CNN卷積神經網絡詳解
前言
在學計算機視覺的這段時間裏整理了不少的筆記,想着就把這些筆記再重新整理出來,然後寫成Blog和大家一起分享。目前的計劃如下(以下網絡全部使用Pytorch搭建):
專題一:計算機視覺基礎
- 介紹CNN網絡(計算機視覺的基礎)
- 淺談VGG網絡,介紹ResNet網絡(網絡特點是越來越深)
- 介紹GoogLeNet網絡(網絡特點是越來越寬)
- 介紹DenseNet網絡(一個看似十分NB但是卻實際上用得不多的網絡)
- 整理期間還會分享一些自己正在參加的比賽的Baseline
專題二:GAN網絡
- 搭建普通的GAN網絡
- 卷積GAN
- 條件GAN
- 模式崩潰的問題及網絡優化
以上會有相關代碼實踐,代碼是基於Pytorch框架。話不多說,我們先進行專題一的第一部分介紹,卷積神經網絡。
一、CNN解決了什麼問題?
在CNN出現之前,對於圖像的處理一直都是一個很大的問題,一方面因為圖像處理的數據量太大,比如一張512 x 512的灰度圖,它的輸入參數就已經達到了252144個,更別說1024x1024x3之類的彩色圖,這也導致了它的處理成本十分昂貴且效率極低。另一方面,圖像在數字化的過程中很難保證原有的特徵,這也導致了圖像處理的準確率不高。
而CNN網絡能夠很好的解決以上兩個問題。對於第一個問題,CNN網絡它能夠很好的將複雜的問題簡單化,將大量的參數降維成少量的參數再做處理。也就是說,在大部分的場景下,我們使用降維不會影響結果。比如在日常生活中,我們用一張1024x1024x3表示鳥的彩色圖和一張100x100x3表示鳥的彩色圖,我們基本上都能夠用肉眼辨別出這是一隻鳥而不是一隻狗。這也是卷積神經網絡在圖像分類里的一個重要應用。【ps:卷積神經網絡可以對一張圖片進行是貓還是狗進行分類。如果一張圖片里有貓有狗有雞,我們要分別識別出每個區域的動物,並用顏色分割出來,基礎的CNN網絡還能夠使用嗎?這是一個拓展思考,有興趣的讀者可以看一下FCN網絡。對比之下能夠更好的理解CNN網絡】

對於第二個問題,CNN網絡利用了類似視覺的方式保留了圖像的特徵,當圖像做翻轉、旋轉或者變換位置的時候,它也能有效的識別出來是類似的圖像。
以上兩個問題的解決,都是由於CNN網絡具有以下優勢和特點:局部區域連接、權值共享。在解釋這三個特點之前,我們先看一下CNN網絡的三大主要結構,卷積層、池化層(或者叫做匯聚層)、全連接層。
二、CNN網絡的結構
2.1 卷積層 – 提取特徵
卷積運算
