Python 編譯器與解釋器
- 2019 年 10 月 3 日
- 筆記
Python 編譯器與解釋器
Python的環境我們已經搭建好了,可以開始學習基礎知識了。但是,在此之前,還要先說說編譯器與解釋器相關的內容。
如果這部分內容,讓你覺得難以理解或不能完全明白,可以暫時跳過,等以後再回過頭來重新讀一遍。
一、數據的表示方式
我們都知道,現實生活中,數字的表示方式有很多種,常見的有二進制、八進制、十進制和十六進制。十進制我們都很熟悉,加法口訣表我們都背過,主要是使用0~9,這10個阿拉伯數字來構建整個十進制的體系,其中最核心的法則是“逢十進一”,借位則是“借一當十”。那麼為什麼全世界不管什麼國家,什麼歷史,什麼文化水平基本都是用十進制作為基本進制呢?是因為我們人有10個手指頭,掰起來最方便!我們對十進制有着天然的友好度。

那麼對於計算機呢?計算機不是人,沒有10個手指頭可以掰,所以它用不了十進制。那麼它用幾進制?二進制!二進制是用0和1兩個數碼來表示的數,也就是形如010101010的樣子。它的基數為2,進位規則是“逢二進一”,借位規則是“借一當二”。

為什麼計算機要使用二進制作為自己的機器語言也就是數據的表示方式呢?因為計算機最小的計算單元是根據開關狀態高低電平來確定的,它只有開和關,高和低的概念,換成數學就是0和1的兩種。同樣的,在物理存儲方面,硬盤的磁道只能區分打孔和未打孔的狀態,也是0和1兩種。同時二進制便於進行加、減運算和計數編碼。二進制與十進制數易於互相轉換。二進制便於邏輯判斷(是或非),邏輯判斷通常也是兩種狀態,這和二進制很搭配。二進制表示數據還具有抗干擾能力強,可靠性高的特點,因為當受到一定程度的電磁干擾時,只要可以分辨出它是高電平還是低電平,至於高多少或低多少並不重要,就能區分0和1,這在網絡信號中,就是天生自帶抗干擾能力。
但是,在人機交流上,二進位制有致命的弱點,數字的書寫特別冗長,並且沒有人類可讀性!例如,十進位制的100000寫成二進制就是11000011010100000,長了好幾倍,而且你能從一個這麼長的二進制數里讀出它的十進制數是多少嗎?
計算機不能獨立存在,目前也無法自我創造,不管是輸入還是輸出,它的一切都必須和人交流。那麼問題來了,人類只能讀10進制和英語、漢語等,可計算機只會010101,至於英語、漢語對它而言更是天書。那麼我們是怎麼和計算機交流的呢?怎麼將我們的英語或者漢語編碼成計算機能夠識別的1010101呢?
二、 編程語言發展歷程
1. 打孔紙條
我們已經知道了計算機只懂機器語言,也就是二進制的數據表示方式,任何對它的操作和編碼,最終都要統一到這上面來,然而這是一個悲傷的故事。

