ICCV2021 | 用於視覺跟蹤的學習時空型transformer
前言
本文介紹了一個端到端的用於視覺跟蹤的transformer模型,它能夠捕獲視頻序列中空間和時間信息的全局特徵依賴關係。在五個具有挑戰性的短期和長期基準上實現了SOTA性能,具有實時性,比Siam R-CNN快6倍。
本文來自公眾號CV技術指南的
關注公眾號CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。

論文:Learning Spatio-Temporal Transformer for Visual Tracking
代碼://github.com/researchmm/Stark
Backgound
卷積核不擅長對圖像內容和特徵的長期相關性進行建模,因為它們只處理局部鄰域,無論是在空間上還是在時間上。目前流行的追蹤器,包括離線siamese追蹤器和在線學習模型,幾乎都是建立在卷積運算的基礎上。因此,這些方法只能很好地對圖像內容的局部關係進行建模,但僅限於捕獲遠程的全局交互。這樣的缺陷可能會降低模型處理全局上下文信息對於定位目標對象很重要的場景的能力,例如經歷大規模變化或頻繁進出視圖的對象。
空間信息和時間信息對於目標跟蹤都是重要的。前者包含用於目標定位的對象外觀信息,而後者包含對象跨幀的狀態變化。以前的siamese跟蹤器只利用空間信息進行跟蹤,而在線方法使用歷史預測進行模型更新。雖然這些方法很成功,但它們並沒有明確地對空間和時間之間的關係進行建模。
Contribution
受最近的檢測transformer(DETR)的啟發,論文提出了一種新的端到端跟蹤結構,採用編碼器-解碼器transformer來提高傳統卷積模型的性能。
新架構包含三個關鍵組件:編碼器、解碼器和預測頭。
1. 編碼器接受初始目標對象、當前圖像和動態更新模板的輸入。編碼器中的self-attention模塊通過輸入的特徵依賴關係來學習輸入之間的關係。由於模板圖像在整個視頻序列中被更新,因此編碼器可以捕獲目標的空間和時間信息。
2. 解碼器學習嵌入的查詢以預測目標對象的空間位置。
3. 使用基於角點的預測頭來估計當前幀中目標對象的邊界框。同時,學習記分頭來控制動態模板圖像的更新。
總而言之,這項工作有三個貢獻。
1. 提出了一種新的致力於視覺跟蹤的transformer架構。它能夠捕獲視頻序列中空間和時間信息的全局特徵依賴關係。提出使用動態更新模板。
2. 整個方法是端到端的,不需要餘弦窗口、bounding box平滑等後處理步驟,大大簡化了現有的跟蹤流水線。
3. 提出的跟蹤器在五個具有挑戰性的短期和長期基準上實現SOTA性能,同時以實時速度運行。
Methods