了解卷積層,我們先要了解一下卷積運算。別看它叫做卷積,但是和嚴格意義上的數學卷積是不同的。深度學習所謂的卷積運算是互相關( cross-correlation )運算。【實際上,經過數學證明發現無論用嚴格卷積或互相關運算,卷積層的輸出不會受太大影響。而互相關運算比嚴格卷積運算簡潔的多,所以我們一般都採用互相關運算來替代嚴格意義上的卷積運算。】我們以二維數據為例(高 x 寬),不考慮圖像的通道個數,假設輸入的高度為3、寬度為3的二維張量,卷積核的高度和寬度都是2,而卷積核窗口的形狀由內核的高度和寬度決定:
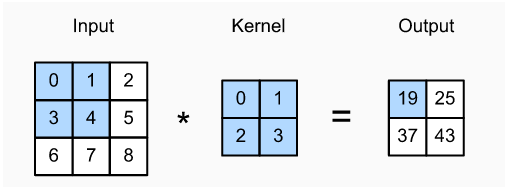
二維的互相關運算。陰影部分是第一個輸出元素,以及用於計算這個輸出的輸入和核張量元素: 0 x 0 + 1×1 + 3×2 +4×3 = 19。由此可見互相關運算就是一個乘積求和的過程。在二維互相關運算中,卷積窗口從輸入張量的左上角開始,從左到右、從上到下滑動。這裡我們設置步長為1,即每次跨越一個距離。當卷積窗口滑到新一個位置時,包含在該窗口中的部分張量與卷積核張量進行按元素相乘,得到的張量再求和得到一個單一的標量值,由此我們得到了這一位置的輸出張量值。 【我們這裡頻繁提到了張量,張量(Tensor)是一個多維數組,它是標量、向量、矩陣的高維拓展。】
看了上面的內容,可能有讀者開始思考,如果這個輸入矩陣是 4×4,卷積核是3×3,步長為1的時候,在向右移動時,我們發現如果要和卷積核進行卷積操作,左便的輸入矩陣還缺少了一列;在行的方向也是如此。如果我們忽略邊緣的像素,我們可能就丟失了邊緣的細節。那麼這種情況下我們如何處理呢?這時我們可以進行填充操作(padding),在用pytorch實現時我們可以在Convd函數中對padding進行設置,這裡我們可以設置padding=1,就能夠在行和列上向外擴充一圈。【ps:實際上當處理比較大的圖片,且任務是分類任務時,我們可以不用進行padding。因為對於大部分的圖像分類任務,邊緣的細節是是無關緊要的,且邊緣的像素點相比於總的像素來講,佔比是很小的,對於整個圖像分類的任務結果影響不大】
對於卷積操作,我們有一個統一的計算公式。且學會相關的計算對於了解感受野和網絡的搭建至關重要。學會相關的計算,我們在搭建自己的網絡或者復現別人的網絡,才能夠確定好填充padding、步長stride以及卷積核kernel size的參數大小。一般這裡有一個統一的公式:
假設圖像的尺寸是 input x input,卷積核的大小是kernel,填充值為padding,步長為stride,卷積後輸出的尺寸為output x output,則卷積後,尺寸的計算公式為:
