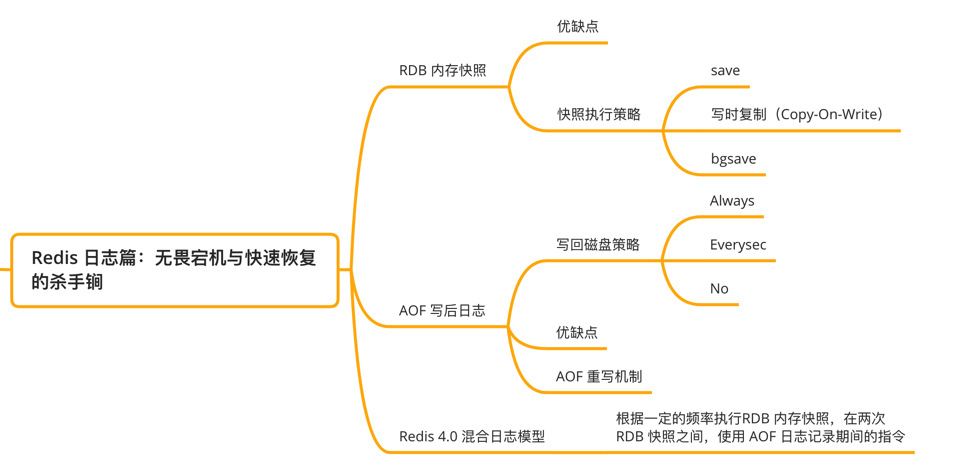
Redis 日誌篇:無畏宕機快速恢復的殺手鐧
特立獨行是對的,融入圈子也是對的,重點是要想清楚自己嚮往怎樣的生活,為此願意付出怎樣的代價。
我們通常將 Redis 作為緩存使用,提高讀取響應性能,一旦 Redis 宕機,內存中的數據全部丟失,假如現在直接訪問數據庫大量流量打到 MySQL 可能會帶來更加嚴重的問題。
另外慢慢的從數據庫讀取放到 Redis 性能必然比不過從 Redis 獲取快,也會導致響應變慢。
Redis 為了實現無畏宕機快速恢復,設計了兩大殺手鐧,分別是 AOF(Append Only FIle)日誌和 RDB 快照。
學習一個技術,通常只接觸了零散的技術點,沒有在腦海里建立一個完整的知識框架和架構體系,沒有系統觀。這樣會很吃力,而且會出現一看好像自己會,過後就忘記,一臉懵逼。
跟着「碼哥位元組」一起吃透 Redis,深層次的掌握 Redis 核心原理以及實戰技巧。搭建一套完整的知識框架,學會全局觀去整理整個知識體系。
本文硬核,建議收藏點贊,靜下心來閱讀,我相信都會有很多收穫。
上一篇《Redis 核心篇:唯快不破的秘密》分析了 Redis 的核心數據結構、IO 模型、線程模型、根據不同數據使用合適的數據編碼。深層次掌握真正快的原因!
本篇將圍繞如下幾點展開:
- 宕機後,如何快速恢復?
- 宕機了,Redis 如何避免數據丟失?
- 什麼是 RDB 內存快照?
- AOF 日誌實現機制
- 什麼是 寫時複製技術?
- ….
涉及的知識點如圖所示:
Redis 全景圖
全景圖可以圍繞兩個維度展開,分別是:
應用維度:緩存使用、集群運用、數據結構的巧妙使用
系統維度:可以歸類為三高
- 高性能:線程模型、網絡 IO 模型、數據結構、持久化機制;
- 高可用:主從複製、哨兵集群、Cluster 分片集群;
- 高拓展:負載均衡
Redis 系列篇章圍繞如下思維導圖展開,這次一起探索 Redis 的高性能、持久化機制的秘密。
擁有全景圖,掌握系統觀。
系統觀其實是至關重要的,從某種程度上說,在解決問題時,擁有了系統觀,就意味着你能有依據、有章法地定位和解決問題。
RDB 內存快照,讓宕機快速恢復
65 哥:Redis 因為某些原因宕機了,會導致所有的流量會打到後端 MySQL,我立馬重啟 Redis,可是它的數據存在內存裏面,重啟後如何還是沒有任何數據,如何防止重啟數據丟失呢?
