單階段實例分割綜述
- 2021 年 10 月 22 日
- 筆記
前言 本文比較全面地介紹了實例分割在單階段方法上的進展,根據基於局部掩碼、基於全局掩碼和按照位置分割這三個類別,分析了相關19篇論文的研究情況,並介紹了它們的優缺點。
公眾號文末附相關19篇論文的下載方式。
關注公眾號CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
實例分割是一項具有挑戰性的計算機視覺任務,需要預測對象實例及其每像素分割掩碼。這使其成為語義分割和目標檢測的混合體。

![]()
自 Mask R-CNN 以來,實例分割的SOTA方法主要是 Mask RCNN 及其變體(PANet、Mask Score RCNN 等)。它採用先檢測再分割的方法,先進行目標檢測,提取每個目標實例周圍的邊界框,然後在每個邊界框內部進行二值分割,分離前景(目標)和背景。
除了檢測然後分割(或逐檢測分割)的自頂向下方法之外,還有其他一些實例分割方法。一個例子是通過將實例分割作為自底向上的像素分配問題來關注像素,就像在 SpatialEmbedding (ICCV 2019) 中所做的那樣。但是這些方法通常比檢測然後分割的 SOTA 具有更差的性能,我們不會在這篇文章中詳細介紹。
然而,Mask RCNN 速度非常慢,許多實時應用場合無法使用。此外,Mask RCNN 預測的掩碼具有固定的分辨率,因此對於具有複雜形狀的大目標來說不夠精細。由於anchor-free目標檢測方法(例如 CenterNet 和 FCOS)的進步,已經出現了一波關於單階段實例分割的研究。其中許多方法比 Mask RCNN 更快、更準確,如下圖所示。
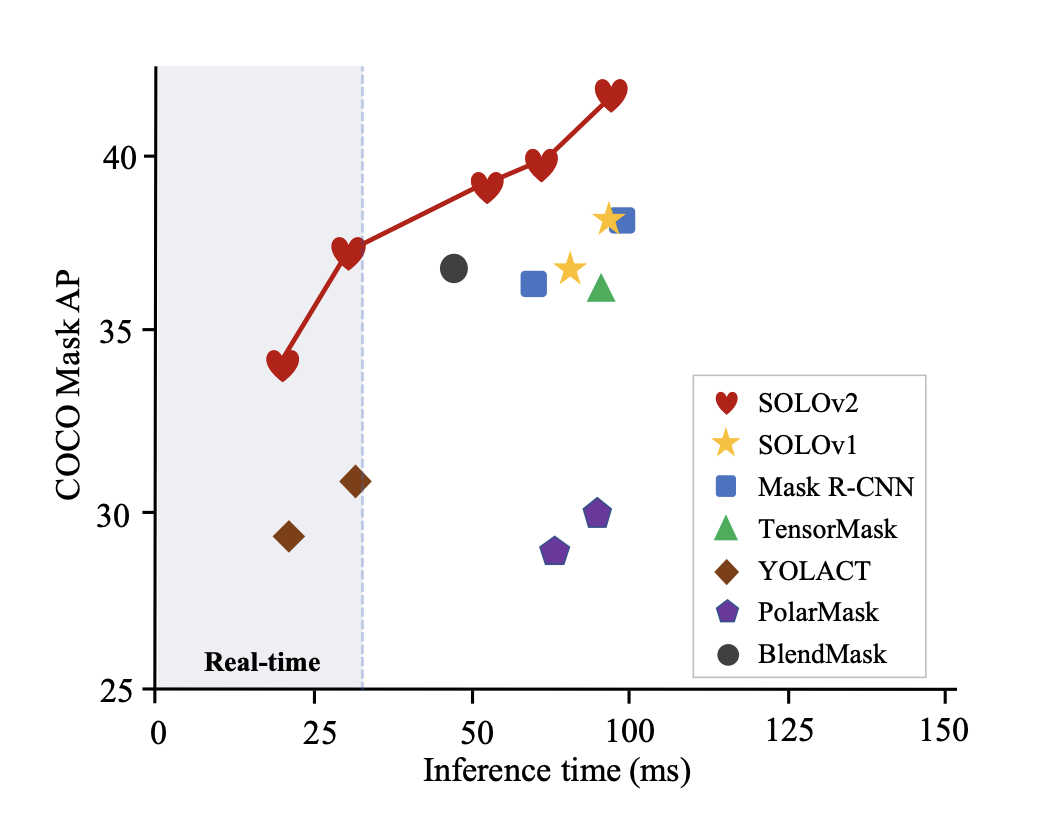
![]()
最近在 Tesla V100 GPU 上測試的單階段方法的推理時間
本文將回顧單階段實例分割的最新進展,重點是掩碼錶示——實例分割的一個關鍵方面。
局部掩碼和全局掩碼
在實例分割中要問的一個核心問題是實例掩碼的表示或參數化——1)是使用局部掩碼還是全局掩碼,2)如何表示/參數化掩碼。
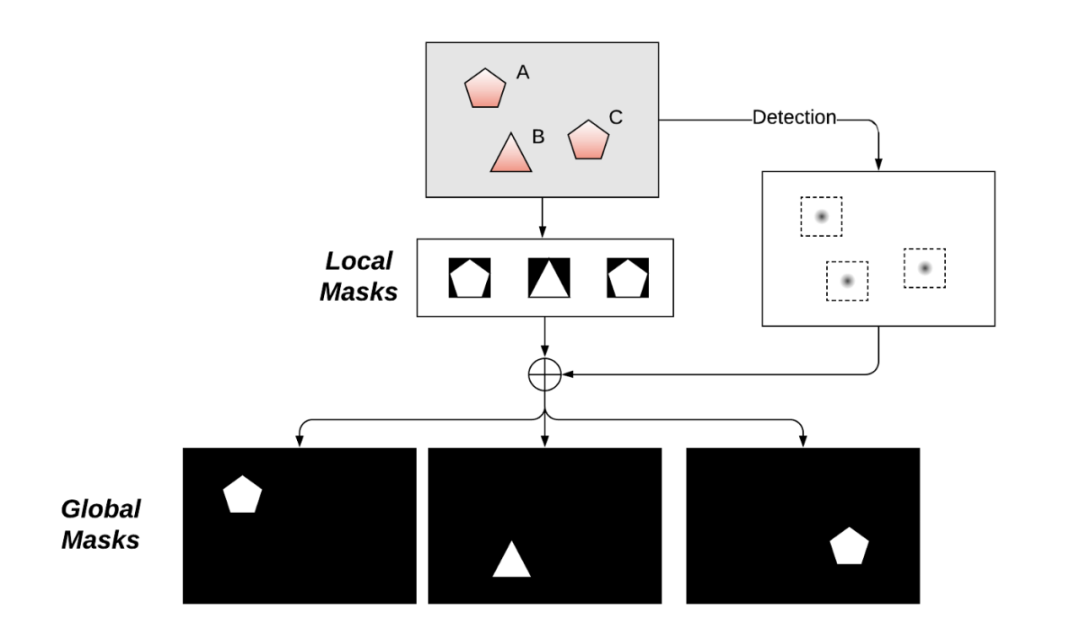
![]()
掩碼錶示:局部掩碼和全局掩碼
主要有兩種表示實例掩碼的方法:局部掩碼和全局掩碼。