\]
ps:如果輸入的圖像尺寸是 mxn類型的,可以通過裁剪 or 插值轉換成 mxm or nxn類型的圖像;或者分別計算圖像的高和寬大小也可以,公式都是類似的。
我們在第二部分的一開始提到過特徵映射(feature map)。其實每一層卷積層得到的輸出就被稱為一個feature map,因為它可以被視為一個輸入映射到下一層空間維度的轉換器。在CNN中,對於某一層的任意元素x,其感受野(Receptive Field)是指前向傳播期間可能影像x計算的所有元素(來自所有的先前層)。隨着網絡層數越來越深,感受野會越來越大。在感受野變化的過程中,較淺的感受野比較小,學習到一些局部區域的特徵,較深的卷積層有較大的感受野,能夠學習到更加抽象的一些特徵。
權重共享
我們在前面有提到過CNN網絡的一個特性是權重共享(share weights)也正是體現在通道處理的過程中。一般的神經網絡層與層之間的連接是,每個神經元與上一層的全部神經元連接,這些連接線的權重獨立於其他的神經元,所以假設上一層是m個神經元,當前層是n個神經元,那麼共有mxn個連接,也就有mxn個權重。權重矩陣是mxn的形式。那麼CNN是如何呢?權重共享是什麼意思?我們引入下面這樣一張圖來幫助我們理解:

我們先說明上圖中各個模塊的矩陣格式及關係:
- 輸入矩陣格式:(樣本數,圖像高度,圖像寬度,圖像通道數)
- 輸出矩陣格式:(樣本數,圖像高度、圖像寬度、圖像通道數)
- 卷積核的格式:(卷積核高度、卷積核寬度、輸入通道數、輸出通道數)
- 卷積核的輸入通道數(in depth)由輸入矩陣的通道數所決定。(紅色標註)
- 輸出矩陣的通道數(out depth)由卷積核的輸出通道所決定。(綠色標註)
- 輸出矩陣的高度和寬度,由輸入矩陣、卷積核大小、步長、填充共同決定,具體計算公式見上文。
當輸入一張大小為8x8x3的彩色圖時,我們已經提前設計好了卷積核後的輸出通道為5,即卷積核的個數為5【即五個偏置,一個卷積核一個偏置】(通道數的設計一般是實驗後得到的較優結果)。每個卷積核去和輸入圖像在通道上一一對應進行卷積操作(即互相關操作,除非刻意強調,這裡所說的卷積都是互相關,步長為1,填充為0),得到了3個6×6的feature map。然後再將三個6×6的Feature map按照Eletwise相加進行通道融合得到最終的feature map,大小為6×6(也就是將得到的三個矩陣逐元素相加,之後所有元素再加上該矩陣的偏置值,得到新的6×6矩陣)。