資源分享 | PyTea:不用運行代碼,靜態分析pytorch模型的錯誤
前言
本文介紹一個Pytorch模型的靜態分析器 PyTea,它不需要運行代碼,即可在幾秒鐘之內掃描分析出模型中的張量形狀錯誤。文末附使用方法。
本文轉載自機器之心
編輯:CV技術指南
關注公眾號
張量形狀不匹配是深度神經網絡機器學習過程中會出現的重要錯誤之一。由於神經網絡訓練成本較高且耗時,在執行代碼之前運行靜態分析,要比執行然後發現錯誤快上很多。
由於靜態分析是在不運行代碼的前提下進行的,因此可以幫助軟件開發人員、質量保證人員查找代碼中存在的結構性錯誤、安全漏洞等問題,從而保證軟件的整體質量。
相比於程序動態分析,靜態分析具有不實際執行程序;執行速度快、效率高等特點而廣受研究者青睞,目前,已有許多分析工具可供研究使用,如斯坦福大學開發的 Meta-Compilation(Coverity)、利物浦大學開發的 LDRA Testbed 等。
近日,來自韓國首爾大學的研究者們提出了另一種靜態分析器 PyTea,它可以自動檢測 PyTorch 項目中的張量形狀錯誤。在對包括 PyTorch 存儲庫中的項目以及 StackOverflow 中存在的張量錯誤代碼進行測試。結果表明,PyTea 可以成功的檢測到這些代碼中的張量形狀錯誤,幾秒鐘就能完成。

