開發好能重構的代碼,都是這麼乾的
摘要:絕大多數碼農沒日沒夜被需求憋着肝出來的代碼,無論有多麼的吭哧癟肚,都不可能有重構,只有重新寫。
本文分享自華為雲社區《還重構?就你那代碼只能鏟了重寫!》,作者:小傅哥。
一、前言
我們不一樣,就你沒對象! 對,你是面向過程編程的!
我說的,絕大多數碼農沒日沒夜被需求憋着肝出來的代碼,無論有多麼的吭哧癟肚,都不可能有重構,只有重新寫。為什麼?因為重新寫所花的時間成本,遠比重構一份已經爛成團的代碼,要節省時間。但誰又不敢保證重寫完的代碼,就比之前能好多少,況且還要承擔著重寫後的代碼事故風險和幾乎體現不出來的業務價值!
雖然代碼是給機器運行的,但同樣也是給人看的,並且隨着每次需求的迭代、變更、升級,都需要研發人員對同一份代碼進行多次開發和上線,那麼這裡就會涉及到可維護、易擴展、好交接的特點。
而那些不合理分層實現代碼邏輯、不寫代碼注釋、不按規範提交、不做格式化、命名隨意甚至把 queryBatch 寫成 queryBitch 的,都會造成後續代碼沒法重構的問題。那麼接下來我們就分別介紹下,開發好能重構的代碼,都要怎麼干!
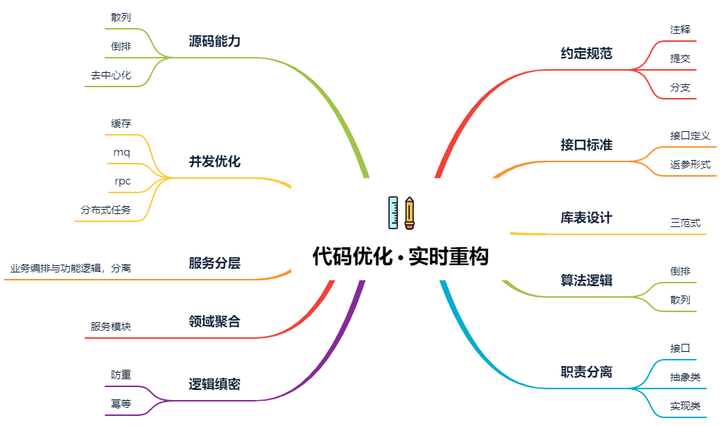
二、代碼優化
1. 約定規範
# 提交:主要 type feat: 增加新功能 fix: 修復bug # 提交:特殊 type docs: 只改動了文檔相關的內容 style: 不影響代碼含義的改動,例如去掉空格、改變縮進、增刪分號 build: 構造工具的或者外部依賴的改動,例如webpack,npm refactor: 代碼重構時使用 revert: 執行git revert打印的message # 提交:暫不使用type test: 添加測試或者修改現有測試 perf: 提高性能的改動 ci: 與CI(持續集成服務)有關的改動 chore: 不修改src或者test的其餘修改,例如構建過程或輔助工具的變動 # 注釋:類注釋配置 /** * @description: * @author: ${USER} * @date: ${DATE} */
- 分支:開發前提前約定好拉分支的規範,比如日期_用戶_用途,210905_xfg_updateRuleLogic
- 提交:作者,type: desc 如:小傅哥,fix:更新規則邏輯問題 參考Commit message 規範
- 注釋:包括類注釋、方法注釋、屬性注釋,在 IDEA 中可以設置類注釋的頭信息 Editor -> File and Code Templates -> File Header 推薦下載安裝 IDEA P3C 插件 Alibaba Java Coding Guidelines,統一標準化編碼方式。
2. 接口標準
在編寫 RPC 接口的時候,返回的結果中一定要包含明確的Code碼和Info描述,否則使用方很難知道這個接口是否調用成功還是異常,以及是什麼情況的異常。
定義 Result
public class Result implements java.io.Serializable { private static final long serialVersionUID = 752386055478765987L; /** 返回結果碼 */ private String code; /** 返回結果信息 */ private String info; public Result() { } public Result(String code, String