語義模型在智能工業運營中的作用
介紹
本文着眼於語義模型設計和技術在工業運營集成中的應用,以及語義計算的不斷發展的作用。比較語義(數據)建模。作為應用程序架構的核心組件,以更熟悉的架構集成模式。功能能力描述了語義模型的操作基礎。語義模型的價值通過一系列讀者應該熟悉的例子來說明。
只匹配比賽;因此,為了通過區分其績效來競爭,每家公司都必須明智地應用領先實踐。語義計算現在具有足夠的工業應用,可以被認為是一種領先的實踐。因此,建議以各種方式補充傳統技術和可能的長期增強功能,以促進安全性和完整性。
在圍繞更智能工廠解決方案的討論中,通常會描述三個關鍵要素,其中語義概念是關鍵要素。這三個關鍵要素,分別是「儀錶化(Instrumented)」、「智能(Intelligent)」和「互連(Interconnected)」。這些元素支持這樣一種觀點,即從我們周圍的世界收集了大量數據,如果我們使用三個「I」來聯合數據,就會產生運營智能,從而推動圍繞關鍵業務任務的及時溝通、響應和優化。在這種方法中,重要的是能夠解釋數據以進行及時分析並從各種格式和上下文的各種來源中獲得理解。使用語義計算,計算和分析被推廣到將它們應用到的相似對象的所有實例。
現實世界中的數據會不斷變化。因此,結構需要是自適應的,而不是嚴格預定義的。這種差異被稱為「開放世界」與「封閉世界」。語義建模及其技術可識別基礎數據的變化以及這些變化的潛在相互作用。然而,在大多數情況下,語義的作用是在適當的上下文中及時提醒認類,以便可以識別對這些變化的響應並採取適當的行動。
實施的語義模型可以將來自任何連接數據存儲的數據聯合到一個靈活、自適應、適合用途的模型中,該模型利用和擴展行業標準和本體。當語義模型與執行分析、邏輯、報告、視圖等的應用程序相結合時,這些應用程序可以輕鬆且一致地應用和調整,全球製造商正在真正發展到一個環境,在這個環境中,業務和運營人員可以直接控制其數據、業務和運營規則,以及業務和運營流程。一些人將這種演變稱為「不斷演變的無處不在的計算模型」,因為計算能力已經變得高度分散和普遍。
工業架構的設計必須能夠處理不斷變化的、不同的數據以及數據之間隱含的實際關係。數據源包括結構化和非結構化數據、傳感器數據(當前值和歷史值)、圖像、音頻和視頻。此外,必須識別建議的數據更改的交互作用,以便將協調更改做為規則,並且將變更降至最低。當前的數據處理不僅不能很好地適應標準的關係持久性結構,而且還面臨著在上下文中理解這些數據並適應經過經驗的添加、刪除和更改,同時又不會帶來不必要的複雜性的挑戰。
語義計算的另一個主要用途是監控工業設施中部署的無數不同系統和服務的整體機械完整性。開發通用本體是一回事,這是開發語義模型的先決條件,但定期驗證適用於運營中的工業設施的法規,標準,政策,程序等的合規性計劃的完整性是完全不同的事情。核查要求確認遵守了計劃,系統配置已獲批准,所需關鍵設備正在運行,或者在無法獲得這種確認的情況下,正在作出特別努力,以適當的方式監測增加的風險。如果事件繼續,系統應以這樣一種方式上報警報,即人類無法抑制發送到更高級別的消息。
在我們的世界中,相互依賴和互動變得過於相互關聯,以至於不得不使用技術來幫助我們驗證對既定意圖的遵守情況。也許是時候使用語義技術來監控和驗證安全性和一般合規性,包括強大的、敏捷的治理。
考慮一個更智能的城市交通管理應用程序。實時交通數據通過交通燈傳感器、交通部 (DOT) 速度傳感器和攝像機提供。對準確交通流量預測至關重要的其他數據可以來自各種來源,包括天氣報告;事故報告;推文;交通中斷;日曆活動,如假期;季節性趨勢,如海灘交通;遊行、節日或重大體育賽事、緊急調度事件等特殊活動;和重大新聞事件。大量數據源用它們自己的術語描述事件,這可能與其他來源的術語有所不同。所有這些數據都必須以可用的形式被同化並在上下文中理解,並且必須解釋事件之間的關係以推斷情報。
