ICCV2021 | Tokens-to-Token ViT:在ImageNet上從零訓練Vision Transformer
前言
本文介紹一種新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT將原始ViT的參數數量和MAC減少了一半,同時在ImageNet上從頭開始訓練時實現了3.0%以上的改進。通過直接在ImageNet上進行訓練,它的性能也優於ResNet,達到了與MobileNet相當的性能。
本文來自公眾號CV技術指南的
關注公眾號CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。

![]()
論文:Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
代碼://github.com/yitu-opensource/T2T-ViT
Background
Vision Transformer(ViT)是第一個可以直接應用於圖像分類的全Transformer模型。具體地說,ViT將每個圖像分割成固定長度的14×14或16×16塊(也稱為tokens);然後ViT應用Transformer層對這些tokens之間的全局關係進行建模以進行分類。
儘管ViT證明了全Transformer架構在視覺任務中很有前途,但在中型數據集(例如ImageNet)上從頭開始訓練時,其性能仍遜於類似大小的CNN對等架構(例如ResNets)。
論文假設,這種性能差距源於ViT的兩個主要局限性:
1)通過硬分裂對輸入圖像進行簡單的tokens化,使得ViT無法對圖像的邊緣和線條等局部結構進行建模,因此它需要比CNN多得多的訓練樣本(如JFT-300M用於預訓練)才能獲得類似的性能;
2)ViT的注意力骨幹沒有很好地像用於視覺任務的CNN那樣的設計,如ViT具有冗餘性和特徵豐富度有限的缺點,導致模型訓練困難。
為了驗證論文的假設,論文進行了一項初步研究,通過圖2中的可視化來調查ViTL/16和ResNet5的獲知特徵的差異。論文觀察ResNet的功能,捕捉所需的局部結構(邊、線、紋理等)。從底層(Cv1)逐漸向中間層(Cv25)遞增。
然而,ViT的特點卻截然不同:結構信息建模較差,而全局關係(如整條狗)被所有的注意塊捕獲。這些觀察結果表明,當直接將圖像分割成固定長度的tokens時,原始 ViT忽略了局部結構。此外,論文發現ViT中的許多通道都是零值(在圖2中以紅色突出顯示),這意味着ViT的主幹不如ResNet高效,並且在訓練樣本不足的情況下提供有限的特徵豐富度。

創新思路
論文決意設計一種新的full-Transformer視覺模型來克服上述限制。
1)與ViT中使用的樸素tokens化不同,論文提出了一種漸進式tokens化模塊,將相鄰tokens聚合為一個tokens(稱為tokens-to-token模塊),該模塊可以對周圍tokens的局部結構信息進行建模,并迭代地減少tokens的長度。具體地說,在每個tokens-to-token(T2T)步驟中,transformer層輸出的tokens被重構為圖像(restructurization),然後圖像被分割成重疊(soft split)的tokens,最後周圍的tokens通過flatten分割的patches被聚集在一起。因此,來自周圍patches的局部結構被嵌入要輸入到下一transformer層的tokens中。通過迭代進行T2T,將局部結構聚合成tokens,並通過聚合過程減少tokens的長度。
2)為了尋找高效的Vision Transformer主幹,論文借鑒了CNN的一些架構設計來構建Transformer層,以提高功能的豐富性,論文發現ViT中通道較少但層數較多的「深度窄」架構設計在同等型號和MAC(Multi-Adds)的情況下性能要好得多。具體地說,論文研究了寬ResNet(淺寬VS深窄結構)、DenseNet(密集連接)、ResneXt結構、Ghost操作和通道注意。論文發現其中,深窄結構對於ViT是最有效和最有效的,在幾乎不降低性能的情況下顯着地減少了參數數目和MACs。這也表明CNNs的體系結構工程可以為Vision Transformer的骨幹設計提供幫助。
基於T2T模塊和深度窄骨幹網架構,論文開發了tokens-to-token Vision Transformer(T2T-ViT),它在ImageNet上從頭開始訓練時顯著提高了性能,而且比普通ViT更輕便。
Methods
T2T-ViT由兩個主要部分組成(圖4):
1)一個層次化的「Tokens-to-Token模塊」(T2T模塊),用於對圖像的局部結構信息進行建模,並逐步減少tokens的長度;
2)一個有效的「T2T-ViT骨幹」,用於從T2T模塊中提取對tokens的全局關注關係。
在研究了幾種基於CNN的體系結構設計後,對主幹採用深窄結構,以減少冗餘度,提高特徵豐富性。

