看動畫學算法之:hashtable
簡介
java中和hash相關並且常用的有兩個類hashTable和hashMap,兩個類的底層存儲都是數組,這個數組不是普通的數組,而是被稱為散列表的東西。
散列表是一種將鍵映射到值的數據結構。它用哈希函數來將鍵映射到小範圍的指數(一般為[0..哈希表大小-1])。同時需要提供衝突和對衝突的解決方案。
今天我們來學習一下散列表的特性和作用。
文末有代碼地址,歡迎下載。
散列表的關鍵概念
散列表中比較關鍵的三個概念就是散列表,hash函數,和衝突解決。
散列是一種算法(通過散列函數),將大型可變長度數據集映射為固定長度的較小整數數據集。
散列表是一種數據結構,它使用哈希函數有效地將鍵映射到值,以便進行高效的搜索/檢索,插入和/或刪除。
散列表廣泛應用於多種計算機軟件中,特別是關聯數組,數據庫索引,緩存和集合。
散列表必須至少支持以下三種操作,並且儘可能高效:
搜索(v) – 確定v是否存在於散列表中,
插入(v) – 將v插入散列表,
刪除(v) – 從散列表中刪除v。
因為使用了散列算法,將長數據集映射成了短數據集,所以在插入的時候就可能產生衝突,根據衝突的解決辦法的不同又可以分為線性探測,二次探測,雙倍散列和分離鏈接等衝突解決方法。
數組和散列表
考慮這樣一個問題:找到給定的字符串中第一次重複出現的的字符。
怎麼解決這個問題呢?最簡單的辦法就是進行n次遍歷,第一次遍歷找出字符串中是否有和第一個字符相等的字符,第二次遍歷找出字符串中是否有和第二個字符相等的字符,以此類推。
因為進行了n*n的遍歷,所以時間複雜度是O(n²)。
有沒有簡單點的辦法呢?
考慮一下字符串中的字符集合其實是有限的,假如都是使用的ASCII字符,那麼我們可以構建一個256長度的數組一次遍歷即可。
具體的做法就是遍歷一個字符就將相對於的數組中的相應index中的值+1,當我們發現某個index的值已經是1的時候,就知道這個字符重複了。
數組的問題
那麼數組的實現有什麼問題呢?
數組的問題所在:
鍵的範圍必須很小。 如果我們有(非常)大範圍的話,內存使用量會(非常的)很大。
鍵必須密集,即鍵值中沒有太多空白。 否則數組中將包含太多的空單元。
我們可以使用散列函數來解決這個問題。
通過使用散列函數,我們可以:
將一些非整數鍵映射成整數鍵,
將大整數映射成較小的整數。
通過使用散列函數,我們可以有效的減少存儲數組的大小。
hash的問題
有利就有弊,雖然使用散列函數可以將大數據集映射成為小數據集,但是散列函數可能且很可能將不同的鍵映射到同一個整數槽中,即多對一映射而不是一對一映射。
尤其是在散列表的密度非常高的情況下,這種衝突會經常發生。
這裡介紹一個概念:影響哈希表的密度或負載因子α= N / M,其中N是鍵的數量,M是哈希表的大小。
其實這個衝突的概率要比我們想像的更大,舉一個生日悖論的問題:
一個班級裏面有多少個學生會使至少有兩人生日相同的概率大於 50%?
我們來計算一下上面的問題。
假設Q(n)是班級中n個人生日不同的概率。
Q(n)= 365/365×364/365×363/365×…×(365-n + 1)/ 365,即第一人的生日可以是365天中的任何一天,第二人的生日可以是除第一人的生日之外的任何365天,等等。
設P(n)為班級中 n 個人的相同生日的概率,則P(n)= 1-Q(n)。
計算可得,當n=23的時候P(23) = 0.507> 0.5(50%)。
也就是說當班級擁有23個人的時候,班級至少有兩個人的生日相同的概率已經超過了50%。 這個悖論告訴我們:個人覺得罕見的事情在集體中卻是常見的。
好了,回到我們的hash衝突,我們需要構建一個好的hash函數來盡量減少數據的衝突。
什麼是一個好的散列函數呢?