info) { this.code = code; this.info = info; } public static Result buildSuccessResult() { Result result = new Result(); result.setCode(Constants.ResponseCode.SUCCESS.getCode()); result.setInfo(Constants.ResponseCode.SUCCESS.getInfo()); return result; } // ...get/set }
返回結果包裝:繼承
public class RuleResult extends Result { private String ruleId; private String ruleDesc; public RuleResult(String code, String info) { super(code, info); } // ...get/set } // 使用 public RuleResult execRule(DecisionMatter request) { return new RuleResult(Constants.ResponseCode.SUCCESS.getCode(), Constants.ResponseCode.SUCCESS.getInfo()); }
返回結果包裝:泛型
public class ResultData<T> implements Serializable { private Result result; private T data; public ResultData(Result result, T data) { this.result = result; this.data = data; } // ...get/set } // 使用 public ResultData<Rule> execRule(DecisionMatter request) { return new ResultData<Rule>(Result.buildSuccessResult(), new Rule()); }
- 兩種接口返回結果的包裝定義,都可以規範返回結果。在這樣的方式包裝後,使用方就可以用統一的方式來判斷Code碼並做出相應的處理。
3. 庫表設計
三範式:是數據庫的規範化的內容,所謂的數據庫三範式通俗的講就是設計數據庫表所應該遵守的一套規範,如果不遵守就會造成設計的數據庫不規範,出現數據庫字段冗餘,數據的查詢,插入等操作等問題。
數據庫不僅僅只有三範式(1NF/2NF/3NF),還有BCNF、4NF、5NF…,不過在實際的數據庫設計時,遵守前三個範式就足夠了。再向下就會造成設計的數據庫產生過多不必要的約束。
0NF

- 第零範式是指沒有使用任何範式,數據存放冗餘大量表字段,而且這樣的表結構非常難以維護。
1NF
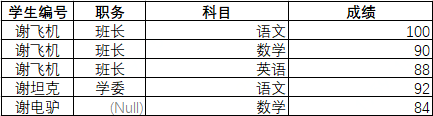
- 第一範式是在第零範式冗餘字段上的改進,把重複字段抽離出來,設計成一個冗餘數據較少便於存儲和讀取的表結構。
- 同時在第一範式中也指出,表中的所有字段都應該是原子的、不可再分割的,例如:你不能把公司僱員表的部門名稱和職責存放到一個字段。需要確保每列保持原子性
2NF

- 滿足1NF後,要求表中的列,都必須依賴主鍵,確保每個列都和主鍵列之間聯繫,而不能間接聯繫,也就是一個表只能描述一件事情。需要確保表中的每列都和主鍵相關。