65 哥別急,「碼哥位元組」帶你一步步深入理解到底 Redis 宕機後如何快速恢復的。
Redis 數據存儲在內存中,是否可以考慮將內存中的數據寫到磁盤上呢?當 Redis 重啟的時候就把保存在磁盤上的數據快速恢復到內存中,這樣就能實現重啟後正常提供服務了。
65 哥:我想到一個方案,每次執行「寫」操作操作內存的同時寫入到磁盤
這個方案有一個致命問題:每次寫指令不僅寫內存還是寫入磁盤,磁盤的性能相對內存太慢,會導致 Redis 性能大大降低。
內存快照
65 哥:那如何規避這個同時寫入的問題呢?
我們通常將 Redis 當作緩存使用,所以即使 Redis 沒有保存全部數據,還可以通過數據庫獲取,所以 Redis 不會保存所有的數據, Redis 的數據持久化使用了「RDB 數據快照」的方式來實現宕機快速恢復。
65 哥:那什麼是 RDB 內存快照呢?
在 Redis 執行「寫」指令過程中,內存數據會一直變化。所謂的內存快照,指的就是 Redis 內存中的數據在某一刻的狀態數據。
好比時間定格在某一刻,當我們拍照的,通過照片就能把某一刻的瞬間畫面完全記錄下來。
Redis 跟這個類似,就是把某一刻的數據以文件的形式拍下來,寫到磁盤上。這個快照文件叫做 RDB 文件,RDB 就是 Redis DataBase 的縮寫。
Redis 通過定時執行 RDB 內存快照,這樣就不必每次執行「寫」指令都寫磁盤,只需要在執行內存快照的時候寫磁盤。既保證了唯快不破,還實現了持久化,宕機快速恢復。
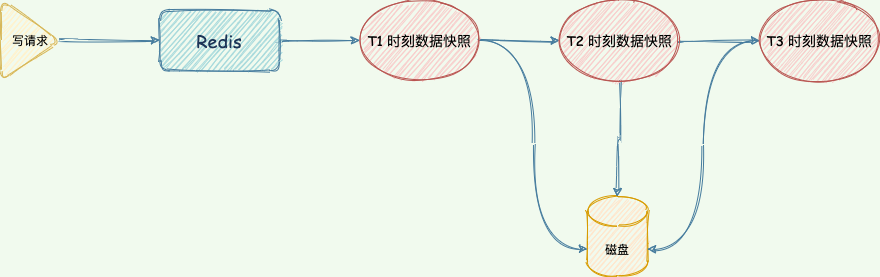
在做數據恢復時,直接將 RDB 文件讀入內存完成恢復。
65 哥:對哪些數據做快照呢?或者多久做一次快照呢?這個會影響快照的執行效率。
65 哥不錯呀,開始考慮數據效率問題了。在《Redis 核心篇:唯快不破的秘密》中我們知道他的單線程模型決定了我們要儘可能的避免會阻塞主線程的操作,避免 RDB 文件生成阻塞主線程。
生成 RDB 策略
Redis 提供了兩個指令用於生成 RDB 文件:
- save: 主線程執行,會阻塞;
- bgsave:調用 glibc 的函數
fork產生一個子進程用於寫入 RDB 文件,快照持久化完全交給子進程來處理,父進程繼續處理客戶端請求,生成 RDB 文件的默認配置。
65 哥:那在對內存數據做「快照」的時候,內存數據還能修改么?也就是寫指令能否正常處理?
首先我們要明確一點,避免阻塞和 RDB 文件生成期間能處理寫操作不是一回事。雖然主線程沒有阻塞,到那時為了保證快照的數據的一致性,只能處理讀操作,不能修改正在執行快照的數據。
很明顯,為了生成 RDB 而暫停寫操作,Redis 是不答應的。
65 哥:那 Redis 如何實現一邊處理寫請求,同時生成 RDB 文件呢?