能夠快速計算,即其時間複雜度是O(1)。
儘可能使用最小容量的散列表,
儘可能均勻地將鍵分散到不同的基地址∈[0..M-1],
儘可能減少碰撞。
在討論散列函數的實現之前,讓我們討論理想的情況:完美的散列函數。
完美的散列函數是鍵和散列值之間的一對一映射,即根本不存在衝突。 當然這種情況是非常少見的,如果我們事先知道了散列函數中要存儲的key,還是可以辦到的。
好了,接下來我們討論一下hash中解決衝突的幾種常見的方法。
線性探測
先給出線性探測的公式:i描述為i =(base + step * 1)%M,其中base是鍵v的散列值,即h(v),step是從1開始的線性探測步驟。
線性探測的探測序列可以正式描述如下:
h(v)//基地址
(h(v)+ 1 * 1)%M //第一個探測步驟,如果發生碰撞
(h(v)+ 2 * 1)%M //第二次探測步驟,如果仍有碰撞
(h(v)+ 3 * 1)%M //第三次探測步驟,如果仍有衝突
…
(h(v)+ k * 1)%M //第k個探測步驟等…
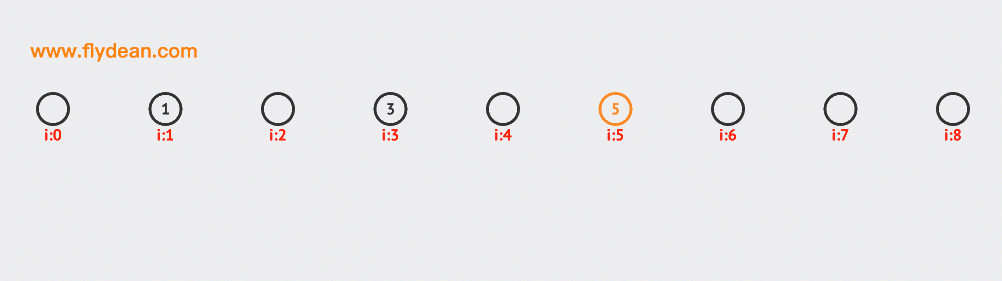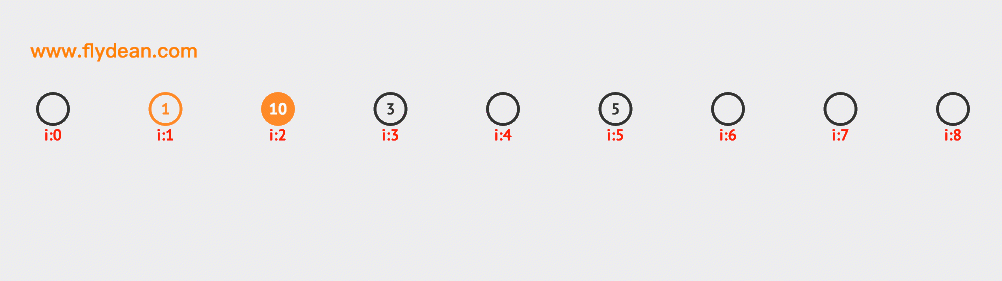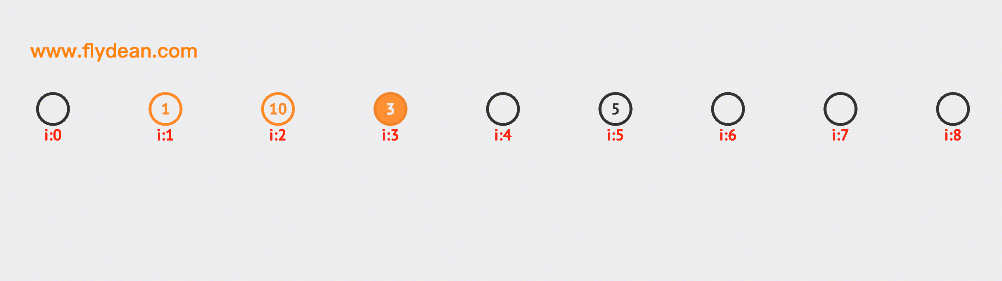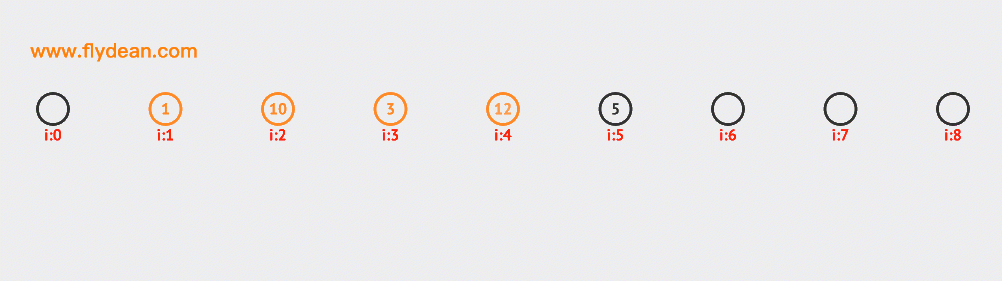
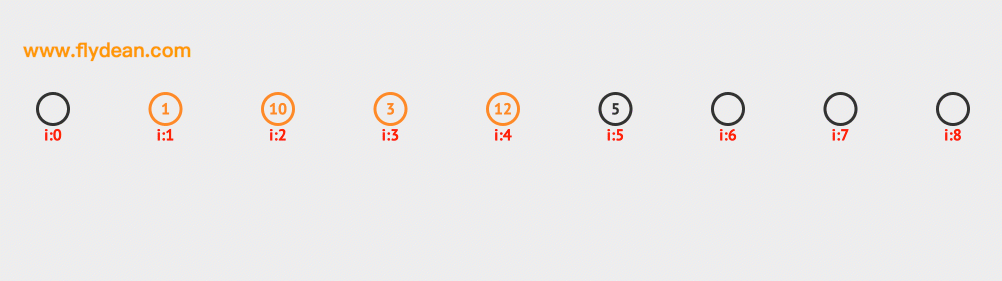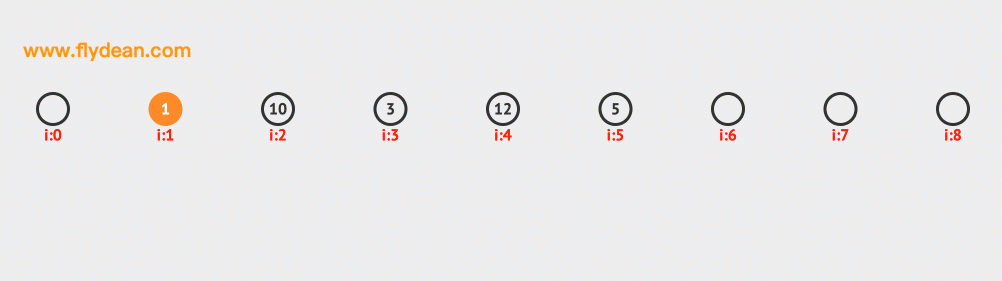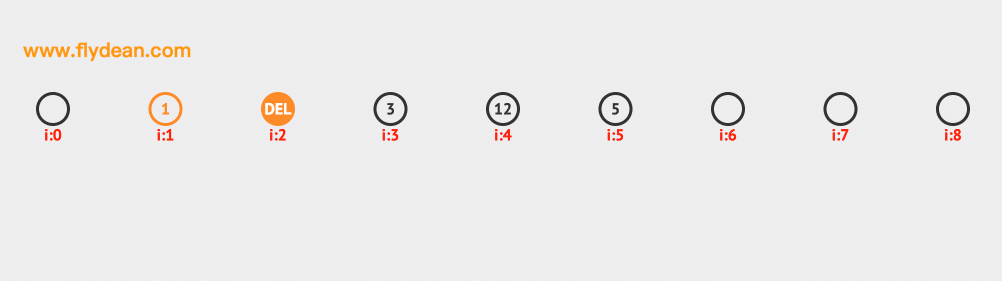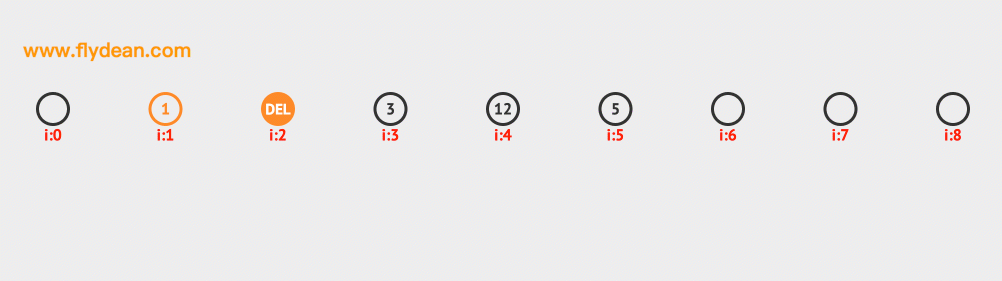
