應用開發中的存儲架構進化史——從起步到起飛
按樓主的經驗和知識,本文總結了應用開發中的各種存儲架構,從易到難,從起步到起飛。如有不對之處,歡迎留言。
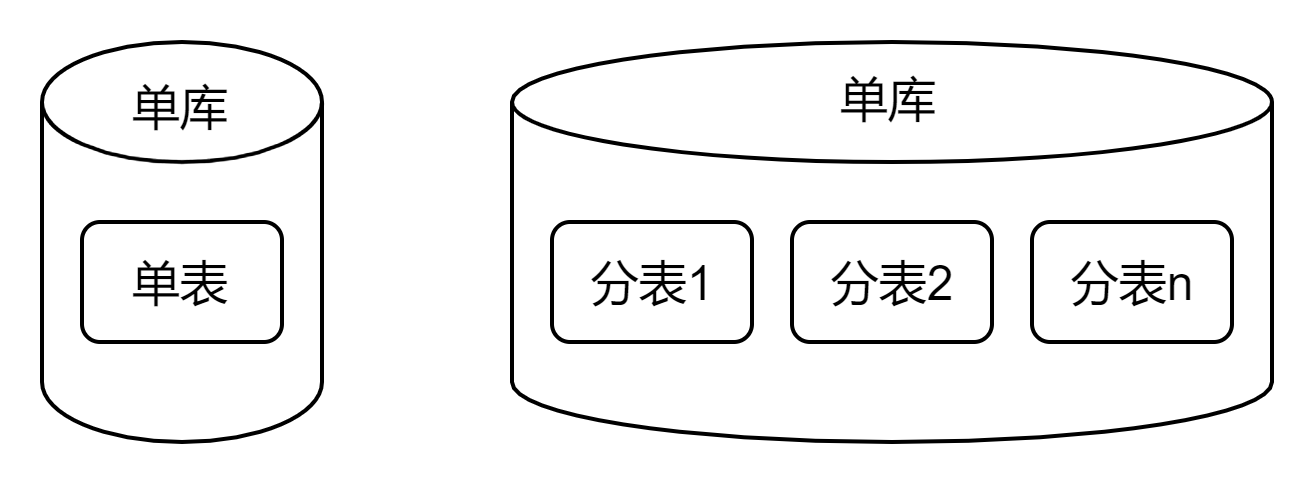
1、單庫
最簡單的初始架構,適用於千萬級以下的數據,並發量低的場景。
- 單庫、單表
- 或單庫、多個分表:之所以分表是為了給後續分庫做預留準備

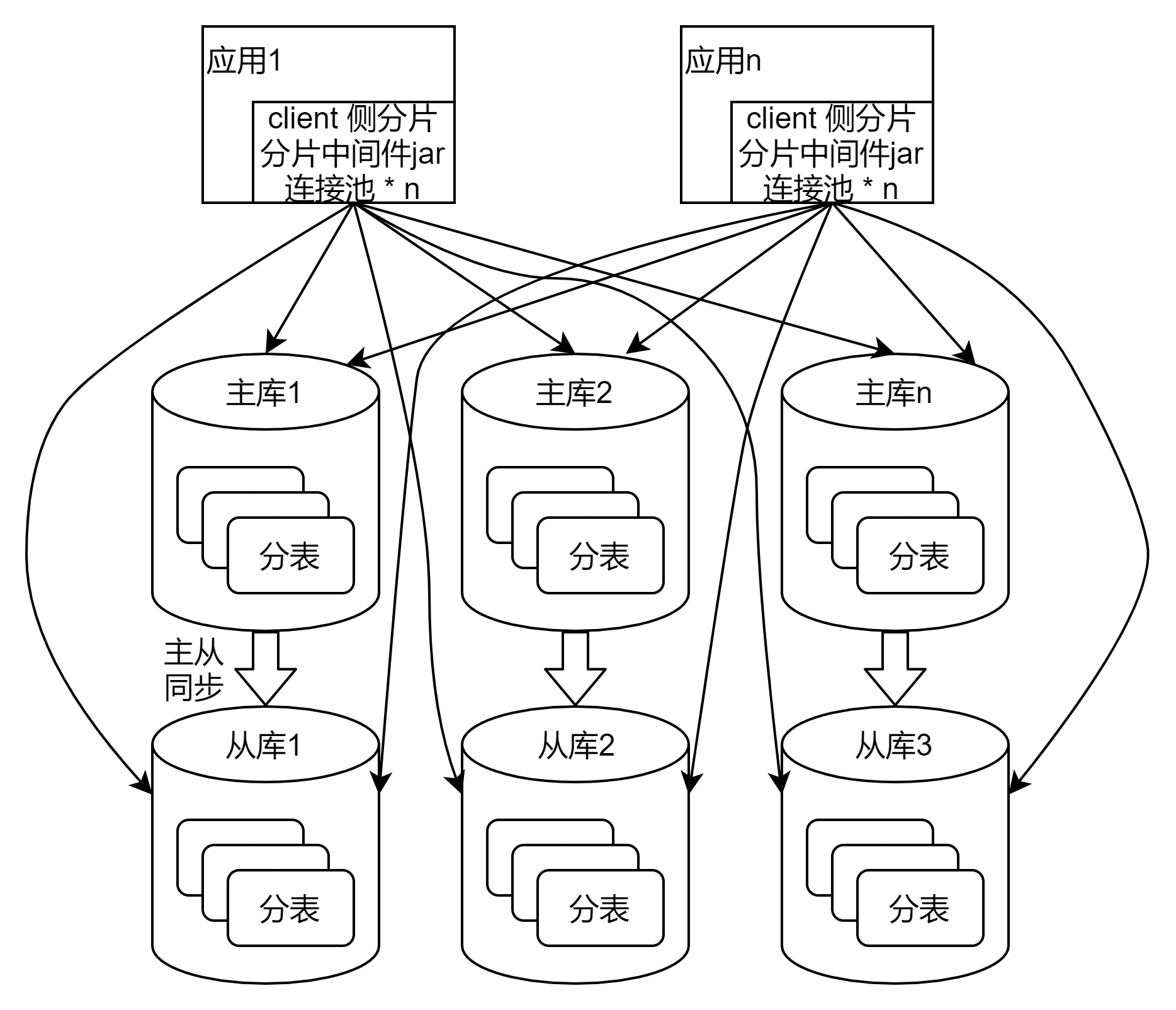