權重共享也是體現在這個過程中。我們單獨提取出第一個卷積核,當它的第一個通道(3×3)與輸入圖像的第一個通道(8×8)進行卷積操作時,按照普通的神經網絡連接方式其權重矩陣是9 x 81。但是這裡我們要注意,我們在窗口滑動進行卷積的操作權重是確定的,都是以輸入圖像的第一個通道為模板,卷積核的第一個通道3×3矩陣為權重值,然後得到卷積結果。這個過程中權重矩陣就是3×3,且多次應用於每次計算中。權重的個數有9×81減少到3×3,極大的減少了參數的數量。綜合起來,對於第一個卷積核來講,它的權重矩陣就是3x3x3+1,整個卷積過程的權重大小為3x3x3x5+5,而不是8x8x3x3x3x3x5。權重共享大大減少了模型的訓練參數。權重共享意味着當前隱藏層中的所有神經元都在檢測圖像不同位置處的同一個特徵,即檢測特徵相同。因此也將輸入層到隱藏層的這種映射稱為特徵映射。由上我們可以理解,從某種意義上來說,通道就是某種意義上的特徵圖。輸出的同一張特徵圖上的所有元素共享一個卷積核,即共享一個權重。通道中某一處(特徵圖上某一個神經元)數值的大小就是當前位置對當前特徵強弱的反應。而為什麼在CNN網絡中我們會增加通道數目,其實就是在增加通道的過程中區學習圖像的多個不同特徵。
稀疏連接
通過上面對於卷積的過程以及權重共享的解釋,我們能夠總結出CNN的另一個特徵。有心的讀者其實能夠自己總結出來。我們在上面提到過,對於普通的神經網絡,隱藏層和輸入層之間的神經元是採用全連接的方式。然而CNN網絡並不是如此。它的在局部區域創建連接,即稀疏連接。比如,對於一張輸入的單通道的8×8圖片,我們用3×3的卷積核和他進行卷積,卷積核中的每個元素的值是和8×8矩陣中選取了3×3的矩陣做卷積運算,然後通過滑動窗口的方式,卷積核中的每個元素(也就是神經元)只與上一層的所有神經元中的9個進行連接。相比於神經元之間的全連接方式,稀疏連接極大程度上的減少了參數的數量,同時也一定程度上避免了模型的過擬合。這種算法的靈感是來自動物視覺的皮層結構,其指的是動物視覺的神經元在感知外界物體的過程中起作用的只有一部分神經元。在計算機視覺中,像素之間的相關性與像素之間的距離同樣相關,距離較近的像素間相關性強,距離較遠則相關性比較弱,由此可見局部相關性理論也適用於計算機視覺的圖像處理。因此,局部感知(稀疏連接)採用部分神經元接受圖像信息,再通過綜合全部的圖像信息達到增強圖像信息的目的。(至於我們為什麼現在經常採用3×3卷積核,因為實驗結果告訴我們,3×3卷積核常常能達到更好的實驗效果。)
