Java中的函數式編程(七)流Stream的Map-Reduce操作
- 2021 年 10 月 26 日
- 筆記
- JAVA, Java Stream, 函數式編程, 後端
寫在前面
Stream 的 Map-Reduce 操作是Java 函數式編程的精華所在,同時也是最為複雜的部分。但一旦你啃下了這塊硬骨頭,那你就真正熟悉Java的函數式編程了。
如果你有大數據的編程經驗,你會對術語 Map-Reduce 十分熟悉親切。如果你不熟悉大數據編程,也無所謂,通過本文的學習,相信你會對 Map-Reduce 會有一定的理解。下面我們將開始一次有趣的歷程。
如有疑問,歡迎加群討論。
本文的示例代碼可從gitee上獲取://gitee.com/cnmemset/javafp
Stream的map操作
map操作又稱為映射操作,是處理Stream的重要操作。它的作用是將當前Stream中的每個元素都映射轉換為另一個元素,從而得到一個新的Stream。轉換前後的元素類型也可以不同。
下面介紹 Stream 中常用的 Map 方法。
map()
map的方法簽名是:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
map方法是一個中間操作,作用是將當前Stream中的每個元素通過參數 mapper 轉換為另一個元素,轉換前的元素類型為T,轉換後的元素類型為 R。
一個簡單例子是字符串轉換為字符串的長度:
public static void mapStream() {
List<String> words = Arrays.asList("hello", "world", "I", "love", "you");
words.stream()
.map(String::length)
.forEach(System.out::println);
}
上述代碼輸出每個單詞的長度:
5
5
1
4
3
mapToInt()、mapToLong()和mapToDouble()
它們的方法簽名分別是:
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
它們和map()方法大同小異,分別是針對基礎類型 int 、long 和 double 的特殊處理,省去了裝拆箱的消耗。
flatMap()
flatMap的方法簽名是:
<R> Stream<R> flatMap(
Function<? super T, ? extends Stream<? extends R>> mapper);
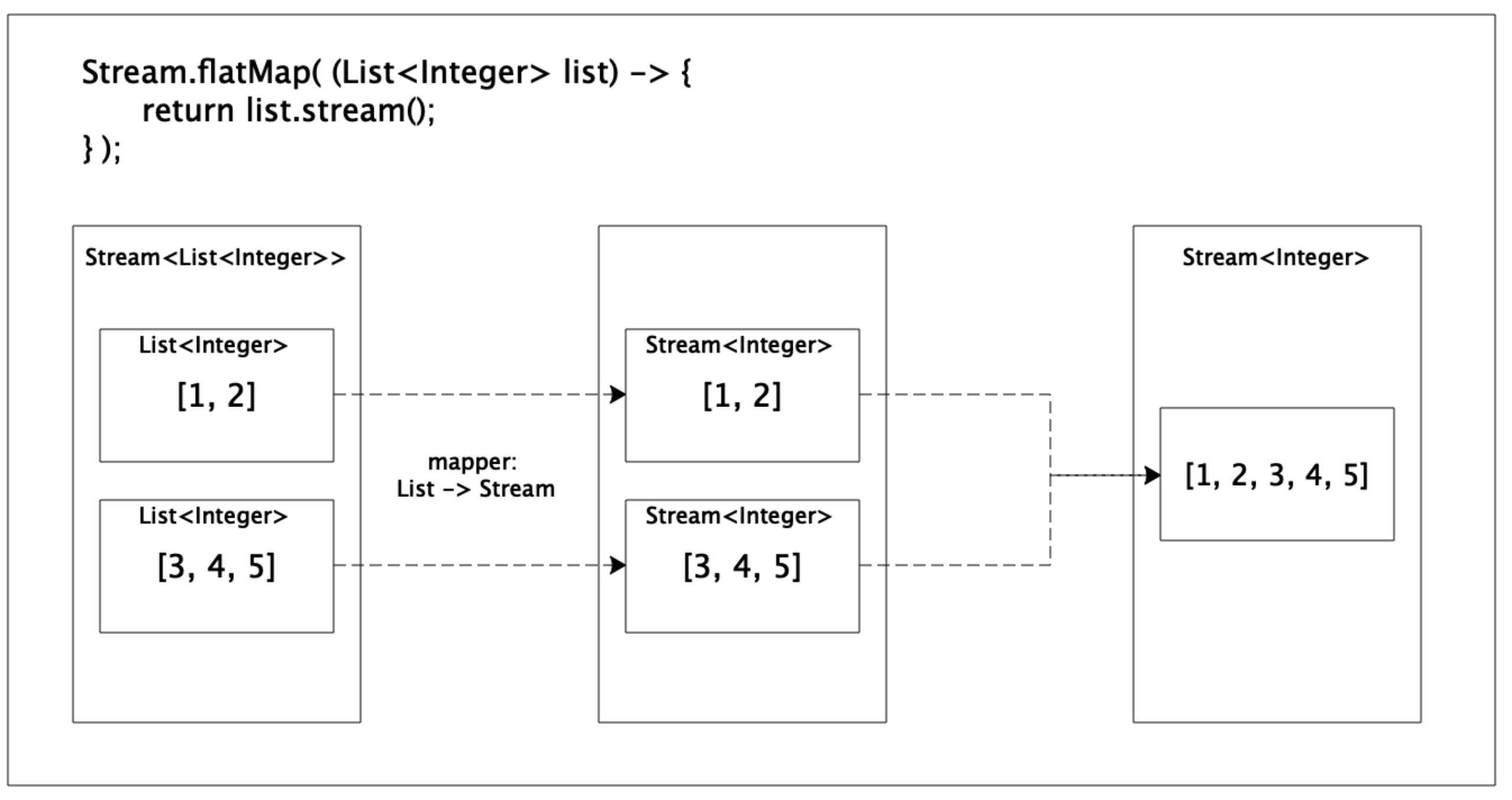
flatMap是一個中間操作,作用是將當前Stream的每個元素通過參數 mapper 轉換成一個類型為 Stream 的元素,然後將這些 Stream 合併為一個新的 Stream。顧名思義,flat的含義就是將當前Stream中的元素「攤平」,從一個單獨的元素,轉換為多個元素組成的Stream。
文字表述總是蒼白無力,我們先用一個實例來輔助說明:
public static void flatMapStream() {
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(System.out::println);
}
上述代碼的輸出為:
1
2
3
4
5
stream的元素類型是一個 List,總共有兩個元素 —— [1, 2] 和 [3, 4, 5]。
在 flatMap 方法中,首先將2個 List 轉換為2個 Stream,然後再將這2個Stream合併為一個新的Stream並返回。圖解如下:
Stream的reduce操作
reduce操作(reduction operation),翻譯為規約操作,是Stream中最複雜的操作。
規約操作,是通過重複執行指定的合併操作(combining operation),將Stream中的所有元素合併得到一個匯總結果的過程。例如,求和(sum)、求最大或最小值(max / min)、求平均數(average)、求元素總個數(count)、將所有元素匯總到一個列表(collect),這些都屬於規約操作。