論文提出了一種用於視覺跟蹤的時空transformer網絡,稱為STARK。論文基於一種簡單的基線方法,該方法直接應用原始編解碼器變壓器進行跟蹤,且只考慮了空間信息。論文擴展基線以學習用於目標定位的空間和時間表示,引入了一個動態模板和一個更新控制器來捕捉目標對象的外觀變化。
Baseline方法
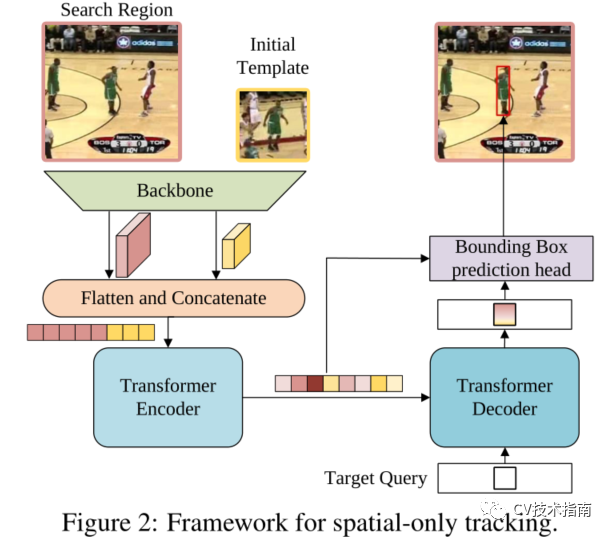
圖2為baseline方法
baseline主要由三個部分組成:卷積主幹、編解碼器轉換器和bounding box預測頭。
原圖像先通過CNN backbone進行降維和降採樣,完了再進行Flatten 和Concatenate得到向量,向量再加入正弦位置嵌入,作為transformer的Encoder輸入。隨機初始化一個查詢向量,Decoder將目標查詢和來自編碼器的增強特徵序列作為輸入。與DETR採用100個對象查詢不同,論文只向解碼器輸入一個查詢來預測目標對象的一個bounding。此外,由於只有一個預測,論文去掉了DETR中用於預測關聯的匈牙利算法。目標查詢可以關注模板上的所有位置和搜索區域特徵,從而學習最終邊界框預測的魯棒表示。

![]()
DETR採用三層感知器預測目標坐標。然而,正如GFLoss所指出的那樣,直接回歸坐標等同於擬合狄拉克增量分佈,它沒有考慮數據集中的模糊性和不確定性。這種表示方式不靈活,對目標跟蹤中的遮擋和雜亂背景等挑戰也不夠穩健。
為了提高box估計的質量,通過估計box角點的概率分佈,設計了一種新的預測頭。如圖3所示,首先從編碼器的輸出序列中提取搜索區域特徵,然後計算搜索區域特徵與解碼器輸出嵌入的相似度。最後特徵序列會reshape成3維,通過L層Conv-BN-ReLU的全卷積網絡輸出兩個概率圖,一個概率圖為bounding box左上角的坐標,一個概率圖為bounding box右下角的坐標,跟DETR一樣,這裡不多細講。
本文方法
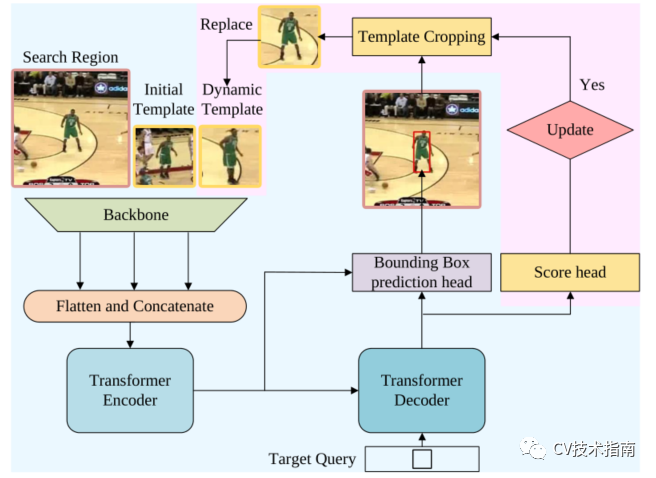
論文提出的時空跟蹤框架。粉色突出顯示了與純空間架構的區別。
與僅使用第一幀和當前幀的基線方法不同,時空方法引入了從中間幀採樣的動態更新模板作為附加輸入(論文的唯一貢獻),如圖所示。除了初始模板的空間信息外,動態模板還可以捕捉目標外觀隨時間的變化,提供額外的時間信息。三元組的特徵圖被扁平化和拼接,然後發送到編碼器。該編碼器通過在空間和時間維度上對所有元素之間的全局關係建模來提取可區分的時空特徵。
