【論文筆記】Leveraging Post-click Feedback for Content Recommendations
Leveraging Post-click Feedback for Content Recommendations
Authors: Hongyi Wen, Longqi Yang, Deborah Estrin
Recsys’19 Cornell University
論文鏈接://dl.acm.org/doi/pdf/10.1145/3298689.3347037
本文鏈接://www.cnblogs.com/zihaojun/p/15708632.html
0. 總結
這篇文章證明了在推薦系統中,將用戶點擊之後沒有看完的物品作為負樣本的一部分參與訓練是有效的。
1.研究目標
利用用戶在點擊之後的反饋數據,來解決點擊數據中的噪聲問題,提高推薦系統的性能。
- 例如,用戶觀看視頻或聽音樂的時長,可以反映用戶看到物品之後是否真正喜歡。
2.問題背景
在構建推薦系統時,通常會選用隱式反饋數據作為訓練數據,但隱式反饋數據的正樣本不一定都是用戶喜歡的物品。例如,用戶點擊了一個物品,這隻能反映用戶對這個物品的第一印象比較好,用戶在瀏覽之後可能並不喜歡這個物品。
3.分析點擊之後的反饋信息
數據集:
- Spotify:在線音樂數據集,包含上億的聽歌會話,每個會話包含最多二十首歌,記錄了用戶跳過還是聽完了每首歌,跳過與否是根據挑戰賽組委會設定的播放閾值。隨機選擇了九百萬會話進行分析。
- ByteDance:用戶與短視頻(10秒)的交互記錄,包含是否完播。選取了13 million的數據。
3.1 反饋信息的特點
點擊之後的用戶反饋在很多場景中都存在,這種反饋可能是顯式的(評分),也可能是隱式的(觀看時長)。在上述兩個數據集中,音樂和短視頻場景下,分別有51%和56%的交互是點擊之後被跳過的。也就是說,超過半數的交互是點擊之後用戶並不滿意的。
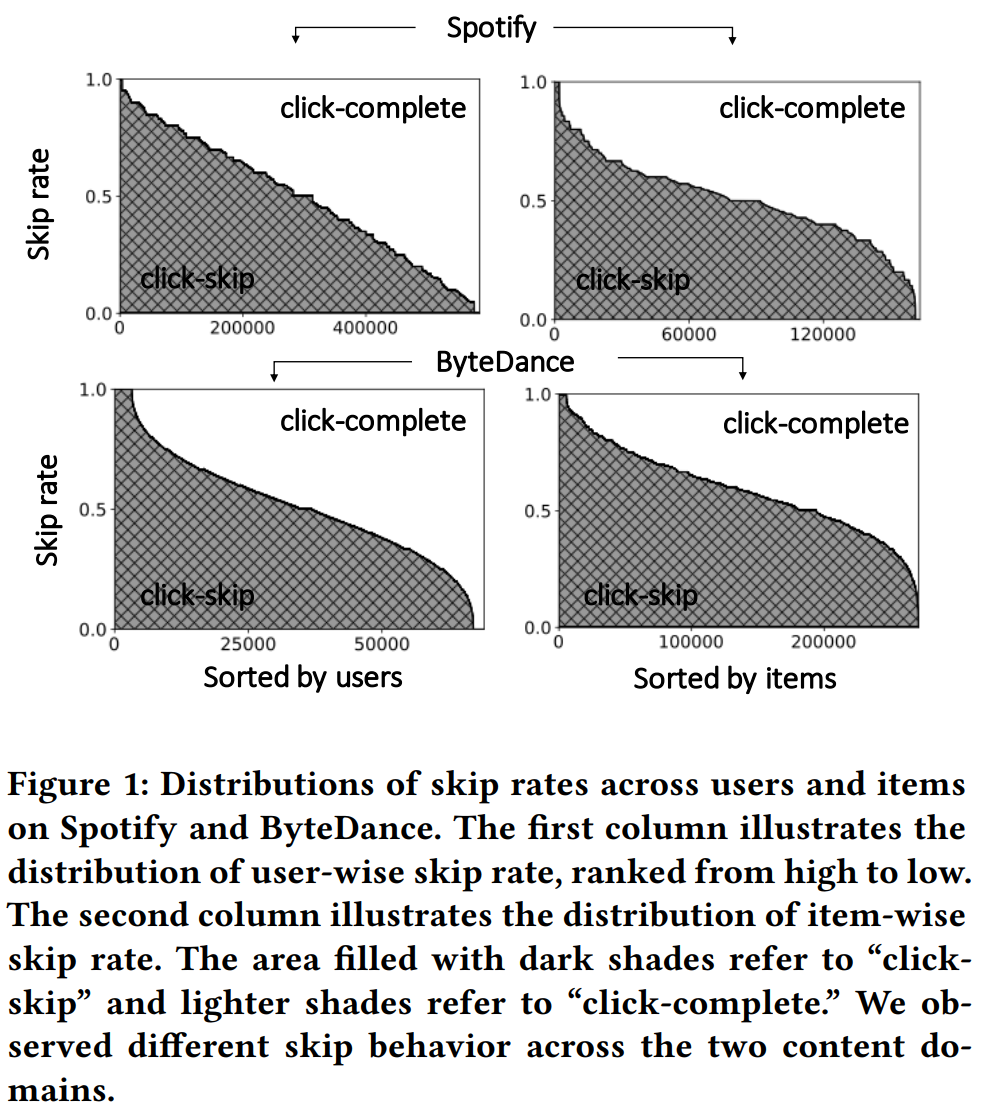
