爬蟲實戰–拿下最全租房數據 | 附源碼
- 2020 年 1 月 8 日
- 筆記

點贊再看,養成好習慣Python版本3.8.0,開發工具:Pycharm
寫在前面的話
老規矩,目前為止,你應該已經了解爬蟲的三個基本小節:
不了解的自行點進去複習。
上一篇的實戰只是給大家作為一個練手,數據內容比較少,且官網也有對應的 API,難度不大。
但是「麻雀雖小,五臟俱全」,如果這一節看完感覺流程還不是很熟悉,建議去看上一節:
好了,前面的回顧就到此為止。這節開始帶大家真正搞事情。
準備工作
確定目標
今天我們的目標是某家網,官網鏈接:https://www.lianjia.com/。
當你用瀏覽器訪問這個網址的時候,可能會自動變成 https://sz.lianjia.com/ 這種。
sz 代表的是城市深圳。
(哈哈,是的,小一我現在在深圳。)
某家網上有二手房、新房、租房等等,我們今天的目標是 https://sz.lianjia.com/zufang/
「你沒看錯,zufang 是 租房 的拼音「
所以,今天我們要爬取某家網的租房數據,地點:深圳。
設定流程
因為官網的數據每天都在發生變化,你也不必說要和我截圖中的數據一模一樣。
首先,我們已經確定了目標是某家網在深圳的所有租房數據,看一下首頁

截止2019-12-31號,深圳十個區共 32708 套深圳租房,好像還挺多的,不知道我們能不能全部爬下來。
按照官網每頁30條數據來看,我們看一下翻頁的顯示:

問題來了,顯示頁碼只有100頁,是不是100頁之後被隱藏了呢?
我們試着在 url 中修改頁碼為pg101,結果發現顯示的還是第100頁的內容。
那,如何解決網頁只有前100頁數據?
設置搜索條件,確保每個搜索條件下的數據不超過3000條,這樣我們就可以通過100頁拿到所有的數據。
通過設置區域進行搜索,試試看:

羅湖區 2792條數據 < 3000。
ok,我們再看看其他區

好像不太妙,福田區整租都有4002套(已經設置了整租條件的情況下)。
沒關係,我們繼續設置搜索條件:

新增居室搜索,可以看到福田區整租的一居有1621套,滿足條件。
其他三個直接不用看了,肯定也滿足。
繼續查看剩餘的幾個區,發現也滿足,搞定
那這樣子的話,我們的步驟就是先檢查記錄數有沒有超過3000條,超過了則繼續增加新的條件,一直到不超過3000,然後分頁遍歷所有數據。
好,那我們稍微畫一下流程圖:

確定條件
大致流程基本沒什麼問題了,我們看一下具體需要注意的搜索條件。

首先是城市區域的獲取,每個城市的區域都不一樣,區域數據通過網頁獲取
其次是出租方式的獲取,官網對應兩種:整租和合租,觀察 url 發現分別對應 rt200600000001、rt200600000002
然後是房屋居室的獲取,官網對應四種:一居、二居、三居和四居,觀察 url 發現分別對應 l0、l1、l2、l3(小寫字母 L 不是1)
最後是分頁的獲取,官網 url 對應 pg+number。
拼接成 url 之後是:
base_url+/區域/+pg+出租方式+居室
細節處理
- 爬取的內容較多,每次爬取需要設置時間間隔
- 需要增加瀏覽器標識,防止被封 ip
- 需要增加檢測機制,丟掉已經爬取過的數據
- 數據需動態保存在文件中,防止被封后需要重頭再來
- 若要保存數據庫,爬蟲結束後再連接數據庫
異常處理
官網中有一種類型的房屋,網頁格式不標準,且拿不到具體數據。
對,就是公寓。
可以看到,在房屋列表中公寓無論是在價格顯示、房屋地址、朝向等都異於普通房屋。