道路、信號、傳感器等代表了交通網絡的基本模型。當前讀數、傳感器狀況、事件聲明、車輛等都代表了道路系統的狀況和每條道路的活動水平。這是要解釋的更瞬態的數據,模型更改的頻率較低。在後台獨立驗證,從而受制於適當的治理模型和開發的使用模式。事實上,甚至可以通過監控預算、施工進度等來預測模型的變化。當前的讀數和新聞源(無論其來源如何)更加動態,並且在短時間內驗證更具挑戰性。通過分離這兩類信息(模型和更多瞬態數據),可以推導出額外的邏輯來增強對更多瞬態數據的驗證,從而減少響應時間。
為了有效地溝通,必須從這些不同的來源中引用對操作工作流程中的事件及其上下文的共同理解。例如,諸如「車輛」之類的基本術語在數據源和提供者之間可能會變得不明確,而諸如汽車、輕型卡車、半汽車、公共汽車或摩托車之類的區別可能會明顯減少。一些特徵,例如車軸數量或乘員數量,可能會成為重要的區別。本體可以根據情況關聯「車輛」。當然,正在收集的相關數據在不斷變化。幸運的是,模型數據的更改頻率遠低於實時數據饋送。語義計算推理引擎有助於理解模型和瞬態數據變化。
語義建模定義了數據以及這些數據實體之間的關係。工業或運營信息模型提供了抽象不同類型數據的能力,並提供了對數據元素如何關聯的理解。語義模型是一種支持數據實體及其關係的固定和即席建模的信息模型。我們語義模型中的實體總集包括類的分類法,這些類可以在我們的模型中用於表示現實世界。這些想法一起由本體表示,本體是語義模型的詞彙表,為形成用戶定義的模型查詢提供了基礎。該模型支持實體及其關係的表示,支持對這些關係和實體的約束,並根據查詢聚合術語,例如「車輛」的定義。這提供了信息模型的語義構成。
在萬維網聯盟(W3C)版本的語義計算中,通過個別元素對數據的訪問,被應用於數據的驗證、計算等的本體對齊規則,以及衍生的推論,與數據存儲相分離。這不僅僅是一個關於系統或整體架構的生產力和機械完整性的基本概念。
當前的語義計算技術使:
- 將來自多個數據存儲的數據聯合為規範化形式,而無需從其主數據存儲或記錄系統(SOR)中移出。
- 創建一個由工程師動態構建的不可知數據模型,以關注當前的需求。
- 以任何形式或架構以及任何所需的工具想消費者提供數據。
- 在獨立於任何單個應用程序的信息模型中集成業務和運營規則。
- 開發算法等,無需用戶特別努力即可在所需對象的所有現有和新實例上運行。
這些是對信息管理和業務流程的典型方法的重大轉變。因此,他們確實需要重新定位和重組 IT 團隊,以不同於業務和運營團隊的傳統方式生成信息。
語義計算的長期目標是實現敏捷、自適應的環境,其中:
- 數據 + 模型 = 信息
- 信息 + 規則 = 知識
- 知識 + 行動 = 結果
在我們的交通管理示例中,語義模型允許用戶理解諸如 (1) 交通燈傳感器和被監控的十字路口之間的關係,(2) 任何給定交通燈傳感器與同一道路上其他傳感器的關聯, 或(3)道路與其他相交道路和主要公路的關係。語義模型還可以產生關於公交線路或地鐵線路的類似信息,以進一步描述服務位置內可用的服務類型。車站與街道地址、服務線路和地面道路路線之間的推斷關係還為理解公共交通服務的特定中斷對道路交通的影響提供了基礎。
作為一個額外的複雜功能,一個單一的應用程序必須與多個領域模型或領域本體交互。實現這種交互的一種方法是將現有的本體合併為一個新的本體。沒有必要合併來自每個原始本體的所有信息,因為這種集成可能無法在邏輯上得到滿足。此外,新的本體可能會引入新的術語和關係,用於鏈接源本體中的相關項:在後面部分的示例中,本文將密切研究如何進行語義模型的構建最適合。
