4個優化方法,讓你能了解join計算過程更透徹
摘要:現如今, 跨源計算的場景越來越多, 數據計算不再單純局限於單方,而可能來自不同的數據合作方進行聯合計算。
本文分享自華為雲社區《如何高可靠、高性能地優化join計算過程?4個優化讓你掌握其中的精髓》,作者: breakDraw 。
現如今, 跨源計算的場景越來越多, 數據計算不再單純局限於單方,而可能來自不同的數據合作方進行聯合計算。
聯合計算時,最關鍵的就是標識對齊,即需要將兩方的角色將同一個標識(例如身份證、註冊號等)用join操作關聯起來, 提取出兩邊的交集部分, 後面再進行計算,得到需要的結果。
而這種join過程看似簡單,其實有非常多的門道,這裡讓我從最簡單的join方法開始, 一步步演示join的優化過程。
首先假設以下場景:
- 有tb1, tb2兩張表的數據,存放在不同位置
- 各有相同的id列。
- tb1有1億行數據,而tb2表只有10w行數據。
1.簡單全集2次循環碰撞
拿到2張表的全量數據, 直接2個for循環進行遍歷
如果id匹配,則合併2個行記錄作為join結果
for (row r1 : tb1) { for(row r2 : tb2) { if(idMatch(r1, r2) { // 獲取r1和r2拼接後的r3 r3 = join(r1,r2) result.add(r3) } } }
圖示如下:
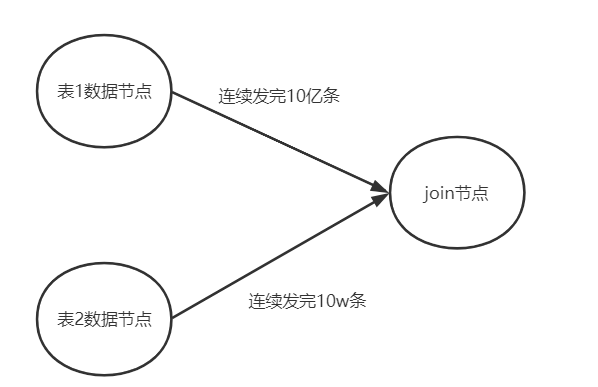
上面這種join有2個問題:
- 性能很差,兩次for循環相當於O(mn)的複雜度
- 為了收集全量數據, 可能導致內存溢出,例如大表有10億行數據,無法一次性存放。
2. 使用哈希表優化性能
首先解決剛才提到的第一個問題
實際上join過程就很像一種命中過程, 因此可以聯想到哈希表。
- 我們使用一個 hashMap存儲較小的tb2表(只有10w行)。
使用id列當作哈希表的key。 - 只對大表做for循環,如果id列在哈希表中能匹配中,則取出對用數據做拼接
for (row r1 : tb1) { if(idMap.containKey(r1.getId())) { row r2 = idMap.get(r1.getId()); r3 = join(r1,r2) result.add(r3) } }
這樣複雜度就優化到了O(m)了
3. 大表數據分批傳輸
還有一個問題沒解決: 」為了收集全量數據, 可能導致內存溢出「。
那我們可以將大表按照特定數量進行拆分,分成多批數據
例如每次以1000條的數量,和小表進行上面的哈希表碰撞過程。這樣空間複雜度就是O (K + n)。
當每碰撞完一次,才接着接收下一批數據。如下面所示
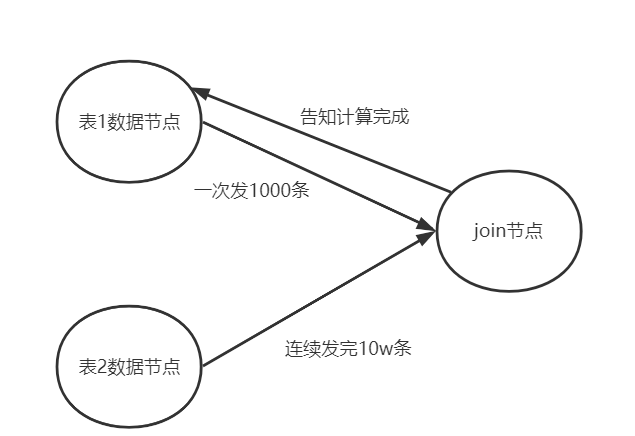
注意, 」告知計算完成這種響應機制「也可以優化成阻塞的緩衝隊列。
但是還有個問題, 如果小表本身也很大, 例如1億條, 計算節點連小表的哈希表都存不下,怎麼辦?