且在詳細界面的內容也是無法拿到標準信息的

對於這種數據,我們直接丟掉就好。
開始實戰
根據流程圖,步驟已經很清楚了:
- 確定城市,獲取目標主頁網址
- 針對數據,確定目標查詢條件
- 針對總數,確定目標頁碼劃分
- 針對內容,確定目標對象字段
你準備好了嗎?
確定要獲取的數據字段:
city: 城市 house_id:房源編號 house_rental_method:房租出租方式:整租/合租/不限 house_address:房屋地址:城市/區/小區/地址 house_longitude:經度 house_latitude:緯度 house_layout:房屋格局 house_rental_area:房屋出租面積 house_orientation:房屋朝向 house_rental_price:房屋出租價格 house_update_time:房源維護時間 house_tag:房屋標籤 house_floor:房屋樓層 house_elevator:是否有電梯 house_parking:房屋車位 house_water:房屋用水 house_electricity:房屋用電 house_gas:房屋燃氣 house_heating:房屋採暖 create_time:創建時間 house_note:房屋備註 # 額外字段 house_payment_method:房屋付款方式:季付/月付 housing_lease:房屋租期
第一件事,設置城市、網址和爬蟲頭部
# 通過城市縮寫確定url city_number = 'sz' url = 'https://{0}.lianjia.com/zufang/'.format(city_number)
爬蟲頭部我們只需要設置一個 User-Agent 就行了
User-Agent 儘可能多的設置。(篇幅有限,這裡只放一部分,更多設置請在文末獲取源碼查看)
# 主起始頁 self.base_url = url # 當前篩選條件下的頁面 self.current_url = url # 設置爬蟲頭部 self.headers = { 'User-Agent': self.get_ua(), } def get_ua(self): """ 在UA庫中隨機選擇一個UA :return: 返回一個庫中的隨機UA """ ua_list = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0" ] return random.choice(ua_list)
接下來,獲取當前城市的總記錄數。
想一想,萬一有的城市出租房總記錄數都不大於3000,那我們豈不是連搜索條件都不用設置了?
每個城市的區域數據都不一樣,如果要手動輸入的話那太麻煩了。
我們直接通過網頁獲取到要查詢城市的區域數據。
def get_house_count(self): """ 獲取當前篩選條件下的房屋數據個數 @param text: @return: """ # 爬取區域起始頁面的數據 response = requests.get(url=self.current_url, headers=self.headers) # 通過 BeautifulSoup 進行頁面解析 soup = BeautifulSoup(response.text, 'html.parser') # 獲取數據總條數 count = soup.find_all(class_='content__title--hl')[0].string return soup, count
獲取到總記錄數之後,就需要拿 3000 對它衡量一下了。
超過3000,則進行二次劃分;不超過,則直接遍歷獲取數據
# 獲取當前篩選條件下數據總條數 soup, count_main = self.get_house_count() # 如果當前當前篩選條件下的數據個數大於最大可查詢個數,則設置第一次查詢條件 if int(count_main) > self.page_size*self.max_pages: # 獲取當前城市的所有區域,當做第一個查詢條件 pass else: # 直接遍歷獲取數據 pass
第二步,添加條件
首先獲取當前城市的所有區域
可以看到,深圳市的所有區域都在頁面上

多謝某家整理的整整齊齊,以後租房就去你家了
直接獲取到所有符合要求的 li 標籤,拿到區域數據
需要注意我們拿到的區域數據,我們只需要它的拼音,即 href 中後面的部分
# 拿到所有符合要求的 li 標籤 soup_uls = soup.find_all('li', class_='filter__item--level2', attrs={'data-type': 'district'}) self.area = self.get_area_list(soup_uls) def get_area_list(self, soup_uls): """ 獲取城市的所有區域信息,並保存 """ area_list = [] for soup_ul in soup_uls: # 獲取 ul 中的 a 標籤的 href 信息中的區域屬性 href = soup_ul.a.get('href') # 跳過第一條數據 if href.endswith('/zufang/'): continue else: # 獲取區域數據,保存到列表中 area_list.append(href.replace('/zufang/', '').replace('/', '')) return area_list
拿到之後,直接遍歷每個區域,將區域當做我們第一個查詢條件
在第一個查詢條件下,同樣需要獲取該條件下的總記錄數
是不是有點熟悉,又重複第一步的工作了。體會到我為什麼剛才把獲取總記錄數這個功能封裝在函數里了吧,後面也還會再用到!
# 遍歷區域,重新生成篩選條件 for area in self.area: self.get_area_page(area) def get_area_page(self, area): """ 當前搜索條件:區域 @param area: @return: """ # 重新拼接區域訪問的 url self.current_url = self.base_url + area + '/' # 獲取當前篩選條件下數據總條數 soup, count_area = self.get_house_count()
在當前條件下,同樣需要判斷是否超過 3000條。
如果超過,同樣進行條件劃分
'''如果當前當前篩選條件下的數據個數大於最大可查詢個數,則設置第二次查詢條件''' if int(count_area) > self.page_size * self.max_pages: # 遍歷出租方式,重新生成篩選條件 for rental_method in self.rental_method: pass else: # 直接遍歷獲取數據 pass
這裡我們在初始化函數中定義了出租方式和居室情況,所以不需要再從網頁上獲取,可以直接 for 循環了。
每個城市的出租方式和居室數據都是固定的,直接定義好會更方便。
# 出租方式:整租+合租 self.rental_method = ['rt200600000001', 'rt200600000002'] # 居室:一居、二居、三居、四居+ self.rooms_number = ['l0', 'l1', 'l2', 'l3']
同樣我們需要獲取出租方式條件下的總記錄數
# 重新拼接區域 + 出租方式訪問的 url self.current_url = self.base_url + area + '/' + rental_method + '/' # 獲取當前篩選條件下數據總條數 soup, count_area_rental = self.get_house_count()
同理,繼續往下添加房屋居室數量
# 重新拼接區域 + 出租方式 + 居室 訪問的 url self.current_url = self.base_url + area + '/' + rental_method + room_number + '/' # 獲取當前篩選條件下數據總條數 soup, count_area_rental_room = self.get_house_count()
第三步,確定頁數,並開始遍歷每一頁
設置相應的頁碼初始化數據,方便進行遍歷
# 起始頁碼默認為0 self.start_page = 0 # 當前條件下的總數據頁數 self.pages = 0 # 每一頁的出租房屋個數,默認page_szie=30 self.page_size = page_size # 最大頁數 self.max_pages = 100
當我們最終條件確定的記錄數不足3000時
就可以通過遍歷頁碼獲取所有數據。
# 確定頁數 # count_number是當前搜索條件下的總記錄數 self.pages = int(count_number/self.page_size) if (count_number%self.page_size) == 0 else int(count_number/self.page_size)+1 '''遍歷每一頁''' for page_index in range(1, self.pages+1): self.current_url = self.base_url + area + '/' + 'pg' + str(page_index) + rental_method + room_number + '/' # 解析當前頁的房屋信息,獲取到每一個房屋的詳細鏈接 self.get_per_house() page_index += 1
第四步,訪問每個房屋的詳細頁面
上一步已經定位到整個頁面了,我們來看看定位的頁面