製造業的複雜性問題
在今天的商業環境中,有效決策的挑戰由於大量數據的湧入和對可操作信息的日益迫切而加劇了。業務線經理正在尋找信息基礎設施,以提醒他們及早發現不斷變化的不良情況,以便他們能夠通過商業智能(BI)和運營智能(OI)解決方案中的背景可見性和決策支持來緩解不良情況。在一個製造企業中,信息存在於各種島嶼中,它們必須相互銜接和溝通,以協調運營工作流程的執行。每個島嶼都是一個運營部門或地區的記錄系統(SOR),其中的信息系統是某個數據元素或信息的權威數據源。SORs包括ERP、MES、LIMS、QMS、WMS、SCADA和IO設備。每個SOR中的信息結構會隨着產品庫存單位(SKU)數量、生產組合、吞吐率的生產線比例以及持續改進措施和工藝技術改進而發生變化。SORs使用一個非常具體的數據模型,它是為支持實時工作流程的特定應用功能要求而設計的。在當今快速變化的世界中,MOM和流程控制應用的非靜態性質和較長的採用時間框架是持續改進和企業競爭力的主要抑制因素。這些都是實施和維護綜合MOM和流程控制解決方案的主要成本因素。
通常情況下,SORs的能力有限,無法以合理的成本和在短時間內適應流程和數據的變化。這就是60-90%的IT預算是用於維護而不是用於增強的主要原因。通過將SORs的數據暴露給語義計算應用,額外的功能更容易被整合,但更重要的是,對所有法規、標準、政策、程序等的正式遵守,能夠在每個SORs內部和SORs之間得到驗證,並且獨立於每個SORs。
製造業企業內的運營是由不斷變化的結構、業務驅動的。操作過程(活動)利用了多個SORs的信息和能力。每個SORs都參與到工作流程中,用設備、材料和人員來執行,這就形成了動態的、特別的操作流程和信息本體。由於知識工作者使用的80-90%的信息已經存在,語義建模技術可以有效地集中來自多個SORs的可操作數據,允許知識工作者有效地使用每個SORs來執行準確和及時的行動。事實上,語義技術可以更新基礎數據存儲,但是在不久的將來,知識工作者可能最好是使用適當的SORs來更新數據。
ISA-95第3部分標準《製造運營管理(MOM)的活動模型》確定了四種活動模型,涉及MOM的各種SORs,必須交換的數據和事件:
- 生產經營管理。
- 質量運營管理。
- 維護操作管理。
- 庫存運營管理。
ISA-95第3部分指出,MOM活動是指製造工廠在將原材料或零部件轉化為產品過程中協調人員、設備、材料和能源的活動。每個MOM活動模型是由功能中的任務和任務與功能之間的數據交換組成的。根據普渡企業參考架構(PERA)(www.pera.net)的概念(ISA-95的原始參考模型),功能和任務可以由物理設備、人力或信息系統執行。對於工單的操作路線中的每一項操作,四個MOM活動、功能、任務和交換的一些子集被調用,以執行該操作的工作流程,使用各種設備、SORs和人員完成工單。按照這種模式,作業資源(材料[原材料、中間產品、消耗品和成品]、設備和工具、MOM和過程控制系統,以及人)被視為相當於作業流程執行中的SORs的參與者。
業務資源是數據的來源,也是改變狀態的功能調用的目標,類似於一個數據庫。換句話說,一個給定的任務或數據交換隻能由人、設備或記錄系統–一個信息系統來執行,該系統是給定數據元素或信息的權威數據源。作業資源在路線的每項作業中的應用是作為作業定義和規則中規定的每項活動的一組任務來執行的。對於一個給定的產品和生產線,安排和執行操作計劃的操作定義和規則通常是:各種SORs的一部分。生產路線的所有操作的協調方法必須驗證訂單執行過程中操作定義的變化,並且必須對變化做出反應,同時保持SORs之間信息的一致性,以產生每個活動的任務和數據交換的預期結果。