先看個例子,上面的數組中,我們的基數是9,數組中已經有1,3,5這三個元素。
現在我們需要插入10和12,根據計算10和12的hash值是1和3,但是1和3現在已經有數據了,那麼需要線性向前探測一位,最終插入在1和3的後面。
上面是刪除10的例子,同樣的先計算10的hash值=1,然後判斷1的位置元素是不是10,不是10的話,向前線性探測。
看下線性探測的關鍵代碼:
//插入節點
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//獲取key的hashcode
int hashIndex = hashCode(key);
//find next free space
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex++;
hashIndex %= capacity;
}
//插入新節點,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//將新節點插入數組
hashNodes[hashIndex] = temp;
}
如果我們把具有相同h(v)地址的連續存儲空間叫做clusters的話,線性探測有很大的可能會創建大型主clusters,這會增加搜索(v)/插入(v)/刪除(v)操作的運行時間。
為了解決這個問題,我們引入了二次探測。
二次探測
先給出二次探測的公式:i描述為i =(base + step * step)%M,其中base是鍵v的散列值,即h(v),step是從1開始的線性探測步驟。
h(v)//基地址
(h(v)+ 1 * 1)%M //第一個探測步驟,如果發生碰撞
(h(v)+ 2 * 2)%M //第2次探測步驟,如果仍有衝突
(h(v)+ 3 * 3)%M //第三次探測步驟,如果仍有衝突
…
(h(v)+ k * k)%M //第k個探測步驟等…
就是這樣,探針按照二次方跳轉,根據需要環繞哈希表。
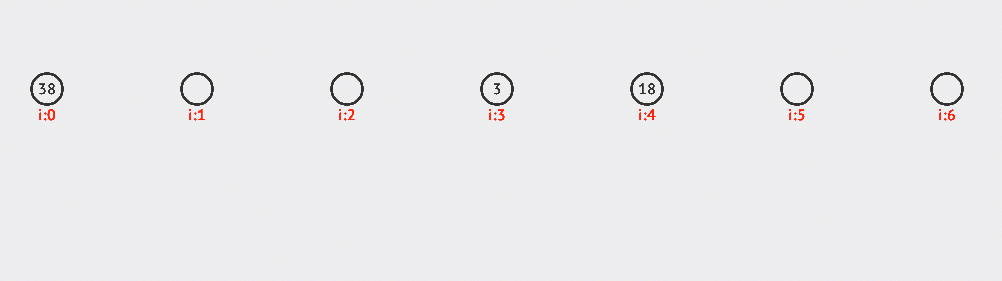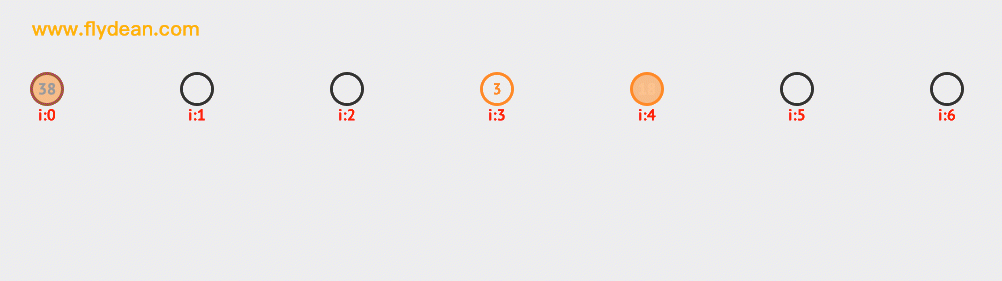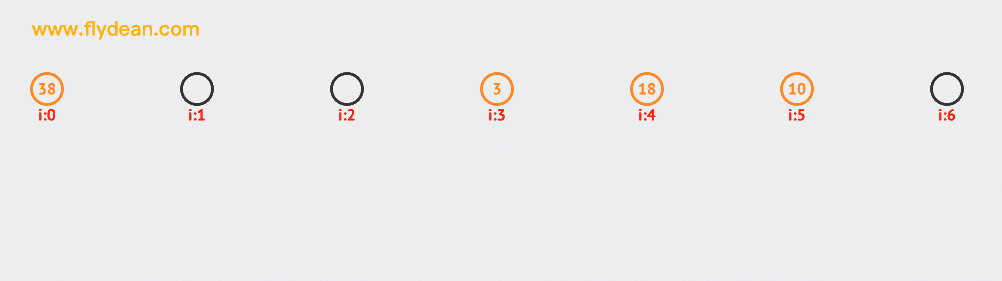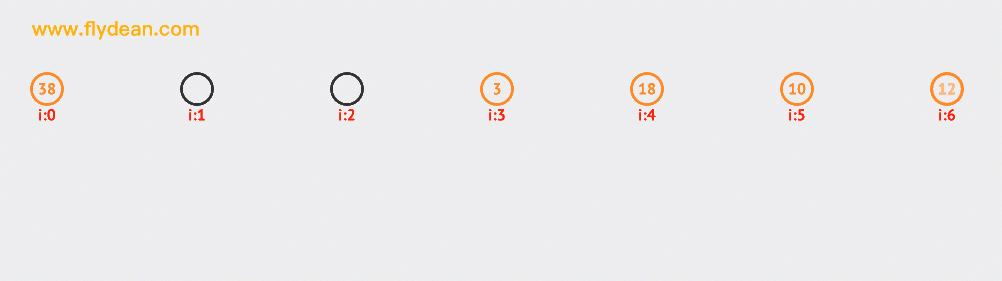
看一個二次探測的例子,上面的例子中我們已經有38,3和18這三個元素了。現在要向裏面插入10和12。大家可以自行研究下探測的路徑。
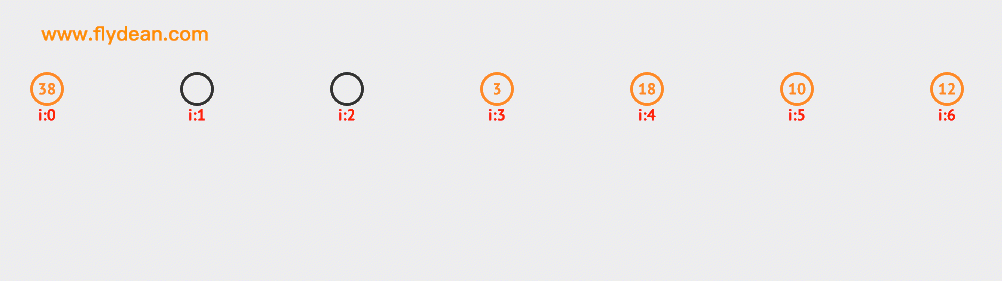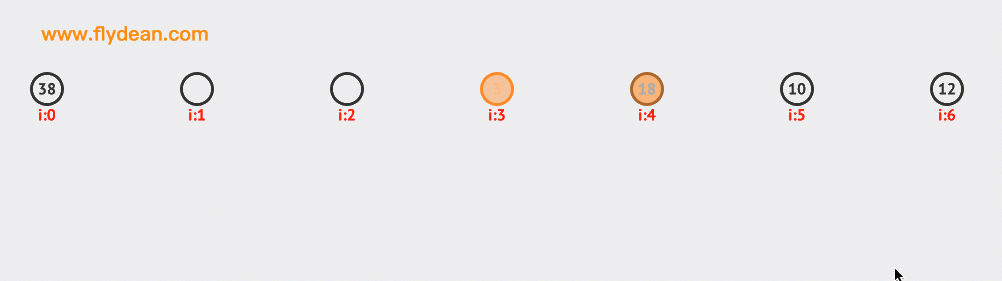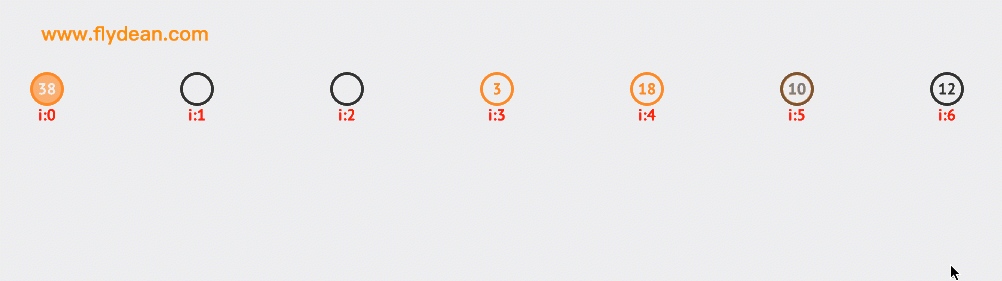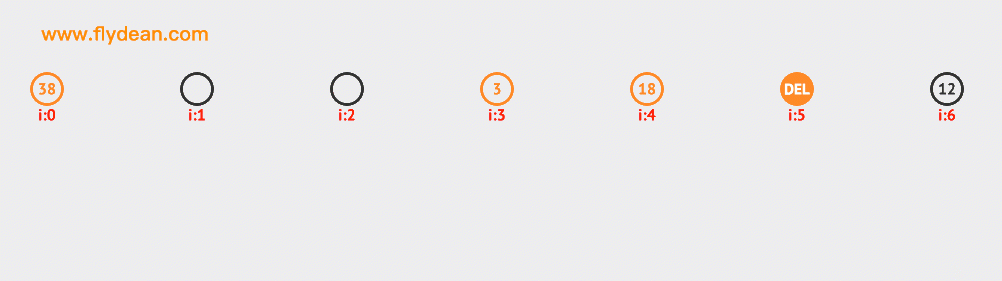
再看一個二次探索刪除節點的例子。
看下二次探測的關鍵代碼:
//插入節點
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//獲取key的hashcode
int hashIndex = hashCode(key);