3NF
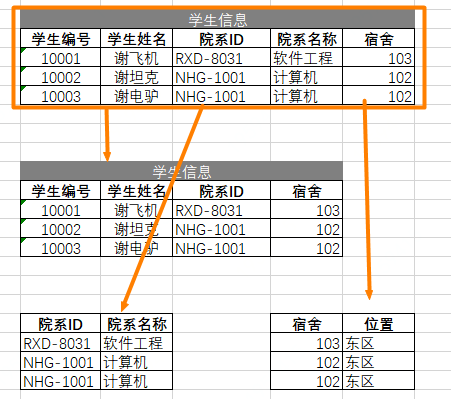
- 不能存在依賴關係,學號、姓名,到院系,院繫到宿舍,需要確保每列都和主鍵列直接相關,而不是間接相關。
反三範式
三大範式是設計數據庫表結構的規則約束,但是在實際開發中允許局部變通:
- 有時候為了便於查詢,會在如訂單表冗餘上當時用戶的快照信息,比如用戶下單時候的一些設置信息。
- 單列列表數據匯總到總表中一個數量值,便於查詢的時候可以避免列表匯總操作。
- 可以在設計表的時候冗餘一些字段,避免因業務發展情況多變,考慮不周導致該表繁瑣的問題。
4. 算法邏輯
通常在我們實際的業務功能邏輯開發中,為了能滿足一些高並發的場景,是不可能對數據庫表上鎖扣減庫存、也不能直接for循環大量輪訓操作的,通常需要考慮 在這樣場景怎麼去中心化以及降低時間複雜度。
秒殺:去中心化
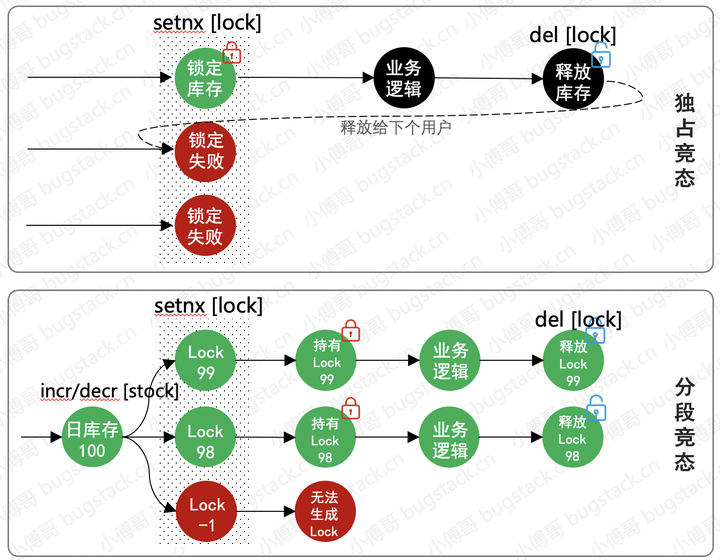
- 背景:這個一個商品活動秒殺的實現方案,最開始的設計是基於一個活動號ID進行鎖定,秒殺時鎖定這個ID,用戶購買完後就進行釋放。但在大量用戶搶購時,出現了秒殺分佈式獨佔鎖後的業務邏輯處理中發生異常,釋放鎖失敗。導致所有的用戶都不能再拿到鎖,也就造成了有商品但不能下單的問題。
- 優化:優化獨佔競態為分段靜態,將活動ID+庫存編號作為動態鎖標識。當前秒殺的用戶如果發生鎖失敗那麼後面的用戶可以繼續秒殺不受影響。而失敗的鎖會有worker進行補償恢復,那麼最終會避免超賣以及不能售賣。
算法:反面教材
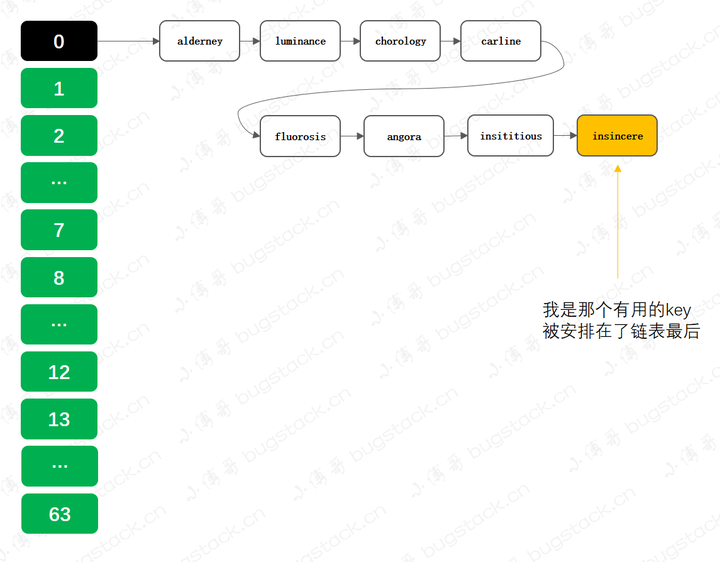
@Test public void test_idx_hashMap() { Map<String, String> map = new HashMap<>(64); map.put("alderney", "未實現服務"); map.put("luminance", "未實現服務"); map.put("chorology", "未實現服務"); map.put("carline", "未實現服務"); map.put("fluorosis", "未實現服務"); map.put("angora", "未實現服務"); map.put("insititious", "未實現服務"); map.put("insincere", "已實現服務"); long startTime = System.currentTimeMillis(); for (int i = 0; i < 100000000; i++) { map.get("insincere"); } System.out.println("耗時(initialCapacity):" + (System.currentTimeMillis() - startTime)); }
- 背景:HashMap 數據獲取時間複雜度在 O(1) -> O(logn) -> O(n),但經過特殊操作,可以把這個時間複雜度,拉到O(n)
- 操作:這是一個定義HashMap存放業務實現key,通過key調用服務的功能。但這裡的key,只有insincere有用,其他的都是未實現服務。那你看到有啥問題了嗎?
- 這點代碼乍一看沒什麼問題,看明白了就是代碼里下砒霜!它的目的就一個,要讓所有的key成一個鏈表放到HashMap中,而且把有用的key放到鏈表的最後,增加get時的耗時!
