四種 AI 技術方案,教你擁有自己的 Avatar 形象
大火的 Avatar到底是什麼 ?
隨着元宇宙概念的大火,Avatar 這個詞也開始越來越多出現在人們的視野。2009 年,一部由詹姆斯・卡梅隆執導 3D 科幻大片《阿凡達》讓很多人認識了 Avatar 這個英語單詞。不過,很多人並不知道這個單詞並非導演杜撰的,而是來自梵文,是印度教中的一個重要術語。根據劍橋英語詞典解釋,Avatar 目前主要包含三種含義。
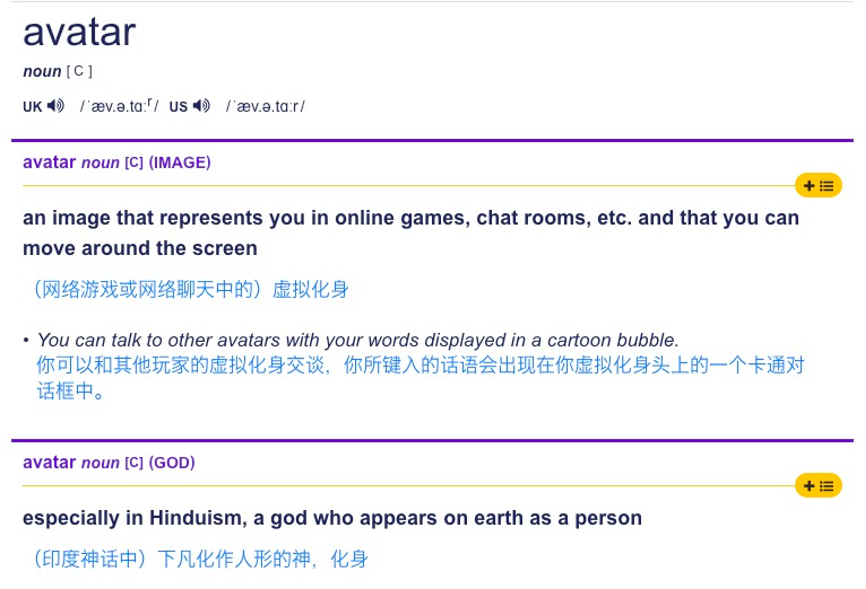
avatar 在劍橋詞典的翻譯結果 © Cambridge University Press
最初,Avatar 起源於梵文 avatarana ,由 ava ( off , down )+ tarati ( cross over )構成,字面意思是 「下凡」,指的是神靈降臨人間的化身,通常特指主神毗濕奴 ( VISHNU ) 下凡化作人形或者獸形的狀態。後於1784年進入英語詞語中。
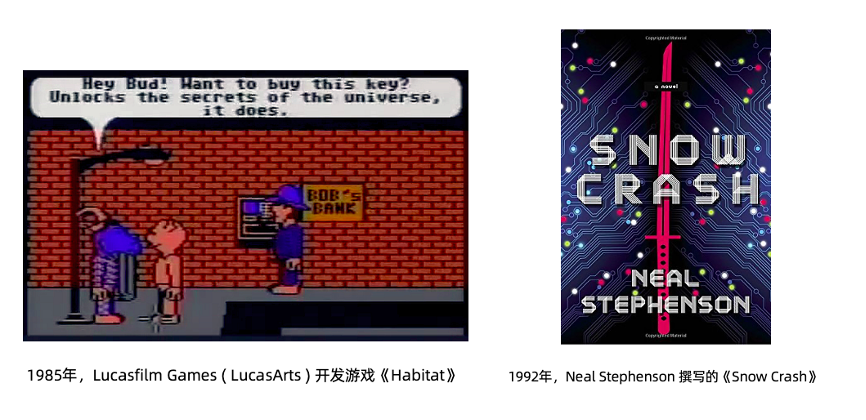
1985 年切普・莫寧斯塔和約瑟夫・羅梅羅在為盧卡斯影視公司Lucasfilm Games ( LucasArts ) 設計網絡角色扮演遊戲Habitat時使用了 Avatar 這個詞來指代用戶網絡形象。而後在1992 年,科幻小說家 Neal Stephenson 撰寫的《Snow Crash》一書中描述了一個平行於現實世界的元宇宙。所有的現實世界中的人在元宇宙中都有一個網絡分身 Avatar,這一次也是該詞首次出現在大眾媒體。
互聯網時代,Avatar 一詞開始被程序員們廣泛使用在軟件系統中,用於代表用戶個人或其性格的一個圖像,即我們常說的 「頭像」 或 「個人秀」。這個頭像可以是網絡遊戲或者虛擬世界裏三維立體的圖像,也可以是網絡論壇或社區里常用的二維平面圖像。它是可以代表用戶本人的一個標誌物。
從QQ秀到Avatar
如今支持讓用戶創建屬於自己的頭像已經成為了各種軟件應用的標配,用戶使用的頭像也隨着技術發展從普通 2D形象發展到了3D形象。里程碑事件當屬2017 年,蘋果在 iPhone X 發佈了新功能 ——Animoji,使用面部識別傳感器來檢測用戶面部表情變化,同時用麥克風記錄用戶的聲音,並最終生成可愛的 3D 動畫表情符號,用戶可以通過 iMessage 與朋友分享表情符號。但是第一代不支持用戶自定義形象,僅支持系統內置的動物卡通頭像。隨後更新的 Animoji 二代開始支持用戶自由化捏臉,生成風格化的人臉頭像。當前不少場景中可以看到自動化捏臉功能,僅通過拍攝一張或幾張照片,自動生成符合用戶人臉特點的CG模型,但背後依賴於複雜的CG建模及渲染技術支持。
Avatar也可以跳過昂貴的CG建模及渲染流程,通過機器學習算法將拍攝人臉進行「風格化」。即自動化將目標訓練風格遷移、與拍攝者本來的面目特徵做融合,創建符合用戶臉部特徵的風格化人臉 Avatar。
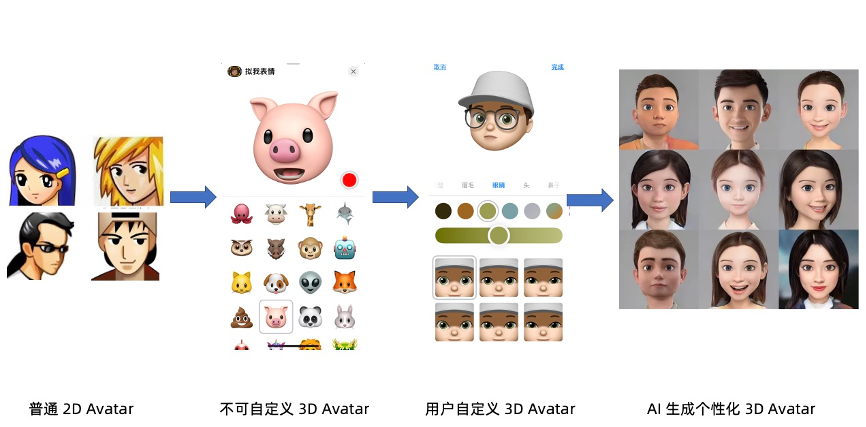
人臉風格化 Avatar 的四種技術實現路線
什麼是人臉風格化?
所謂人臉風格化,就是將真實的人臉頭像轉換為特定的風格頭像,例如卡通風格、動漫風格、油畫風格,如下圖所示:

基本上說,實現人臉風格化可通過紋理貼圖、風格遷移、循環對抗網絡和隱變量映射等幾種技術路線實現。
紋理貼圖
紋理貼圖一般是給定一張樣本圖片,通過算法自動將該圖片的紋理逐像素或逐塊貼到目標人臉上,形成一種合理自然、可隨動的人臉面具 [1]。

[1] 中樣例圖片
風格遷移
風格遷移是給定一張或一組風格照片,基於學習方法從風格圖片中提取出風格編碼、從目標人臉圖片中提出內容編碼,通過兩組編碼自動化生成對應的風格化圖片 [2, 3]。只更改了人臉圖片的表面紋理,而無法合理地保留或調整人臉的結構屬性、形成有意義的結構性風格改變。

[3] 中樣例圖片
循環對抗網絡
採用循環對抗網絡的方法,通過利用循環對抗網絡及其重建約束來訓練得到可實現沒有成對訓練樣本的風格化效果。往往配合使用風格遷移,即分別提取風格編碼和內容編碼。針對人臉的風格化也會顯示建模並根據目標風格屬性對人臉結構信息做形變(如基於人臉關鍵點)。但由於循環對抗網絡缺少對中間結果約束(如A->B->A中的B)導致最終生成效果不可控、不穩定(即無法保證A->B的合理性)[4]。

[4] 中樣例圖片
隱變量映射
隱變量映射一般將一個預先訓練好的真實人臉生成模型、利用一組風格圖片往目標風格微調,從而獲得一個對應的人臉風格化生成模型 [5, 6]。採用一個編碼網絡將輸入人臉圖片映射成或基於多步的優化得到該圖片對應的隱變量,並將該變量作為人臉風格化生成模型的輸入,從而得到該人臉圖片對應的風格化圖片。其中基於優化的隱變量映射方法往往得到比較好的效果,但在實際運行時需要大量計算。映射後的隱變量雖然包含了人臉的全局信息,但容易丟失原輸入人臉的細節特徵,容易造成生成的效果無法反映出個人辨識特徵和細節表情。




[5] 中樣例圖片(來自//toonify.photos/)
[6] 中樣例圖片

阿里雲視頻雲自研卡通智繪 Avatar
2020年,由阿里雲視頻雲自研的卡通智繪Avatar橫空出世,獲得了業界矚目。在2021年10月的雲棲大會上,阿里雲視頻雲的卡通智繪項目亮相阿里雲開發者展台,近2000名參會者爭相體驗,成為了大會爆款。