在跟蹤過程中,有些情況下不應更新動態模板。例如,當目標被完全遮擋或移出視線時,或者當跟蹤器漂移時,裁剪的模板是不可靠的。為簡單起見,論文認為只要搜索區域包含目標,就可以更新動態模板。為了自動確定當前狀態是否可靠,論文添加了一個簡單的分數預測頭,它是一個三層感知器,然後是Sigmoid激活。如果得分高於閾值τ,則認為當前狀態可靠。
訓練和推理
正如最近的工作所指出的那樣,定位和分類的聯合學習可能會導致這兩個任務的次優解,這有助於將定位和分類解耦。因此,論文將訓練過程分為兩個階段,將定位作為首要任務,將分類作為次要任務。
具體地說,在第一階段,除了分數頭外,整個網絡都進行了端到端的訓練,只使用與定位相關的損失。在這個階段,確保所有的搜索圖像都包含目標對象,並讓模型學習定位能力。在第二階段,僅利用定義為如下的二進制交叉熵損失來優化分數頭
並且凍結所有其他參數以避免影響定位能力。

![]()
這樣,最終的模型在經過兩個階段的訓練後,既學習了定位能力,又學習了分類能力。
在推理過程中,在第一幀中初始化兩個模板和對應的特徵。然後,裁剪搜索區域並將其送入網絡,生成一個邊界框和置信度分數。僅當達到更新間隔並且置信度分數高於閾值τ時,才更新動態模板。為了提高效率,論文將更新間隔設置為Tu 幀。新的模板被從原始圖像中裁剪出來,然後饋送到主幹中進行特徵提取。
Conclusion
與以前的長期跟蹤器相比,提出的方法的框架要簡單得多。具體地說,以前的方法通常由多個組件組成,例如基本跟蹤器、目標驗證模塊和全局檢測器。相比之下,提出的方法只有一個以端到端方式學習的網絡。大量的實驗表明,提出的方法在短期和長期跟蹤基準上都建立了新的SOTA性能。
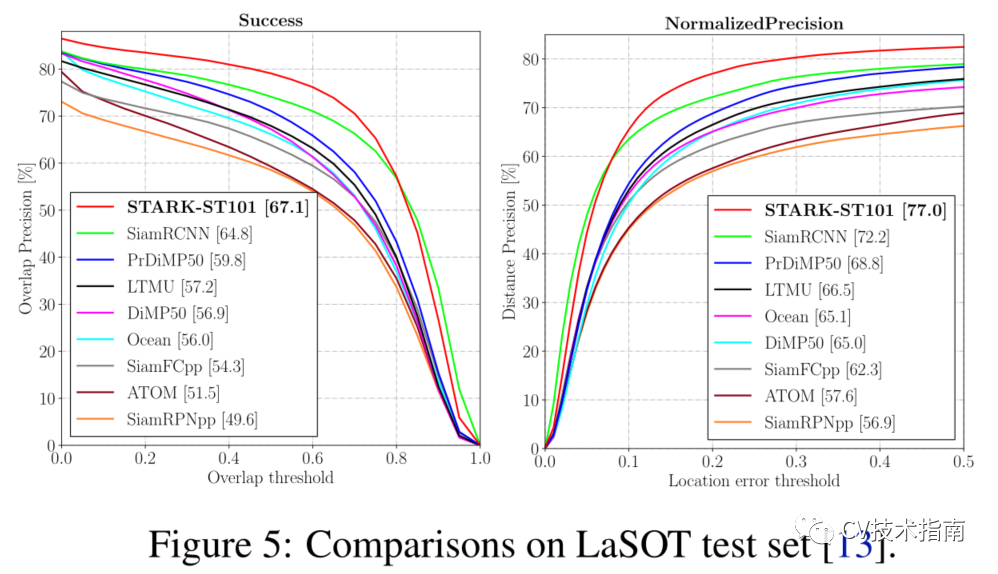
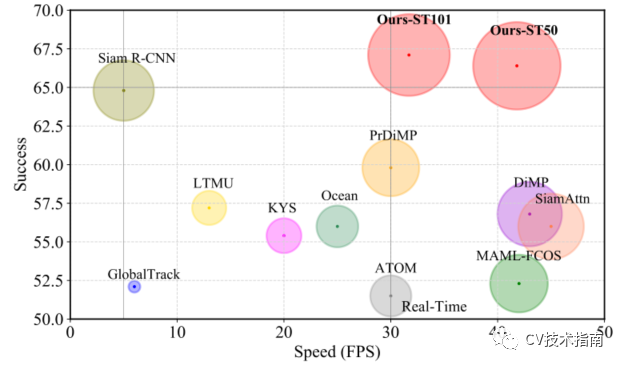
例如,論文的時空transformer跟蹤器在GOT-10K和LaSOT上分別比Siam R-CNN高3.9%(AO score)和2.3%(Success)。此外,論文的跟蹤器可以實時運行,在Tesla V100圖形處理器上比Siam R-CNN(30V.S.5fps)快6倍,如圖所示
![]()
![]()
與LaSOT上SOTA的比較。將Success性能與Frame-PerSecond(Fps)跟蹤速度進行了可視化比較。
在多個數據集上與其它SOTA方法的比較
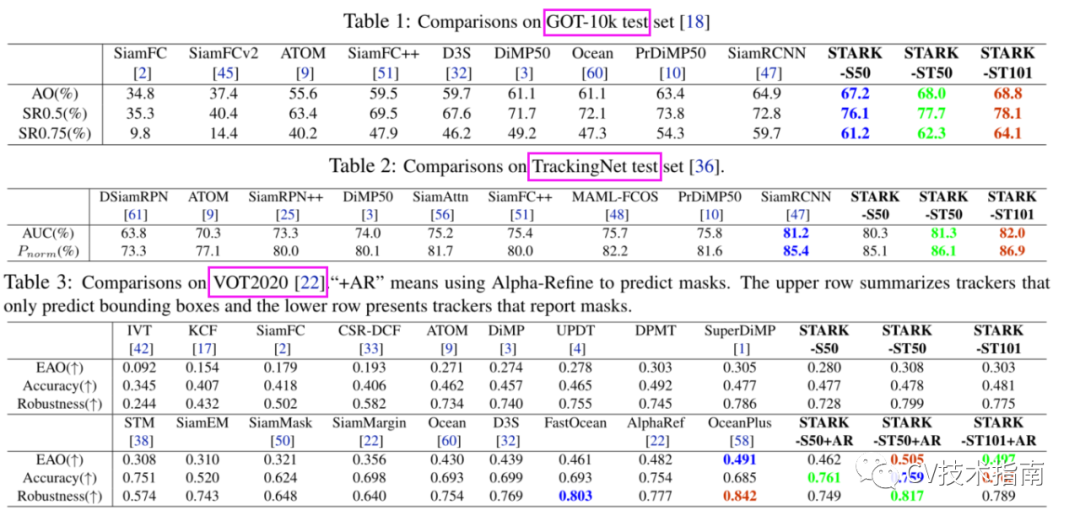
![]()
速度、計算量和參數
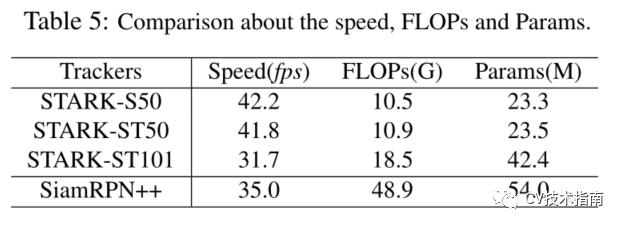
![]()
歡迎關注公眾號 CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「入門指南「可獲取計算機視覺入門所有必備資料。

![]()
其它文章