全局掩碼是我們最終想要的,它與輸入圖像具有相同的空間範圍,儘管分辨率可能更小,例如原始圖像的 1/4 或 1/8。它具有對大或小目標具有相同分辨率(因此具有固定長度特徵)的天然優勢。這不會犧牲更大目標的分辨率,固定分辨率有助於執行批處理以進行優化。
局部掩碼通常更緊湊,因為它沒有作為全局掩碼的過多邊界。它必須與要恢復到全局掩碼的掩碼位置一起使用,並且局部掩碼大小將取決於目標大小。但是要執行有效的批處理,實例掩碼需要固定長度的參數化。最簡單的解決方案是將實例掩碼調整為固定圖像分辨率,如 Mask RCNN 所採用的那樣。正如我們在下面看到的,還有更有效的方法來參數化局部掩碼。
根據是使用局部掩碼還是全局掩碼,單階段實例分割在很大程度上可以分為基於局部掩碼( local-mask-based )和基於全局掩碼( global-mask-based )的方法。
基於局部掩碼的方法
基於局部掩碼的方法直接在每個局部區域上輸出實例掩碼。
顯式編碼的輪廓
Bounding box 在某種意義上是一個粗糙的掩碼,它用最小的邊界矩形來逼近掩碼的輪廓。ExtremeNet(Bottom-up Object Detection by Grouping Extreme and Center Points,CVPR 2019)通過使用四個極值點(因此是一個具有8個自由度的邊界框而不是傳統的4個DoF)進行檢測,並且這種更豐富的參數化可以自然地擴展通過在其對應邊緣上的兩個方向上的極值點延伸到整個邊緣長度的 1/4 的一段,到八邊形掩模。

![]()
從那時起,有一系列工作試圖將實例掩碼的輪廓編碼/參數化為固定長度的係數,給定不同的分解基礎。這些方法回歸每個實例的中心(不一定是 bbox 中心)和相對於該中心的輪廓。
ESE-Seg(Explicit Shape Encoding for Real-Time Instance Segmentation,ICCV 2019)為每個實例設計了一個內圓心半徑形狀簽名,並將其與切比雪夫多項式擬合。
PolarMask(PolarMask:Single Shot Instance Segmentation with Polar Representation,CVPR 2020)使用從中心以恆定角度間隔的光線來描述輪廓。