//find next free space
int i=1;
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex=hashIndex+i*i;
hashIndex %= capacity;
i++;
}
//插入新節點,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//將新節點插入數組
hashNodes[hashIndex] = temp;
}
在二次探測中,群集(clusters)沿着探測路徑形成,而不是像線性探測那樣圍繞基地址形成。 這些群集稱為次級群集(Secondary Clusters)。
由於在所有密鑰的探測中使用相同的模式,所以形成次級群集。
二次探測中的次級群集不如線性探測中的主群集那樣糟糕,因為理論上散列函數理論上應該首先將鍵分散到不同的基地址∈[0..M-1]中。
為了減少主要和次要clusters,我們引入了雙倍散列。
雙倍散列
先給出雙倍散列的公式:i描述為i =(base + step * h2(v))%M,其中base是鍵v的散列值,即h(v),step是從1開始的線性探測步驟。
h(v)//基地址
(h(v)+ 1 * h2(v))%M //第一個探測步驟,如果有碰撞
(h(v)+ 2 * h2(v))%M //第2次探測步驟,如果仍有衝突
(h(v)+ 3 * h2(v))%M //第三次探測步驟,如果仍有衝突
…
(h(v)+ k * h2(v))%M //第k個探測步驟等…
就是這樣,探測器根據第二個散列函數h2(v)的值跳轉,根據需要環繞散列表。