總結:標準的卷積操作
在進行上面的解釋後,相信大家已經對於什麼是卷積,卷積的兩點特點:稀疏鏈接和權重共享已經有了了解。下面我們來總結一般意義的標準的卷積操作:當輸入的feature map數量(即輸入的通道數)是N,卷積層filter(卷積核)個數是M時,則M個filter中,每一個filter都有N個channel,都要分別和輸入的N個通道做卷積,得到N個特徵圖,然後將這N個feature map按Eletwise相加(即:進行通道融合),再加上該filter對應的偏置(一個filter對應一個共享偏置),作為該卷積核所得的特徵圖。同理,對其他M-1個filter也進行以上操作。所以最終該層的輸出為M個feature map(即:輸出channel等於filter的個數)。可見,輸出的同一張特徵圖上的所有元素共享同一個卷積核,即共享一個權重。不同特徵圖對應的卷積核不同。
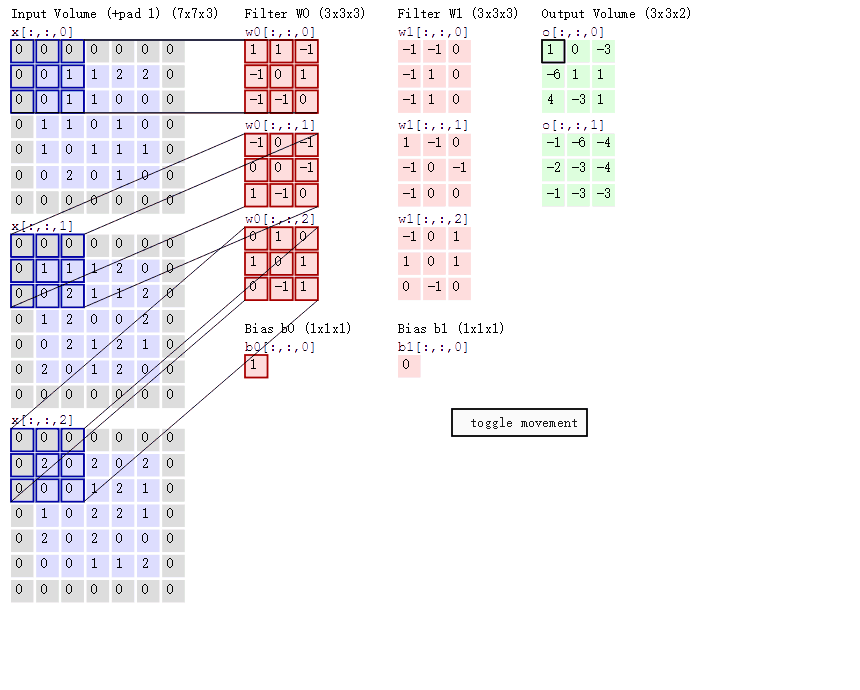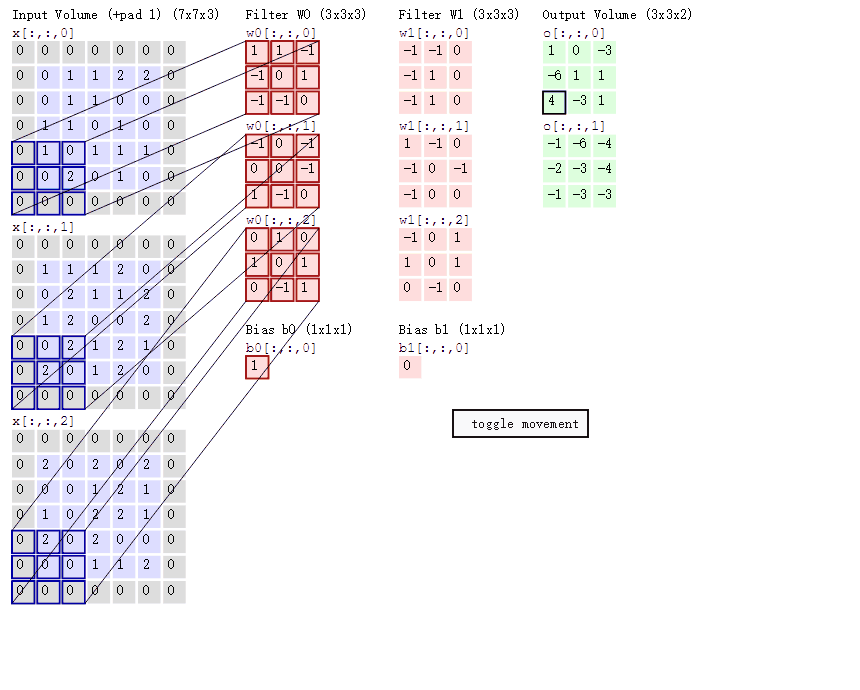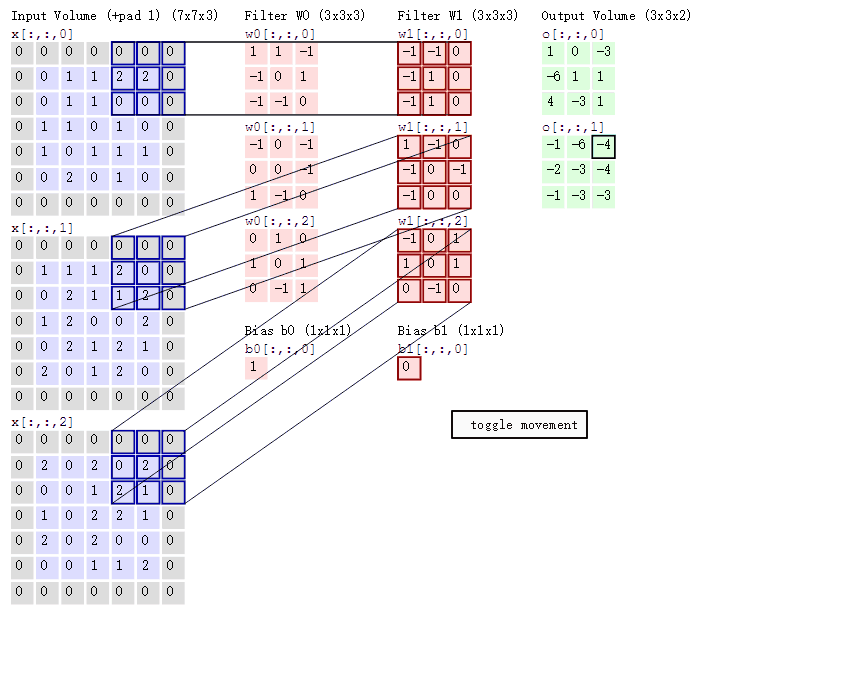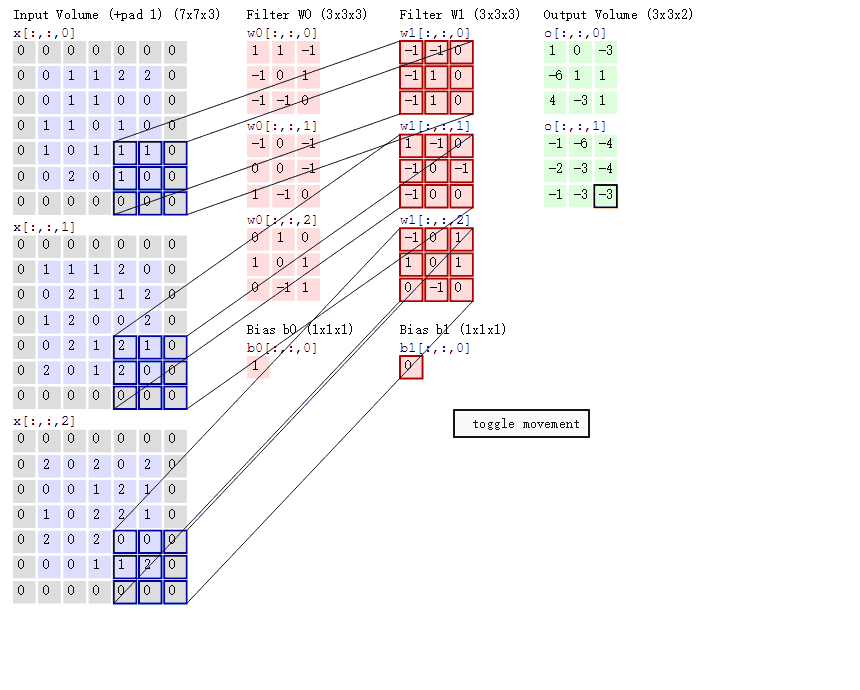
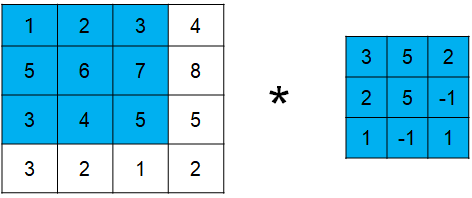
卷積的意義
如果用圖像處理上的專業術語,我們可以將卷積叫做銳化。卷積其實是想要強調某些特徵,然後將特徵強化後提取出來,不同卷積核關注圖片上不同的特徵,比如有的更關注邊緣而有的更關注中心地帶等。當完成幾個卷積層後(卷積 + 激活函數 + 池化)【後面講解激活函數和池化】,如圖所示:
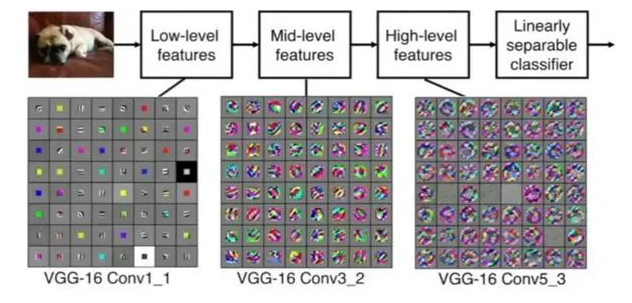
在CNN中,我們就是通過不斷的改變卷積核矩陣的值來關注不同的細節,提取不同的特徵。也就是說,在我們初始化卷積核的矩陣值(即權重參數)後,我們通過梯度下降不斷降低loss來獲得最好的權重參數,整個過程都是自動調整的。
1×1卷積的重大意義
按照道理講,我是不該這麼快就引入1×1卷積的,不過考慮到它在各種網絡中應用的重要性並且也不難理解,就在這裡提前和大家解釋一下1×1卷積是什麼,作用是什麼。
如果有讀者在理解完上文所提到的卷積後,可能會發出疑問:卷積的本質不是有效的提取相鄰像素間的相關特徵嗎?1×1卷積核的每個通道和上一層的通道進行卷積操作的時候不是沒法識別相鄰元素了嗎?