FourierNet(FourierNet:Compact mask representation for instance segmentation using differentiable shape decoders)引入了使用傅立葉變換的輪廓形狀解碼器,並實現了比 PolarMask 更平滑的邊界。

![]()
各種基於輪廓的方法
這些方法通常使用 20 到 40 個係數來參數化掩碼輪廓。它們推理速度快且易於優化。但是,它們的缺點也很明顯。首先,從視覺上看,它們都看起來——老實說——非常糟糕。它們無法精確描繪掩碼,也無法描繪中心有孔的物體。
這系列方法很有意思,但是前途渺茫。實例掩碼的複雜拓撲或其輪廓的顯式編碼是難以處理的。
結構化 4D 張量
TensorMask (TensorMask: A Foundation for Dense Object Segmentation, ICCV 2019) 是通過預測每個特徵圖位置的掩碼來展示密集掩碼預測思想的首批作品之一。TensorMask 仍然通過感興趣區域而不是全局掩碼來預測掩碼,並且它能夠在不運行目標檢測的情況下運行實例分割。
TensorMask 利用結構化的 4D 張量來表示空間域上的掩碼(2D 迭代輸入圖像中的所有可能位置,2D 表示每個位置的掩碼),它還引入了對齊表示和張量雙錐體( aligned representation and tensor bipyramid )來恢復空間細節,但這些對齊操作使網絡甚至比兩階段的 Mask R-CNN 還要慢。此外,為了獲得良好的性能,它需要使用比標準 COCO 目標檢測管道(6x schedule)長 6 倍的調度進行訓練。
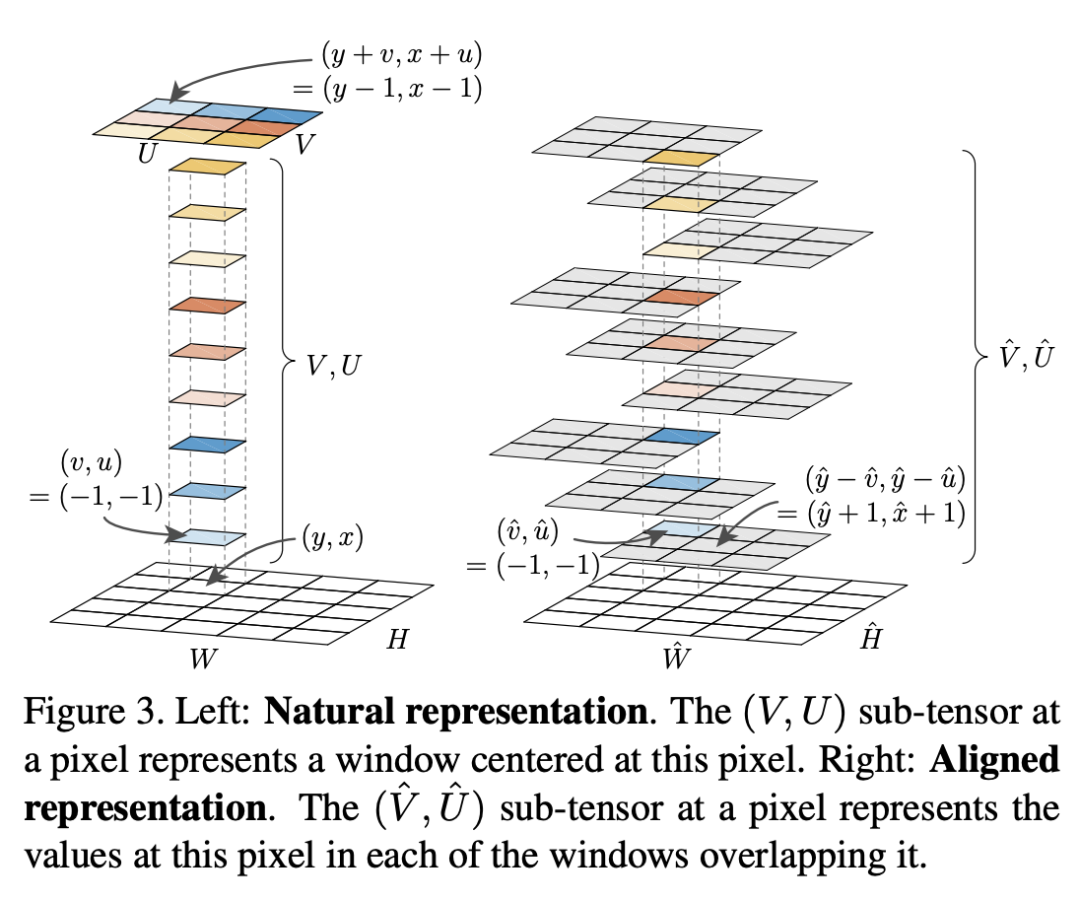
![]()
緊湊型掩碼編碼
自然的目標掩碼不是隨機的,類似於自然圖像,實例掩碼位於比像素空間低得多的內在維度。
MEInst(Mask Encoding for Single Shot Instance Segmentation,CVPR 2020)將掩碼提煉為緊湊且固定的維度表示。通過使用 PCA 進行簡單的線性變換,MEInst 能夠將 28×28 的局部掩碼壓縮為 60 維的特徵向量。 該論文還嘗試在單級目標檢測器(FCOS)上直接回歸 28×28=784-dim 特徵向量,並且在 1 到 2 個 AP 點下降的情況下也得到了合理的結果。