看下雙倍散列的關鍵代碼:
//插入節點
void insertNode(int key, int value)
{
HashNode temp = new HashNode(key, value);
//獲取key的hashcode
int hashIndex = hash1(key);
//find next free space
int i=1;
while(hashNodes[hashIndex] != null && hashNodes[hashIndex].key != key
&& hashNodes[hashIndex].key != -1)
{
hashIndex=hashIndex+i*hash2(key);
hashIndex %= capacity;
i++;
}
//插入新節點,size+1
if(hashNodes[hashIndex] == null || hashNodes[hashIndex].key == -1) {
size++;
}
//將新節點插入數組
hashNodes[hashIndex] = temp;
}
如果h2(v)= 1,則雙散列(Double Hashing)的工作方式與線性探測(Linear Probing)完全相同。 所以我們通常希望h2(v)> 1來避免主聚類。
如果h2(v)= 0,那麼Double Hashing將會不起作用。
通常對於整數鍵,h2(v)= M’ – v%M’其中M’是一個小於M的質數。這使得h2(v)∈[1..M’]。
二次散列函數的使用使得理論上難以產生主要或次要群集問題。
分離鏈接
分離鏈接法(SC)衝突解決技術很簡單。如果兩個鍵 a 和 b 都具有相同的散列值 i,那麼這兩個鍵會以鏈表的形式附加在要插入的位置。
因為鍵(keys)將被插入的地方完全依賴於散列函數本身,因此我們也稱分離鏈接法為封閉尋址衝突解決技術。
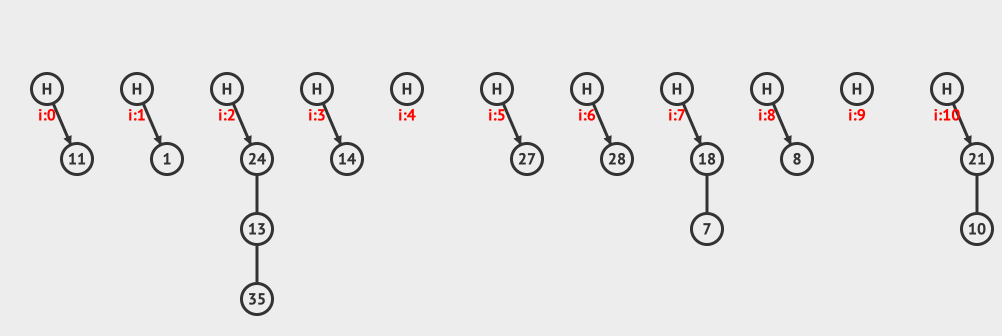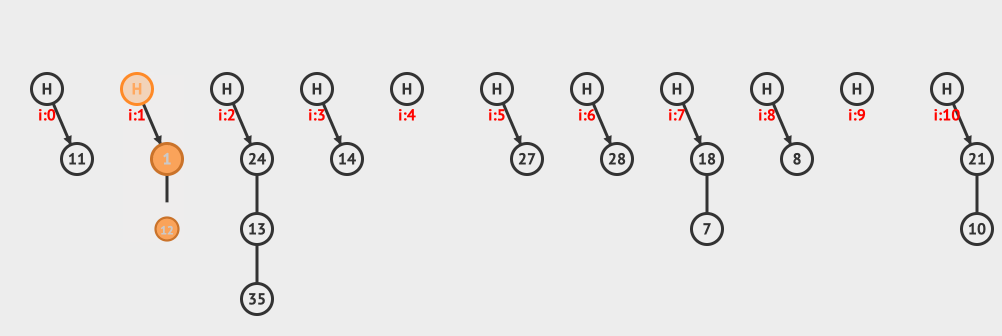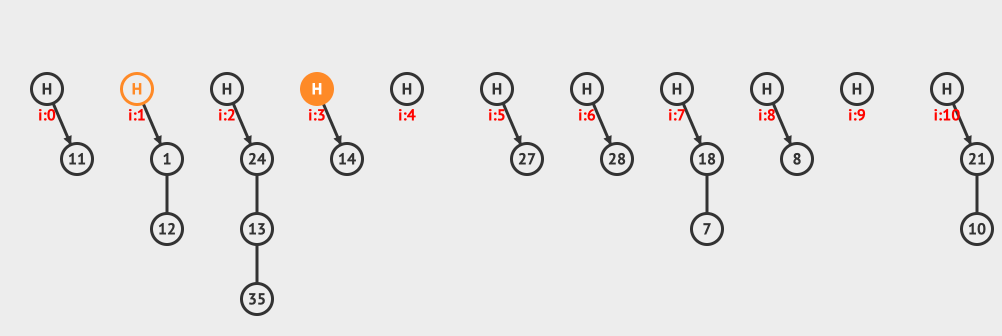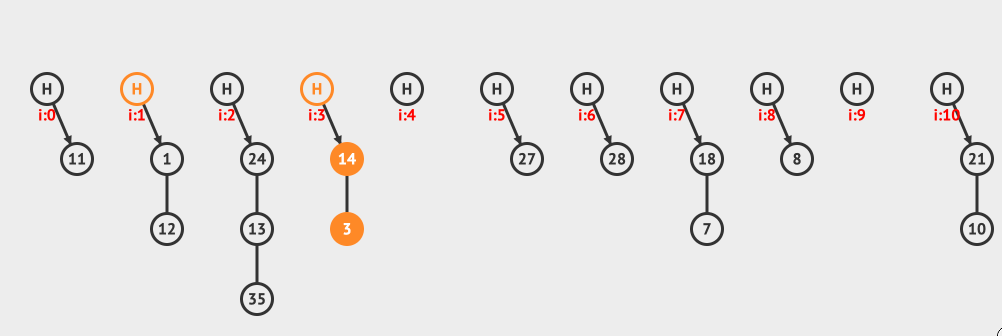
上面是分離鏈接插入的例子,向現有的hashMap中插入12和3這兩個元素。
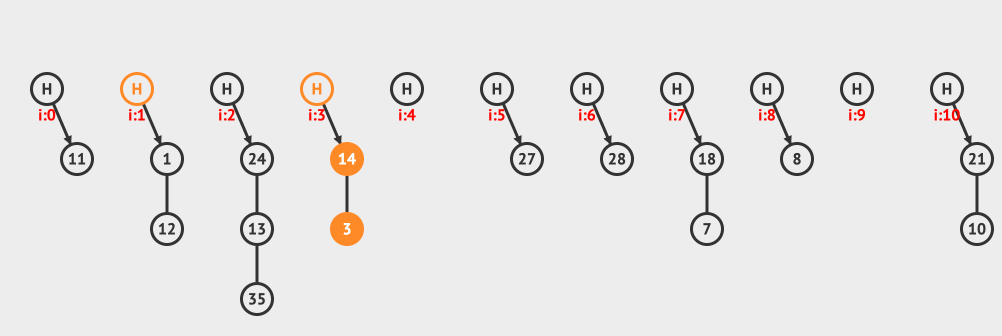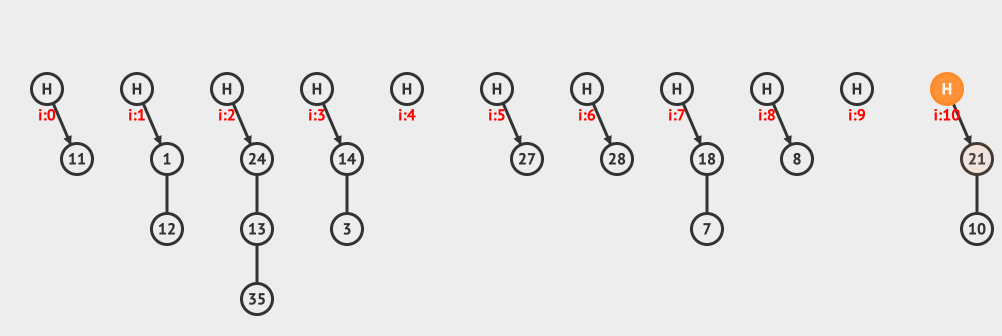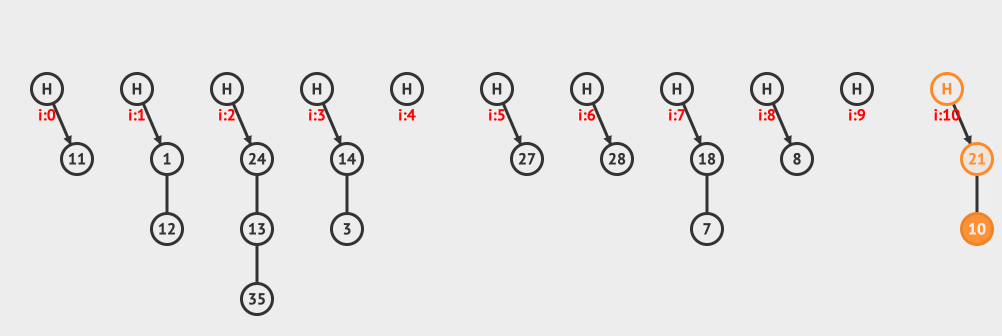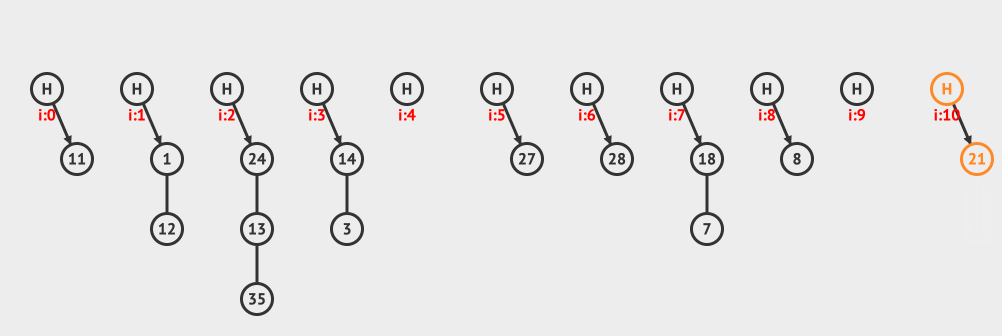
上面是分離鏈接刪除的例子,從鏈接中刪除10這個元素。
看下分離鏈接的關鍵代碼:
//添加元素
public void add(int key,int value)
{
int index=hashCode(key);
HashNode head=hashNodes[index];
HashNode toAdd=new HashNode(key,value);
if(head==null)
{
hashNodes[index]= toAdd;
size++;
}
else
{
while(head!=null)
