基於 Mysql 實現一個簡易版搜索引擎
前言
前段時間,因為項目需求,需要根據關鍵詞搜索聊天記錄,這不就是一個搜索引擎的功能嗎?
於是我第一時間想到的就是 ElasticSearch 分佈式搜索引擎,但是由於一些原因,公司的服務器資源比較緊張,沒有額外的機器去部署一套 ElasticSearch 服務,而且上線時間也比較緊張,數據量也不大,然後就想到了 Mysql 的全文索引。
簡介
其實 Mysql 很早就支持全文索引了,只不過一直只支持英文的檢索,從5.7.6 版本開始,Mysql 就內置了 ngram 全文解析器,用來支持中文、日文、韓文分詞。
Mysql 全文索引採用的是倒排索引的原理,在倒排索引中關鍵詞是主鍵,每個關鍵詞都對應着一系列文件,這些文件中都出現了這個關鍵詞。這樣當用戶搜索某個關鍵詞時,排序程序在倒排索引中定位到這個關鍵詞,就可以馬上找出所有包含這個關鍵詞的文件。
本文測試,基於 Mysql 8.0 版本,數據庫引擎採用的是 InnoDB
ngram 全文解析器
ngram 就是一段文字裏面連續的 n 個字的序列。ngram 全文解析器能夠對文本進行分詞,每個單詞是連續的 n 個字的序列。例如,用 ngram 全文解析器對「你好靚仔」進行分詞:
n=1: '你', '好', '靚', '仔'
n=2: '你好', '好靚', '靚仔'
n=3: '你好靚', '好靚仔'
n=4: '你好靚仔'
MySQL 中使用全局變量 ngram_token_size 來配置 ngram 中 n 的大小,它的取值範圍是1到10,默認值是 2。通常 ngram_token_size 設置為要查詢的單詞的最小字數。如果需要搜索單字,就要把 ngram_token_size 設置為 1。在默認值是 2 的情況下,搜索單字是得不到任何結果的。因為中文單詞最少是兩個漢字,推薦使用默認值 2。
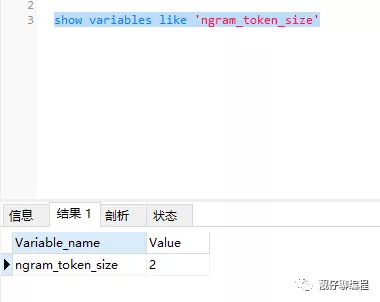
可以通過以下命令查看 Mysql 默認的 ngram_token_size 大小:
show variables like 'ngram_token_size'