隨着製造業第4層業務和第3層操作流程的執行,各種SORs的數據被使用或改變。來自不同來源的事件被觸發,以推進流程的執行或啟動新的業務和運營流程。傳統上(即 “語義 “計算之前),其中一些流程是在SORs之外定義和執行的,在這些系統之外留下一些流程執行的短暫歷史。換句話說,大量的這些系統並不存儲理解因果關係所需的信息變化歷史,而這又是理解「what, when, and why」所需要的。這種信息對於分析推動製造企業內部的持續流程改進至關重要。有了語義計算,這種信息就很容易被捕獲,並成為正式記錄的一部分。
諸如流程歷史記錄這樣的應用,如果用來捕捉信息,通常只包括時間上下文,而不是用來處理來自SORs的複雜和交易性數據,如ERP和MOM應用。同樣,ERP系統通常缺乏詳細的執行信息或高速交易功能,例如,在對某一特定設備進行設備維護後,識別哪一個生產請求被首次處理。為了從傳統系統中獲得這些信息,有人必須知道如何從運營執行管理系統(生產、質量、庫存和維護)中查詢與設備、操作單、工單和操作環節有關的記錄。被查詢的記錄必須從記錄、生產單和工單的時間戳中進行搭配和協調,以找到在設備最後一次返修前後處理的生產請求的完整譜系。時間,作為跨SORs的一致數據元素,是可用於連接SORs之間信息的相關上下文。當然,這假定時間在各系統之間是適當同步的。有了語義計算,這些查詢可以以一種易於維護的方式進行結構化和重複使用,並且有審計跟蹤。
製造業企業擁有豐富的標準操作程序(SOPs),這些程序定義了應該如何執行操作流程。以上面的例子為基礎,製造企業可能有詳細的SOPs,用於設備維護程序、設備投入生產的資格認證,以及產品在製造過程中的路由和調度。
目前和歷史上,SOPs是以紙質形式存在的,根據需要參考。由於SOPs是手動執行工作流程的(在SOR之外),對發生了什麼、何時發生以及為什麼發生的詳細說明的譜系和理解,在最好的情況下,需要收集和關聯紙質記錄,在最壞的情況下,需要開會,讓人們通過討論他們記得的發生過的事情來彙集記錄。有了語義計算和自動化的商業和運營流程,這些都會發生變化,但對這種有價值的變化卻有很多阻力。今天的製造企業對變革有強烈的、固有的抵觸情緒,對人們必須了解其中的風險和實現回報的好處這一現實有抵觸情緒。
使問題更加複雜的是,SORs中的信息通常是以特定的任務或工作流程的形式存在,而不是以領域專家看待更廣泛挑戰的形式存在。在大多數情況下,為滿足新的需求而修改、替換或擴展SORs,即使是一種選擇,也是成本過高的。務實的解決方案是一種干擾性較小的方法,它能滿足動態製造環境的要求,並為企業和工廠的各部門提供多種形式的相關、及時的信息訪問。事實上,整個企業和行業的領域專家都需要一個結構化的信息環境,以提醒他們的教條事件,供他們分析的背景意見,從而得出他們的決策。通過語義計算,語義模型(具有將數據與數據存儲分離以及對該數據採取行動的能力)在這種務實的MOM架構形式中發揮了關鍵作用。
無論是城市交通管理還是煉油廠管理,通過語義計算應用語義模型所提供的推論和理解,對於從被監測的SORs和過程儀器中正確地得出見解至關重要。這種近乎實時的分析最終導致了通過及時的、反應迅速的決策來優化、敏捷的業務和運營流程。語義計算通過使用其推理能力來提醒正確業務流程中的正確人員及時採取正確的行動,並在沒有及時解決的情況下進行升級,從而大大增強了來自各種SORs的數據聯合。
為什麼是語義模型?