規約操作都屬於終止操作(terminal operations)。
Stream類庫有兩個通用的規約操作 reduce() 和collect()。下面我們着重介紹相關的方法。
reduce()
reduce方法有3種重寫形式:
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
雖然參數和返回值不同,但它們的語義是相似的。下面逐一介紹。
reduce(BinaryOperator)
先看第一個reduce方法:
Optional<T> reduce(BinaryOperator<T> accumulator);
其中 T 是 Stream 的泛型類型。
參數 accumulator 是指定的合併操作(combining operation)。
在串行執行時,整個方法等價於下面的偽代碼:
boolean foundAny = false;
T result = null;
for (T element : this stream) {
if (!foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();
要注意的是,參數 accumulator 定義的函數必須滿足結合律(associative),否則在一些順序不確定的或並行的場景中會導致不正確的結果。譬如數據源是一個HashSet的話,其中的元素順序是不確定的。
結合律(associative)就是我們在小學時候學的結合律(加法結合律,乘法結合律)。對於一個函數或操作 op ,給定三個操作數 a、b、c,當 op 滿足結合律時,即:
(a op b) op c == a op (b op c)
以上述的 accumulator 為例,accumulator 滿足結合律,即:
accumulator.apply(accumulator.apply(a, b), c) == accumulator.apply(a, accumulator(b, c))
示例代碼:
public static void reduceStream() {
Stream<Integer> stream = Stream.of(1, 3, 5, 7, 9);
Integer sum = stream.reduce((x, y) -> x + y).get();
System.out.println(sum);
}
上述代碼輸出為:
25
reduce(T, BinaryOperator)
第二個reduce的方法簽名是:
T reduce(T identity, BinaryOperator<T> accumulator);
其中 T 是 Stream 的泛型類型。
與第一個reduce方法比較,多了一個參數 identity 。
參數 identity 是reduce操作的初始值。
參數accumulator 要求滿足結合律(associative)。
在串行的場景中,整個方法等價於下面的偽代碼:
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
和第一個reduce方法一樣,參數 accumulator 定義的函數必須滿足結合律(associative),否則在一些順序不確定的或並行的場景中會導致不正確的結果。
此外,如果涉及到並行操作(parallel operations),對參數 identity 還有一個要求:
對任意值 t,要滿足 accumulator.apply(identity, t) == t 。否則,會導致錯誤的結果。
還是求和的場景,示例代碼如下:
public static void reduceStream2() {
List<Integer> list = Arrays.asList(1, 3, 5, 7, 9);
// 串行執行,對參數 identity 並沒有實際的約束。
Integer sum = list.stream().reduce(0, (x, y) -> x + y);