Redis 使用操作系統的多進程寫時複製技術 COW(Copy On Write) 來實現快照持久化,這個機制很有意思,也很少人知道。多進程 COW 也是鑒定程序員知識廣度的一個重要指標。
Redis 在持久化時會調用 glibc 的函數fork產生一個子進程,快照持久化完全交給子進程來處理,父進程繼續處理客戶端請求。
子進程剛剛產生時,它和父進程共享內存裏面的代碼段和數據段。這時你可以將父子進程想像成一個連體嬰兒,共享身體。
這是 Linux 操作系統的機制,為了節約內存資源,所以儘可能讓它們共享起來。在進程分離的一瞬間,內存的增長几乎沒有明顯變化。
bgsave 子進程可以共享主線程的所有內存數據,讀取主線程的數據並寫入到 RDB 文件。
在執行 SAVE 命令或者BGSAVE命令創建一個新的 RDB 文件時,程序會對數據庫中的鍵進行檢查,已過期的鍵不會被保存到新創建的 RDB 文件中。
當主線程執行寫指令修改數據的時候,這個數據就會複製一份副本, bgsave 子進程讀取這個副本數據寫到 RDB 文件,所以主線程就可以直接修改原來的數據。
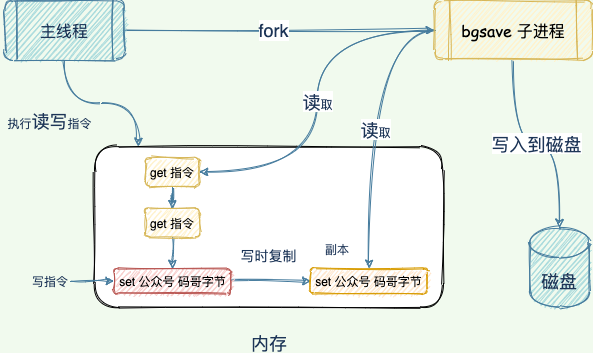
這既保證了快照的完整性,也允許主線程同時對數據進行修改,避免了對正常業務的影響。
Redis 會使用 bgsave 對當前內存中的所有數據做快照,這個操作是子進程在後台完成的,這就允許主線程同時可以修改數據。
65 哥:那可以每秒都執行 RDB 文件么,這樣即使發生宕機最多丟失 1 秒的數據。
過於頻繁的執行全量數據快照,有兩個嚴重性能開銷:
- 頻繁生成 RDB 文件寫入磁盤,磁盤壓力過大。會出現上一個 RDB 還未執行完,下一個又開始生成,陷入死循環。
- fork 出 bgsave 子進程會阻塞主線程,主線程的內存越大,阻塞時間越長。
優缺點
快照的恢復速度快,但是生成 RDB 文件頻率不好把握,頻率過低宕機丟失的數據就會比較多;太快,又會消耗額外開銷。