有兩種方式可以設置全局變量 ngram_token_size 的值:
1、啟動 mysqld 命令時指定:
mysqld --ngram_token_size=2
2、修改 Mysql 配置文件 my.ini,末尾增加一行參數:
ngram_token_size=2
創建全文索引
1、建表時創建全文索引
CREATE TABLE `article` (
`id` bigint NOT NULL,
`url` varchar(1024) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`title` varchar(256) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`source` varchar(32) COLLATE utf8mb4_general_ci DEFAULT '',
`keywords` varchar(32) COLLATE utf8mb4_general_ci DEFAULT NULL,
`publish_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `title_index` (`title`) WITH PARSER `ngram`
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
2、通過 alter table 方式
ALTER TABLE article ADD FULLTEXT INDEX title_index(title) WITH PARSER ngram;
3、通過 create index 方式
CREATE FULLTEXT INDEX title_index ON article (title) WITH PARSER ngram;
檢索方式
1、自然語言檢索(NATURAL LANGUAGE MODE)
自然語言模式是 MySQL 默認的全文檢索模式。自然語言模式不能使用操作符,不能指定關鍵詞必須出現或者必須不能出現等複雜查詢。
示例
select * from article where MATCH(title) AGAINST ('北京旅遊' IN NATURAL LANGUAGE MODE);
// 不指定模式,默認使用自然語言模式
select * from article where MATCH(title) AGAINST ('北京旅遊');
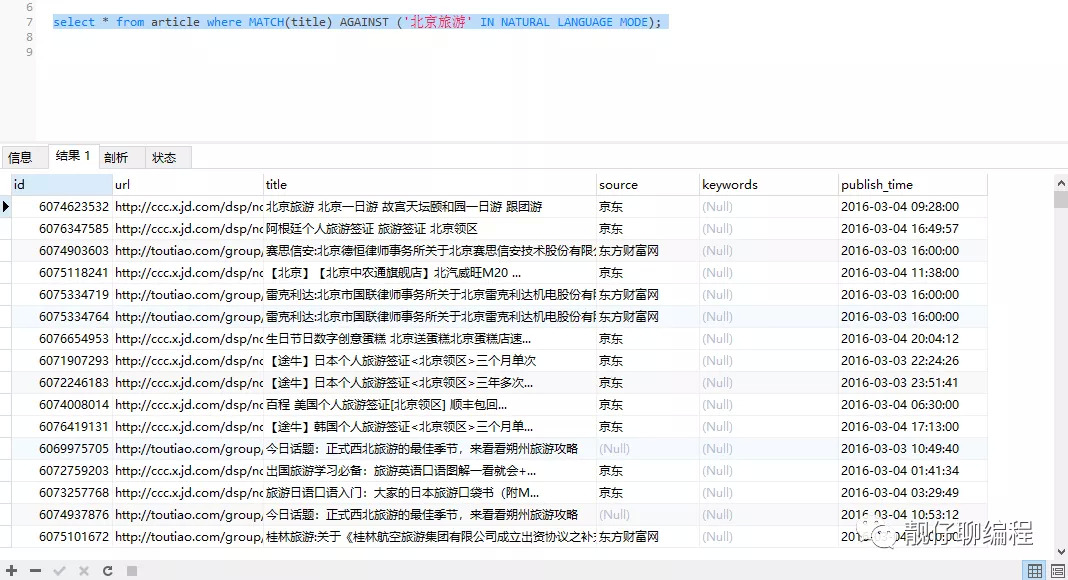
可以看出,該模式下根據「北京旅遊」搜索,可以搜索出包含「北京」的或者包含「旅遊」的內容,因為它是根據自然語言分成了兩個關鍵詞。
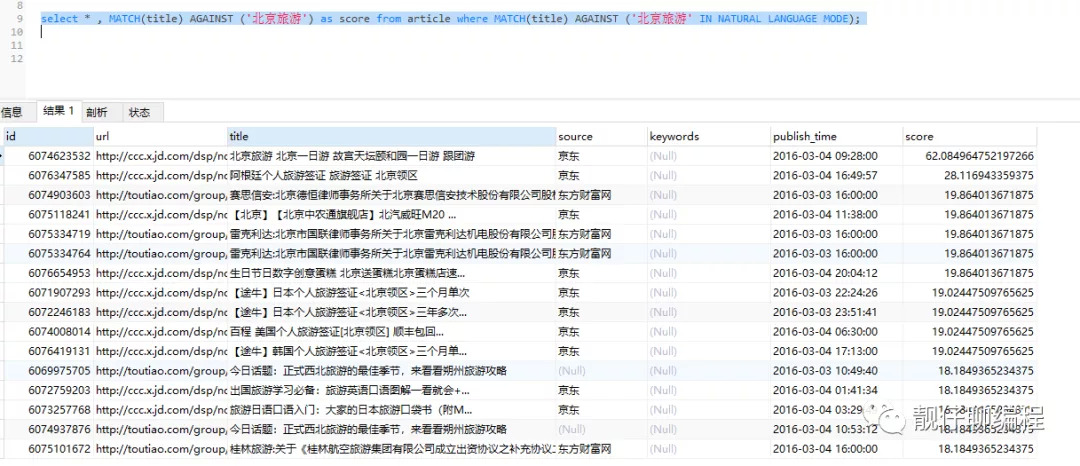
上面示例中返回的結果會自動按照匹配度排序,匹配度高的在前面,匹配度是一個非負浮點數。
示例
// 查看匹配度
select * , MATCH(title) AGAINST ('北京旅遊') as score from article where MATCH(title) AGAINST ('北京旅遊' IN NATURAL LANGUAGE MODE);
2、布爾檢索(BOOLEAN MODE)
布爾檢索模式可以使用操作符,可以支持指定關鍵詞必須出現或者必須不能出現或者關鍵詞的權重高還是低等複雜查詢。
示例
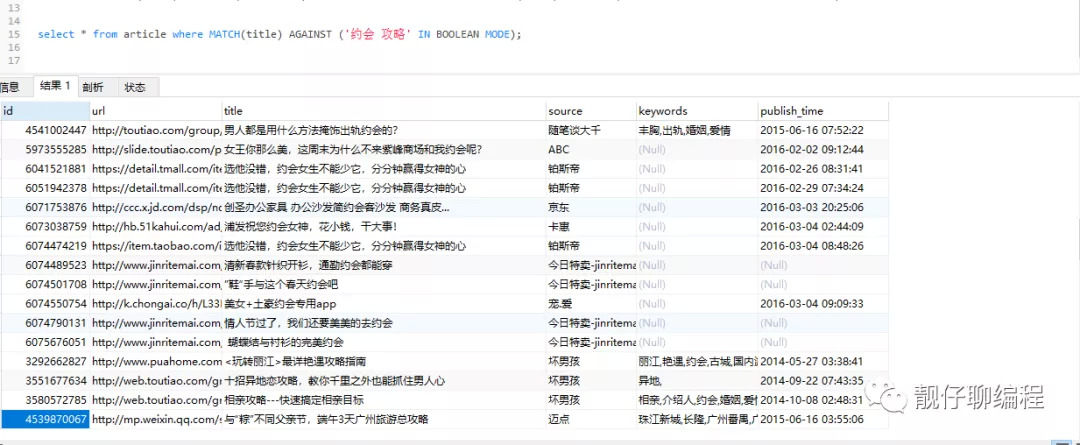
// 無操作符
// 包含「約會」或「攻略」
select * from article where MATCH(title) AGAINST ('約會 攻略' IN BOOLEAN MODE);
// 使用操作符
// 必須包含「約會」,可包含「攻略」
select * from article where MATCH(title) AGAINST ('+約會 攻略' IN BOOLEAN MODE);
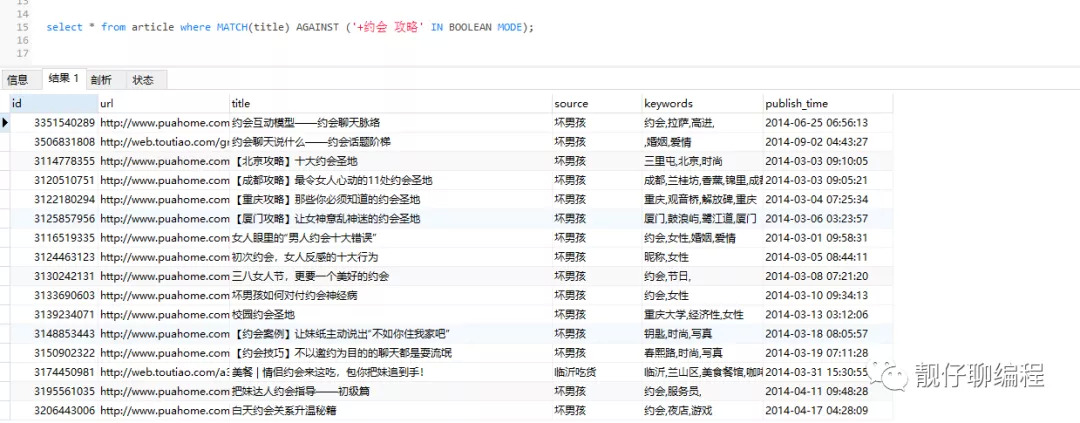
更多操作符示例:
'約會 攻略'
無操作符,表示或,要麼包含「約會」,要麼包含「攻略」
'+約會 +攻略'
必須同時包含兩個詞