起初,為了讓計算機按我們的想法工作,程序員不得不編寫計算機可以讀懂看明白直接執行的機器碼,也就是01010101的樣子,打孔字條就是這麼乾的。用打沒打孔來代表0和1。OK,計算機沒問題,它能無障礙閱讀,可程序員就難受了。拍腦袋也能想得到這裏面的問題。容易出錯,效率低,編寫困難,維護困難。可能就是個簡單的打印“hello world”,也許就需要好幾米長的字條。這簡直就是原始社會,生產效率低下的令人髮指。發生個火災什麼的,直接Over。唯一的好處就是無需轉換,可直接執行,但相對缺點來講,這點好處完全可以被忽略。
2. 彙編語言
彙編語言是一種可編程器件的低級語言,亦稱為符號語言。在彙編語言中,用助記符代替機器指令的操作碼,用地址符號或標號代替指令或操作數的地址。在不同的設備中,彙編語言對應着不同的機器語言指令集,通過彙編過程轉換成機器指令。也就是說不同平台之間不可直接移植,它是平台相關的,你在這個硬件平台寫的彙編程序,換到另外一套硬件上去是運行不了的。 因此,彙編語言通常被應用在底層,硬件操作和高要求的程序優化的場合。驅動程序、嵌入式操作系統和實時運行程序較多使用彙編語言。相比於機器碼,它更偏向人類的語言習慣,更易於編寫和閱讀,也就是有一點抽象符號概念化了,這大大提高了編程效率。但是,這依然是一種低級語言,還有改善和提高的空間。
上面一段看得暈沒關係,簡單地說就是彙編語言相比打孔紙條,對人類更友好一點了,至少能用幾個類似ADDCALLMOV的英文縮寫了。但是,它犧牲了一定的性能,並且依然不夠友好。
3. C語言
在C語言之前其實還有很多低級語言,我們不關心它們。為了讓編程更簡單,更高效,聰明的計算機程序員,一步步發明了FORTRAN、BASIC、B等許多語言,然後在1972年誕生了無人不知,應用最廣,影響最深,至今仍然地位不可動搖的C語言。
C語言為什麼這麼厲害?歸根結底是一句話:直接操作硬件!同樣的算法,用C語言,其執行效率超過JAVA等語言很多。那可能有人會問,C和彙編和機器碼比呢?肯定是C慢,但是寫個彙編程序和寫個C程序的效率差別那就更大了。C語言在人類友好性和底層相關性上達到了一個高度的平衡。這兩者是互相矛盾的,不可同時兼得。
C幹了些什麼?其實它就是在人類友好性方面相比以前跨出了更大一步。人類是方便了,可機器就迷糊了!你給我這麼多字符都是啥意思?機器它只懂二進制啊!那麼C的代碼是如何被執行的呢?這就得請出編譯器了!
編譯器將編程語言寫的代碼翻譯成機器能夠執行或者說“看懂”的二進制機器碼。
其實我們安裝JAVA也好,C也好,Python也罷,主要就是安裝的這個編程語言的“編譯器”。
4. Python語言
在幾十年前,C語言是當之無愧的高級語言代表,現在也依然是語言排行榜第二的霸主。然而,在很多領域,它已經不太適用了,現今更主流的語言是那些上手快、簡單易懂,說白了就是門檻低的語言,讓更多的人能進入程序員行業,讓編程能更容易、更快是未來的發展趨勢。也就是說,需要進一步讓編程語言更貼近人類語言,更遠離機器語言。
Python就是這麼一種語言。它的語法簡單明了,更貼近人類的使用習慣。作為一種動態解釋性語言,讓人們在寫代碼的時候可以更多的關注業務邏輯細節,而不需要花太多精力去關注數據類型定義、程序運行效率等!
既然都說的是機器不懂的“人話”,那必然也需要一個Python“編譯器”。對於Python語言,廣義上的“編譯器”,叫做解釋器。
三、 編譯器與解釋器
編譯器/解釋器:高級語言與機器之間的翻譯官
都是將代碼翻譯成機器可以執行的二進制機器碼,只不過在運行原理和翻譯過程有不同而已。