- 首先,new HashMap<>(64);為啥默認初始化64個長度?因為默認長度是8,插入元素時,當鏈表長度為8時候會進行擴容和鏈表樹化判斷,此時就會把原有的key散列了,不能讓所有key構成一個時間複雜度較高的鏈表。
- 其次,所有的 key 都是刻意選出來的,因為他們在 HashMap 計算下標時,下標值都為0,idx = (size – 1) & (key.hashCode() ^ (key.hashCode() >>> 16)),這樣就能讓所有 key 都散列到同一個位置進行碰撞。而且單詞 insincere 的意思是;不誠懇的、不真誠的!
- 最後,前7個key其實都是廢 key,不起任何作用,只有最後一個 key 有服務。那麼這樣就可以在HashMap中建出來很多這樣耗時的碰撞鏈表,當然要滿足0.75的負載因子,不要讓HashMap擴容。
其實很多算法包括:散列、倒排、負載等,都是可以用到很多實際的業務場景中的,包括:人群過濾、抽獎邏輯、數據路由等等方面,這些功能的使用可以降低時間複雜度,提升系統的性能,降低接口響應時常。
5. 職責分離
為了可以讓程序的邏輯實現更具有擴展性,通常我們都需要使用設計模式來處理各個場景的代碼實現結構。而設計模式的使用在代碼開發中的體現也主要為接口的定義、抽象類的包裝和繼承類的實現。通過這樣的方式來隔離各個功能領域的開發,以此保障每次需求擴展時可以更加靈活的添加,而不至於讓代碼因需求迭代而變得更加混亂。
案例
public interface IRuleExec { void doRuleExec(String req); } public class RuleConfig { protected Map<String, String> configGroup = new ConcurrentHashMap<>(); static { // ... } } public class RuleDataSupport extends RuleConfig{ protected String queryRuleConfig(String ruleId){ return "xxx"; } } public abstract class AbstractRuleBase extends RuleDataSupport implements IRuleExec{ @Override public void doRuleExec(String req) { // 1. 查詢配置 String ruleConfig = super.queryRuleConfig("10001"); // 2. 校驗信息 checkRuleConfig(ruleConfig); // 3. 執行規則{含業務邏輯,交給業務自己處理} this.doLogic(configGroup.get(ruleConfig)); } /** * 執行規則{含業務邏輯,交給業務自己處理} */ protected abstract void doLogic(String req); private void checkRuleConfig(String ruleConfig) { // ... 