Kafka從入門到放棄(三) —— 詳說生產者
上一篇對Kafka做了簡單介紹,還沒看的朋友可以點擊下方鏈接。
消息中間件必須與生產者和消費者一起存在才有意義,這次先來聊聊Kafka的生產者。
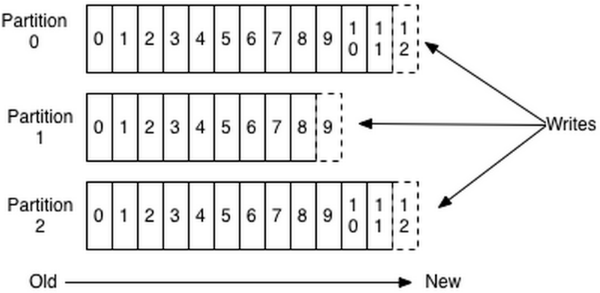
在開始之前,先了解一下消息在Kafka中是如何存儲的,如下圖所示,一般我們稱那些數字為offset(偏移量)一般來說,消息在持久化後應該是有序的,這裡的有序是針對分區的,而不是針對 Topic 的。
而且,生產者寫入消息時,是往 Leader 寫入,Follower 從 Leader 進行複製。
別看生產者只是發消息,調用 API 也是幾行代碼,但它的學問多着呢。為更好地理解後面的內容,請帶着以下問題閱讀:
- 生產者發送消息前會做什麼準備?
- 生產者發送消息怎麼保證數據不丟失?
- 生產者發送消息如何保證消息有序性?
- 生產者發送的消息是怎麼分區的?
生產者設計了一個緩衝池,可以通過修改 buffer.memory 參數設置其大小;緩衝池內又有多個 Batch,當有多個消息需要寫入同一個分區時,消息會先往 Batch 裏面寫入,等消息達到 batch.size 的時候開始發送,如果 batch.size 設置太小,生產者會頻繁發送消息,帶來更多的網絡開銷;
有些讀者可能有這個疑問,如果有時候生產者生產的消息很少很小,一直達不到批次的大小,而消費者對時效性要求比較高,這種情況怎麼辦?其實,默認情況下,只要有線程,即使批次里只有一條消息,也會直接發送出去。但是,可以設置參數 linger.ms 來指定等待消息加入批次的時間,只要當批次消息達到 batch.size 或者等待時間達到 linger.ms 的時候,消息就會發送。
除此之外,生產者可以對消息進行壓縮,以降低網絡開銷以及存儲開銷,通過設置參數 compression.type 設置相應的壓縮算法。
先拋開 Kafka 現有確認機制,假如一條消息發到對應分區後,沒有任何確認就緊接着發送第二條,很難不造成數據丟失。
於是我們讓分區在收到消息後返回確認消息給生產者,生產者收到後發送下一條。
就這樣,消息很順利地發著,正好在 Leader 拿到最新的消息並返回確認給生產者的時候,Leader 掛了,此時,Follower 還沒同步最新的消息,而生產者已經接收到了分區返回的確認,這時候還是丟了數據。
因此我們讓 Leader 以及參與複製的 Follower 都收到消息後返回確認,這樣就能最大程度保證消息不丟失,不過延遲較高。
針對上述的情況,Kafka 設置了一個 acks 參數,指定了必須有幾個副本收到消息生產者才認為是寫入成功了。
- acks=0,生產者只管寫入,不會等待 Broker 返迴響應,默認成功。這種情況最容易造成數據丟失,不過吞吐量最高;
- acks=1,Leader 收到消息後響應,生產者才認為寫成功,這種也會造成丟失;
- acks=all,Kafka 集群內部會維護一個副本清單 ISR(後續會寫,再此不做描述),當 ISR 里的所有副本都收到消息,才認為寫入成功,最大程度保證消息不丟失,不過可能會造成延遲較高。
另外,Kafka 還有一個參數 retries,表示當消息發送失敗後,生產者重試的次數,默認為0,如果對丟失消息零容忍,那就不能設置為0.
事實上,生產者在收到分區返回的確認消息前,還是可以持續發送消息的,這個可以通過設置 max.in.flight.requests.per.connection 參數進行修改,這個參數指定了生產者在收到響應前可以發送多少個消息。
這裡需要注意的是,如果這個參數不為1,而 retries 參數也不為 0 的時候,當發生重試的時候,有可能造成分區數據順序錯亂。在有些場景下,順序是很重要的,比如分析交易流水的過程,某個第一次存款的客戶先存1塊錢再取1塊錢是正常的,但反過來可能就有點奇怪了。
所以,如果要保證數據不丟失,同時要保證數據有序性,就需要將 retries 設置為非 0 整數,max.in.flight.requests.per.connection 設置為 1,注意不是 0.
生產者可以指定鍵作為分區鍵,如果不指定,生產者會使用輪詢算法將消息均勻的發到各個分區上
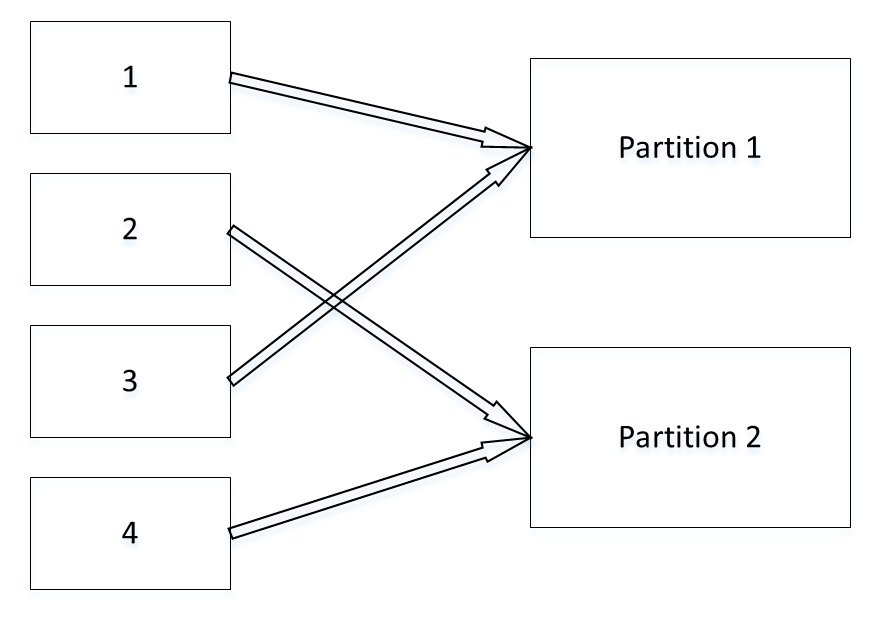
但如果指定了分區鍵,Kafka 會使用自己的 hash 算法獲得 hash 值,然後根據 hash 值發到相應的分區。
到這,回顧一下前面的幾個問題,是不是有點豁然開朗了?
如果覺得寫得不錯,對你有幫助,麻煩點個小小的贊,謝謝!
轉載請註明出處:工眾號「大數據的奇妙冒險」,博客園 Lyu_zt