具體到每個物品和每個用戶的完播比例,如Figure 1所示,兩個數據集上面,左邊一列(用戶跳過比例)的分佈不同,可能是因為音樂和視頻的使用場景不同,音樂被跳過會更加隨機。
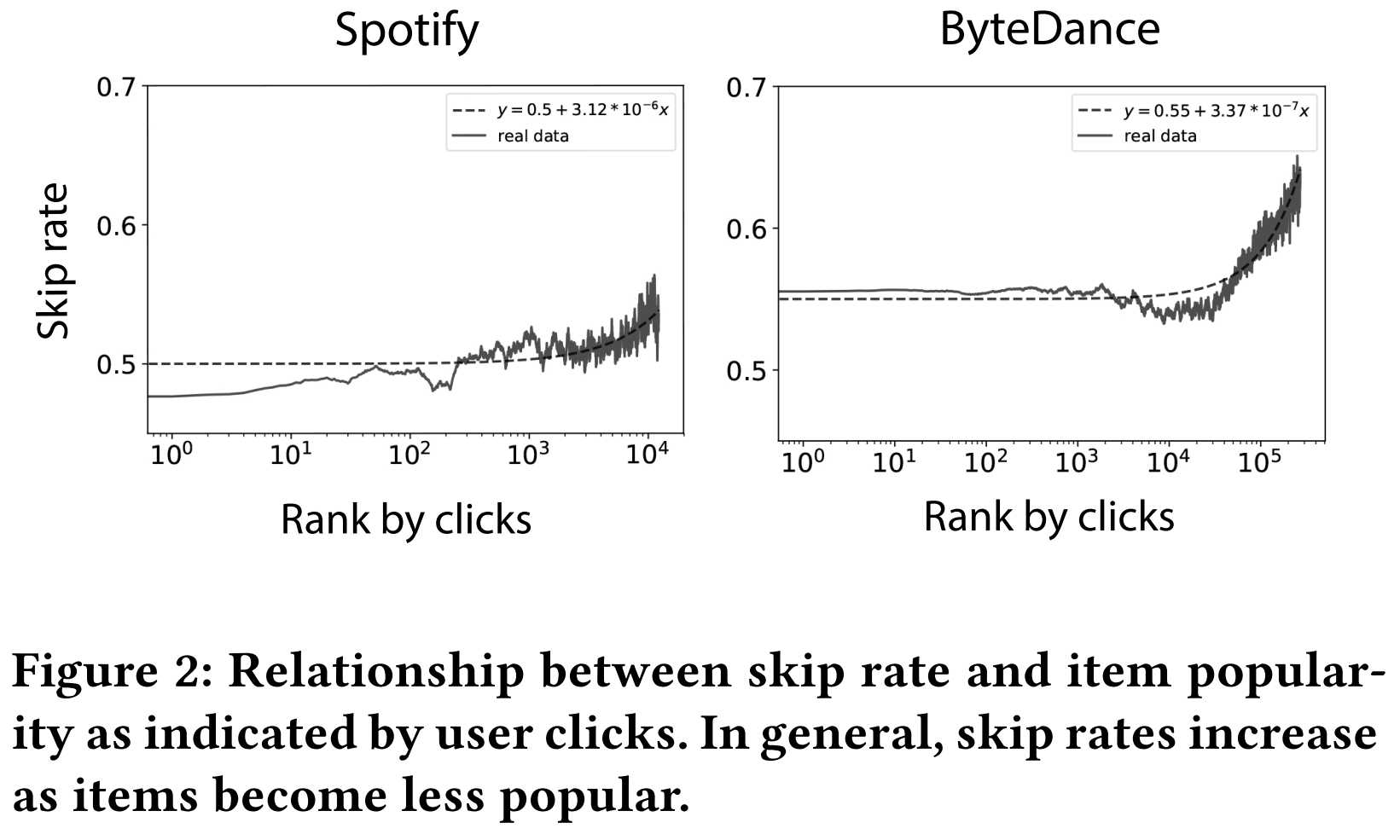
作者還觀察到,越冷門的物品,被跳過的比例越高。這可能是物品質量導致的。
3.2 點擊和反饋信息
用點擊數據作為訓練集,分別在常規測試集和興趣測試集上進行性能測試,研究模型對點擊行為和對完播行為的推薦精度差別。
- 常規測試集是指,將所有物品作為候選集,將測試階段點擊物品作為正樣本。
- 興趣測試集是指,將測試階段的點擊樣本作為候選列表,將完播數據作為正樣本(看能不能把完播排在跳過前面)。
最後得出結論,模型對點擊行為的預測能力遠高於對完播行為的預測能力。
這一段實驗設計有問題,詳見Weakness部分
\hline \text { Dataset } & \text { # of users } & \text { # of items } & \text { # of records } & \text { Density } & \text { Percentage of skips % } \\
\hline \text { Spotify } & 229,792 & 100,586 & 4,090,895 & 0.018 \% & 51.05 \% \\
\text { ByteDance } & 37,043 & 271,259 & 9,391,103 & 0.093 \% & 55.13 \% \\
\hline
\end{array}
\]
4.方法
方法是比較簡單的,雖然寫的很複雜。
總體思路就是把用戶跳過的樣本(skip)也當做負樣本。
4.1 Pointwise Loss
\(O_P\)表示用戶未跳過的交互,\(O_N\)表示用戶跳過的交互,\(O_M\)表示用戶未交互的物品。
\]
其實就是把跳過的物品當做負樣本,並且加個權重。
4.2 Pairwise Loss