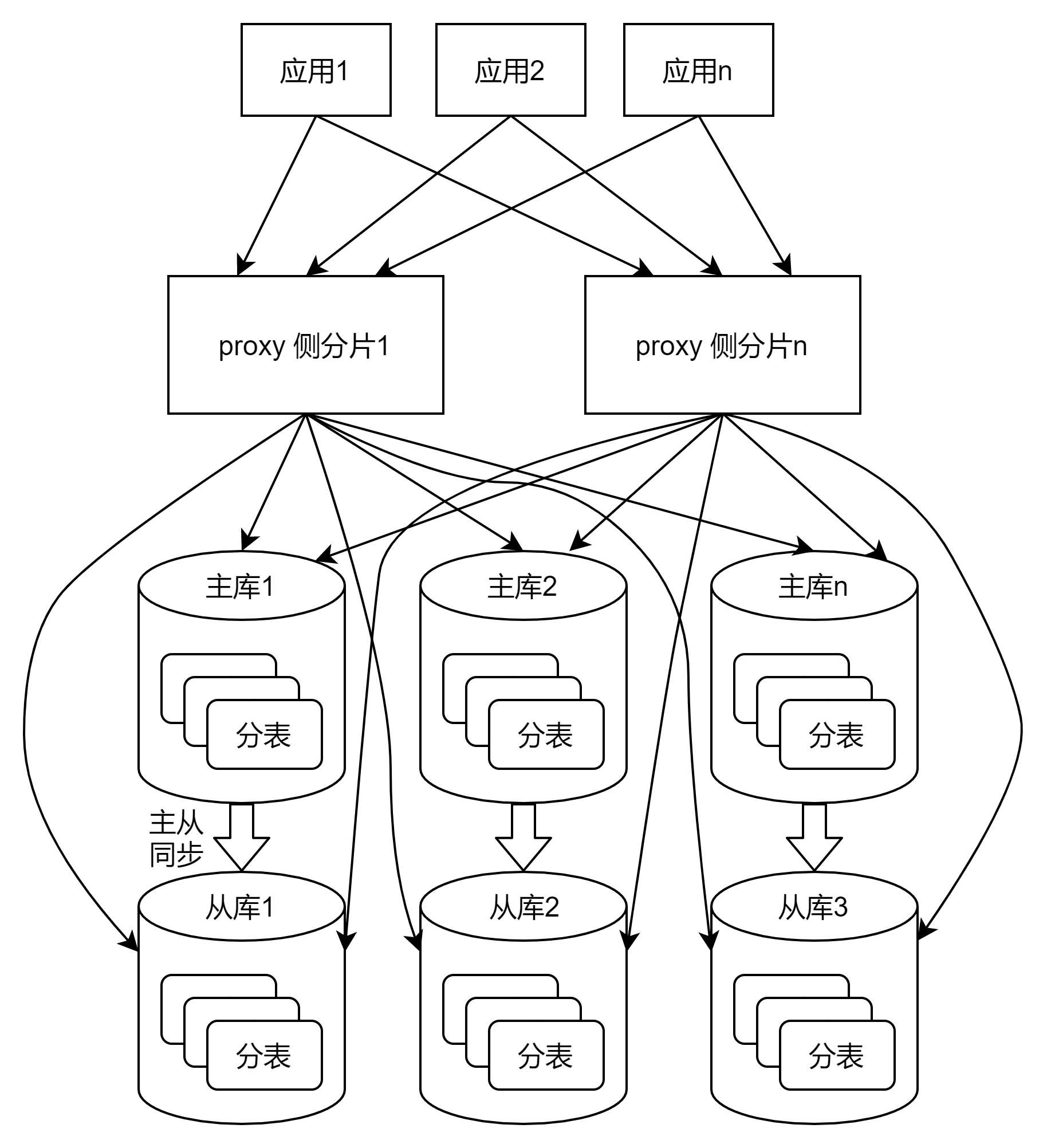
2、分庫分表、讀寫分離
最常見的存儲架構,適用於十億級別以下的數據(單表控制在千萬級別或以下),並發量較大、主備高可用的場景。
- 分庫分表:對業務id(如用戶id、商戶id)取模,散列到各個分庫的分表中
- 讀寫分離:適用於讀多寫少的場景,利用數據庫一主多從的方式,提高並發量,對主庫讀寫,對從庫只讀
此時還需要分片中間件來實現對分庫分表的讀寫分離訪問,有2種類型:
- client側分片:較為常見,以jar包庫的方式內嵌在服務中,需要與所有的數據庫實例,各自建立和維護連接池,性能好
- proxy側分片:proxy是一個數據庫訪問中間層服務,應用與proxy建立少量連接,proxy與所有的數據庫實例建立連接,優點是對應用開發簡單透明,缺點是有性能損耗、需要專門的團隊維護
client側分片
proxy側分片
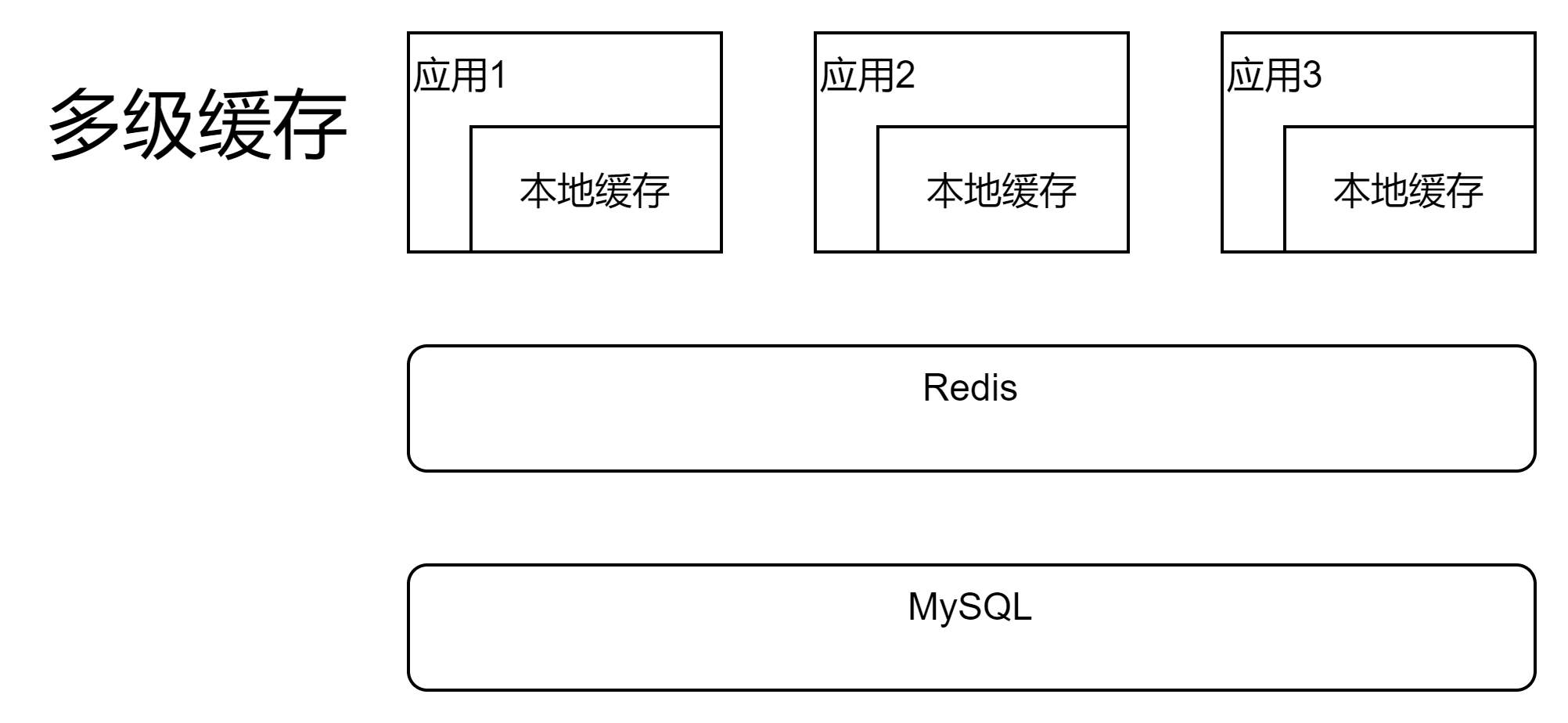
3、引入緩存
高並發標配,當QPS高到只靠mysql扛不住流量時引入,適用於高並發、流量尖峰的場景
