使用pmml實現跨平台部署機器學習模型
一、概述
對於由Python訓練的機器學習模型,通常有pickle和pmml兩種部署方式,pickle方式用於在python環境中的部署,pmml方式用於跨平台(如Java環境)的部署,本文敘述的是pmml的跨平台部署方式。
PMML(Predictive Model Markup Language,預測模型標記語言)是一種基於XML描述來存儲機器學習模型的標準語言。如,對在Python環境中由sklearn訓練得到的模型,通過sklearn2pmml模塊可將它完整地保存為一個pmml格式的文件,再在其他平台(如java)中加載該文件進行使用,從而實現模型的跨平台部署。
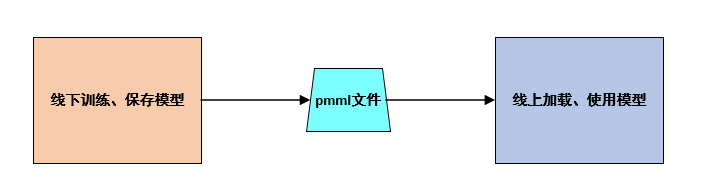
二、實現步驟
1.訓練環境中安裝生成pmml文件的工具。
如在Python環境中安裝sklearn2pmml模塊(pip install sklearn2pmml)。
2.訓練模型。
3.將模型保存為pmml文件。
4.部署環境中導入依賴的工具包。
如在Java環境中導入pmml-evaluator、pmml-evaluator-extension(特殊情況下另加)、jaxb-core、jaxb-api、jaxb-impl等jar包。
5.開發應用,加載、使用模型。
注:對sklearn2pmml生成的pmml模型文件,在java中加載使用時,需將文件中的命名空間屬性xmlns=”…/PMML-4_4″改為xmlns=”…/PMML-4_3″,以適應低版本的jar包對它的解析。
三、示例
在python中使用sklearn訓練一個線性回歸模型,並在java環境中部署使用。
工具:PyCharm-2017、Python-39、sklearn2pmml-0.76.1;IntelliJ IDEA-2018、jdk-14.0.2。
1.訓練數據集training_data.csv
2.訓練、保存模型
import sklearn2pmml as pmml
from sklearn2pmml import PMMLPipeline
from sklearn import linear_model as lm
import os
import pandas as pd
def save_model(data, model_path):
pipeline = PMMLPipeline([("regression", lm.LinearRegression())]) #定義模型,放入pipeline管道
pipeline.fit(data[["x"]], data["y"]) #訓練模型,由數據中第一行的名稱確定自變量和因變量
pmml.sklearn2pmml(pipeline, model_path, with_repr=True) #保存模型
if __name__ == "__main__":
data = pd.read_csv("training_data.csv")
model_path = model_path = os.path.dirname(os.path.abspath(__file__)) + "/my_example_model.pmml"
save_model(data, model_path)
print("模型保存完成。")
3.將pmml文件的xmlns屬性修改為PMML-4_3

4.java程序中加載、使用模型
(1)創建maven項目,將pmml模型文件拷貝至項目根目錄下。
(2)加入依賴包
<dependencies>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.15</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.1</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>
</dependencies>
(3)java程序加載模型完成預測
public class MLPmmlDeploy {
public static void main(String[] args) {
String model_path = "./my_example_model.pmml"; //模型路徑
int x = 20; //測試的自變量值
Evaluator model = loadModel(model_path); //加載模型
Object r = predict(model, x); //預測
Double result = Double.parseDouble(r.toString());
System.out.println("預測的結果為:" + result);
}
private static Evaluator loadModel(String model_path){
PMML pmml = new PMML(); //定義PMML對象
InputStream inputStream; //定義輸入流
try {
inputStream = new FileInputStream(model_path); //輸入流接到磁盤上的模型文件
pmml = PMMLUtil.unmarshal(inputStream); //將輸入流解析為PMML對象
}catch (Exception e){
e.printStackTrace();
}
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance(); //實例化一個模型構造工廠
Evaluator evaluator = modelEvaluatorFactory.newModelEvaluator(pmml); //將PMML對象構造為Evaluator模型對象
return evaluator;
}
private static Object predict(Evaluator evaluator, int x){
Map<String, Integer> data = new HashMap<String, Integer>(); //定義測試數據Map,存入各元自變量
data.put("x", x); //鍵"x"為自變量的名稱,應與訓練數據中的自變量名稱一致
List<InputField> inputFieldList = evaluator.getInputFields(); //得到模型各元自變量的屬性列表
Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>();
for (InputField inputField : inputFieldList) { //遍歷各元自變量的屬性列表
FieldName inputFieldName = inputField.getName();
Object rawValue = data.get(inputFieldName.getValue()); //取出該元變量的值
FieldValue inputFieldValue = inputField.prepare(rawValue); //將值加入該元自變量屬性中
arguments.put(inputFieldName, inputFieldValue); //變量名和變量值的對加入LinkedHashMap
}
Map<FieldName, ?> results = evaluator.evaluate(arguments); //進行預測
List<TargetField> targetFieldList = evaluator.getTargetFields(); //得到模型各元因變量的屬性列表
FieldName targetFieldName = targetFieldList.get(0).getName(); //第一元因變量名稱
Object targetFieldValue = results.get(targetFieldName); //由因變量名稱得到值
return targetFieldValue;
}
}

示例下載:
//download.csdn.net/download/Albert201605/45645889
End.
參考
- //www.freesion.com/article/4628411548/
- //www.cnblogs.com/pinard/p/9220199.html
- //www.cnblogs.com/moonlightpoet/p/5533313.html


