Semi-supervised semantic segmentation needs strong, varied perturbations
論文閱讀:
Semi-supervised semantic segmentation needs strong, varied perturbations
作者聲明
版權聲明:本文為博主原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接和本聲明。
原文鏈接:鳳⭐塵 》》//www.cnblogs.com/phoenixash/p/15379232.html
基本信息
\1.標題:Semi-supervised semantic segmentation needs strong, varied perturbations
\2.作者:Geoff French, Samuli Laine, Timo Aila, Michal Mackiewicz, Graham Finlayson
\3.作者單位:\(^1School\ of\ Computing\ Sciences\ University\ of\ East\ Anglia\ Norwich,\ UK \\^2\ NVIDIA Helsinki,\ Finland\)
\4.發表期刊/會議:BMVC
\5.發表時間:2020
\6.原文鏈接://arxiv.org/abs/1906.01916
Abstract
一致性正則化描述了在半監督分類問題中產生突破性結果的一類方法。先前的工作已經建立了一類假設,在這種假設下,數據分佈是由通過低密度區域分離的樣本組成的均勻類聚類,這對其成功是非常重要的。我們分析了語義分割的問題,發現它的分佈並沒有顯示出低密度的區域來區分類,這就解釋了為什麼半監督分割是一個具有挑戰性的問題,只有很少的成功報告。然後,我們確定增強的選擇是在沒有這樣的低密度區域的情況下獲得可靠的性能的關鍵。我們發現,最近提出的CutOut和CutMix增強技術的改進變種在標準數據集中產生了最先進的半監督語義分割結果。此外,鑒於語義分割具有挑戰性的本質,我們提出將語義分割作為評估半監督正則化器的有效acid test測試。 Implementation at: //github.com/Britefury/cutmix-semisup-seg.
1.Introduction
半監督學習提供了一個誘人的前景,即使用只有一小部分樣本有標籤的數據集來訓練機器學習模型。這些情況經常出現在實際的計算機視覺問題中,因為大量的圖像是現成的,由於成本和勞動力的需要,真值標註成為一個瓶頸。一致性正則化[19,25,26,32]描述了一類半監督學習算法,這些算法在半監督分類中產生了最先進的結果,同時概念簡單,通常易於實現。關鍵的想法是鼓勵網絡對以各種方式受到干擾的無標記輸入給出一致的預測。
一致性正則化的有效性通常歸因於平滑假設[23]或聚類假設[5,31,33,37]。平滑假設表明,彼此接近的樣本可能具有相同的標籤。聚類假設是平滑假設的一種特殊情況,認為決策曲面應該位於數據分佈的低密度區域。這通常適用於分類任務,因為迄今為止大多數成功的一致性正則化方法已經被報道出來。