- 本地緩存(堆內緩存、或堆外緩存):如caffeine、ehcache、guava等
- 分佈式緩存:如Redis集群
緩存查詢:先查本地緩存,如果查不到再查Redis並寫入本地緩存和Redis,如果Redis也查不到再查數據庫並寫入本地緩存和Redis
緩存更新:數據庫更新後,觸發變更消息,通過消息驅動更新Redis
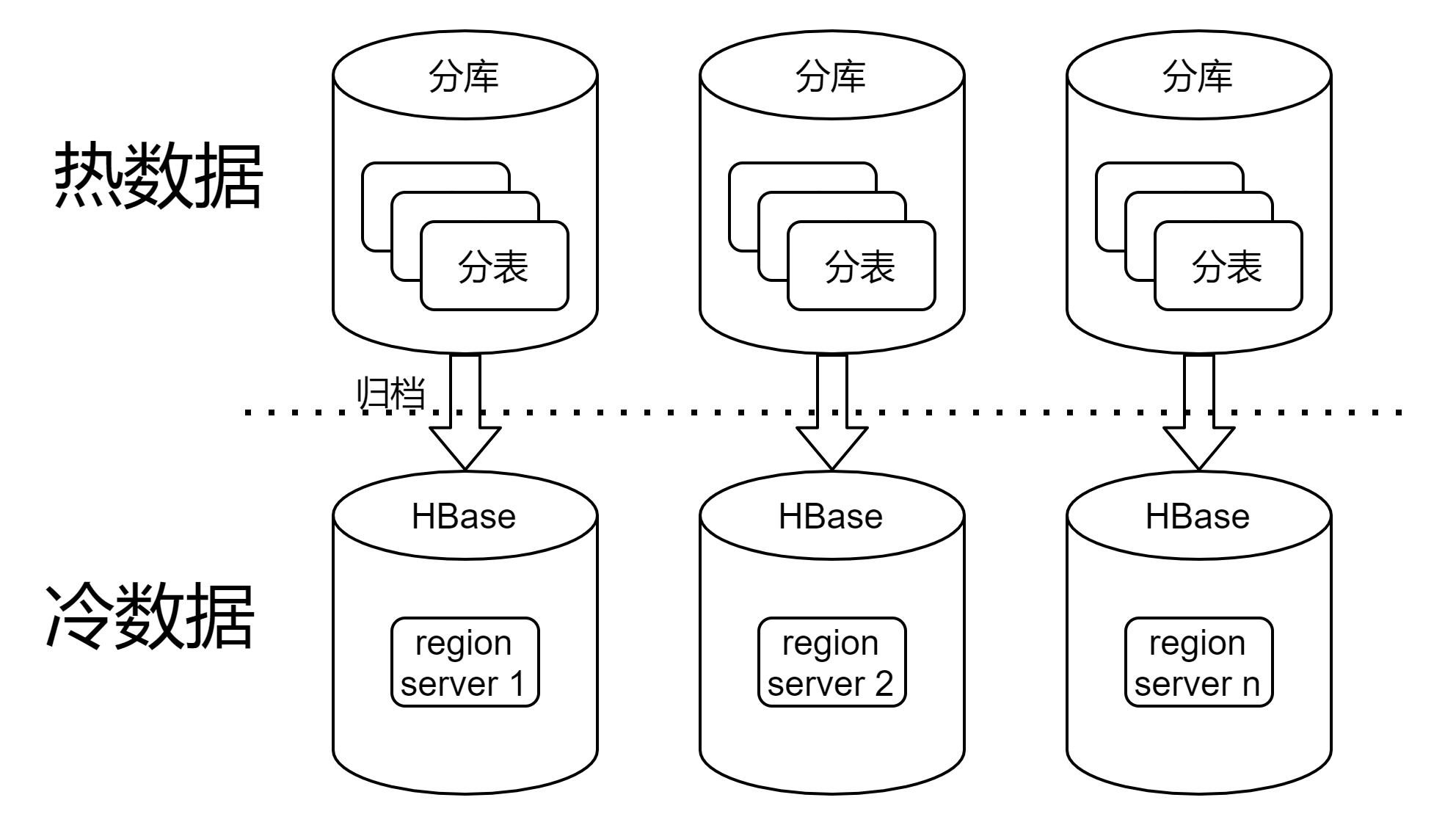
4、冷熱數據分離