System.out.println(sum); // sum = 0+1+3+5+7+9 = 25
// 串行執行,對參數 identity 並沒有實際的約束。
sum = list.stream().reduce(5, (x, y) -> x + y);
System.out.println(sum); // sum = 5+1+3+5+7+9 = 30
// 並行執行。這是正確的範例:因為數字 0 是累加操作的 identity 。
sum = list.parallelStream().reduce(0, (x, y) -> x + y);
System.out.println(sum); // sum = 0+1+3+5+7+9 = 25
// 並行執行。這是錯誤的範例:因為數字 5 並不是累加操作的 identity 。
sum = list.parallelStream().reduce(5, (x, y) -> x + y);
System.out.println(sum); // 會輸出一個大於 30 的數字
}
上述代碼輸出類似:
25
30
25
50
可以看到,在最後一個範例中,得出了一個錯誤的結果(正確結果應該是30)。
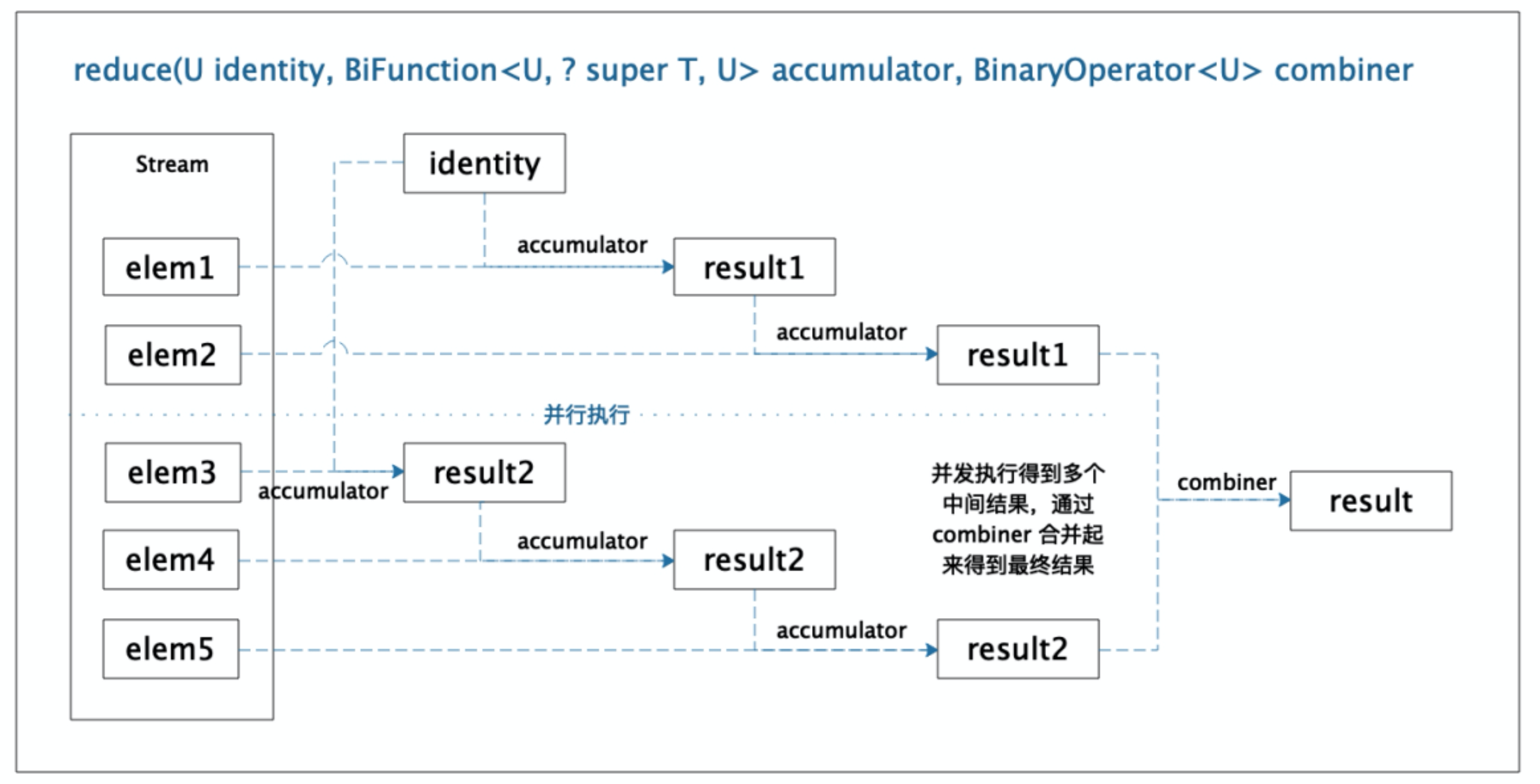
reduce(U, BiFunction, BinaryOperator)
第三個reduce方法的簽名是:
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
其中 U 是返回值的類型,T 是 Stream 的泛型類型。
參數 identity 是規約操作的初始值。
參數accumulator 是與Stream中單個元素的合併操作,等同於函數 U apply(U u, T t)。
參數 combiner 是將並行執行得到的多個中間結果進行合併的操作,等同於函數 U apply(U u1, U u2)。
圖解如下:
在串行的場景中,整個方法等價於下面的偽代碼:
U result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
從偽代碼中可以看到,串行時不涉及到參數 combiner ,串行時甚至可以將其設置為任一個非null值即可,不影響執行。
但在並行編程中,對3個參數都有一些特殊要求:
1. 參數 combiner 必須滿足結合律
2. 參數 identity,對於任意值 u,必須滿足 combiner.apply(identity, u) == u
3. 參數 accumulator 和 combiner 兩者必須兼容,即對於任意值 u 和 t,必須滿足:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
假設一個場景,我們要求一篇文章中字母的總長度,示例代碼:
public static void reduceStream3() {
List<String> article = Arrays.asList("hello", "world", "I", "love", "you");
Integer letterCount = article.stream().reduce(
0, // identity 初始值
(count, str) -> count + str.length(), // accumulator 累加器,也起到了 map 的作用
(a, b) -> a + b // combiner 拼接器,並行執行時才會用到
);
// 輸出 18
// 5(hello) + 5(world) + 1(I) + 4(love) + 3(you) = 18
System.out.println(letterCount);
}
在上述示例中,
1) combiner 是求和函數,滿足結合律;
2) identity 是0,也滿足 0 + u == u;
3) 對於任意的整數 count 和 字符串 str,也滿足 count + (0 + str.length()) == count + str.length()