在較高的層次上,語義分割就是分類,每個像素根據其鄰域進行分類。因此,有趣的是,在醫學成像領域,只有兩份一致性正則化成功應用於分割的報告[21,28],而沒有一份應用於自然場景圖像的報告。我們觀察到,即使中心像素的類別發生變化,以相鄰像素為中心的\(L^2\)像素含量距離之間的小塊也會平滑變化,因此在類邊界上不存在低密度區域。這一令人震驚的觀察結果促使我們研究在這些情況下,允許一致性正則化操作的條件。
我們發現基於掩模的增強策略對半監督語義分割是有效的,一種適應的CutMix[45]變體實現了顯著的收益。
本文的主要貢獻在於分析了語義分割的數據分佈和方法的簡便性。我們利用了經過嘗試和測試的半監督學習方法,並採用了CutMix一種監督分類的增強技術進行半監督學習和分割,取得了最先進的結果。
2.Background
我們的工作涉及三個領域的現有技術:最近的分類正則化技術,專註於一致性正則化的半監督分類,以及語義分割。
2.1 MixUp, Cutout, and CutMix
Zhang等人[40]的MixUp正則化器通過在訓練過程中使用插值樣本提高了有監督圖像、語音和表格數據分類器的性能。兩個隨機選擇的樣本的輸入和目標標籤使用一個隨機選擇的因子進行混合。
Devries等人[11]的Cutout正則化器通過將矩形區域掩蔽為零來增強圖像。Yun等人最近提出的[39]CutMix正則化器結合了MixUp和CutOut的各個方面,從圖像B中切割出一個矩形區域,並將其粘貼到圖像a上。MixUp、CutOut和CutMix提高了監督分類性能,其中CutMix優於其他兩個。
2.2 Semi-supervised classification
文獻中提出了多種基於一致性正則化的半監督分類方法。他們通常將標準監督損失項(例如交叉熵損失)與非監督一致性損失項結合起來,以鼓勵對應用於非監督樣本的擾動作出一致預測。
Laine等人[19]的Π-model將每個未標記樣本通過分類器兩次,應用隨機增廣過程的兩種實現,並使所得到的類別概率預測之間的平方差最小。他們的時間模型和Sajjadi等人[32]的模型鼓勵當前預測和歷史預測之間的一致性。Miyato等人的[25]將隨機增廣替換為對抗方向,從而將擾動向決策邊界瞄準。
Tarvainen等人[36]的平均教師模型鼓勵學生網絡預測和教師網絡預測之間的一致性,其中教師網絡的權重是學生網絡的指數移動平均[29]。[13]採用均值教師進行域適應。
無監督數據增強(UDA)模型[38]和最先進的FixMatch模型[34]展示了豐富的數據增強的好處,因為它們都結合了CutOut[11]和RandAugment [10] (UDA)或CTAugment [3] (FixMatch)。RandAugment和CTAugment從14種圖像增強中提取。
Verma等人[37]和MixMatch[4]的插值一致性訓練(ICT)結合了MixUp[40]和一致性正則化。ICT使用平均教師模型,並將MixUp應用於無監督樣本,將輸入圖像與教師類預測混合,產生混合輸入和目標,以訓練學生模型。
2.3 Semantic segmentation