校驗配置 } } public class RuleExec extends AbstractRuleBase { @Override protected void doLogic(String req) { // 封裝自身業務邏輯 } }
類圖
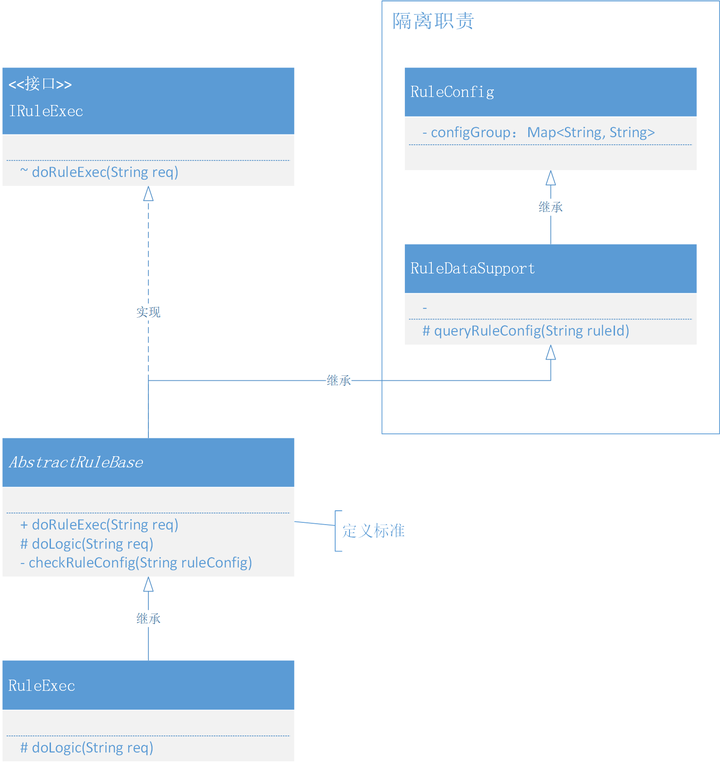
- 這是一種模版模式結構的定義,使用到了接口實現、抽象類繼承,同時可以看到在 AbstractRuleBase 抽象類中,是負責完成整個邏輯調用的定義,並且這個抽象類把一些通用的配置和數據使用單獨隔離出去,而公用的簡單方法放到自身實現,最後是關於抽象方法的定義和調用,而業務類 RuleExec 就可以按需實現自己的邏輯功能了。
6. 邏輯縝密
你的代碼出過線上事故嗎?為什麼出的事故,是樹上有十隻鳥開一槍還剩幾隻的問題嗎?比如:槍是無聲的嗎、鳥聾嗎、有懷孕的嗎、有綁在樹上的鳥嗎、邊上的樹還有鳥嗎、鳥害怕槍聲嗎、有殘疾的鳥嗎、打鳥的人眼睛花不花,… …
實際上你的線上事故基本回圍繞在:數據庫連接和慢查詢、服務器負載和宕機、異常邏輯兜底、接口冪等性、數據防重性、MQ消費速度、RPC響應時常、工具類使用錯誤等等。
下面舉個例子:用戶積分多支付,造成批量客訴。
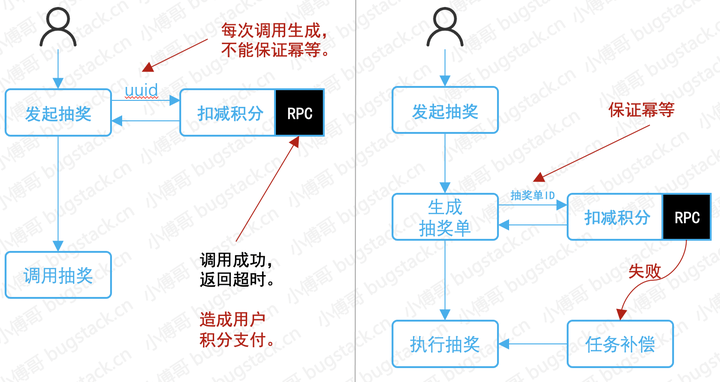
- 背景:這個產品功能的背景可能很大一部分研發都參與開發過,簡單說就是滿足用戶使用積分抽獎的一個需求。上圖左側就是研發最開始設計的流程,通過RPC接口扣減用戶積分,扣減成功後進行抽獎。但由於當天RPC服務不穩定,造成RPC實際調用成功,但返回超時失敗。而調用RPC接口的uuid是每次自動生成的,不具備調用冪等性。所以造成了用戶積分多支付現象。
- 處理:事故後修改抽獎流程,先生成待抽獎的抽獎單,由抽獎單ID調用RPC接口,保證接口冪等性。在RPC接口失敗時由定時任務補償的方式執行抽獎。流程整改後發現,補償任務每周發生1~3次,那麼也就是證明了RPC接口確實有可用率問題,同時也說明很久之前就有流程問題,但由於用戶客訴較少,所以沒有反饋。
7. 領域聚合
不夠抽象、不能寫死、不好擴展,是不是總是你的代碼,每次都像一鎚子買賣,完全是寫死的、綁定的,根本沒有一點縫隙讓新的需求擴展進去。
為什麼呢,因為很多研發寫出來的代碼都不具有領域聚合的特點,當然這並不一定非得是在DDD的結構下,哪怕是在MVC的分層里,也一樣可以寫出很多好的聚合邏輯,把功能實現和業務的調用分離開。
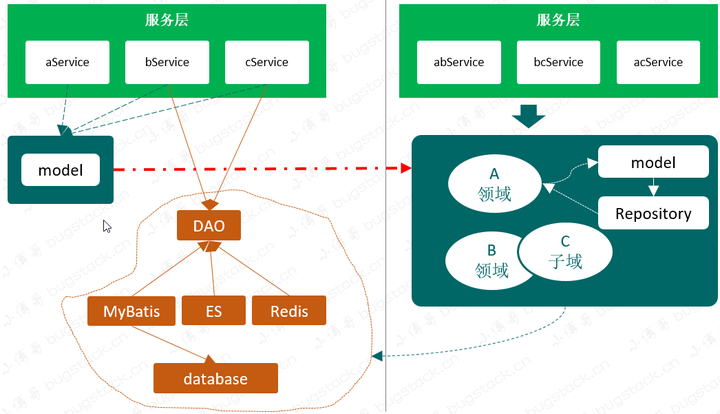
- 依靠領域驅動設計的設計思想,通過事件風暴建立領域模型,合理劃分領域邏輯和物理邊界,建立領域對象及服務矩陣和服務架構圖,定義符合DDD分層架構思想的代碼結構模型,保證業務模型與代碼模型的一致性。通過上述設計思想、方法和過程,指導團隊按照DDD設計思想完成微服務設計和開發。