這意味着直接預測高維掩碼(以每個 TensorMask 的自然表示)並非完全不可能,但很難優化。 掩碼的緊湊表示使其更容易優化,並且在推理時運行速度也更快。 它與 Mask RCNN 最相似,可以直接與大多數其他目標檢測算法一起使用。
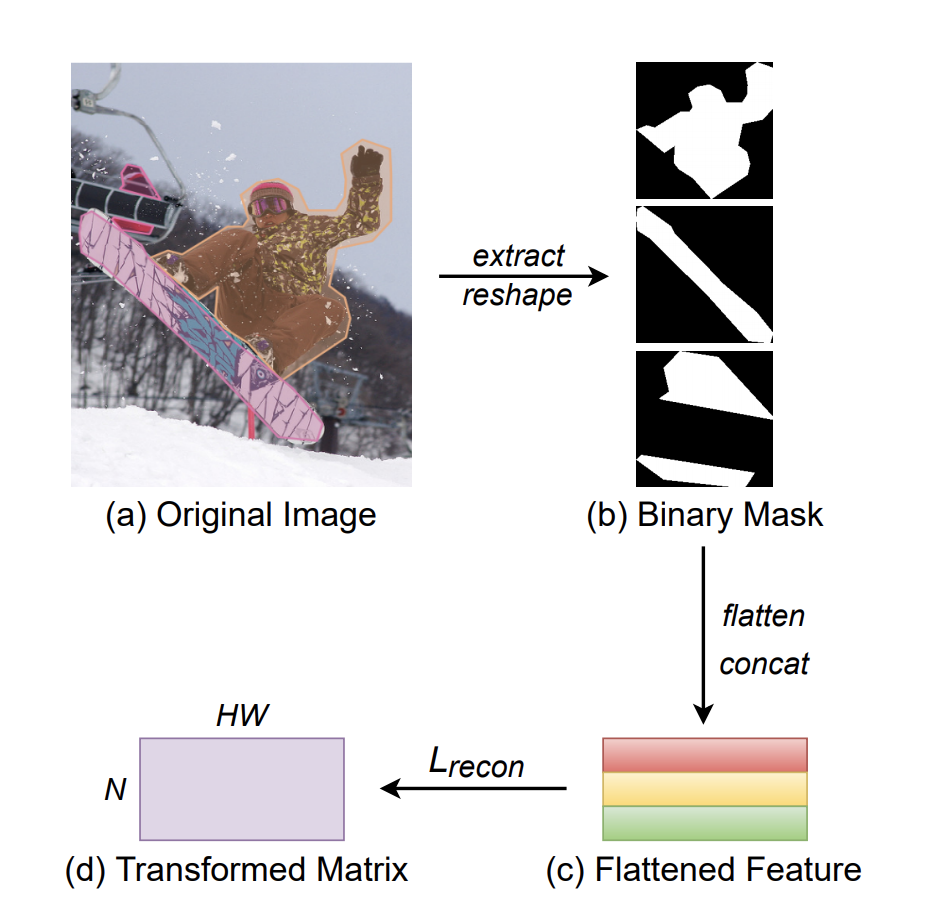
![]()
基於全局掩碼的方法
基於全局掩碼( Global-mask-based )的方法首先基於整個圖像生成中間和共享特徵圖,然後組合提取的特徵以形成每個實例的最終掩碼。這是最近的單階段實例分割方法中的主流方法。
原型和係數( Prototypes and Coefficients )
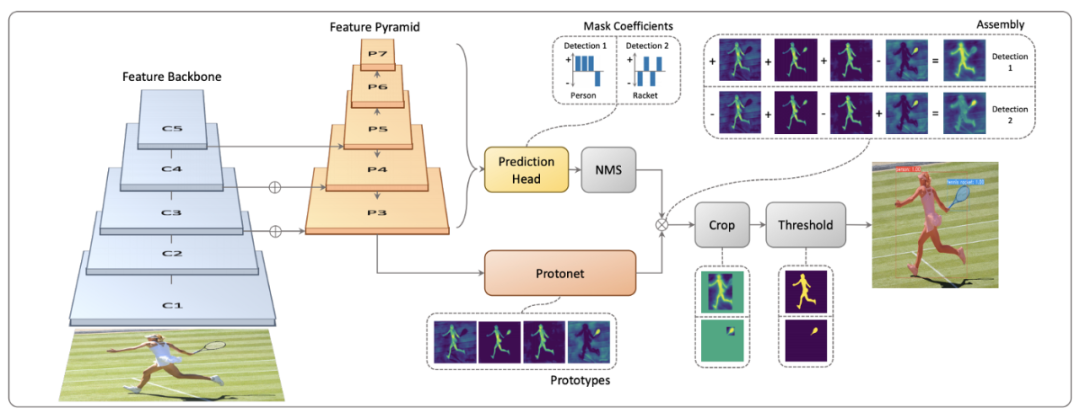
YOLACT(YOLACT:實時實例分割,ICCV 2019)是最早嘗試實時實例分割的方法之一。YOLACT 將實例分割分解為兩個並行任務,生成一組原型掩碼並預測每個實例的掩碼係數。
原型掩碼( prototype masks )是用 FCN 生成的,可以直接受益於語義分割的進步。係數被預測為邊界框的額外特徵。這兩個並行步驟之後是組裝步驟:通過矩陣乘法實現的簡單線性組合和對每個實例的預測邊界框的裁剪操作。裁剪操作減少了網絡抑制邊界框外噪聲的負擔,但如果邊界框包含同一類的另一個實例的一部分,仍然會看到一些泄漏。
![]()
原型掩碼的預測對於確保最終實例掩碼的高分辨率至關重要,這與語義分割相當。原型掩碼僅依賴於輸入圖像,與類別和特定實例無關。這種分佈式表示是緊湊的,因為原型掩碼的數量與實例的數量無關,這使得 YOLACT 的掩碼計算成本恆定(不像 Mask RCNN 的計算成本與實例數量成線性關係)。
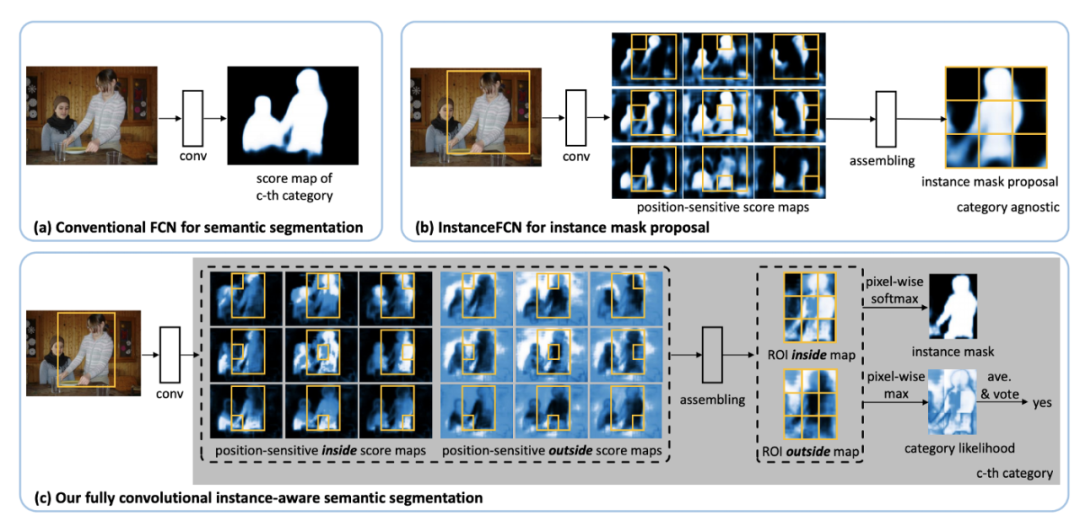
回顧 InstanceFCN(Instance-sensitivefully Convolutional Networks,ECCV 2016)和 MSRA 的後續研究 FCIS(Fully Convolutional Instance-aware Semantic Segmentation,CVPR 2017),它們似乎是 YOLACT 的一個特例。InstanceFCN 和 FCIS 都利用 FCN 生成多個實例敏感的分數圖,其中包含目標實例的相對位置,然後應用組裝模塊輸出目標實例。位置敏感的分數圖可以被視為原型掩碼,但 IntanceFCN 和 FCIS 使用一組固定的空間池操作來組合位置敏感的原型掩碼,而不是學習線性係數。