大多數語義分割網絡將圖像分類器轉換為一個完全卷積的網絡,生成一組密集的預測,用於重疊輸入窗口,分割任意大小[22]的輸入圖像。DeepLab v3[7]架構通過結合atrous卷積和空間金字塔池化來提高定位精度。解碼器網絡[2,20,30]使用跳躍連接將像編碼器一樣的圖像分類器連接到解碼器。編碼器逐漸對輸入進行向下採樣,而解碼器則向上採樣,從而產生分辨率與輸入相匹配的輸出。
許多半監督語義分割方法使用額外的數據。Kalluri等人的[17]使用來自不同領域的兩個數據集的數據,最大化每個數據集的類嵌入之間的相似性。Stekovic等人的[35]使用深度圖像和三維場景的多個視圖之間的強制幾何約束。
在嚴格的半監督環境下操作的方法相對較少。Hung等人[16]和Mittal等人[24]採用基於GSN的對抗學習,使用鑒別器網絡區分真實和預測的分割圖來指導學習。
據我們所知,一致性正則化在分割中的唯一成功應用來自醫學成像領域;Perone等人[28]和Li等人[21]分別對MRI體積數據集和皮膚病變應用一致性正則化。兩種方法都使用標準增廣來提供擾動。
3.Consistency regularization for semantic segmentation
一致性正則化將一致性損失項\(L_{cons}\)添加到在訓練過程中被最小化[26]的損失中。在分類任務中,\(L_{cons}\)衡量了將神經網絡\(f_θ\)應用於非監督樣本\(x\)與同一樣本的擾動版本\(\hat{x}\)的預測結果之間的距離\(d(·,·)\),即\(L_{cons} = d(f_θ (x), f_θ (\hat{x}))\)。用於生成\(\hat{x}\)的擾動依賴於所使用的一致性正則化的變體。使用了多種距離度量\(d(·,·)\),例如距離的平方[19]或交叉熵[25]。
Athiwaratkun等人[1]的形式分析支持了聚類假設的好處。他們分析了一個簡化的Π-model[19](使用加性各向同性高斯噪聲擾動(\(\hat{x} = x+εN(0,1)))\),發現\(L_{cons}\)的期望值與網絡輸出的雅可比矩陣\(J_{f_θ} (x)\)相對於輸入的平方大小近似成正比。因此,最小化\(L_{cons}\)可以平滑無監督樣本附近的決策函數,將決策邊界及其周圍的高梯度區域移動到低樣本密度的區域。
3.1 Why semi-supervised semantic segmentation is challenging
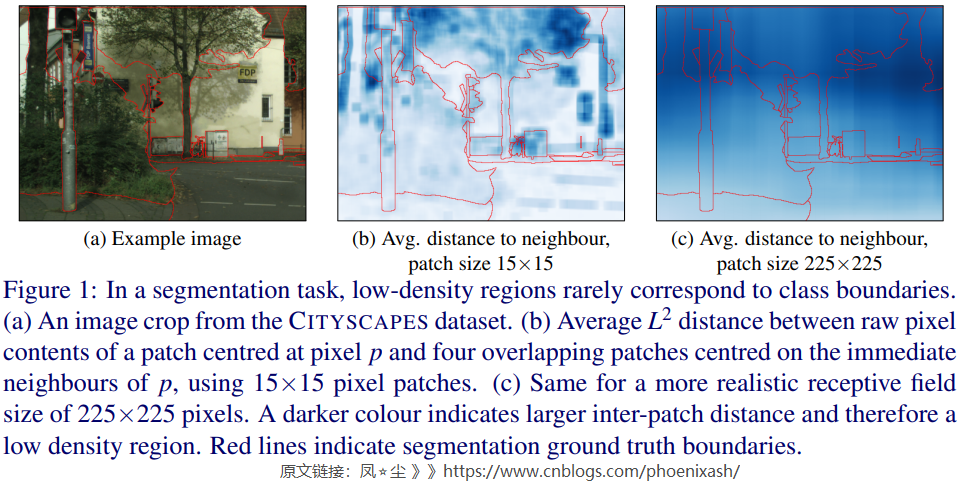
我們將語義分割視為滑動窗口patch分類,目標是識別patch中心像素的類別。鑒於之前的工作[19,25,34]對原始像素(輸入)空間應用了擾動,我們對數據分佈的分析集中在圖像小塊的原始像素內容,而不是來自網絡內部的更高層次的特徵。
我們將一致性正則化在自然圖像語義分割問題上的罕見成功歸因於輸入數據中的低密度區域不能很好地與類邊界對齊。這種低密度區域的存在將表現為局部地大於類邊界兩側相鄰像素為中心的patch之間的平均\(L^2\)距離。在圖1中,我們可視化了相鄰patch之間的\(L^2\) 距離。當使用一個合理的接受域如圖1(c)所示我們可以看到集群假設顯然是違反了:一個像素接受域的原始像素內容與相鄰像素接受域內容的差異與patch中心像素是否屬於同一類無關。