另外單節點計算的CPU有限,如何能在短時間內快速提升性能?
4. 分佈式計算
當計算節點存不下小表構成的哈希表時, 這時候可以擴容2個join計算節點, 引入分佈式計算來分擔內存壓力。
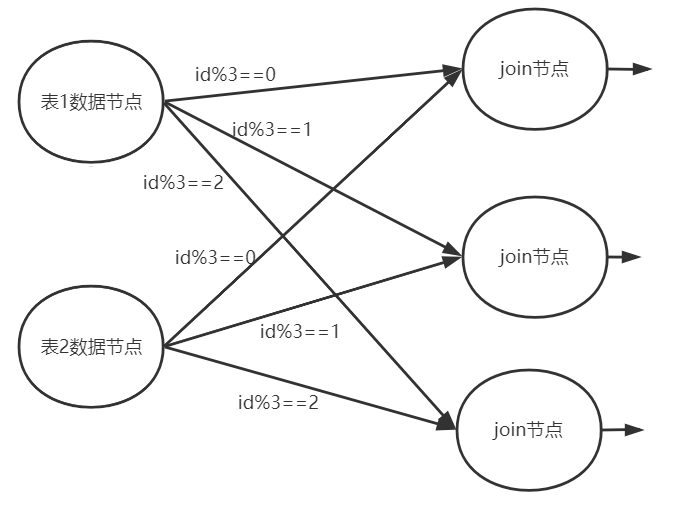
例如我們可以對id列進行shuffle分片
- id%3==0 分到計算節點A
- id%3==1 分到計算節點B
- id%3 ==2 分到計算階段C
如果id是均勻的, 則小表的數據就被拆成了3份,也許就能正好存下了。
大表數據按同樣的方式分片, 分到相同的節點, 對計算結果是沒有影響的, 只要你的分片算法確保id匹配的行一定在同一個節點即可。
另外性能上, 分佈式計算理論上按照節點數量也能夠提升N倍的join速度。
這種分佈式計算的方式已經能解決大部分join作業了,但是還有個問題:
- 假設網絡帶寬壓力比較大(比如買的帶寬比較便宜,發送數據的成本比較大)
- 部分涉及安全的計算場景中可能需要對數據做加密
這2種情況都會造成數據在輸出時會耗費很多時間,甚至超過join的過程。那麼該如何優化?
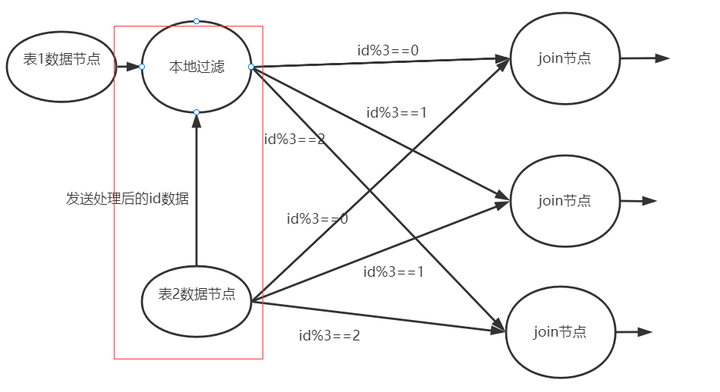
5. 本地join計算
本地計算,指的就是在通過網絡輸出數據前,先提前做一些預處理。這種操作在各種計算引擎中都有體現
- 在spark中有一個叫boardCast廣播數據的機制
- presto中有一種叫runtimeFilter的方式。
對於join過程, 我們可以:
- 將小表的id進行一定的壓縮處理(例如哈希之後取前x位)
這樣可以減少傳輸的數據量。 - 然後將這塊數據傳輸給大表所在的節點, 進行提前的簡單join篩選, 這樣就可以提前過濾掉很多的沒必要通過網絡輸出的數據。
以上僅僅只是最基礎的join優化過程, 而在海量數據、高性能、高安全、跨網絡的複雜場景中, 關於join計算還會有更多的挑戰。
因此可以關注華為可信智能計算TICS服務,專註高性能高安全的聯邦計算和聯邦學習,推動跨機構數據的可信融合和協同,安全釋放數據價值。