RDB 採用二進制 + 數據壓縮的方式寫磁盤,文件體積小,數據恢復速度快。
Redis 除了 RDB 全量快照以外,還設計了 AOF 寫後日誌,接下來我們一起來聊下什麼是 AOF 日誌。
AOF 寫後日誌,避免宕機數據丟失
AOF 日誌存儲的是 Redis 服務器的順序指令序列,AOF 日誌只記錄對內存進行修改的指令記錄。
假設 AOF 日誌記錄了自 Redis 實例創建以來所有的修改性指令序列,那麼就可以通過對一個空的 Redis 實例順序執行所有的指令,也就是「重放」,來恢復 Redis 當前實例的內存數據結構的狀態。
寫前與寫後日誌對比
寫前日誌(Write Ahead Log, WAL): 在實際寫數據之前,將修改的數據寫到日誌文件中,故障恢復得以保證。
比如 MySQL Innodb 存儲引擎 中的 redo log(重做日誌)便是記錄修改的數據日誌,在實際修改數據前先記錄修改日誌在執行修改數據。
寫後日誌: 先執行「寫」指令請求,將數據寫入內存,再記錄日誌。
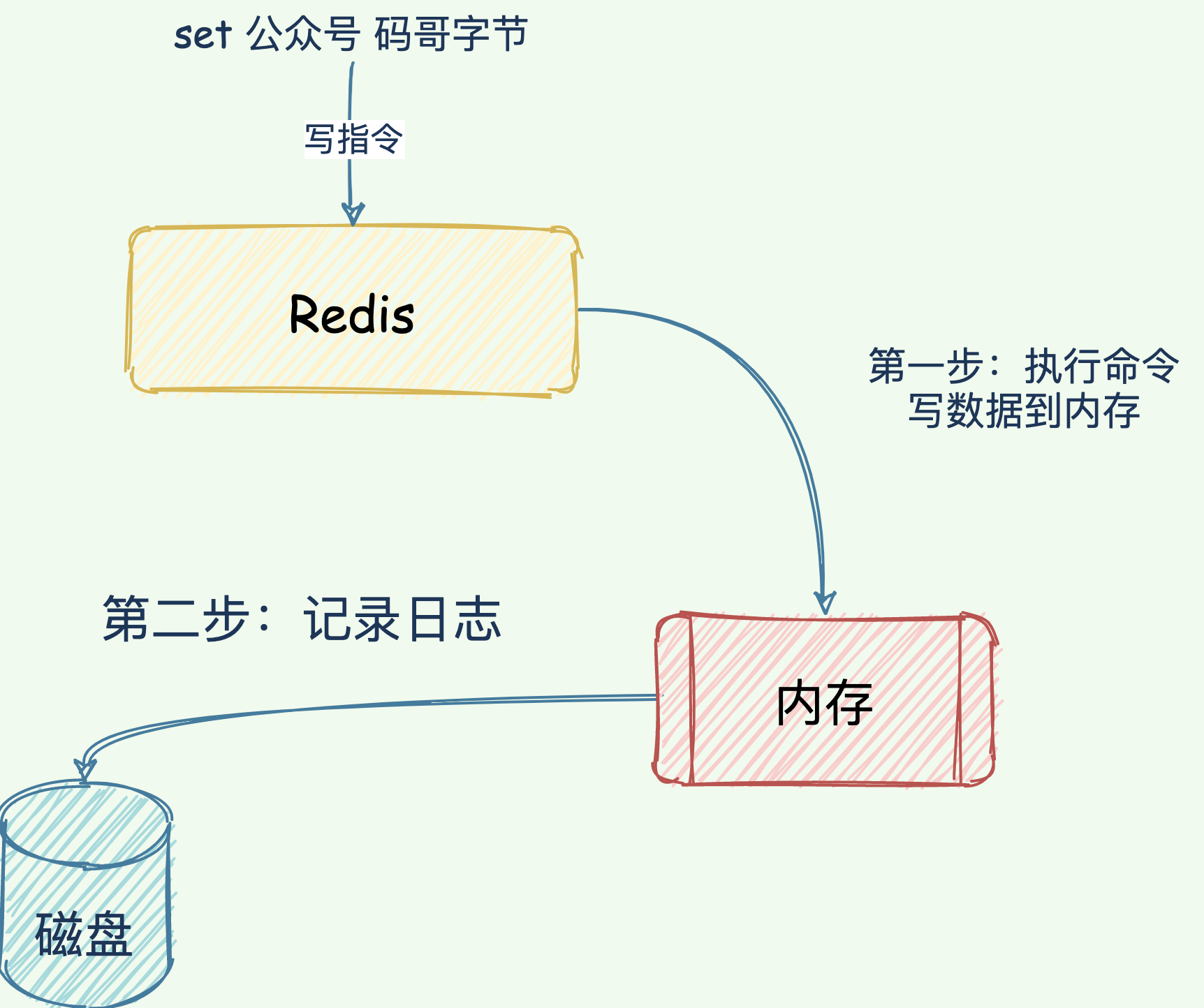
日誌格式
當 Redis 接受到 「set key MageByte」命令將數據寫到內存後,Redis 會按照如下格式寫入 AOF 文件。
- 「*3」:表示當前指令分為三個部分,每個部分都是 「$ + 數字」開頭,緊跟後面是該部分具體的「指令、鍵、值」。
- 「數字」:表示這部分的命令、鍵、值多佔用的位元組大小。比如 「$3」表示這部分包含 3 個位元組,也就是 「set」指令。

65 哥:為什麼 Redis 使用寫後日誌這種方式呢?
寫後日誌避免了額外的檢查開銷,不需要對執行的命令進行語法檢查。如果使用寫前日誌的話,就需要先檢查語法是否有誤,否則日誌記錄了錯誤的命令,在使用日誌恢復的時候就會出錯。
另外,寫後才記錄日誌,不會阻塞當前的「寫」指令執行。
65 哥:那有了 AOF 就萬無一失了么?