究竟什麼是語義模型。它們對這種類型的運營系統整合有什麼幫助?首先,為了清楚起見,解釋一下統一建模語言(UML)中的模型與網絡本體語言(OWL)之間的區別:
UML 是一種建模語言,用於軟件工程中,主要圍繞面向對象的系統設計工件。在此 UML 上下文中解釋基於面向信息的體系結構 (IOA) 的操作系統集成時,語義模型被用作應用程序的功能核心,以提供可導航的數據模型和關聯關係,這些模型共同表示我們目標領域的知識。
Web Ontology Language 是用於編寫本體的知識表示語言系列。這些語言的特點是形式語義和資源定義框架 (RDF)/RDF 模式 (RDFS)/語義 Web 的基於 XML 的序列化。OWL 得到了萬維網聯盟 (W3C) 的認可,並引起了學術、醫學和商業的興趣。OWL家族中的本體描述的數據被解釋為一組「個體」和一組「屬性斷言」,它們將這些個體相互關聯。本體由一組公理組成,這些公理對個體的集合(稱為「類」)以及他們之間允許的關係類型進行約束。這些公理提供語義,允許系統根據明確提供的數據推斷出額外的信息來。W3C 的 OWL 指南中提供了對 OWL 表達能力的完整介紹。
本體定義了用於描述和表示一個知識領域的術語。本體被需要分享領域信息的人、數據庫和應用程序所使用(領域只是一個特定的學科領域或知識領域,如醫學、工具製造、房地產、汽車維修或金融管理)。本體包括領域中基本概念的計算機可使用的定義以及它們之間的關係(注意,在這裡和整個本文中,定義不是在邏輯學家理解的技術意義上使用的)。它們對一個領域的知識進行編碼,也對跨領域的知識進行編碼。通過這種方式,它們使這些知識可以重複使用。
本體一詞已被用於描述具有不同結構程度的人工製品(工件)。這些範圍從簡單的分類法(例如樹型層次結構)到元數據方案,再到邏輯理論。語義網需要具有相當程度的結構的本體。這些需要為以下類型的概念指定描述:
- 許多感興趣的領域中的類(一般事物)。
- 事物之間可能存在的關係。
- 這些事物可能具有的特性(或屬性)。
本體通常用一種基於邏輯的語言來表達,這樣就可以在類、屬性和關係之間做出詳細、準確、一致、合理和有意義的區分。一些本體工具可以使用本體進行自動推理,從而為智能應用提供高級服務,如:概念/語義搜索和檢索、軟件代理、決策支持、語音和自然語言理解、知識管理、智能數據庫和電子商務。
本體在新興的語義網中佔有重要地位,它是代表文件語義的一種方式,並使語義能夠被網絡應用和智能代理使用。本體對於一個社區來說是非常有用的,它可以作為一種結構化和定義目前正在收集和標準化的元數據術語的方式。使用本體,未來的應用程序可以是 “智能的”,在這個意義上,它們可以更準確地在人類可理解的概念層面上工作。
語義模型允許用戶以更自然的方式,以結構化查詢、交易、接口和報表的形式,對建模系統中正在發生的事情提出問題。舉例來說,一個石油生產企業可能由五個地理區域組成,每個區域包含三到五個鑽井平台,每個鑽井平台由幾個控制系統監控,每個系統都有不同的目的。其中一個控制系統可能監測採油的溫度,而另一個可能監測泵的振動。語義模型允許用戶問一個問題,如 “3號平台上正在開採的油的溫度是多少?”而不必了解細節,如哪個具體的控制系統監測該信息,或哪個物理傳感器(通常由OPC標籤代表)報告該平台上的油溫。