因此,上述的示例是可以通過並行的方式執行的:
public static void reduceStream4() {
List<String> article = Arrays.asList("hello", "world", "I", "love", "you");
// parallelStream():以並行的方式執行
Integer letterCount = article.parallelStream().reduce(
0, // identity 初始值
(count, str) -> count + str.length(), // accumulator 累加器,也起到了 map 的作用
(a, b) -> a + b // combiner 拼接器,並行執行時才會用到
);
// 輸出 18
// 5(hello) + 5(world) + 1(I) + 4(love) + 3(you) = 18
System.out.println(letterCount);
}
對於第三個reduce方法,參數 accumulator 同時也是一個mapper(映射器),在進行合併操作的同時,也做了map操作。因此,我們是可以通過 「map方法 + 第二個reduce方法」來實現第三個reduce方法的。但在某些場景中,將mapper和accumulator 混合起來,可以避免一些不必要的計算操作,使得程序更有效率。
用「map方法 + 第二個reduce方法」實現同樣的功能,示例代碼:
public static void reduceStream5() {
List<String> article = Arrays.asList("hello", "world", "I", "love", "you");
// parallelStream():以並行的方式執行
// 分開的 map + accumulator
Integer letterCount = article.parallelStream()
.map(s->s.length())
.reduce(0, (a, b) -> a + b);
// 輸出 18
// 5(hello) + 5(world) + 1(I) + 4(love) + 3(you) = 18
System.out.println(letterCount);
}
collect()
collect方法,顧名思義,它的作用是將Stream中的元素「收集」起來。它是Stream類庫中最靈活、最通用的方法之一。一個常見的應用場景就是通過collect方法將Stream中的匯總到一個List中。
先給一個簡單的例子直觀感受一下:
public static void collectToList() {
Stream<String> stream = Stream.of("hello", "world", "I", "love", "you");
List<String> list = stream.collect(Collectors.toList());
System.out.println(list);
}
上述代碼是collect方法最簡單的應用:將一個Stream轉換為一個List。
collect方法有2種重寫形式:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
這2種重寫形式的語義是一致的,雖然細節上有差異,但仍然可以認為第二個collect方法的參數 collector 就是對第一個collect方法中三個參數supplier、accumulator和combiner的封裝。
collect(Supplier, BiConsumer, BiConsumer)
第一個collect方法的簽名是:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
其中 R 是返回值的類型,通常是一個容器類(例如 Collection 或 Map)。T 是Stream中的元素類型。