![]()
InstanceFCN [b] 和 FCIS [c] 使用固定池操作進行實例分割
BlendMask (BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation, CVPR 2020) 建立在 YOLACT 之上,但不是為每個原型掩碼預測一個標量係數,BlendMask 預測一個低分辨率 (7×7) 注意力圖來混合其中的掩碼邊界框。該注意力圖被預測為附加到每個邊界框的高維特徵 (7×7=49-d)。有趣的是,BlendMask 使用的原型掩碼是 4 個,但它甚至只對 1 個原型掩碼起作用。
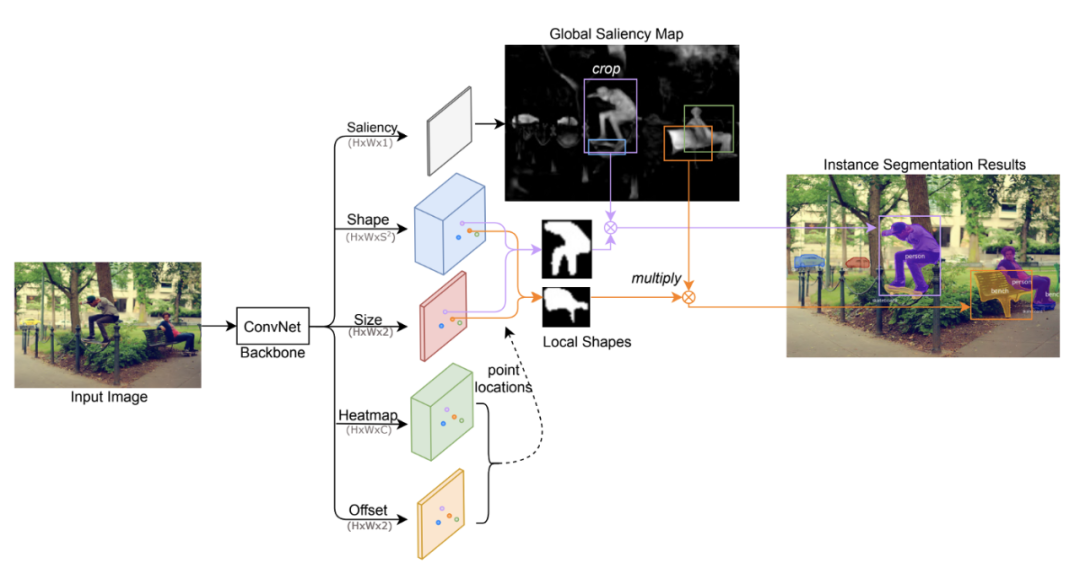
CenterMask(CenterMask:single shot instance segmentation with point representation,CVPR 2020)的工作方式幾乎完全相同,並明確使用 1 個原型掩碼(命名為全局顯着圖)。
CenterMask 使用 CenterNet 作為主幹,而 BlendMask 使用類似的anchor-free和單級 FCOS 作為主幹。
![]()
CenterMask 的架構。BlendMask 有一個極其相似的管道。
請注意,BlendMask 和 CenterMask 都進一步依賴於檢測到的邊界框。在與裁剪的原型蒙版混合之前,注意力圖或掩碼大小必須縮放到與邊界框相同的大小。
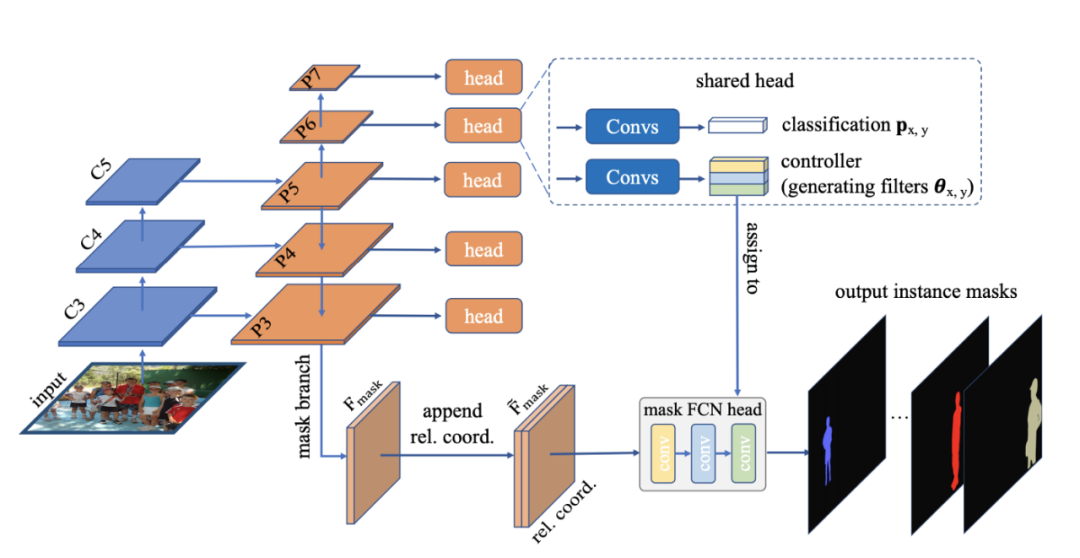
CondInst (Conditional Convolutions for Instance Segmentation) 更進一步,完全消除了對邊界框的任何依賴。它沒有組裝裁剪的原型掩碼,而是借用了動態過濾器的思想並預測了輕量級 FCN 頭部的參數。FCN頭部共有三層,共有169個參數。令人驚奇的是,作者表明,即使原型掩碼是單獨的 2-ch CoordConv,網絡也能在 COCO 上達到 31 個 AP。我們將在下面的隱式表示部分討論這個。
![]()
BlendMask /CenterMask 和 CondInst 都是 YOLACT 的擴展。
-