傻孩子,可沒這麼簡單。假如 Redis 剛執行完指令,還沒記錄日誌宕機了,就有可能丟失這個命令相關的數據。
還有,AOF 避免了當前命令的阻塞,但是可能會給下一個命令帶來阻塞的風險。AOF 日誌是主線程執行,將日誌寫入磁盤過程中,如果磁盤壓力大就會導致寫磁盤很慢,導致後續的「寫」指令阻塞。
發現了沒,這兩個問題與磁盤寫回有關,如果能合理的控制「寫」指令執行完後 AOF 日誌寫回磁盤的時機,問題就迎刃而解。
寫回策略
為了提高文件的寫入效率,當用戶調用 write 函數,將一些數據寫入到文件的時候,操作系統通常會將寫入數據暫時保存在一個內存緩衝區裏面,等到緩衝區的空間被填滿、或者超過了指定的時限之後,才真正地將緩衝區中的數據寫入到磁盤裏面。
這種做法雖然提高了效率,但也為寫入數據帶來了安全問題,因為如果計算機發生停機,那麼保存在內存緩衝區裏面的寫入數據將會丟失。
為此,系統提供了fsync和fdatasync兩個同步函數,它們可以強制讓操作系統立即將緩衝區中的數據寫入到硬盤裏面,從而確保寫入數據的安全性。
Redis 提供的 AOF 配置項appendfsync寫回策略直接決定 AOF 持久化功能的效率和安全性。
- always:同步寫回,寫指令執行完畢立馬將
aof_buf緩衝區中的內容刷寫到 AOF 文件。 - everysec:每秒寫回,寫指令執行完,日誌只會寫到 AOF 文件緩衝區,每隔一秒就把緩衝區內容同步到磁盤。
- no: 操作系統控制,寫執行執行完畢,把日誌寫到 AOF 文件內存緩衝區,由操作系統決定何時刷寫到磁盤。
沒有兩全其美的策略,我們需要在性能和可靠性上做一個取捨。
always同步寫回可以做到數據不丟失,但是每個「寫」指令都需要寫入磁盤,性能最差。
everysec每秒寫回,避免了同步寫回的性能開銷,發生宕機可能有一秒位寫入磁盤的數據丟失,在性能和可靠性之間做了折中。
no操作系統控制,執行寫指令後就寫入 AOF 文件緩衝就可以執行後續的「寫」指令,性能最好,但是有可能丟失很多的數據。
65 哥:那我該如何選擇策略呢?
我們可以根據系統對高性能和高可靠性的要求,來選擇寫回策略。總結一下:想要獲得高性能,就選擇 No 策略;如果想要得到高可靠性保證,就選擇 Always 策略;如果允許數據有一點丟失,又希望性能別受太大影響的話,那麼就選擇 Everysec 策略。
優缺點
優點:執行成功才記錄日誌,避免了指令語法檢查開銷。同時,不會阻塞當前「寫」指令。
缺點:由於 AOF 記錄的是一個個指令內容,具體格式請看上面的日誌格式。故障恢復的時候需要執行每一個指令,如果日誌文件太大,整個恢復過程就會非常緩慢。
另外文件系統對文件大小也有限制,不能保存過大文件,文件變大,追加效率也會變低。
日誌過大:AOF 重寫機制
65 哥:AOF 日誌文件過大着怎麼辦?
AOF 寫前日誌,記錄的是每個「寫」指令操作。不會像 RDB 全量快照導致性能損耗,但是執行速度沒有 RDB 快,同時日誌文件過大也會造成性能問題,對於唯快不破的 Redis 這個真男人來說,絕對不能忍受日誌過大導致的問題。
所以,Redis 設計了一個殺手鐧「AOF 重寫機制」,Redis 提供了 bgrewriteaof指令用於對 AOF 日誌進行瘦身。
其原理就是開闢一個子進程對內存進行遍歷轉換成一系列 Redis 的操作指令,序列化到一個新的 AOF 日誌文件中。序列化完畢後再將操作期間發生的增量 AOF 日誌追加到這個新的 AOF 日誌文件中,追加完畢後就立即替代舊的 AOF 日誌文件了,瘦身工作就完成了。
65 哥:為啥 AOF 重寫機制能縮小日誌文件呢?