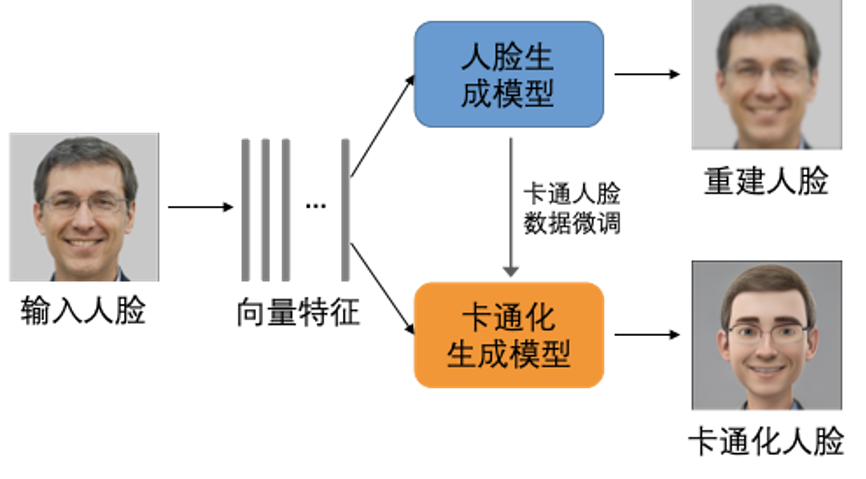
阿里雲卡通智繪採用了隱變量映射的技術方案,對輸入人臉圖片,發掘其顯著特徵(如眼睛大小,鼻型等),可以自動化生成具有個人特色的虛擬形象(即風格化後的效果)。
首先利用自有的海量有版權的高清人臉數據集通過無監督的方式訓練一個可以生成高清人臉圖片的模型,即真實人臉模擬器,在隱變量的控制下生成大量不同人臉特徵的高清人臉圖片。利用收集的少量目標風格圖片(目標風格圖片無需跟真實人臉一一對應)微調該模型、得到風格化模擬器。真實人臉模擬器和風格化模擬器共享隱變量,即一個隱變量可以映射得到一對「偽」人臉圖片及其對應的風格化圖片。


通過採樣大量的隱變量,我們可以得到大量涵蓋不同人臉屬性(性別、年齡、表情、髮型、是否戴眼鏡等)的數據對,從而用來訓練圖像翻譯網絡。基於人臉先天的結構性(如眼睛、鼻子等)以及真實人臉和風格化後虛擬形象的結構性差異(如卡通形象的眼睛往往又大又圓),在網絡中加入局部區域相關性計算模塊以及人臉重建的約束,從而訓練得到的網絡生成的虛擬形象既生動可愛、又具有個人特色。
模型設計
基於人臉先天的結構性(如眼睛、鼻子等)以及真實人臉和風格化後虛擬形象的結構性差異(如卡通形象的眼睛往往又大又圓),在網絡中加入局部區域相關性計算模塊(即希望真人的眼睛和虛擬形象的眼睛的特徵有一定對應關係)以及人臉重建的約束,從而使生成的虛擬形象既生動可愛、又具有個人特色。
效果展示:

Avatar 的未來
得益於 AI 技術的高速發展,我們現在已經擁有了製作虛擬人技術,但相信這一切只是開端。在可預見的未來,Avatar 將作為元宇宙數字居民的數字化身,越來越頻繁的出現在虛擬世界中。而 Avatar 也將成為虛擬世界中的極其重要的一項數字資產。
最後引用扎克伯格對數字人的一段描述,「虛擬世界的特徵是存在感,即你可以真切感受到另一個人或在另外一個地方。創造、虛擬人和數字對象將成為我們表達自我的核心,這將帶來全新的體驗和經濟機會。」
「The defining quality of the metaverse is presence, which is this feeling that you』re really there with another person or in another place,」 Mr. Zuckerberg told analysts in July. 「Creation, avatars, and digital objects are going to be central to how we express ourselves, and this is going to lead to entirely new experiences and economic opportunities.」
參考文獻:
[1] Aneta Texler, Ondřej Texler, Michal Kučera, Menglei Chai, and Daniel Sýkora. FaceBlit: Instant Real-time Example-based Style Transfer to Facial Videos, In Proceedings of the ACM in Computer Graphics and Interactive Techniques, 4(1), 2021.
[2] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. A Neural Algorithm of Artistic Style. Journal of Vision September 2016, Vol.16, 326.
[3] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. A Learned Representation for Artistic Style. In International Conference on Learning Representations 2017.
[4] Kaidi Cao, Jing Liao, and Lu Yuan. CariGANs: Unpaired Photo-to-Caricature Translation. In ACM Transactions on Graphics (Siggraph Asia 2018).
[5] Justin N. M. Pinkney and Doron Adler. Resolution Dependent GAN Interpolation
for Controllable Image Synthesis Between Domains. In NeurIPS 2020 Workshop.
[6] Guoxian Song, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng, and Tat-Jen Cham. AgileGAN: Stylizing Portraits by Inversion-Consistent Transfer Learning. In ACM Transactions on Graphics (Siggraph 2021).