{
if(head.key == key )
{
head.value=value;
size++;
break;
}
head=head.next;
}
if(head==null)
{
head=hashNodes[index];
toAdd.next=head;
hashNodes[index]= toAdd;
size++;
}
}
//動態擴容
if((1.0*size)/capacity>0.7)
{
HashNode[] tmp=hashNodes;
hashNodes=new HashNode[capacity*2];
capacity=2*capacity;
for(HashNode headNode:tmp)
{
while(headNode!=null)
{
add(headNode.key, headNode.value);
headNode=headNode.next;
}
}
}
rehash
當負載因子α變高時,哈希表的性能會降低。 對於(標準)二次探測衝突解決方法,當哈希表的α> 0.5時,插入可能失敗。
如果發生這種情況,我們可以重新散列(rehash)。 我們用一個新的散列函數構建另一個大約兩倍的散列表。 我們遍歷原始哈希表中的所有鍵,重新計算新的哈希值,然後將鍵值重新插入新的更大的哈希表中,最後刪除較早的較小哈希表。
本文的代碼地址:
本文已收錄於 //www.flydean.com/14-algorithm-hashtable/
最通俗的解讀,最深刻的乾貨,最簡潔的教程,眾多你不知道的小技巧等你來發現!
歡迎關注我的公眾號:「程序那些事」,懂技術,更懂你!