重寫機制有「多變一」功能,將舊日誌中的多條指令,在重寫後就變成了一條指令。
如下所示:
三條 LPUSH 指令,經過 AOF 重寫後生成一條,對於多次修改的場景,縮減效果更加明顯。
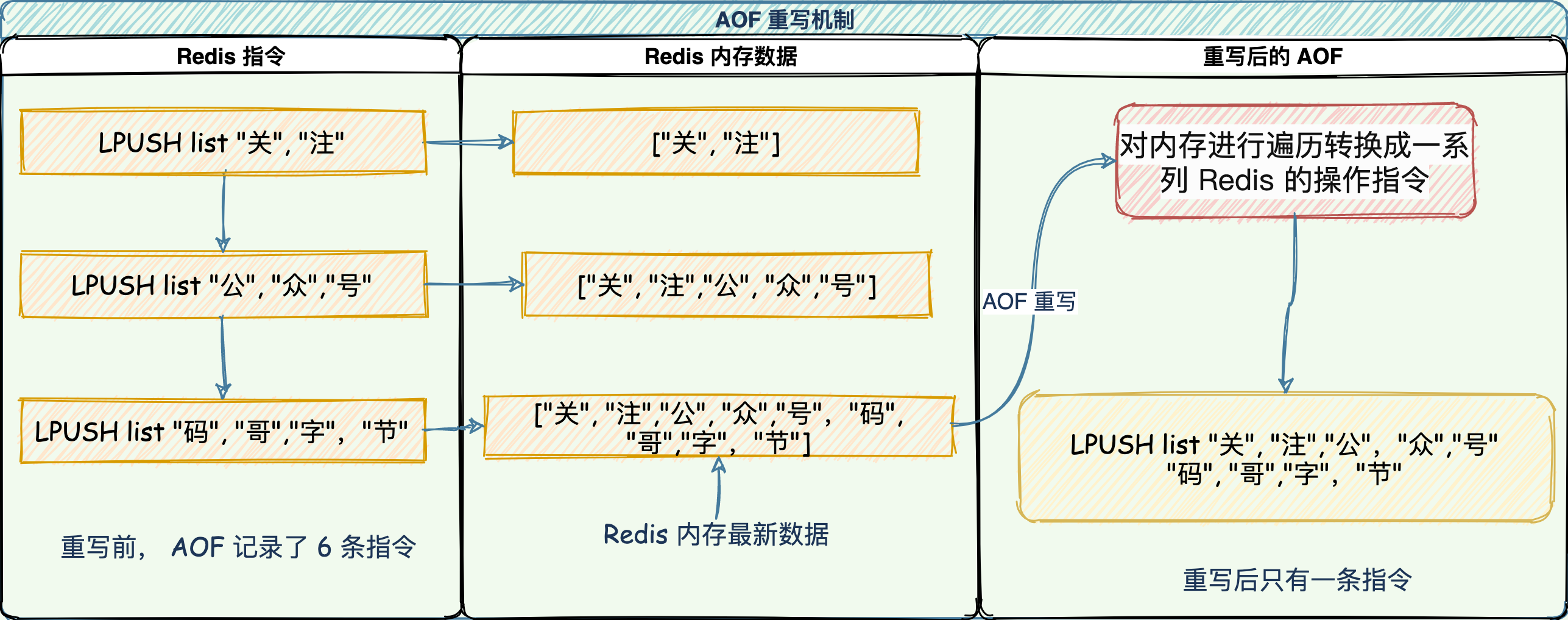
65 哥:重寫後 AOF 日誌變小,最後把整個數據庫最新數據的操作日誌刷寫到磁盤了。重寫會不會阻塞主線程呢?