\(O_P\)中,i表示沒跳過的物品,j表示跳過的物品。
\(O_N\)中,i表示沒跳過的物品,j沒交互過的物品。
\]
注意論文中把第二項的ij反了過來(增加一點複雜度),其實沒有必要。
當\(\beta = 0\)時,模型只利用沒有跳過的交互作為正樣本,而沒有利用跳過的樣本,稱為BL。
當\(\beta \not = 0\)時,模型稱為-NR。
5.實驗結果
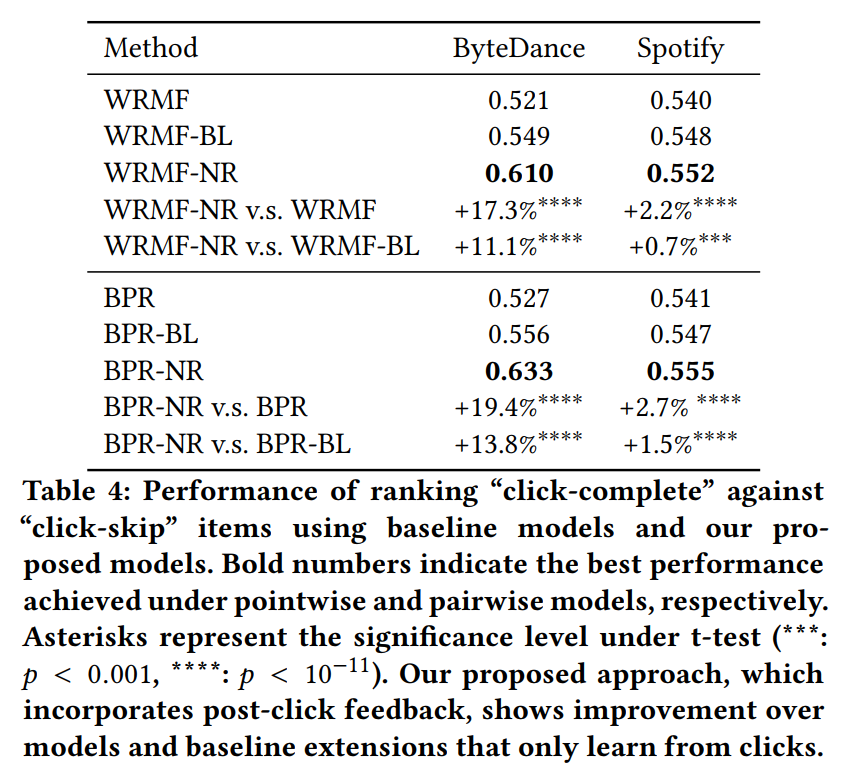
實驗結果表明,將跳過的樣本作為負樣本(NR)是有效的,且直接將這些樣本從正樣本集中去除(BL)也是有效的
可以借鑒的地方
- 3.1的分析方法
- 數據集 Spotify[1]
Weakness
-
3.2的分析不合理
- 兩種測試任務的難度是不同的,常規測試任務的負樣本很簡單,但是興趣測試任務是很難的,因此直接比較兩種設置下的AUC絕對值是不合理的。
- 比較合理的實驗設置應該是保持測試方法一致,修改訓練集數據,用(跳過+完播)和(完播)兩種訓練方式,看測試效果有什麼不同。(看到後面才發現,這已經是論文主實驗了)
-
有錯詞,例如5.2部分第三個單詞purposed,應為proposed。
-
符號不一致,5.1部分使用的符號\(\lambda_p\)和\(\lambda_n\)在前文並沒有提到。
-
[29]和[30]兩篇引用是同一篇
進一步閱讀
[15] Hongyu Lu, Min Zhang, and Shaoping Ma. 2018. Between Clicks and Satisfaction: Study on Multi-Phase User Preferences and Satisfaction for Online News Reading. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 435–444.
[34] Qian Zhao, F Maxwell Harper, Gediminas Adomavicius, and Joseph A Konstan. 2018. Explicit or implicit feedback? engagement or satisfaction?: a feld experiment on machine-learning-based recommender systems. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing. ACM, 1331–1340.
[5] Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative fltering for implicit feedback datasets. In Eighth IEEE International Conference on Data Mining (ICDM』08). IEEE, 263–272.
[8] Youngho Kim, Ahmed Hassan, Ryen W White, and Imed Zitouni. 2014. Modeling dwell time to predict click-level satisfaction. In Proceedings of the 7th ACM international conference on Web search and data mining. ACM, 193–202.
[11] Mounia Lalmas, Janette Lehmann, Guy Shaked, Fabrizio Silvestri, and Gabriele Tolomei. 2015. Promoting positive post-click experience for in-stream yahoo gemini users. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1929–1938.