這個頁面已經包含詳細頁面的跳轉 url以及當前房屋的部分主要數據。
並且這部分主要數據比詳細頁面的主要數據更好拿到,格式更規整。
好,那就選它了。
def get_per_house(self): """ 解析每一頁中的每一個房屋的詳細鏈接 @return: """ # 爬取當前頁碼的數據 response = requests.get(url=self.current_url, headers=self.headers) soup = BeautifulSoup(response.text, 'html.parser') # 定位到每一個房屋的 div (pic 標記的 div) soup_div_list = soup.find_all(class_='content__list--item--main') # 遍歷獲取每一個 div 的房屋詳情鏈接和房屋地址 for soup_div in soup_div_list: # 定位並獲取每一個房屋的詳情鏈接 detail_info = soup_div.find_all('p', class_='content__list--item--title twoline')[0].a.get('href') detail_href = 'https://sz.lianjia.com/' + detail_info # 獲取詳細鏈接的編號作為房屋唯一id house_id = detail_info.split('/')[2].replace('.html', '') '''解析部分數據''' # 獲取該頁面中房屋的地址信息和其他詳細信息 detail_text = soup_div.find_all('p', class_='content__list--item--des')[0].get_text() info_list = detail_text.replace('n', '').replace(' ', '').split('/') # 獲取房屋租金數據 price_text = soup_div.find_all('span', class_='content__list--item-price')[0].get_text()
這裏面我們需要注意開頭說到的一點:公寓
公寓的 content__list--item--des 沒有地址信息,所以我們通過長度去判斷
# 如果地址信息為空,可以確定是公寓,而我們並不能在公寓詳情界面拿到數據,所以,丟掉 if len(info_list) == 5: # 解析當前房屋的詳細數據 self.get_house_content(detail_href, house_id, info_list, price_text)
第五步,獲取每個房屋的詳細數據
上一步已經獲取部分主要數據,這一步我們取剩下的數據。
首先先來看一下詳細頁面長啥樣:

最上邊的維護時間顯示房源的更新狀態,要它!
最右邊的房屋標籤數據也有用,要它一部分!
最下邊的基本信息太有用了吧,肯定要它!
# 生成一個有序字典,保存房屋結果 house_info = OrderedDict() '''爬取頁面,獲得詳細數據''' response = requests.get(url=href, headers=self.headers, timeout=10) soup = BeautifulSoup(response.text, 'html.parser') '''解析房源維護時間''' soup_div_text = soup.find_all('div', class_='content__subtitle')[0].get_text() house_info['house_update_time'] = re.findall(r'd{4}-d{2}-d{2}', soup_div_text)[0] '''解析房屋出租方式(整租/合租/不限)''' house_info['house_rental_method'] = soup.find_all('ul', class_='content__aside__list')[0].find_all('li')[0].get_text().replace('租賃方式:', '') '''解析房屋的標籤''' house_info['house_tag'] = soup.find_all('p', class_='content__aside--tags')[0].get_text().replace('n', '/').replace(' ', '') '''房屋其他基本信息''' # 定位到當前div並獲取所有基本信息的 li 標籤 soup_li = soup.find_all('div', class_='content__article__info', attrs={'id': 'info'})[0]. find_all('ul')[0].find_all('li', class_='fl oneline') # 賦值房屋信息 house_info['house_elevator'] = soup_li[8].get_text().replace('電梯:', '') house_info['house_parking'] = soup_li[10].get_text().replace('車位:', '') house_info['house_water'] = soup_li[11].get_text().replace('用水:', '') house_info['house_electricity'] = soup_li[13].get_text().replace('用電:', '') house_info['house_gas'] = soup_li[14].get_text().replace('燃氣:', '') house_info['house_heating'] = soup_li[16].get_text().replace('採暖:', '') house_info['create_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') house_info['city'] = self.city # 保存當前影片信息 self.data_info.append(house_info)
應該該拿的數據都拿到了。
不對,好像還有經緯度沒有拿到。
檢查一下,在 js 代碼中發現了一個坐標

看着很可疑,我們通過坐標反查看一看到底是不是這個房屋地址
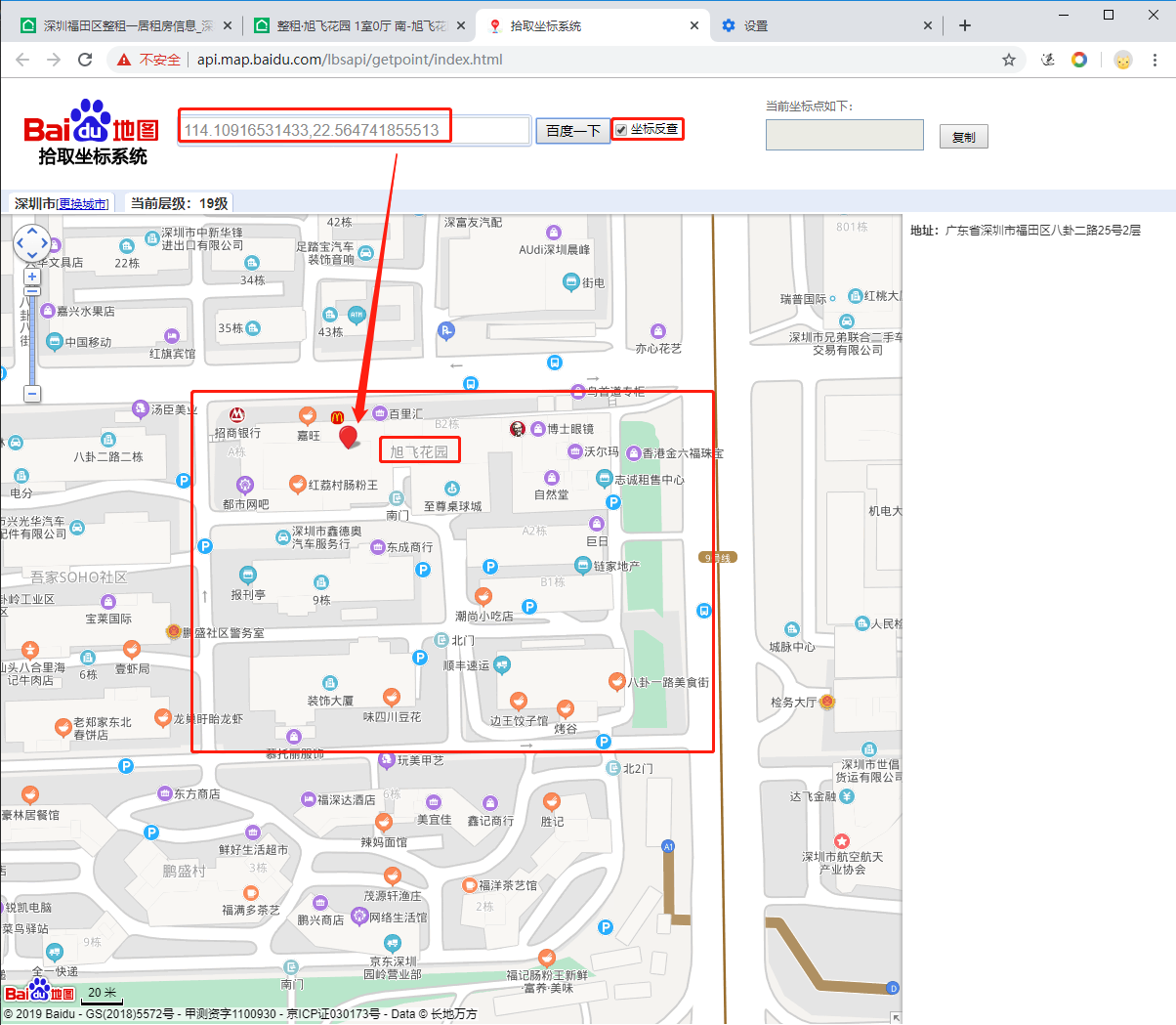
ok,沒問題,正是我們要的,那把它也拿下吧!
'''解析經緯度數據''' # 獲取到經緯度的 script定義數據 location_str = response.text[re.search(r'(g_conf.coord)+', response.text).span()[0]: re.search(r'(g_conf.subway)+', response.text).span()[0]] # 字符串清洗,並在鍵上添加引號,方便轉化成字典 location_str=location_str.replace('n','').replace('','').replace("longitude","'longitude'").replace("latitude", "'latitude'") # 獲取完整經緯度數據,轉換成字典,並保存 location_dict = eval(location_str[location_str.index('{'): location_str.index('}')+1]) house_info['house_longitude'] = location_dict['longitude'] house_info['house_latitude'] = location_dict['latitude']
第六步,保存數據
每 50 條數據追加保存到本地文件中當所有記錄都爬完之後,將本地文件保存到數據庫中。
數據需要保存到本地文件和數據庫中。
其中本地文件每爬取50條追加保存記錄,數據庫只需要爬取結束後保存一次。
def data_to_sql(self): """ 保存/追加數據到數據庫中 @return: """ # 連接數據庫 self.pymysql_engine, self.pymysql_session = connection_to_mysql() # 讀取數據並保存到數據庫中 df_data = pd.read_csv(self.save_file_path, encoding='utf-8') # 導入數據到 mysql 中 df_data.to_sql('t_lianjia_rent_info', self.pymysql_engine, index=False, if_exists='append') def data_to_csv(self): """ 保存/追加數據到本地 @return: """ # 獲取數據並保存成 DataFrame df_data = pd.DataFrame(self.data_info) if os.path.exists(self.save_file_path) and os.path.getsize(self.save_file_path): # 追加寫入文件 df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', header=False, index=False) else: # 寫入文件,帶表頭 df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', index=False) # 清空當前數據集 self.data_info = []
到此我們的流程就已經結束了。
小一我最終花了一天多的時間,爬取到了27000+數據。(公寓數據在爬取過程中已經丟掉了)
自行設置每次的休眠間隔,上面流程中我並沒有貼出來,需要的在源代碼中查看。
貼一下最終數據截圖:

總結一下
主要流程
- 確定目標:爬取的網站網址以及要爬取的數據
- 設定流程:詳細說明了我們每一步如何進行,以及整體的流程圖
- 確定條件:在搜索過程中確定每個層級的搜索條件
- 細節處理:爬取數據較多,增加必要的細節處理,提高代碼健壯性
- 異常處理:異常房屋類型的處理,在這裡我們直接丟掉。
日常思考:
比起第一個項目,這個項目流程會複雜一些,但是本質上沒有區別。
可以看到爬蟲的核心代碼其實就是那幾句。
思考以下幾點:
- 如果本次的網站需要登錄,應該怎麼辦?
- 如果你要租房,你應該怎麼分析?
必要提醒
- 上述方法僅針對當前的官網源代碼
- 本次爬蟲內容僅用作交流學習
源碼獲取
在公眾號後台回復 某家租房 獲取 爬取某家網租房信息源碼
本次爬蟲的結果數據不對外公開,有需要的交流學習的可以加群獲取。(後台回復加群)
寫在後面的話
發現最近幾篇文章都是5000字的長文,是我太啰嗦了嗎(真的懷疑自己了)?
能堅持讀到這的晚上記得給自己加個雞腿,你已經很棒了。
我、我、我也想要加個雞腿
呸呸呸,說好的不拿人民群眾一針一線。
那,點個在看總行吧?
原創不易,歡迎點贊噢
文章首發:公眾號【知秋小夢】 文章同步:掘金,簡書,csdn