「碼哥」上文說了,AOF 日誌是主線程寫回的,AOF 重寫的過程實際上後檯子進程 bgrewriteaof 完成,防止阻塞主線程。
重寫過程
和 AOF 日誌由主線程寫回不同,重寫過程是由後檯子進程 bgrewriteaof 來完成的,這也是為了避免阻塞主線程,導致數據庫性能下降。
總的來說,一共出現 兩個日誌,一次拷內存數據拷貝,分別是舊的 AOF 日誌和新的 AOF 重寫日誌和 Redis 數據拷貝。
Redis 會將重寫過程中的接收到的「寫」指令操作同時記錄到舊的 AOF 緩衝區和 AOF 重寫緩衝區,這樣重寫日誌也保存最新的操作。等到拷貝數據的所有操作記錄重寫完成後,重寫緩衝區記錄的最新操作也會寫到新的 AOF 文件中。
每次 AOF 重寫時,Redis 會先執行一個內存拷貝,用於遍曆數據生成重寫記錄;使用兩個日誌保證在重寫過程中,新寫入的數據不會丟失,並且保持數據一致性。
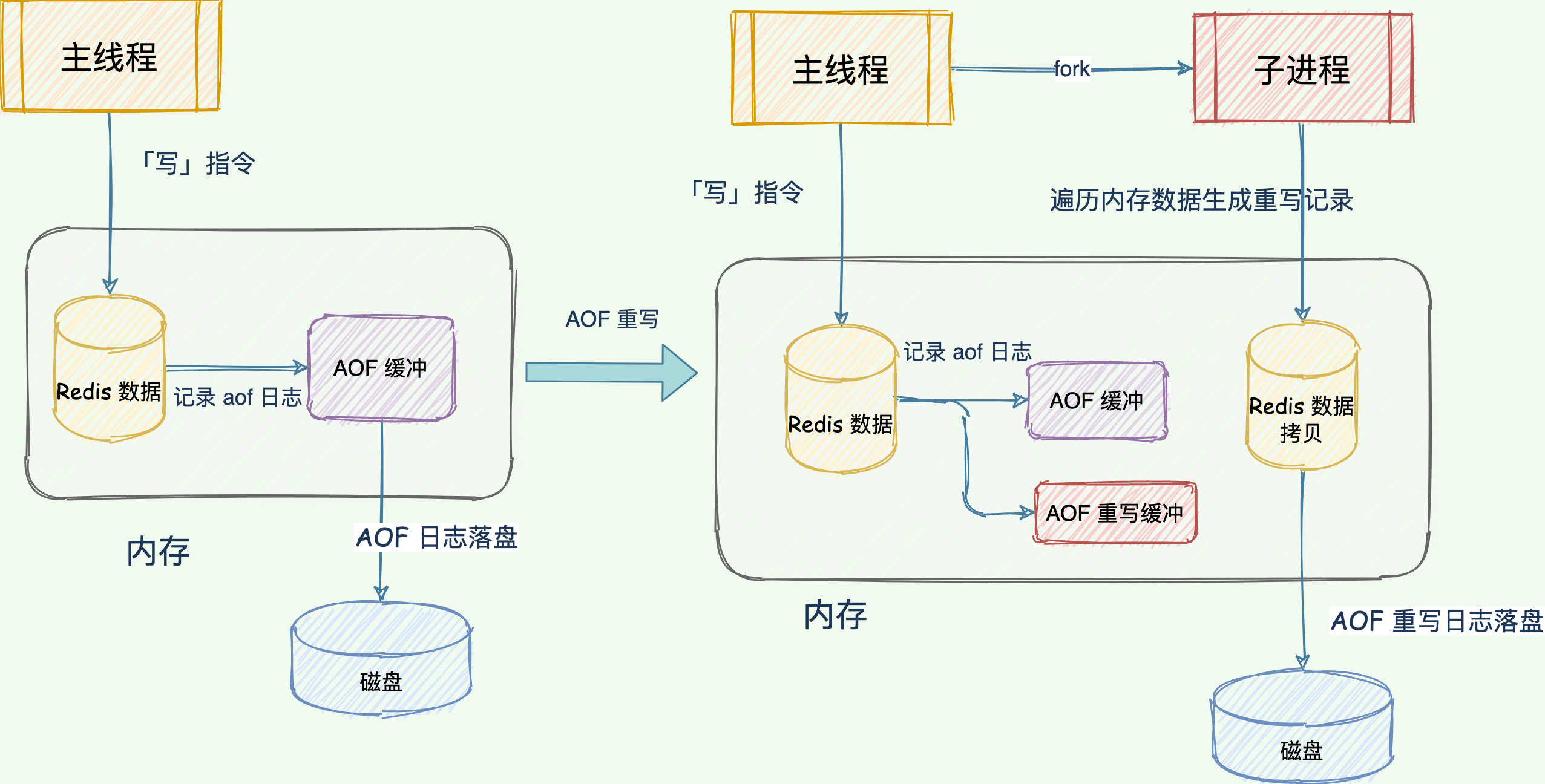
65 哥:AOF 重寫也有一個重寫日誌,為什麼它不共享使用 AOF 本身的日誌呢?