從信號處理的角度很容易解釋patch級別距離的缺乏變化。大小HxW的patch,以所有水平相鄰像素對為中心的重疊patch像素含量之間\(L^2\)距離的距離圖可以寫成\(\sqrt{\left(\Delta_{\mathrm{X}} I\right)^{\circ 2} * 1^{H \times W}}\),其中*表示卷積和\(\Delta_{\mathbf{x}}I\)表示水平梯度的輸入圖像\(I\)。因此,元素級別的平方梯度圖像通過HxW盒形濾波器進行低通濾波,它抑制了圖像高頻成分中的精細細節,導致圖像上平滑變化的樣本密度。
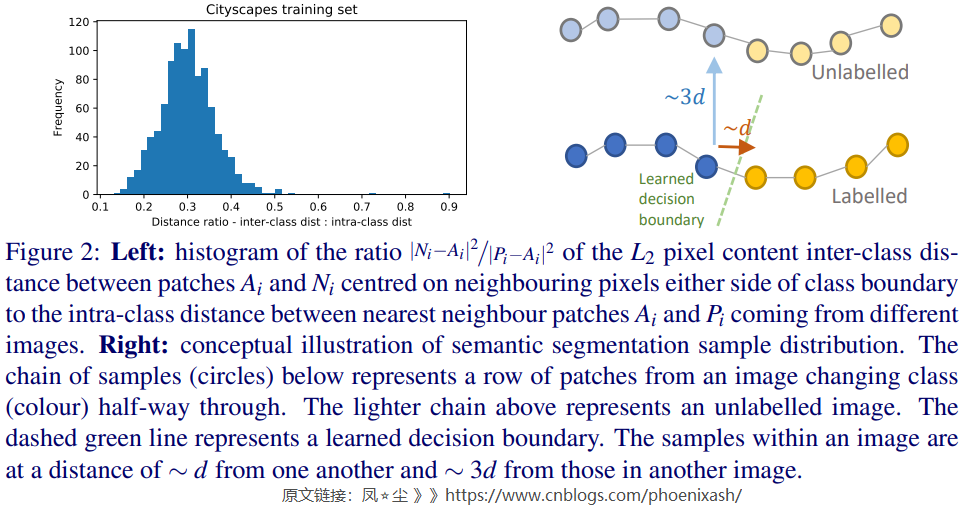
在歸納到其他圖像時,我們對CITYSCAPES數據集的分析量化了在應該屬於不同類別的兩個相鄰像素之間設置決策邊界所涉及的挑戰。我們發現,以類邊界兩邊像素為中心的patch之間的\(L^2\) 距離大約是同一類在不同圖像中最近patch距離的1/3(見圖2)。這表明,精確定位和取向的決策邊界對於良好的性能至關重要。我們在補充材料中進一步詳細討論我們的分析。

3.2 Consistency regularization without the cluster assumption
當考慮在我們上面分析的背景下,成功應用的幾個報告的一致性正規化語義分割尤其是李et al。[21]的工作使我們得出這樣的結論:低密度區域的存在對類分離是非常有益的,但不是必要的。因此,我們提出了一種替代機制:即使用非各向同性的自然擾動,如圖像增強,來約束決策邊界的方向,使其與擾動的方向平行(見Athiwaratkun等人[1]的附錄)。我們現在將使用一個2D玩具的例子來探索這個問題。
圖3a用一個簡單的2D玩具均值教師實驗說明了聚類假設的好處,在這個實驗中,聚類假設成立是因為屬於兩個不同類別的無監督樣本之間存在一個間隙。\(L_{conf}\)使用的擾動是對兩個坐標的各向同性高斯偏移,正如預期的那樣,學習到的決策邊界在兩個集群之間整齊地確定。在圖3b中,無監督樣本是均勻分佈的,違反了聚類假設。在這種情況下,一致性的損失弊大於利;即使它成功地使決策函數的鄰域變平,它也跨越了真正的類邊界。
在圖3c中,我們繪製了到真正類邊界的距離的輪廓。如果我們約束應用於樣本x的擾動,使擾動\(\hat{x}\)位於或非常接近通過x的距離輪廓上,得到的學習決策邊界與真實的類邊界很好地對齊,如圖3d所示。當低密度區域不存在時,必須仔細選擇擾動,使跨越類邊界的概率最小化。
我們認為可靠的半監督分割是可以實現的,前提是增強/擾動機制遵循以下準則:1)擾動必須多樣和高維的以充分約束自然圖像的高維空間的邊界的方向決定,2)與其他維度的探索相比,擾動跨越真實類邊界的概率一定非常小,3)擾動輸入應該是可信的;它們不應遠遠超出各種實際投入。
經典的基於增強的擾動,如裁剪、縮放、旋轉和顏色變化,混淆輸出類的幾率很小,並且已被證明是對自然圖像分類的有效方法[19,36]。儘管該方法在一些醫學圖像分割問題上取得了積極的結果[21,28],但令人驚訝的是,它在自然圖像上卻無效。這促使我們為半監督語義分割尋找更強、更多樣化的增強方法。
3.3 CutOut and CutMix for semantic segmentation