- 拒絕泥球小單體、拒絕污染功能與服務、拒絕一加功能排期一個月
- 架構出高可用極易符合互聯網高速迭代的應用服務
- 物料化、組裝化、可編排的服務,提高人效
8. 服務分層
如果你想讓你的系統工程代碼可以支撐絕對多數的業務需求,並且能沉澱下來可以服用的功能,那麼基本你就需要在做代碼開發實現的時候,抽離出技術組件、功能領域和業務邏輯這樣幾個分層,不要把頻繁變化的業務邏輯寫入到各個功能領域中,應該讓功能領域更具有獨立性,可以被業務層串聯、編排、組合實現不同業務需求。這樣你的功能領域才能被逐步沉澱下來,也更易於每次需求都 擴展。
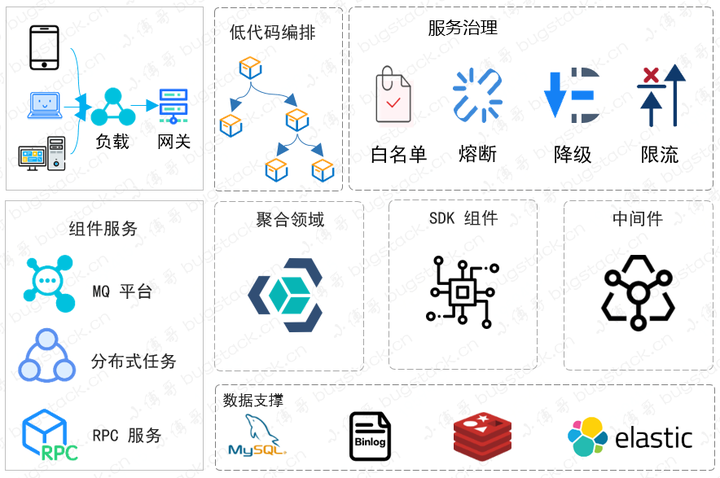
- 這是一個簡化的分層邏輯結構,有聚合的領域、SDK組件、中間件和代碼編排,並提供一些通用共性凝練出的服務治理功能。通過這樣的分層和各個層級的實現方式,就可以更加靈活的承接需求了。
9. 並發優化
在分佈式場景開發系統,要儘可能運用上分佈式的能力,從程序設計上儘可能的去避免一些集中的、分佈式事物的、數據庫加鎖的,因為這些方式的使用都可能在某些極端情況下,造成系統的負載的超標,從而引發事故。
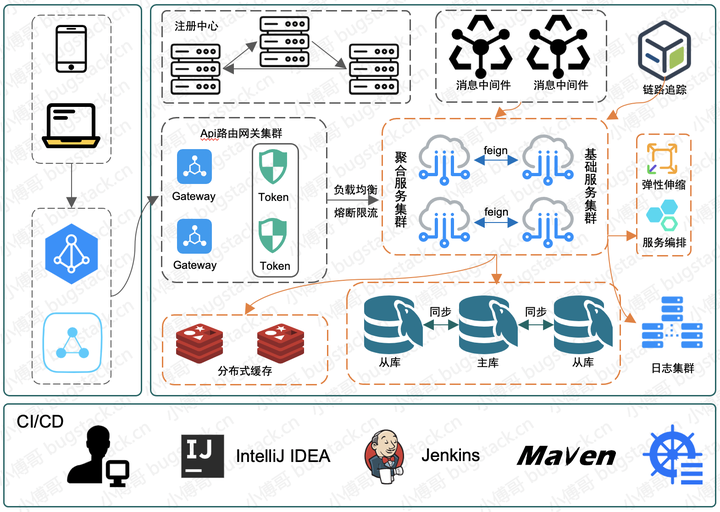
- 所以通常情況下更需要做去集中化處理,使用MQ消除峰,降低耦合,讓數據可以最終一致性,也更要考慮在 Redis 下的使用,減少對數據庫的大量鎖處理。
- 合理的運用MQ、RPC、分佈式任務、Redis、分庫分表以及分佈式事務只有這樣的操作你才可能讓自己的程序代碼可以支撐起更大的業務體量。
10. 源碼能力
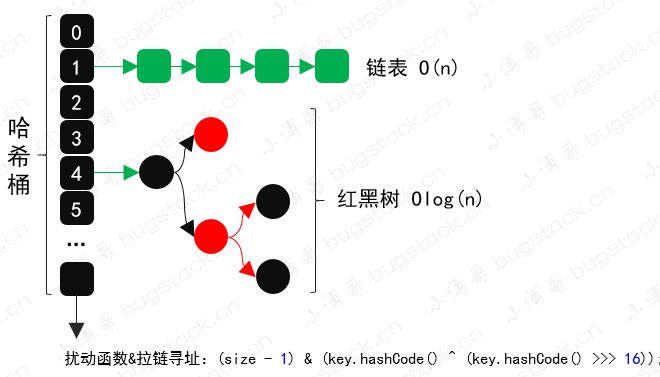
你有了解過 HashMap 的拉鏈尋址數據結構嗎、知道哈希散列和擾動函數嗎、懂得怎麼結合Spring動態切換數據源嗎、AOP 是怎麼實現以及使用的、MyBatis 是怎麼和 Spring 結合交管Bean對象的,等等。看似都是些面試的八股文,但在實際的開發中其實是可以解決很多問題的。
@Around("aopPoint() && @annotation(dbRouter)") public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable { String dbKey = dbRouter.key(); if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!"); // 計算路由 String dbKeyAttr = getAttrValue(dbKey, jp.getArgs()); int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount(); // 擾動函數 