引入多級存儲,保證熱數據量可控、讀寫迅速,冷數據全量儲存,適用於數據量巨大、增長迅速,且分庫分表已經不能解決的場景。
- MySQL熱數據:優先讀寫mysql,預期能覆蓋絕大部分QPS
- Hbase冷數據:從mysql查詢不到數據時,才查詢hbase,hbase可支持海量數據的存儲和查詢,預期只有少量QPS
- 歸檔:定期把數據從mysql歸檔至hbase,mysql只保留最新的熱數據,hbase存儲全量數據
5、引入搜索引擎、離線查詢
適用於複雜條件的查詢、或對運營類統計有需求的場景,此時mysql索引已不能滿足高效查詢,且會影響在線業務。
- 引入ElasticSearch:可支持各種條件的靈活查詢,再也不用擔心mysql因為缺少合適索引而造成慢查詢的問題了
- 大數據分析:引入hive數倉做離線查詢,需要把mysql的數據同步至hive
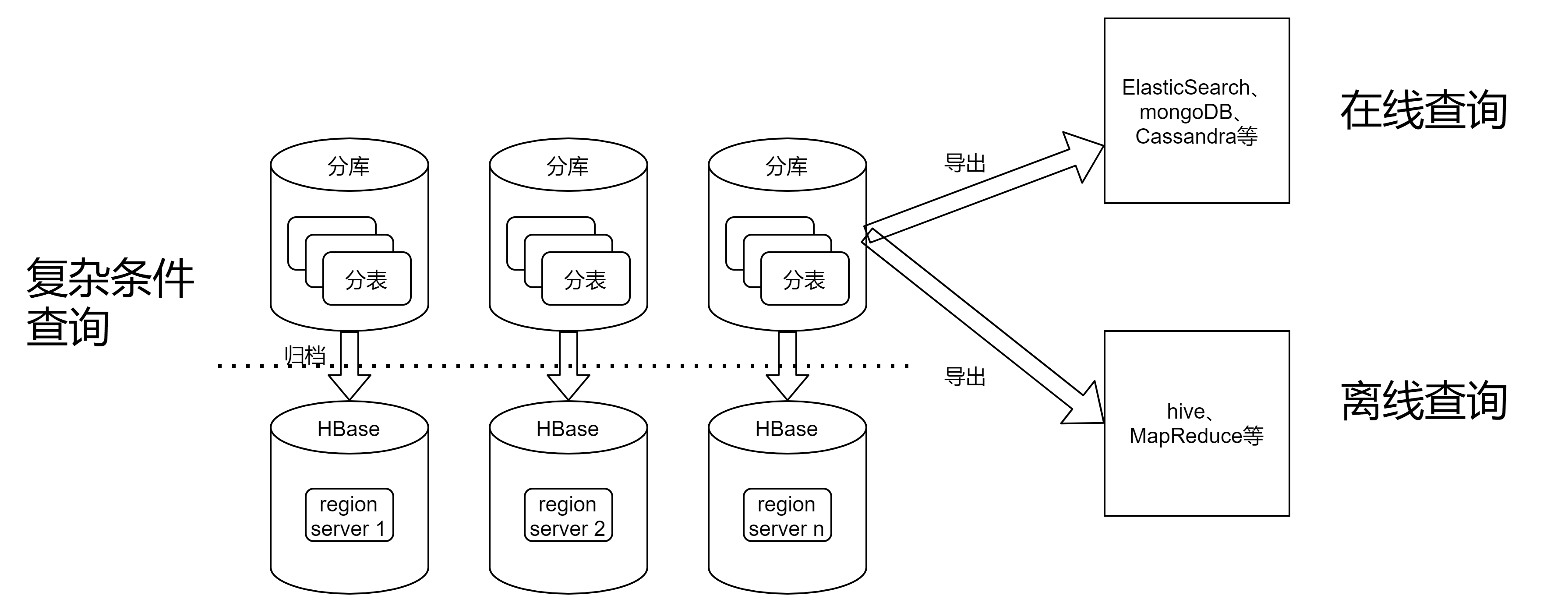

最終架構圖
從單庫,逐步演化成各種存儲緊密配合,滿足不同的需求和場景。切勿為了架構而架構,選擇適合自己的、能解決實際問題的架構,才最重要。