在UDA[38]和FixMatch[34]中,Cutout[11]在半監督分類中產生了很強的結果。UDA消融研究表明,Cutout在半監督性能中貢獻了大部分,而FixMatch消融表明,Cutout可以匹配CTAugment使用的14個圖像操作組合的效果。DeVries等人[11]認為,Cutout鼓勵網絡利用更廣泛的特徵,以克服當前或屏蔽圖像各部分的變化組合。這種由Cutout引入的多樣性表明,它是一個很有前途的分割候選項。
鑒於MixUp已經成功地用於ICT[37]和MixMatch[4]的半監督分類,我們建議使用CutMix以類似的方式混合無監督樣本和相應的預測。 如2.1節所述,CutMix結合了Cutout和MixUp,使用一個矩形蒙版來混合輸入圖像。鑒於MixUp已經成功地用於ICT[37]和MixMatch[4]的半監督分類,我們建議使用CutMix以類似的方式混合無監督樣本和相應的預測。
對比Π-model[19]和均值教師模型[36]的初步實驗表明,使用均值教師模型是提高語義切分性能的關鍵,因此本文的所有實驗都使用均值教師框架。我們將學生網絡表示為\(f_θ\),教師網絡表示為\(g_φ\)。
Cutout. 在[11]中,我們用1初始化一個蒙版M,並將隨機選擇的矩形內的像素設置為0。為了在語義分割任務中應用cutout,我們用 M 屏蔽輸入像素,並忽略被 M 屏蔽為 0 的像素的一致性損失。 FixMatch [34] 使用由裁剪和翻轉組成的弱增強方案來預測用作使用強 CTAugment 方案增強的樣本的目標的偽標籤 。同樣,我們認為Cutout是一種強增強形式,因此我們將教師網絡\(g_φ\)應用於原始圖像生成偽目標,用於訓練學生\(f_θ\)。以距離的平方為度量,我們得到\(L_{cons} = ||M\odot(f_θ (M\odot x) g_φ (x))||^2\),其中\(\odot\)為元素積。
CutMix. CutMix 需要兩個輸入圖像,我們將它們表示為 \(x_a\) 和 \(x_b\),我們將它們與掩碼 M 混合。參照 ICT ([37]) ,我們混合了教師網絡對輸入圖像的預測 \(g_φ (x_a),g_φ (x_b)\) 生成偽標籤,用於學生網絡對混合圖像的預測。 為了簡化符號,讓我們定義函數 \(mix(a,b,M) = (1− M)\odot a+ M\odot b\) ,它根據掩碼 M 選擇輸出像素。 我們現在可以將一致性損失寫為:
\]
用於分類的Cutout[11]的原始公式使用一個固定尺寸和寬高比的矩形,其中心隨機定位,允許部分矩形位於圖像邊界之外。CutMix[39]隨機改變大小,但使用固定的縱橫比。對於分割,我們使用CutOut獲得了更好的性能,通過隨機選擇大小和寬高比,並定位矩形,使其完全位於圖像內。相比之下,通過將矩形的面積固定為圖像面積的一半,同時改變長寬比和位置,CutMix的性能得到了最大化。
雖然Cutout和CutMix應用的增強效果並不會出現在現實生活中的圖像中,但從視覺角度來看,它們是合理的。分割網絡通常使用圖像crop而不是完整的圖像來訓練,所以用Cutout來分割圖像的一段可以看作是逆操作。使用CutMix的效果是將一個矩形區域從一個圖像粘貼到另一個圖像上,類似地產生一個合理的分割任務。
在我們的補充材料中說明了基於Cutout和Cutmix的一致性損失。