-
論文地址://arxiv.org/pdf/2112.09037.pdf
-
項目地址://github.com/ropas/pytea
幾秒就能查找張量形狀錯誤的 PyTea
PyTea 工具可以靜態地掃描 PyTorch 程序並檢測可能的形狀錯誤。PyTea 通過額外的數據處理和一些庫(例如 Torchvision、NumPy、PIL)的混合使用來分析真實世界 Python/PyTorch 應用程序的完整訓練和評估路徑。
PyTea 的工作原理是這樣的:給定輸入的 PyTorch 源,PyTea 靜態跟蹤每個可能的執行路徑,收集路徑張量操作序列所需的張量形狀約束,並決定約束滿足與否(因此可能發生形狀錯誤)。
具體來說:如下圖所示, PyTea 首先將原始 Python 代碼翻譯成一種內核語言,即 PyTea 內部表示(PyTea IR)。然後,它跟蹤轉換後的 IR 的每個可能執行路徑,並收集有關張量形狀的約束,這些約束規定了代碼在沒有形狀錯誤的情況下運行的條件。 PyTea 將收集到的約束集提供給 SMT(Satisfiability Modulo Theories)求解器 Z3,以判斷這些約束對於每個可能的輸入形狀都是可滿足的。根據求解器的結果,PyTea 會得出結論,哪條路徑包含形狀錯誤。如果 Z3 的約束求解花費太多時間,PyTea 會停止並發出「don』t know」提示。
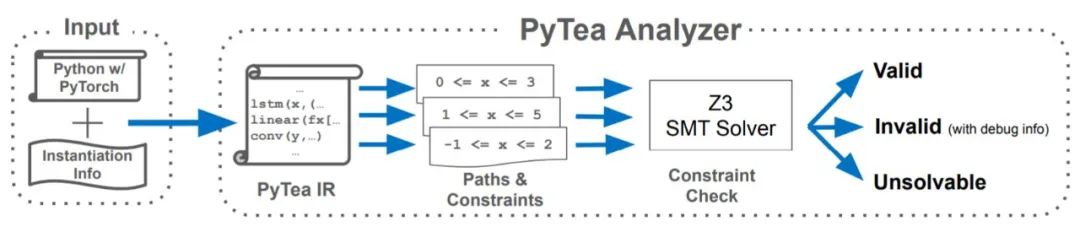
PyTea 的整體結構。
PyTea 由兩個分析器組成,在線分析器:node.js (TypeScript / JavaScript);離線分析器:Z3 / Python。
-
在線分析器:查找基於數值範圍的形狀不匹配和 API 參數的濫用。如果 PyTea 在分析代碼時發現任何錯誤,它將停在該位置並將錯誤和違反約束通知用戶;
-
離線分析器:生成的約束傳遞給 Z3 。Z3 將求解每個路徑的約束集並打印第一個違反的約束(如果存在)。
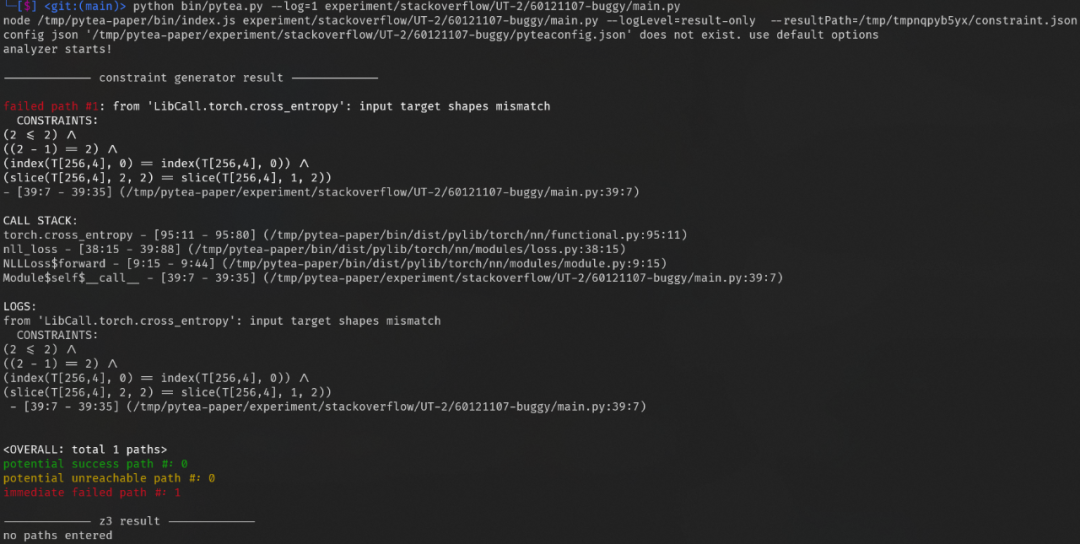
我們先來看下結果展示,在線分析器發現錯誤:
![]()
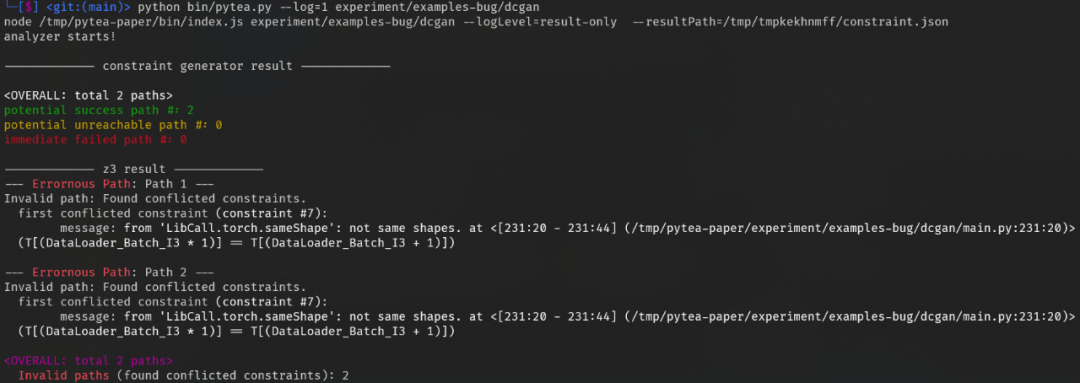
離線分析器發現錯誤:
![]()
為了更好的理解 PyTea 執行靜態分析過程,下面我們介紹一下主要的技術細節,包括 PyTorch 程序結構、張量形狀錯誤、PyTea IR 等,以便讀者更好的理解執行過程。
首先是 PyTorch 程序結構,PyTorch、TensorFlow 和 Keras 等現代機器學習框架需要使用 Python API 來構建神經網絡。使用此類框架訓練神經網絡大多遵循如下四個階段的標準程序。
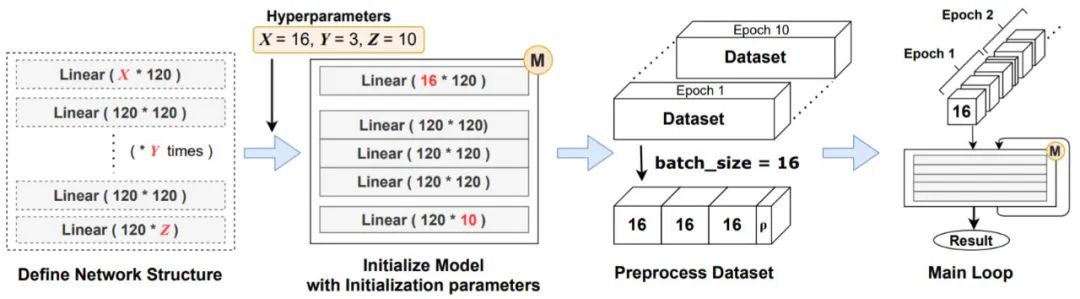
在 PyTorch 中,常規神經網絡訓練代碼的結構。
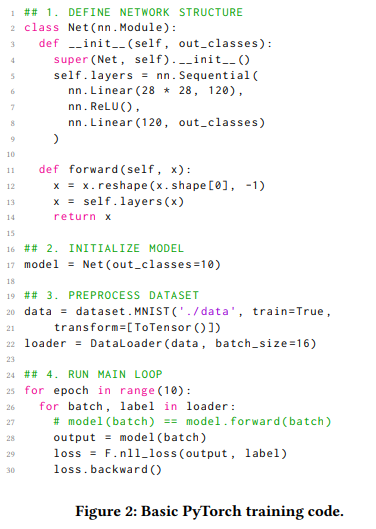
訓練模型需要先定義網絡結構,圖 2 為一個簡化的圖像分類代碼,取自官方的 PyTorch MNIST 分類示例:
![]()
在這裡,上述代碼首先定義一系列神經網絡層,並使它們成為單一的神經網絡模塊。為了正確組裝層,前一層的返回張量必須滿足下一層的輸入要求。網絡使用超參數的初始化參數進行實例化,例如隱藏層的數量。接下來,對輸入數據集進行預處理並根據網絡的要求進行調整。從該階段開始,每個數據集都被切成較小的相同大小的塊(minibatch)。最後,主循環開始,minibatch 按順序輸入網絡。一個 epoch 是指將整個數據集傳遞到網絡的單個循環,並且 epoch 的數量通常取決於神經網絡的目的和結構。除了取決於數據集大小的主訓練循環之外,包括 epoch 數在內,訓練代碼中的迭代次數在大多數情況下被確定為常數。
在構建模型時,網絡層之間輸入、輸出張量形狀的不對應就是張量形狀錯誤。通常形狀錯誤很難手動查找,只能通過使用實際輸入運行程序來檢測。下圖就是典型的張量形狀錯誤(對圖 2 的簡單修改),如果不仔細查看,你根本發現不了錯誤:

![]()
對於張量形狀錯誤(如上圖的錯誤類型),PyTea 將原始 Python 代碼翻譯成 PyTea IR 進行查找,如下圖是 PyTea IR 示例:

![]()
上面提到,PyTea 會跟蹤轉換後的 IR 的每個可能執行路徑,並收集有關張量形狀約束。其實約束是 PyTorch 應用程序所需要的條件,以便在沒有任何張量形狀誤差的情況下執行它。例如,一個矩陣乘法運算的兩個操作數必須共享相同的維數。下圖顯示了約束的抽象語法:

![]()
約束的抽象語法部分截圖
如何使用 PyTea
首先,安裝環境要求:node.js >= 12.x,python >= 3.8,z3-solver >= 4.8。
安裝和使用可參考以下代碼:
# install node.js
sudo apt-get install nodejs
# install python z3-solver
pip install z3-solver
# download pytea
wget //github.com/ropas/pytea/releases/download/v0.1.0/pytea.zip
unzip pytea.zip
# run pytea
python bin/pytea.py path/to/source.py
# run example file
python bin/pytea.py packages/pytea/pytest/basics/scratch.py![]()
編譯代碼:
# install dependencies
npm run install:all
pip install z3-solver
# build
npm run build
![]()
相關文章閱讀:
歡迎關注公眾號 CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「入門指南「可獲取計算機視覺入門所有必備資料。

![]()
其它文章