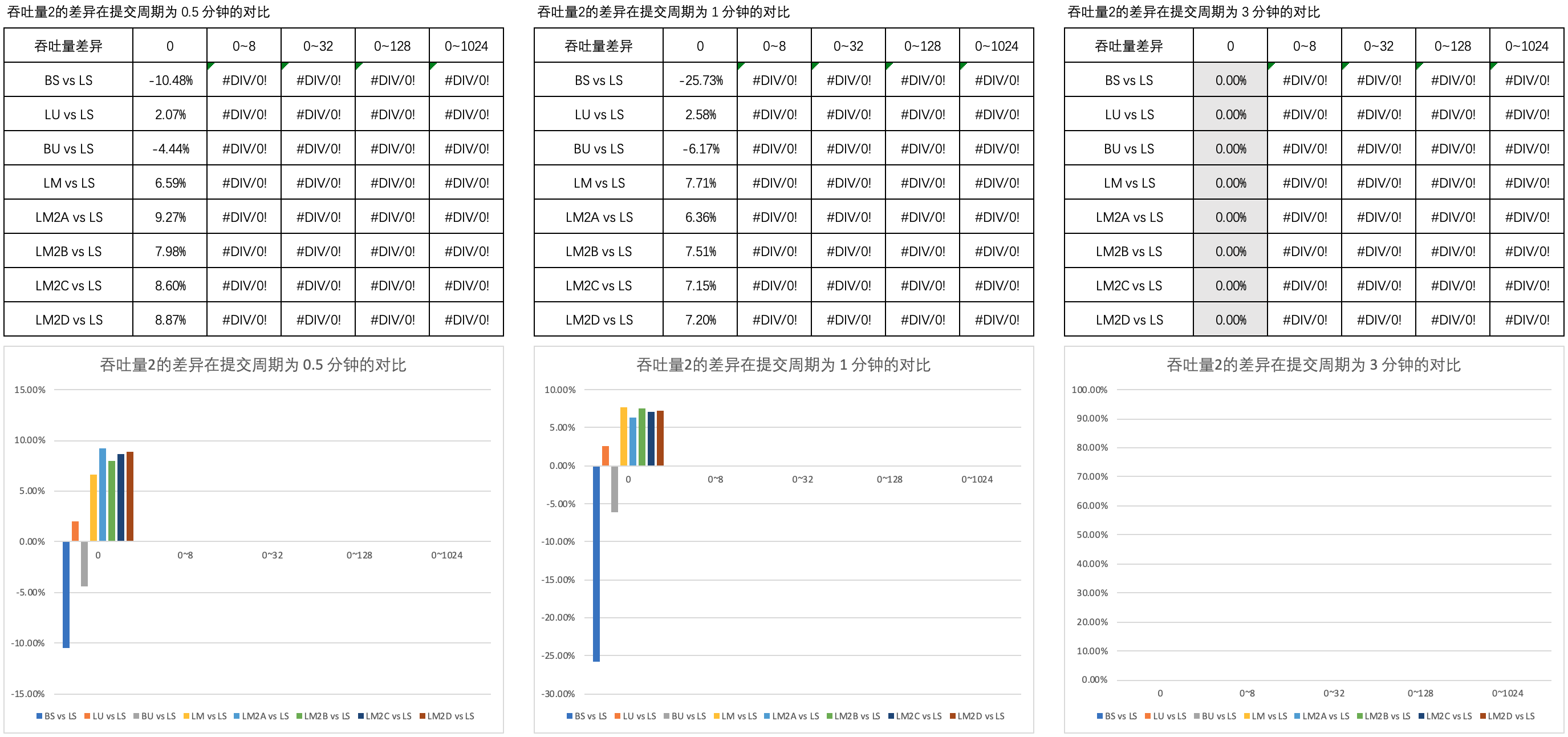
圖3 列舉了 吞吐量3的差異 在 0.5 分鐘、1 分鐘和 3 分鐘的提交周期內不同思考時間上的對比。
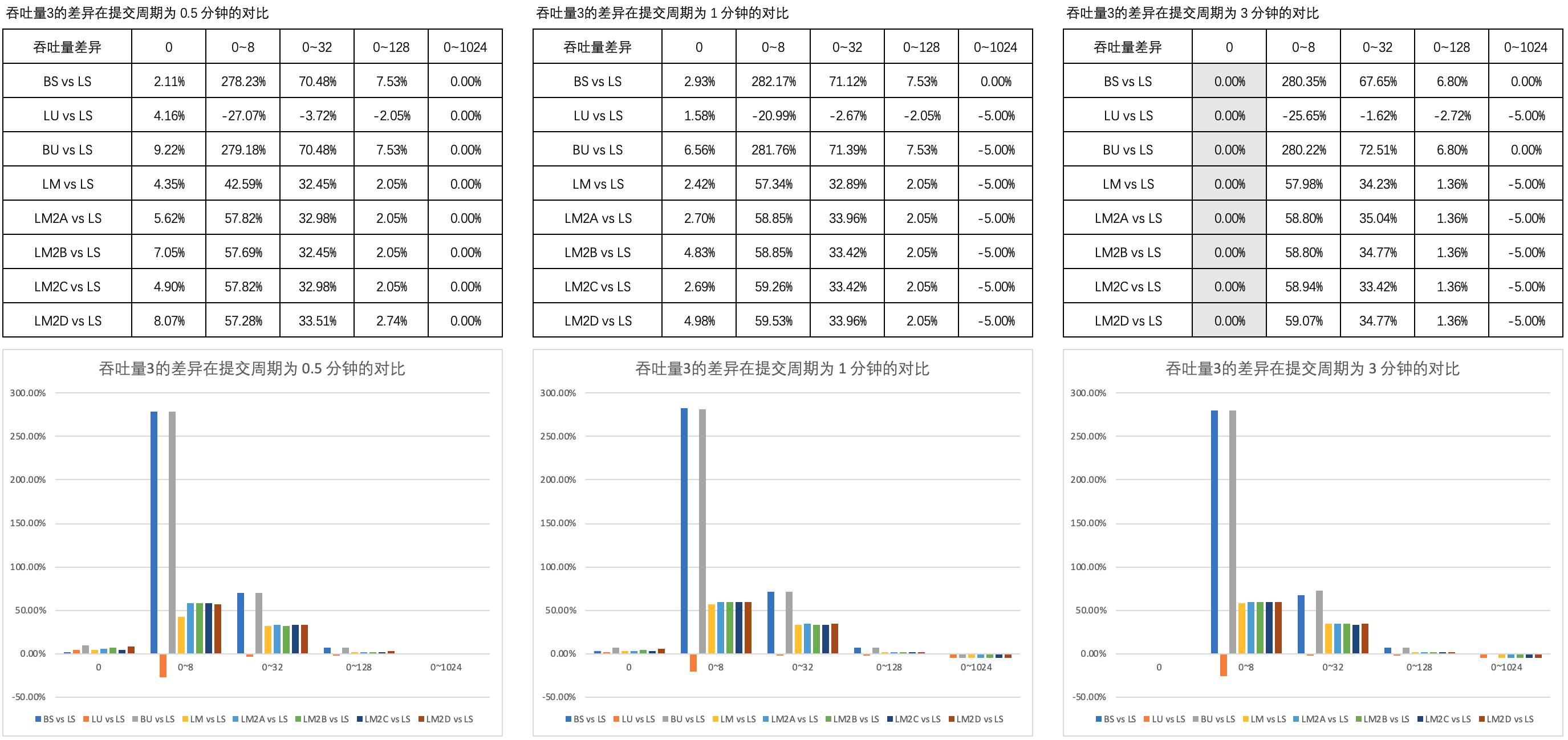
可以看到,B 方式的非阻塞互助式線程池與 A、C、D 方式的以及普通隊列的非阻塞互助式在吞吐量上的表現近乎一致。
基於以上的對比分析,筆者認為,在非阻塞式線程池中採用雙端隊列,
從緩存的角度來說這可以提高性能
這樣的論述是值得討論的。
最後
完整的代碼示例和測試數據請參考 [github] cnblogs/15723078 。
作者參考了 C++並發編程實戰 / (美)威廉姆斯 (Williams, A.) 著; 周全等譯. – 北京: 人民郵電出版社, 2015.6 (2016.4重印) 一書中的部分設計思路。致 Anthony Williams、周全等譯者。