BlendMask/CenterMask 正在嘗試將裁剪的原型掩碼與每個 bbox 中的細粒度掩碼混合。YOLACT 是 BlendMask 或 CenterMask 的一種特殊情況,其中注意力圖的分辨率為 1×1。
-
CondInst 正在嘗試將裁剪的原型掩碼與由動態預測過濾器組成的更深層次的卷積混合在一起。YOLACT 是 CondInst 的一種特殊情況,其中 FCN 是 1 1×1 conv 層。
使用分支來預測原型掩碼允許這些方法受益於使用語義分割的輔助任務(通常在 AP 中提升 1 到 2 個點)。它也可以自然地擴展到執行全景分割( panoptic segmentation )。
關於表示每個實例掩碼所需的參數,下面列出了一些技術細節。這些具有全局掩碼和係數的方法每個實例掩碼使用 32、196、169 個參數。
-
YOLACT使用32個原型掩碼+32-dim掩碼係數+框裁剪;
-
BlendMask 使用 4 個原型掩碼 + 4 個 7×7 注意力圖 + 框裁剪;
-
CondInst 使用 coordConv + 3 1×1 動態 conv(169 個參數)
SOLO 和 SOLOv2:按位置分割目標
SOLO 是其中一種,值得擁有自己的部分。這些論文很有見地,而且寫得很好。它們對我來說是一件藝術品(就像另一個我最喜歡的 CenterNet)。
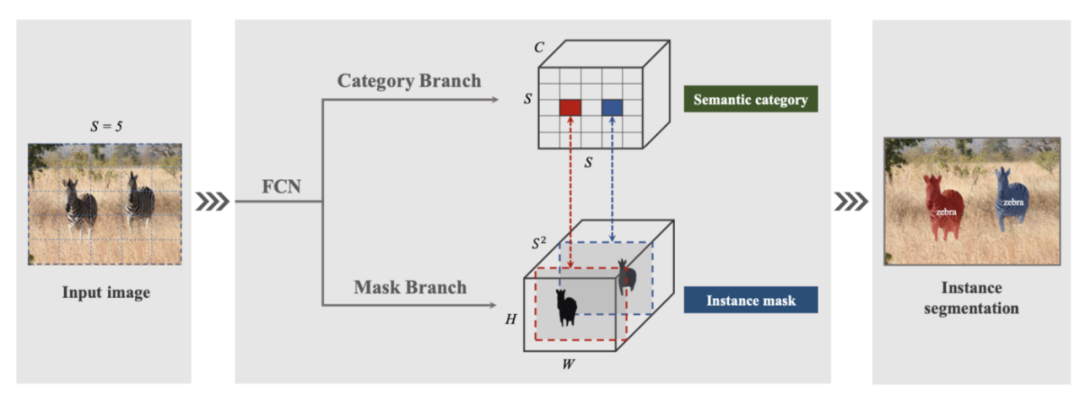
![]()
SOLOv1 的架構
論文第一作者在知乎上回復了SOLO的動機,我引用如下:
「語義分割預測圖像中每個像素的語義類別。類似地,例如分割,我們建議預測每個像素的「實例類別」。現在關鍵的問題是,我們如何定義實例類別?」
如果輸入圖像中的兩個目標實例具有完全相同的形狀和位置,則它們是同一個實例。任何兩個不同的實例要麼具有不同的位置或形狀。由於形狀一般難以描述,我們用尺寸近似形狀。
因此,「實例類別」由位置和大小定義。位置按其中心位置分類。SOLO 通過將輸入圖像劃分為 S x S 單元格和 S² 類的網格來近似中心位置。通過將不同大小的目標分配到特徵金字塔 (FPN) 的不同級別來處理大小。因此對於每個像素,SOLO 只需要決定將像素(和相應的實例類別)分配給哪個 SxS 網格單元和哪個 FPN 級別。所以SOLO只需要執行兩個像素級別的分類問題,類似於語義分割。
現在另一個關鍵問題是掩碼是如何表示的?