![]()
圖4.T2T-ViT的整體網絡架構。在T2T模塊中,首先將輸入圖像soft split為patches,然後將其展開為token T0序列。在T2T模塊中,token的長度逐漸減小(在這裡使用兩次迭代和輸出Tf)。然後,T2T-VIT主幹將固定token作為輸入並輸出預測。兩個T2T塊與圖3相同,PE為位置嵌入。
Tokens-to-Token
Tokens-to-Token(T2T)模塊旨在克服ViT中簡單tokens化的限制。它將圖像逐步結構化為表徵,並對局部結構信息進行建模,這樣可以迭代地減少表徵的長度。每個T2T流程有兩個步驟:重組和Soft Split(SS)(圖3)。
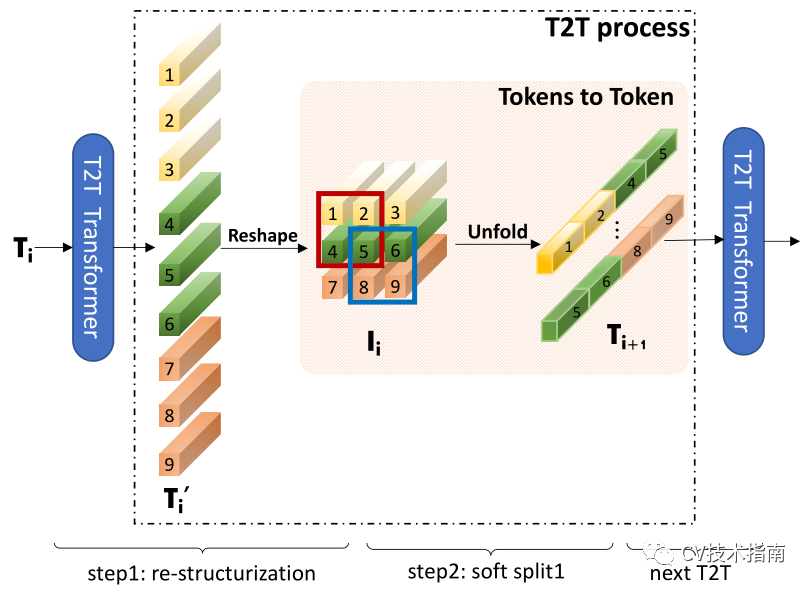
經過變換和reshape後,tokens Ti被重構為圖像Ii,然後重疊split為tokens Ti+1。具體地說,如粉色面板中所示,輸入Ii的四個tokens(1、2、4、5)被串聯以形成一個tokens 在Ti+1。T2T transformer可以是普通的transformer 層或有限GPU存儲器中的像Performer層這樣的其他高效transformer。
在進行soft split時,每個塊的大小為k×k,在圖像上疊加s個,其中k−類似於卷積運算中的步長。因此,對於重建圖像I_∈_rh×w×c,soft split後的輸出tokens的長度為

通過迭代進行上述重構和soft split,T2T模塊可以逐步減少tokens的長度,並轉換圖像的空間結構。T2T模塊中的迭代過程可以表示為

T2T-ViT Backbone
論文探索了不同的VIT體系結構設計,並借鑒了CNN的一些設計,以提高骨幹網的效率,增強學習特徵的豐富性。由於每個transformer層都有跳躍連接,一個簡單的想法是採用如DenseNet的密集連接來增加連通性和特徵豐富性,或者採用Wide-ResNets或ResNeXt結構來改變VIT主幹中的通道尺寸和頭數。
論文探討了從CNN到VIT的五種架構設計:
-
密集連接如DenseNet;
-
深-窄與淺-寬結構如寬ResNet];
-
通道注意如擠壓-激勵(SE)網絡;
-
多頭注意層中更多的分頭如ResNeXt;
-
Ghost操作如Ghost Net。
實驗發現:1)採用簡單降低通道維數的深窄結構來減少通道中的冗餘,增加層深來提高VIT中的特徵豐富度,模型尺寸和MACs都有所減小,但性能有所提高;2)SE塊的通道關注度也提高了VIT,但效果不如深窄結構。
基於這些發現,論文為T2T-VIT骨幹網設計了一種深窄結構。具體地說,它具有較小的通道數和隱藏維度d,但具有更多的層b。對於T2T模塊最後一層定長的Token,論文在其上拼接一個類Token,然後添加正弦位置嵌入(PE),與VIT一樣進行分類:

![]()
T2T-ViT Architecture

![]()
T2T-VIT的結構細節。T2T-VIT-14/19/24的型號尺寸與ResNet50/101/152相當。T2T-VIT-7/12的型號大小與MobileNetV1/V2相當。對於T2T transformer 層,在有限的GPU內存下,論文採用了T2T-VITT-14的transformer層和T2T-VIT-14的Performer層。對於VIT,『S』表示小,『B』表示基本,『L』表示大。『VIT-S/16』是原始VIT-B/16的變體,具有更小的MLP大小和層深。
Conclusion
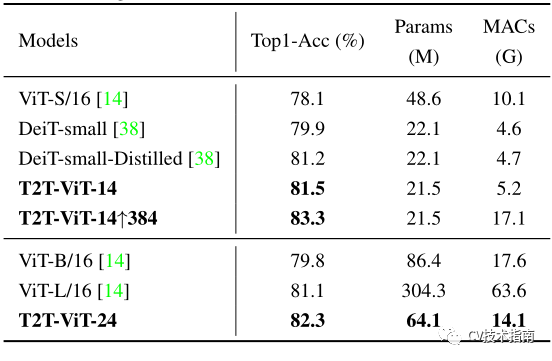
如圖1所示,論文的215M參數和5.2G MACS的T2T-ViT在ImageNet上可以達到81.5%的TOP-1準確率,遠遠高於ViT的48.6M參數和10.1G MACs的TOP-1準確率(78.1%)。這一結果也高於流行的類似大小的CNN,如具有25.5M參數的ResNet50(76%-79%)。此外,論文還通過簡單地採用更少的層來設計T2T-ViT的精簡變體,取得了與MobileNets(圖1)相當的結果。

![]()
T2T-VIT與VIT在ImageNet上從頭訓練的比較
![]()
將CNN中的一些常用設計移植到VIT&T2T-VIT中,包括DenseNet、Wide-ResNet、SE模塊、ResNeXt、Ghost操作。相同的顏色表示相應的遷移。所有模型都是在ImageNet上從頭開始訓練的。

![]()
歡迎關注公眾號 CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「入門指南「可獲取計算機視覺入門所有必備資料。

![]()
其它文章


