2022年你應該掌握這些機器學習算法
想要成為一名合格的 AI 工程師,並不是一件簡單的事情,需要掌握各種機器學習算法。對於小白來說,入行 AI 還是比較困難的。
為了讓初學者更好的學習 AI,網絡上出現了各種各樣的學習資料,也不乏很多 AI 大牛提供免費的授課視頻提供幫助。
近日,來自佐治亞理工學院的理學碩士 Terence Shin 在博客發佈平台 Medium 撰文《2022 年你應該知道的所有機器學習算法》。文中涵蓋了 5 類最重要的機器學習算法:集成學習算法;可解釋算法;聚類算法;降維算法;相似性算法。
目前,Terence Shin 在 Medium 顯示為 Top 1000 作者,有 62K 關注者,目前這篇文章已經有 1.4K 點贊。
集成學習算法
為了理解什麼是集成學習算法,你首先需要知道什麼是集成學習。簡單來講,集成學習是一種同時使用多個模型以獲得比單個模型性能更好的方法。
更形象的解釋,我們以一個學生和一個班級的學生為例:
想像一下,一個學生解決一個數學問題 VS 一個班級學生解決相同的問題。作為班級,所有學生可以相互檢查彼此的答案,並一致找出正確答案解決問題。另一方面,作為學生的個人,如果他 / 她的答案是錯誤的,那麼沒有其他人可以驗證他 / 她的答案正確與否。
因此,由學生組成的班級類似集成學習算法,其中幾個較小的算法協同工作以制定最終響應。
關於集成學習的更多信息請參考://towardsdatascience.com/ensemble-learning-bagging-and-boosting-explained-in-3-minutes-2e6d2240ae21
集成學習算法對於回歸和分類問題或監督學習問題最有用。由於其固有的性質,它優於傳統的樸素貝葉斯、支持向量機、決策樹等機器學習算法。集成學習的代表方法有:Random Forests、XGBoost、LightGBM、CatBoost.
可解釋算法
可解釋算法幫助我們識別和理解與結果有顯著關係的變量。因此,與其創建一個模型來預測響應變量的值,我們可以創建可解釋模型來理解模型中變量之間的關係。
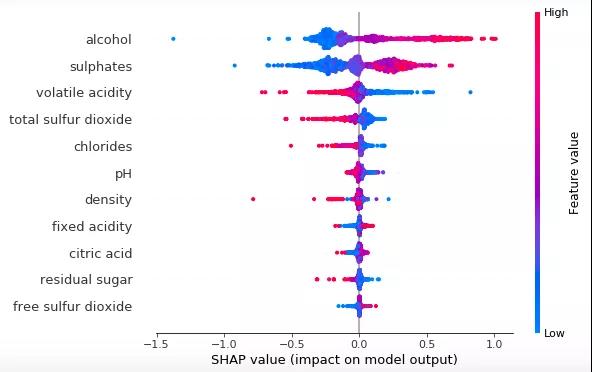
當你想要了解模型為什麼做出這個決策、或者你想要理解兩個或多個變量是如何相互關聯的,可解釋模型能夠提供幫助。在實踐中,解釋機器學習模型能夠實現的性能和機器學習模型本身一樣重要。如果你不能解釋一個模型是如何工作的,那麼將不會有人願意使用它。
目前基於假設檢驗的傳統可解釋模型主要包括:線性回歸、邏輯回歸;此外,可解釋模型還包括 SHAP 和 LIME 這兩種流行技術,它們被用來解釋機器學習模型。
聚類算法
聚類是按照某個特定標準 (如距離) 把一個數據集分割成不同的類或簇,使得同一個簇內的數據對象的相似性儘可能大,同時不在同一個簇中的數據對象的差異性也儘可能地大。也即聚類後同一類的數據儘可能聚集到一起,不同類數據盡量分離。
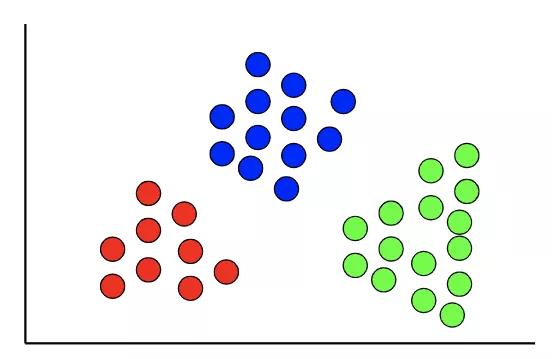
聚類的一般過程包括數據準備、特徵選擇、特徵提取、聚類、聚類結果評估。
聚類算法可用於進行聚類分析,它是一項無監督學習任務,可以將數據分組到聚類中。與目標變量已知的監督學習不同,聚類分析中沒有目標變量。
聚類能夠發現數據中的自然模式和趨勢。k-means 聚類和層次聚類是最常見的兩種聚類算法。
降維算法
數據降維算法是機器學習算法中的大家族,它的目標是將向量投影到低維空間,以達到可視化、分類等目的。

降維技術在很多情況下都很有用:在數據集中有數百甚至數千個特徵並且用戶需要選擇少數特徵時,需要用到降維;當 ML 模型過度擬合數據也需要降維,這意味着用戶需要減少輸入特徵的數量。
目前已經存在大量的數據降維算法,可以從不同的維度進行分類。按照是否有使用樣本的標籤值,可以將降維算法分為有監督降維和無監督降維;按照降維算法使用的映射函數,可以將算法分為線性降維與非線性降維。其中,主成分分析 PCA、線性判別分析 LDA 為線性降維。
相似性算法
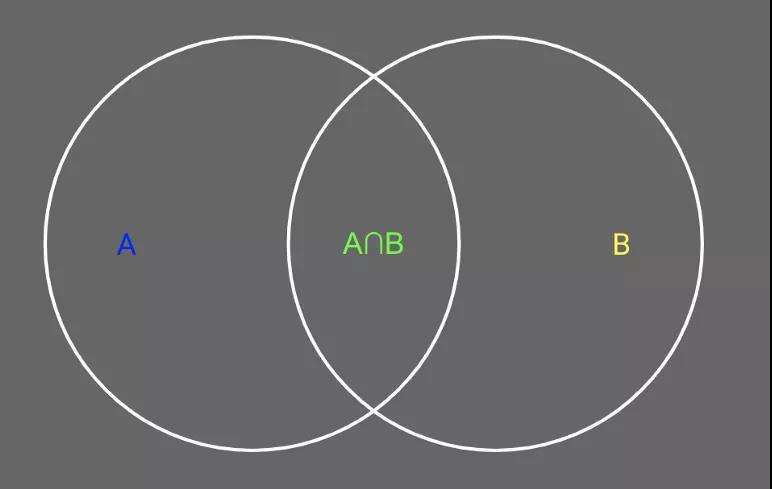
在機器學習中,我們經常需要知道個體間差異的大小,進而評價個體的相似性和類別。相似性算法是計算節點、數據點、文本對相似性的算法,如歐幾里得距離,也有計算文本相似度的相似度算法,如 Levenshtein 算法。
相似性算法主要包括:K 近鄰算法、歐幾里得距離、餘弦相似度、奇異值分解等。其中,K 近鄰算法,即是給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最鄰近的 K 個實例,這 K 個實例的多數屬於某個類,就把該輸入實例分類到這個類中。歐幾里得距離是歐幾里得空間中兩點間普通(即直線)距離。餘弦相似度是通過計算兩個向量的夾角餘弦值來評估他們的相似度。