實例掩碼直接由堆疊到 S² 通道中的全局掩碼錶示。這是一個巧妙的設計,可以同時解決許多問題。首先,許多先前的研究將 2D 掩碼存儲為扁平向量,當掩碼分辨率增加導致通道數量激增時,這很快變得難以處理。全局掩碼自然地保留了掩碼像素內的空間關係。其次,全局掩碼生成可以保持掩碼的高分辨率。第三,預測掩碼的數量是固定的,與圖像中的目標無關。這類似於原型掩碼的工作線,我們將在 SOLOv2 中看到這兩個流如何合併。
SOLO 將實例分割制定為僅分類問題,並刪除任何依賴於回歸的問題。這使得 SOLO 自然獨立於目標檢測。SOLO 和 CondInst 是直接操作全局掩碼的兩個作品,是真正的無邊界框方法。

![]()
SOLO 預測的全局掩碼。掩碼是冗餘的、稀疏的並且對目標定位錯誤具有魯棒性。
分辨率權衡( Resolution tradeoff )
從 SOLO 預測的全局掩碼中,我們可以看到掩碼對定位誤差相對不敏感,因為相鄰通道預測的掩碼非常相似。這帶來了目標定位的分辨率(以及精度)和實例掩碼之間的權衡。
TensorMask 的 4D 結構化張量的想法在理論上很合理,但在當前 NHWC 張量格式的框架中很難在實踐中實現。將具有空間語義的二維張量展平為一維向量不可避免地會丟失一些空間細節(類似於使用全連接網絡進行語義分割),並且即使表示 128×128 的低分辨率圖像也有其局限性。位置的 2D 或掩模的 2D 必須犧牲分辨率。大多數先前的研究都認為位置分辨率更重要並且對掩碼尺寸進行下採樣/壓縮,從而損害了掩碼的表現力和質量。TensorMask 試圖取得平衡,但繁瑣的操作導致訓練和推理緩慢。SOLO 意識到我們不需要高分辨率的位置信息,並通過將位置壓縮為粗略的 S² 網格來借用 YOLO。這樣,SOLO 就保持了全局掩碼的高分辨率。
我天真地認為 SOLO 或許可以通過將 S² x W x H 全局掩碼預測為附加到 YOLO 中每個 S² 網格的附加扁平 WH 維特徵來工作。我錯了——以全分辨率而不是扁平矢量來制定全局掩碼實際上是 SOLO 成功的關鍵。
Decoupled SOLO 和 Dynamic SOLO
如上所述,SOLO 在 S² 通道中預測的全局掩碼非常冗餘和稀疏。即使在 S=20 的粗分辨率下,也有 400 個通道,而且圖片中的對象也不可能太多以至於每個通道都包含一個有效的實例掩碼。
在Decoupled SOLO 中,形狀為 H x W x S² 的原始 M 張量被兩個形狀為 H x W x S 的張量 X 和 Y 替換。對於位於網格位置 (i, j) 的對象,M_ij 近似為 逐元素乘法 X_i ⊗ Y_j。這將 400 個通道減少到 40 個通道,實驗表明性能沒有下降。
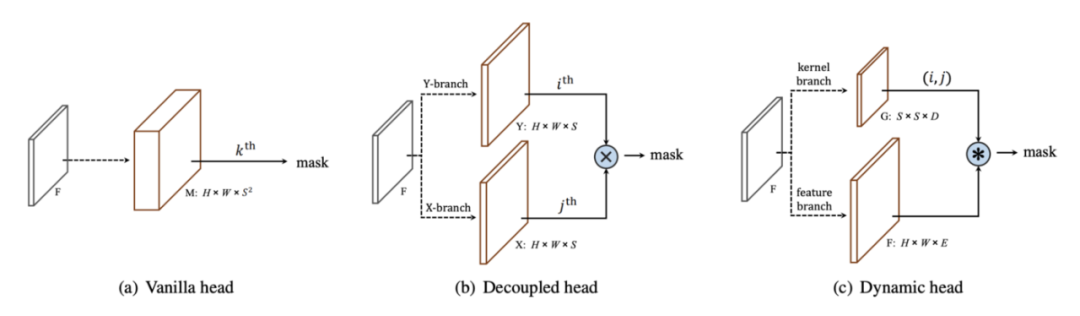
![]()
SOLO vs Decoupled SOLO vs SOLOv2
現在很自然地會問,我們是否可以通過預測更少的掩碼並預測每個網格單元的係數來組合它們來借鑒 YOLACT 的原型掩碼想法?SOLOv2 正是這樣做的。
在 SOLOv2 中,有兩個分支,一個特徵分支和一個內核分支。特徵分支預測 E 原型掩碼,內核分支在每個 S² 網格單元位置預測大小為 D 的內核。正如我們在上面的 YOLACT 部分中看到的那樣,這種動態過濾器方法是最靈活的。當 D=E 時,是原型掩碼(或 1×1 conv)的簡單線性組合,與 YOLACT 相同。該論文還嘗試了 3×3 conv kernels(D=9E)。這可以通過預測輕量級多層 FCN 的權重和偏差(例如在 CondInst 中)更進一步。

![]()
現在,由於全局掩碼分支與其專用位置解耦,我們可以觀察到新的原型掩碼錶現出比 SOLO 中的更複雜的模式。它們仍然對位置敏感,並且更類似於 YOLACT。
掩碼的隱式表示
CondInst 和 SOLOv2 中使用的動態濾波器的想法起初聽起來很棒,但如果將其視為用於線性組合的係數列表的自然擴展,則實際上非常簡單。
還可以認為我們使用係數或注意力圖對掩碼進行了參數化,或者最終將其參數化為用於小型神經網絡頭部的動態濾波器。最近在 3D 學習中也探索了使用神經網絡動態編碼幾何實體的想法。傳統上,3D 形狀要麼使用體素、點雲或網格進行編碼。Occupancy Networks (Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR 2019) 提出將形狀編碼為神經網絡,將深度神經網絡的連續決策邊界視為 3D 表面。網絡接收 3D 中的一個點並判斷它是否在編碼的 3D 形狀的邊界上。這種方法允許在推理期間以任何分辨率提取 3D 網格。
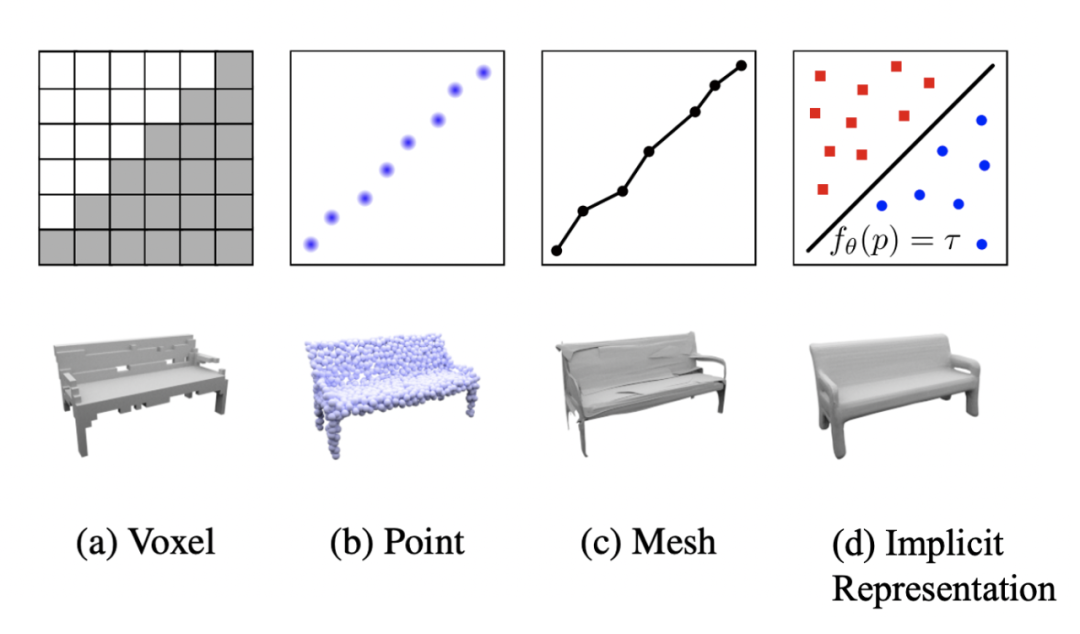
![]()
Occupancy Networks 中提出的隱式表示
我們能否學習一個由每個目標實例的動態過濾器組成的神經網絡,以便網絡接收 2D 中的一個點並輸出該點是否屬於該目標掩碼?這自然會輸出一個全局掩碼,並且可以具有任何所需的分辨率。
回顧 CondInst 的消融研究,證明即使沒有原型掩碼,也只有 CoordConv 輸入(用於執行均勻空間採樣)。由於此操作與原型掩碼的分辨率分離,因此以更高分辨率單獨輸入 CoordConv 以獲得更高分辨率的全局掩碼以查看這是否會提高性能會很有趣。我堅信實例掩碼的隱式編碼是未來。

![]()
只有 CoordConv 輸入沒有原型掩碼,CondInst 也可以預測不錯的性能
最後一句