這個問題問得好,有以下兩個原因:
- 一個原因是父子進程寫同一個文件必然會產生競爭問題,控制競爭就意味着會影響父進程的性能。
- 如果 AOF 重寫過程中失敗了,那麼原本的 AOF 文件相當於被污染了,無法做恢復使用。所以 Redis AOF 重寫一個新文件,重寫失敗的話,直接刪除這個文件就好了,不會對原先的 AOF 文件產生影響。等重寫完成之後,直接替換舊文件即可。
Redis 4.0 混合日誌模型
重啟 Redis 時,我們很少使用 rdb 來恢復內存狀態,因為會丟失大量數據。我們通常使用 AOF 日誌重放,但是重放 AOF 日誌性能相對 rdb 來說要慢很多,這樣在 Redis 實例很大的情況下,啟動需要花費很長的時間。
Redis 4.0 為了解決這個問題,帶來了一個新的持久化選項——混合持久化。將 rdb 文件的內容和增量的 AOF 日誌文件存在一起。這裡的 AOF 日誌不再是全量的日誌,而是自持久化開始到持久化結束的這段時間發生的增量 AOF 日誌,通常這部分 AOF 日誌很小。
於是在 Redis 重啟的時候,可以先加載 rdb 的內容,然後再重放增量 AOF 日誌就可以完全替代之前的 AOF 全量文件重放,重啟效率因此大幅得到提升。
所以 RDB 內存快照以稍微慢一點的頻率執行,在兩次 RDB 快照期間使用 AOF 日誌記錄期間發生的所有「寫」操作。
這樣快照就不用頻繁的執行,同時由於 AOF 只需要記錄兩次快照之間發生的「寫」指令,不需要記錄所有的操作,避免出現文件過大的情況。
總結
Redis 設計了 bgsave 和寫時複製,儘可能避免執行快照期間對讀寫指令的影響,頻繁快照會給磁盤帶來壓力以及 fork 阻塞主線程。
Redis 設計了兩大殺手鐧實現了宕機快速恢復,數據不丟失。
避免日誌過大,提供了 AOF 重寫機制,根據數據庫的數據最新狀態,生成數據的寫操作作為新日誌,並且通過後台完成不阻塞主線程。
綜合 AOF 和 RDB 在 Redis 4.0 提供了新的持久化策略,混合日誌模型。在 Redis 重啟的時候,可以先加載 rdb 的內容,然後再重放增量 AOF 日誌就可以完全替代之前的 AOF 全量文件重放,重啟效率因此大幅得到提升。
最後,關於 AOF 和 RDB 的選擇問題,「碼 哥 字 節」有三點建議:
- 數據不能丟失時,內存快照和 AOF 的混合使用是一個很好的選擇;
- 如果允許分鐘級別的數據丟失,可以只使用 RDB;
- 如果只用 AOF,優先使用 everysec 的配置選項,因為它在可靠性和性能之間取了一個平衡。
經過兩篇 Redis 系列文章,讀者朋友們對 Redis 應該有一個全局認識。
下一篇「碼哥」將帶來一個實戰,《Redis 高可用篇:主從架構的奧秘》 實戰 + 原理呈現給大家!
敬請期待……
硬核好文
從 JMM 透析 volatile 與 synchronized 原理
關注「碼哥位元組」,每次都是炸裂硬核。閱讀後如有收穫請「點贊、分享、收藏」,謝謝支持.
讀者群已經開通,群里與各個大廠的大佬,不僅可以內推也可以學習。添加「碼哥」個人微信,回復「加群」一起成長!
鳴謝
redis 核心技術與實戰: //time.geekbang.org/column/intro/329
redis 深度歷險:核心原理與應用實踐: //juejin.cn/book/6844733724618129422/section/6844733724714614797
redis 設計與實踐: //weread.qq.com/web/reader/d35323e0597db0d35bd957bk73532580243735b90b45ac8