在解釋3個參數的作用之前,我們先思考一個問題:如果要把Stream中的元素「收集」到一個容器中,需要哪些信息呢?很顯然:
首先我們要知道 1) 是哪個容器(supplier);
其次我們要知道 2) 如何將單個元素加入到該容器中(accumulator);
最後我們要知道 3) 在並行執行的時候,如何將多個中間結果的容器合併為一個(combiner)。
對應參數的含義也自然而然出來了:
參數 supplier 是用來創建一個容器實例的函數。
參數 accumulator 是將Stream中的一個元素合併到容器中的函數。
參數 combiner 是將兩個容器歸併為一個容器的函數,只在並行執行的時候用到。
在串行執行的場景下,整個方法等價於以下的偽代碼:
R result = supplier.get();
for (T element : this stream)
accumulator.accept(result, element);
return result;
而在並行執行的場景下,我們有一些額外的要求:
- combiner函數滿足結合律
- 要求combiner 和 accumulator 是兼容的(compatible),即對於任意的r和t,滿足 combiner.accept(r, accumulator.accept(supplier.get(), t)) == accumulator.accept(r, t)
以一個簡單的例子加以說明,假設我們要將Stream中的字符串「collect」到一個ArrayList中,示例代碼如下:
public static void collectToList1() {
Stream<String> stream = Stream.of("hello", "world", "I", "love", "you");
List<String> list = stream.collect(
ArrayList::new, // supplier 創建一個 ArrayList 實例
ArrayList::add, // accumulator將一個 String 加入到 ArrayList 中
ArrayList::addAll // combiner 將兩個 ArrayList 合併成一個
);
System.out.println(list);
}
上述代碼也是符合併行執行的要求的:ArrayList的addAll方法滿足結合律;addAll方法是與add方法兼容的(compatible)。因此,在上述的collect過程中,我們允許以並行的方式來執行 —— 即使 ArrayList 不是線程安全的,我們也無需考慮這個問題,這是Stream並行編程的優勢之一。
collect(Collector)
第二個collect方法的簽名是:
<R, A> R collect(Collector<? super T, A, R> collector);
其中,T是Stream元素的類型;R是返回值的類型;A是一個中間結果的類型,最後需要將結果從A轉換到R。
類Collector(收集器)可以看做是對前一個collect方法中的三個參數supplier、accumulator和combiner的封裝,但Collector更加靈活和通用。
類Collector的原理和源碼相對比較複雜,限於篇幅,本文就不做詳細闡述,如果讀者感興趣,可以加群討論。
Collector是如此的靈活,我們決定從一個現實場景出發,逐步向大家展示Collector的強大功能。
場景描述
假設一個場景:我們接到了一個公司的需求,需要對公司的信息進行一些分析,包括性別、部門、薪酬等維度。為簡單起見,我們不考慮員工重名的情形。
首先,我們定義一個Employee 的類:
public class Employee {
/** 姓名 */
private String name;
/** 性別:0 女 1 男 */
private int gender;
/** 部門 */
private String department;
/** 薪酬 */
private int salary;
// getter and setter
...