其實不然,1×1卷積層的確是在高度和寬度的維度上失去了識別相鄰元素間的相互作用的能力,並且通過1×1卷積核後的輸出結果的高和寬與上一層的高和寬是相同的。但是,通道數目可能是不同的。而1×1卷積的唯一計算也正是發生在通道上。它通過改變1×1卷積核的數量,實現了多通道的線性疊加,使得不同的feature map進行線性疊加。我們通過下圖來更好的認識1×1卷積的作用:

上圖使用了2個通道的1×1卷積核與3個通道的3×3輸入矩陣進行卷積操作。由圖可知,這裡的輸入和輸出具有相同的高度和寬度,輸出的每個元素都是從輸入圖像的同一位置的元素的線性組合。我們可以將1×1卷積層看做是每個像素位置應用的全連接層。同時,我們發現輸出結果的通道數目發生了改變,這也是1×1卷積的一個重要應用。可以對輸出通道進行升維或者降維,並且不改變圖像尺寸的大小,有利於跨通道的信息交流的內涵。降維之後我們可以使得參數數量變得更少,訓練更快,內存佔用也會更少。如果是在GPU上訓練,顯存就更加珍貴了。
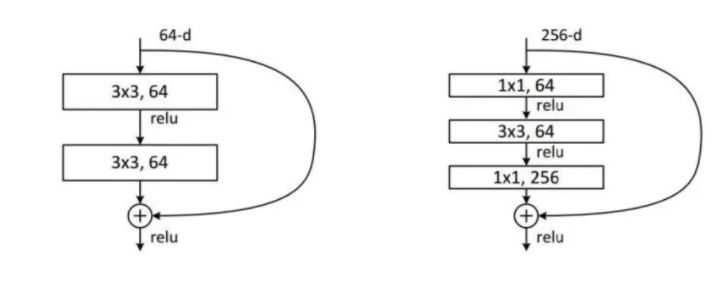
卷積網絡的一個非常重要的應用就是ResNet網絡,而ResNet網絡結構,已經應用於各種大型網絡中,可以說是隨處可見。這裡先貼個ResNet中應用了1×1卷積的殘差塊,後面會有一篇文章來解讀ResNet網絡:ResNet paper download
2.2 激活函數
由前述可知,在CNN中,卷積操作只是加權求和的線性操作。若神經網絡中只用卷積層,那麼無論有多少層,輸出都是輸入的線性組合,網絡的表達能力有限,無法學習到非線性函數。因此CNN引入激活函數,激活函數是個非線性函數,常用於卷積層和全連接層輸出的每個神經元,給神經元引入了非線性因素,使網絡的表達能力更強,幾乎可以逼近任意函數,這樣的神經網絡就可應用到眾多的非線性模型中,我們可以用公式來定義隱藏層的每個神經元輸出公式:
\]
其中,\(b_l\)是該感知與連接的共享偏置,\(W_l\)是個nxn的共享權重矩陣,\(X_{l-1}^{n \times n}\)代表在輸入層的nxn的矩形區域的特徵值。
當激活函數作用於卷積層的輸出時:
\]
這裡的\(\sigma\)是神經元的激勵函數,可以是Sigmoid、tanh、ReLU等函數。
2.3 池化層(下採樣) – 數據降維,避免過擬合
在CNN中,池化層通常在卷積或者激勵函數的後面,池化的方式有兩種,全最大池化或者平均池化,池化主要有三個作用:
- 一是降低卷積層對目標位置的敏感度,即實現局部平移不變性,當輸入有一定的平移時,經過池化後輸出不會發生改變。CNN通過引入池化,使得其特徵提取不會因為目標位置變化而受到較大的影響。
- 二是降低對空間降採樣表示的敏感性
- 三是能夠對其進行降維壓縮,以加快運算速度 ,防止過擬合。
與卷積層類似的是,池化層運算符有一個固定的窗口組成,該窗口也是根據步幅大小在輸入的所有區域上滑動,為固定的形狀窗口遍歷每個位置計算一個輸出。
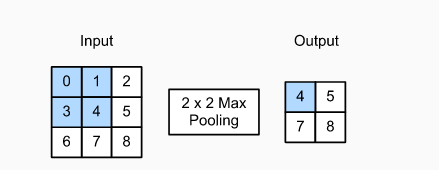
輸出的張量高度為2,寬度為2,這四個元素為每個池化窗口中的最大值(stride=1,padding=0):
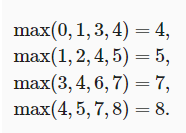