因此,語義模型被用來將控制系統工程師所知道的物理世界(在這個例子中)與業務線領導和決策者所知道的現實世界聯繫起來。在物理世界中,一個控制點,如閥門或溫度傳感器,是通過其在特定控制系統中的標識符,可能是通過一個標籤名稱來了解。這可能是任何給定控制系統中幾千個標識符中的一個,而且整個企業可能有許多類似的控制系統。為了使信息參考和匯總的問題進一步複雜化,其他感興趣的數據點可以通過數據庫、文件、應用程序或組件服務來管理,每一個都有自己的接口方法和數據訪問的命名慣例。
因此,語義模型的一個關鍵價值是以一致的方式提供對現實世界上下文中的信息的訪問。在語義模型實現中,這種信息是使用「主語-謂語-賓語」形式的「三元組」來識別的。例如:
- 儲罐 1 <有溫度> 傳感器 7。
- 儲罐 1 <是>平台 4 的一部分。
- 平台 4 <是>區域 1 的一部分。
這些三元組一起構成了可以存儲在模型服務器中的區域的本體。使用模型查詢語言可以輕鬆遍歷此信息,以回答諸如「平台 4 上的儲罐 1 的溫度是多少?」等問題。這比沒有將工程信息與現實世界相關聯的語義模型的情況要容易得多。
此類應用程序的語義模型的另一個優點是維護。參考圖 2-1。
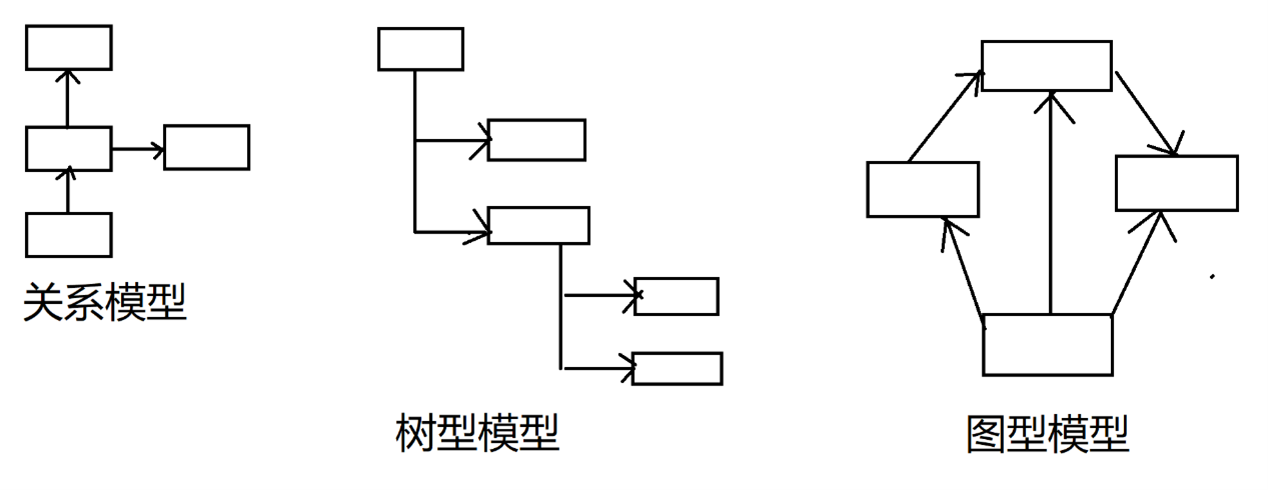
圖 2-1:信息模型結構
這裡描述的現實世界模型可以用圖2-1所示的任何一種類型的模型來實現。關係模型的實體之間的關係是通過明確的鍵(主鍵、外鍵)實體和為關聯實體的多對多關係建立的。在這種情況下,改變關係是很麻煩的,因為它需要改變基礎模型結構本身,這對一個已填充的數據庫來說是很困難的。對基於關係模型的那種數據的查詢也會很麻煩,因為它會導致非常複雜的where條件或重要的表連接。
樹型模型(圖 2-1的中間部分)在涉及現實世界的更新時也有類似的限制,並且在嘗試「橫向」遍歷模型時不是很靈活。
圖型模型(圖 2-1 的右側)是語義模型的實現方式,以便在部署後更輕鬆地查詢和維護模型。例如,一個新的關係必須被表示出來,而這是在設計時沒有預料到的。有了三元組存儲表示法,額外的表示法就很容易被維護。一個新的三元組被 簡單地添加到數據存儲中。這是一個關鍵點。關係是數據的一部分,不是數據庫結構的一部分,也不是特定SOR的一部分。同樣,該模型允許從許多不同的角度進行遍歷,以回答在設計時沒有考慮過的問題。相比之下,其他類型的數據庫設計可能需要更改結構來回答初始實施後出現的新問題。
語義模型(基於圖)允許以非線性方式輕鬆進行推斷。例如:考慮購買書籍或音樂的在線服務。這樣的應用程序應該非常擅長根據您的購買模式提出額外的購買建議。這對於提供諸如「因為您喜歡這部電影,您可能也喜歡這些電影」或「因為您喜歡這首音樂,您可能還會喜歡以下內容」等推薦的電商網站非常常見。
實現此目的的一種方法是使用語義模型,並添加如下關係:
A <類似於> B
此外,還建立了一個本體,其中A和B都屬於名為「新時代」的音樂流派。這些關係一旦在模型中建立,就可以在需要時輕鬆提供這些類型的建議。