}
需求1:要將所有員工的姓名轉換為一個List
實現這個需求的代碼很簡單:
public static void collectEmployeeNamesToList() {
List<Employee> employees = Utils.makeEmployees();
List<String> names = employees.stream()
.map(Employee::getName)
.collect(Collectors.toList());
// 如果要指定返回的List具體類型,譬如指定為 ArrayList
ArrayList<String> arrayNames = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(ArrayList::new));
}
Collectors工具類提供了一系列內置的Collector,包括:
a. Collectors.toList(): 轉換為List
b. Collectors.toSet():轉換為Set
c. Collectors.toCollection(Supplier):轉換為指定的Collection類
一個有趣的問題:為什麼沒有toQueue()?先不給答案了,有興趣的同學可以加群討論。
需求2:將員工列錶轉換成<姓名,薪酬>組成的Map
Collector除了可以將Stream轉換為Collection之外,還可以轉換為Map。
示例代碼如下:
public static void collectEmployeeNamesToMap() {
List<Employee> employees = Utils.makeEmployees();
Map<String, Integer> nameScoreMap = employees.stream()
.collect(Collectors.toMap(Employee::getName, Employee::getSalary));
System.out.println(nameScoreMap);
}
示例代碼中,Employee::getName用來生成Map的key ,而Employee::getSalary則用來生成Map中key對應的value。
toMap方法還有兩個重寫形式,主要用來處理key重複時的情形以及指定Map的具體類型。
需求3:將員工按男女分成兩組
對於這個需求,使用方法 partitioningBy 。示例代碼:
public static void partitionEmployeesToMap() {
List<Employee> employees = Utils.makeEmployees();
Map<Boolean, List<Employee>> map = employees.stream()
.collect(Collectors.partitioningBy(e -> e.getGender() == 1));
System.out.println(map);
}
partitioningBy 可以用更通用的 groupingBy 來實現。下面接着介紹 groupingBy 。
需求4:將員工按照部門分組
使用簡化版 groupingBy(Function) 方法來實現,示例代碼:
public static void groupEmployeesToMap() {
List<Employee> employees = Utils.makeEmployees();
Map<String, List<Employee>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(map);
}
需求5:將員工按照部門分組後,計算每個部門的員工薪酬總數
使用通用版 groupingBy(Function, Collector) 方法來實現,示例代碼:
public static void groupEmployeesToMap1() {
List<Employee> employees = Utils.makeEmployees();
// 使用增強版的 groupingBy
Map<String, Integer> map = employees.stream()
.collect(
// 上游收集器
Collectors.groupingBy(
Employee::getDepartment,
// 下游收集器 downstream collector
Collectors.summingInt(Employee::getSalary)
)
);
System.out.println(map);
}
通用版 groupingBy 方法簽名為:
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(
Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream);
首先通過參數 classifier 定義的函數對Stream的元素分組,然後使用下游收集器(downstream collector),對分組後的元素進行再處理(甚至可以再次分組)。
閱讀源碼可以發現,簡化版 groupingBy 實際上是通用版groupingBy 的簡寫:
groupingBy(classifier) == groupingBy(classifier, toList())
其中,toList() 是 groupingBy 的下游收集器。
自定義Collector
除了可以使用Collectors工具類已經封裝好的收集器,我們還可以自定義收集器,收集任何形式你想要的信息。
但是,不誇張的說,Collectors工具類中內置的Collector,基本能滿足我們所有的需求。在你決定要自定義一個Collector之前,請務必確認內置的Collector無法實現你的需求。
具體如何自定義Collector,限於篇幅,在本文不做詳細描述,有興趣的同學可以加群討論。
結語
本文介紹了 Stream 的 Map-Reduce 操作。
如果你從頭到尾認真閱讀了本文,那麼恭喜你,你的Java函數式編程已經正式入門了。