但是,不同於卷積層中的輸入與卷積核之間的互相關計算,池化層不包含參數。池化層的運算符是確定性的,我們通常計算池化窗口中所有元素的最大值或平均值(些操作分別被稱為最大池化層和平均池化層),而不是像卷積層那樣將各通道的輸入在互相關操作後進行eletwise特徵融合,這也意味着池化層的輸出通道數和輸入通道數目是相同的。池化操作的計算一般形式為,設輸入圖像尺寸為WxHxC,寬x高x深度,卷積核的尺寸為FxF,S:步長,則池化後圖像的大小為:
H = \frac{H-F}{S} + 1
\]
2.4 全連接層 – 分類,輸出結果
我們剛給講了卷積層、池化層和激活函數,這些在全連接層之前層的作用都是將原始數據映射到隱層特徵空間來提取特徵,而全連接層的作用就是將學習到的特徵表示映射到樣本的標記空間。換句話說,就是把特徵正和島一起(高度提純特徵),方便交給最後的分類器或者回歸。
我們也可以把全連接層的過程看做一個卷積過程,例如某個網絡在經過卷積、ReLU激活後得到3x3x5的輸出,然後經過全連接層轉換成1×4096的形式:

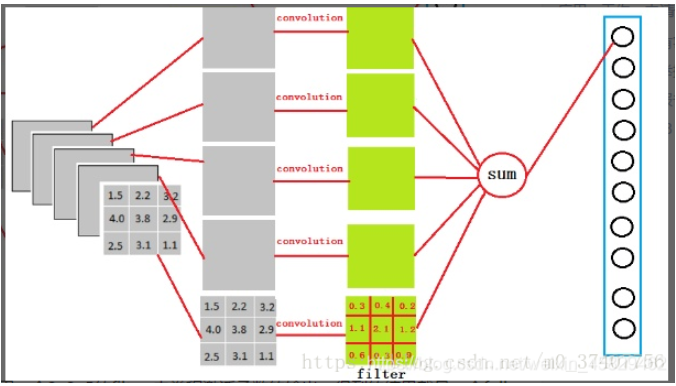
從上圖我們可以看出,我們用一個3x3x5的filter去卷積激活函數的輸出,得到的結果是全連接層的一個神經元,因為我們有4096個神經元,我們實際上就是用一個3x3x5x4096的卷積層去卷積激活函數的輸出【不帶偏置】。因此全連接層中的每個神經元都可以看成一個不帶偏置加權平均的多項式,我們可以簡單寫成$y_l^i = W_l \times x_{l-1}^{n \times n} $。
這一步卷積還有一個非常重要的作用,就是把分佈式特徵representation映射到樣本標記空間,簡單說就是把特徵整合到一起,輸出為一個值,這樣可以大大減少特徵位置對分類帶來的影響。
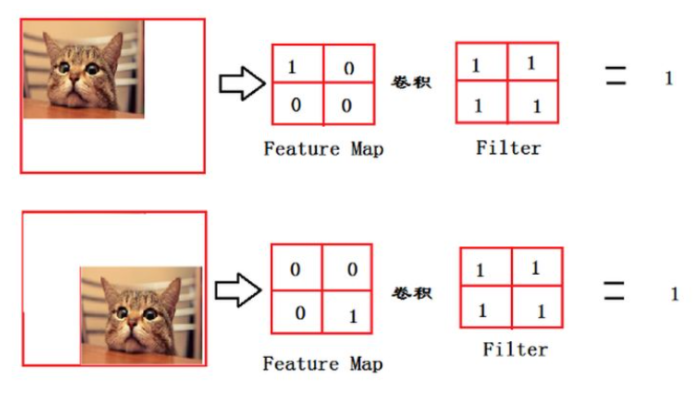
從上面的圖,我們可以看出,貓在不同的位置,輸出的特徵值相同,但是位置不同;對於電腦來說,特徵值相同,但是特徵值位置不同,那分類結果可能是不一樣的。此時全連接層的作用就是,在展平後忽略其空間結構特性,不管它在哪兒,只要它有這個貓,那麼就能判別它是貓。這也說明了它是一個跟全局圖像的問題有關的問題(例如:圖像是否包含一隻貓呢)。這也說明了全連接層的結構不適合用於在方位上找patter的任務,例如分割任務(後面的FCN就是將全連接層改成了卷積層)。不過全連接層有一個很大的缺點,就是參數過於多。所以後面的像ResNet網絡、GoogLeNet都已經採用全局平均池化取代全連接層來融合學到的特徵。另外,參數多了也引發了另外一個問題,模型複雜度提升,學習能力太好容易造成過擬合。
三、Pytorch實現LeNet網絡
LeNet模型是最早發佈的卷積神經網絡之一,它是由AT&T貝爾實驗室的研究院Yann LeCun在1989年提出的,目的是識別圖像中的手寫數字,發表了第一篇通過反向傳播成功訓練卷積神經網絡的研究。我們現在通過pytorch來實現:LeNet – Paper Download 。
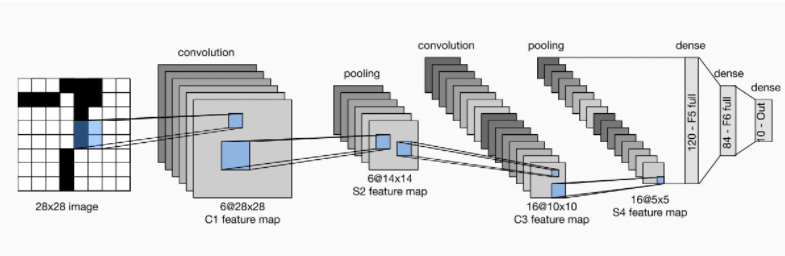
LeNet它雖然很小,但是包含了深度學習的基本模塊。我們先對LeNet結構進行一個具體的分析,這也是我們搭建任何一個神經網絡之前要提前知道的:
每個卷積塊中的基本單元是一個卷積層、一個Sigmod激活函數和平均池化層。(雖然ReLU函數和最大池化層很有效,但是當時還沒有出現)。每個卷積層使用5×5卷積核和一個Sigmoid激活函數。第一個卷積層有6個輸出通道,第二個卷積層有16個輸出通道。每個2×2赤化操作通過空間下採樣將維數減少4倍。卷積的輸出形狀由(批量大小,通道數,高度,寬度)決定。LeNet中有三個全連接層,分別有120、84、10個輸出,因為我們在執行手寫數字的分類任務(一共有0-9共10個數字),所以輸出層的10維對應於最後輸出的結果的數量。
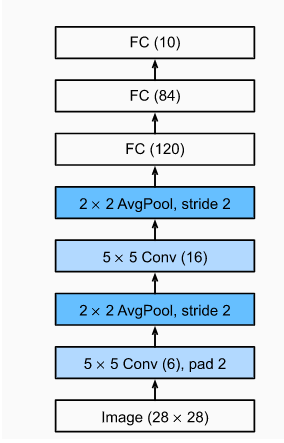
把上面的模型簡化一下,網絡結構大概就是這個樣子:
3.1 模型定義
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
# 通過view函數把圖像展成標準的Tensor接收格式,即(樣本數量,通道數,高,寬)
return x.view(-1, 1, 28, 28)
net = torch.nn.Sequential(
Reshape(),
# 第一個卷積塊,這裡用到了padding=2
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 第二個卷積塊
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 稠密塊(三個全連接層)
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
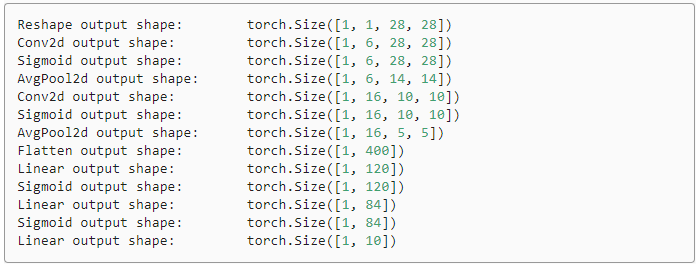
輸出結果為:
3.2 模型訓練(使用GPU訓練)
我們用LeNet在Fashion-MNIST數據集上測試模型表現結果:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU計算模型在數據集上的精度。"""
if isinstance(net, torch.nn.Module):
net.eval() # 設置為評估模式
if not device:
device = next(iter(net.parameters())).device
# 正確預測的數量,總預測的數量
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU訓練模型。"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 訓練損失之和,訓練準確率之和,範例數
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
3.3 訓練和評估模型
“
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
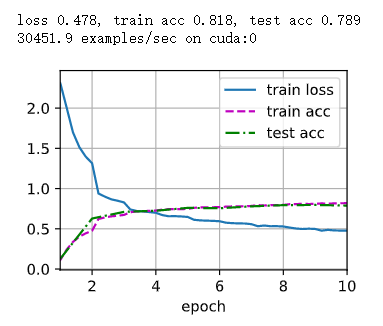
這個是我的訓練結果,大概就醬紫,結束了結束了,累死我了。
引用:
//www.cnblogs.com/chumingqian/articles/11495364.html
//blog.csdn.net/u011240016/article/details/78475043
//mp.weixin.qq.com/s/eOM3YHPkCCmMpLrv4ZDhBA
//zhuanlan.zhihu.com/p/33841176
//blog.csdn.net/weixin_45829462/article/details/106548749