大多數單階段實例分割工作都是基於anchor-free目標檢測,如CenterNet和FCOS。也許不出所料,上述許多論文都來自阿德萊德大學創建 FCOS 的同一個實驗室。他們最近在 //github.com/aim-uofa/AdelaiDet/ 上開源了他們的平台。
最近的許多方法都很快,並且可以實現實時或接近實時的性能 (30+ FPS)。NMS 通常是實時實例分割的瓶頸。為了實現真正的實時性能,YOLACT 使用 Fast NMS,SOLOv2 使用 Matrix NMS。
後記
-
預測實例掩碼的高維特徵向量是棘手的。幾乎所有的方法都集中在如何將掩碼壓縮成低維表示。這些方法通常使用 20 到 200 個參數來描述一個掩碼,取得不同程度的成功。我認為這是對表示掩碼形狀的最少參數數量的基本限制。
-
手工設計的參數化輪廓並不是很有前途。
-
局部掩碼本質上取決於目標檢測。希望能看到更多直接生成全局掩碼的研究。
-
掩碼的隱式表示是富有表現力的、緊湊的並且可以以任何分辨率生成掩碼。CondInst 有可能通過利用隱式表示的力量生成更高分辨率的全局掩碼。
-
SOLO 很簡單,而 SOLOv2 又快又准。希望能看到更多沿着這條路線的未來研究。
在公眾號CV技術指南後台回復關鍵字 「 0011」 可獲取相關19篇論文。
參考資料
1. SOLO: Segmenting Objects by Locations, Arxiv 12/2019
2. SOLOv2: Dynamic, Faster and Stronger, Arxiv 03/2020
3. YOLACT: Real-time Instance Segmentation, ICCV 2019
4. PolarMask: Single Shot Instance Segmentation with Polar Representation, CVPR 2020 oral
5. ESE-Seg: Explicit Shape Encoding for Real-Time Instance Segmentation, ICCV 2019
6. PointRend: Image Segmentation as Rendering, CVPR 2020 oral
7. TensorMask: A Foundation for Dense Object Segmentation, ICCV 2019
8. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation, CVPR 2020
9. CenterMask: single shot instance segmentation with point representation, CVPR 2020
10. MEInst: Mask Encoding for Single Shot Instance Segmentation, CVPR 2020)
11. CondInst: Conditional Convolutions for Instance Segmentation, Arxiv 03/2020
12. Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR 2019
13. FCOS: Fully Convolutional One-Stage Object Detection, ICCV 2019
14. Mask R-CNN, ICCV 2017 Best paper
15. PANet: Path Aggregation Network for Instance Segmentation, CVPR 2018
16. Mask Scoring R-CNN, CVPR 2019
17. InstanceFCN: Instance-sensitive Fully Convolutional Networks, ECCV 2016)
18. FCIS: Fully Convolutional Instance-aware Semantic Segmentation, CVPR 2017
19. FCN: Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
20. CoordConv: An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, NeurIPS 2018
21. Associative Embedding: End-to-End Learning for Joint Detection and Grouping, NeuRIPS 2017
22. SpatialEmbedding: Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth, ICCV 2019
作者:Patrick Langechuan Liu
編譯:CV技術指南
原文鏈接://towardsdatascience.com/single-stage-instance-segmentation-a-review-1eeb66e0cc49
本文來自公眾號CV技術指南的
歡迎關注公眾號 CV技術指南 ,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「技術總結」可獲取公眾號原創技術總結文章的匯總pdf。

![]()
其它文章