int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16)); // 庫表索引 int dbIdx = idx / dbRouterConfig.getTbCount() + 1; int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1); // 設置到 ThreadLocal DBContextHolder.setDBKey(String.format("%02d", dbIdx)); DBContextHolder.setTBKey(String.format("%02d", tbIdx)); logger.info("數據庫路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx); // 返回結果 try { return jp.proceed(); } finally { DBContextHolder.clearDBKey(); DBContextHolder.clearTBKey(); } }
- 這是 HashMap 哈希桶數組 + 鏈表 + 紅黑樹的數據結構,通過擾動函數 (size – 1) & (key.hashCode() ^ (key.hashCode() >>> 16)); 解決數據碰撞嚴重的問題。
- 但其實這樣的散列算法、尋址方式都可以運用到數據庫路由的設計實現中,還有整個數組+鏈表的方式其實庫+表的方式也有類似之處。
- 數據庫路由簡化的核心邏輯實現代碼如上,首先我們提取了庫表乘積的數量,把它當成 HashMap 一樣的長度進行使用。
- 當 idx 計算完總長度上的一個索引位置後,還需要把這個位置折算到庫表中,看看總體長度的索引因為落到哪個庫哪個表。
- 最後是把這個計算的索引信息存放到 ThreadLocal 中,用於傳遞在方法調用過程中可以提取到索引信息。
三、總結
- 講道理,你幾乎不太可能把一堆已經爛的不行的代碼,通過重構的方式把他處理乾淨。細了說,你要改變代碼結構分層、屬性對象整合、調用邏輯封裝,但任何一步的操作都可能會對原有的接口定義和調用造成風險影響,而且外部現有調用你的接口還需要隨着你的改動而升級,可能你會想着在包裝一層,但這一層包裝仍需要較大的時間成本和幾乎沒有價值的適配。
- 所以我們在實際開發中,如果能讓這些代碼具有重構的可能,幾乎就是要實時重構,每當你在添加新的功能、新的邏輯、修復異常時,就要考慮是否可以通過代碼結構、實現方式、設計模式等手段的使用,改變不合理的功能實現。每一次,一點的優化和改變,也不會有那麼難。
- 當你在接需求的時候,認真思考承接這樣的業務訴求,都需要建設怎樣的數據結構、算法邏輯、設計模式、領域聚合、服務編排、系統架構等,才能更合理的搭建出良好的具有易維護、可擴展的系統服務。如果你對這些還沒有什麼感覺,可以閱讀設計模式和手寫Spring,這些內容可以幫助你提升不少的編程邏輯設計。