'+約會 攻略'
必須包含「約會」,但是如果也包含「攻略」的話,匹配度更高。
'+約會 -攻略'
必須包含「約會」,同時不能包含「攻略」。
'+約會 ~攻略'
必須包含「約會」,但是如果也包含「攻略」的話,匹配度要比不包含「攻略」的記錄低。
'+約會 +(>攻略 <技巧)'
查詢必須包含「約會」和「攻略」或者「約會」和「技巧」的記錄,但是「約會 攻略」的匹配度要比「約會 技巧」高。
'約會*'
查詢包含以「約會」開頭的記錄。
'"約會攻略"'
使用雙引號把要搜素的詞括起來,效果類似於like '%約會攻略%',
例如「約會攻略初級篇」會被匹配到,而「約會的攻略」就不會被匹配。
與 Like 對比
全文索引和 like 查詢對比,有以下優點:
- like 只是進行模糊匹配,全文索引卻提供了一些語法語義的查詢功能,會將要查的字符串進行分詞操作,這決定於 Mysql 的詞庫。
- 全文索引可以自己設置詞語的最小、最大長度,要忽略的詞,這些都是可以設置的。
- 用全文索引去某個列查一個字符串,會返回匹配度,可以理解為匹配的關鍵字個數,是個浮點數。
而且全文檢索的性能也是優於 like 查詢的
以下是以 50w 左右數據進行的測試:
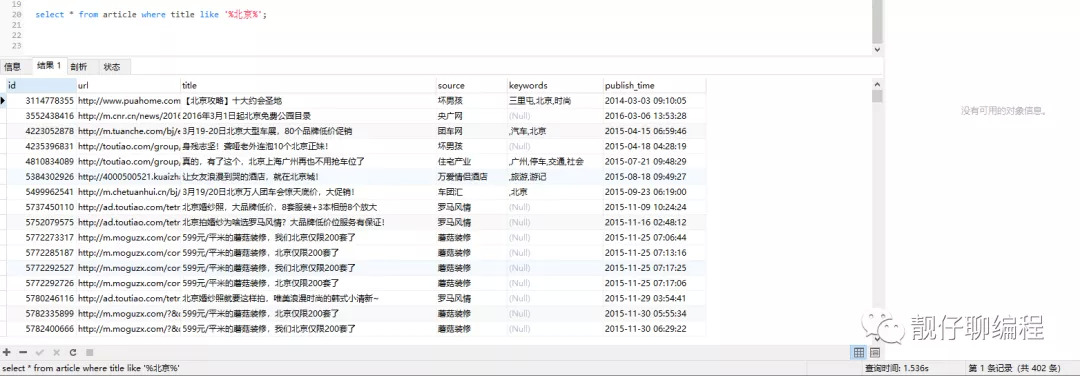
// like 查詢
select * from article where title like '%北京%';
// 全文索引查詢
select * from article where MATCH(title) AGAINST ('北京' IN BOOLEAN MODE);
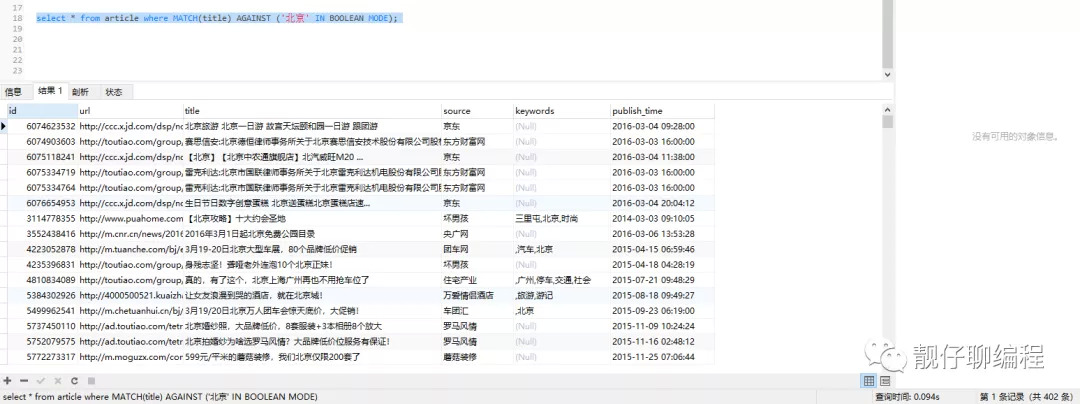
可以看出 like 查詢是 1.536s,全文索引查詢是 0.094s,快了16倍左右。
總結
全文索引能快速搜索,但是也存在維護索引的開銷。字段長度越大,創建的全文索引也越大,會影響DML語句的吞吐量。數據量不大的情況下可以採用全文索引來做搜索,簡單方便,但是數據量大的話還是建議用專門的搜索引擎 ElasticSearch 來做這件事。
END
往期推薦