那麼兩者有什麼區別呢?
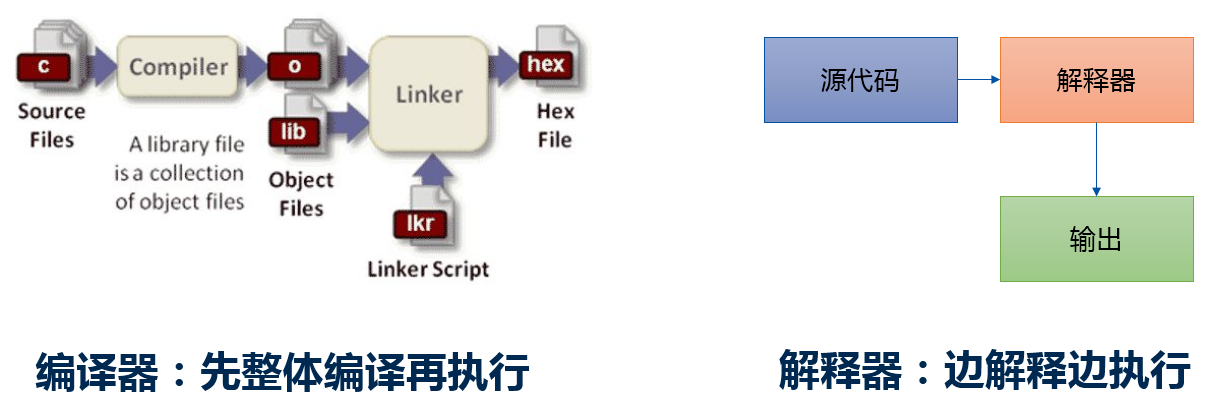
用一個通俗的例子進行比喻:我們去飯館吃飯,點了八菜一湯。編譯器的方式就是廚師把所有的菜給你全做好了,一起給你端上來,至於你在哪吃,怎麼吃,隨便。解釋器的方式就是廚師做好一個菜給你上一個菜,你就吃這個菜,而且必須在飯店裡吃。

至於更深入的編譯器和解釋器是如何工作的,請參考史詩巨著《編譯原理》,這本書有個外號,叫做“龍書”。

四、 Python解釋器種類
Python有好幾種版本的解釋器:
CPython:官方版本的解釋器。這個解釋器是用C語言開發的,所以叫CPython。CPython是使用最廣的Python解釋器。我們通常說的、下載的、討論的、使用的都是這個解釋器。
Ipython:基於CPython之上的一個交互式解釋器,在交互方式上有所增強,執行Python代碼的功能和CPython是完全一樣的。CPython用>>>作為提示符,而IPython用In [序號]:作為提示符。
PyPy:一個追求執行速度的Python解釋器。採用JIT技術,對Python代碼進行動態編譯(注意,不是解釋),可以顯著提高Python代碼的執行速度。絕大部分CPython代碼都可以在PyPy下運行,但還是有一些不同的,這就導致相同的Python代碼在兩種解釋器下執行可能會有不同的結果。
Jython:運行在Java平台上的Python解釋器,可以直接把Python代碼編譯成Java位元組碼執行。
IronPython:和Jython類似,只不過IronPython是運行在微軟.Net平台上的Python解釋器,可以直接把Python代碼編譯成.Net的位元組碼。
五、 Python的運行機制
Python作為動態解釋性語言,其運行機制可參考下圖(圖片來自網絡,其中的“編譯器”是對解釋器的廣義稱呼):
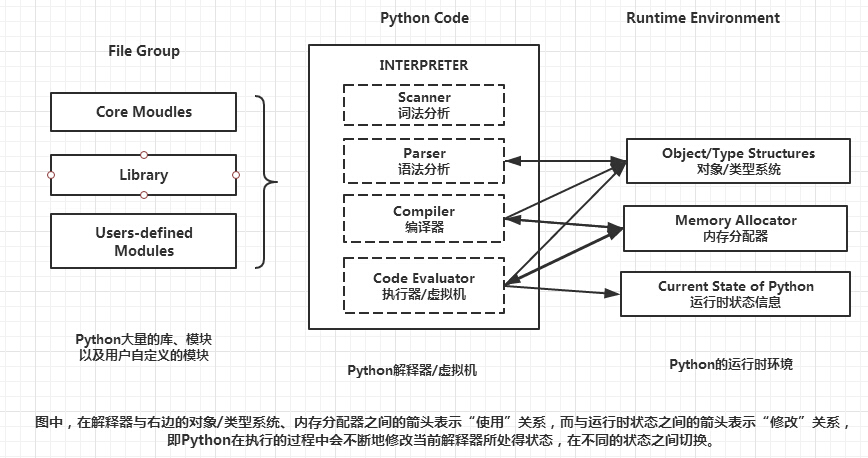
都說解釋器慢,Python也有想辦法提高一下運行速度的,那就是使用pyc文件。這點參考了JAVA的位元組碼做法,但並不完全類同。
我們編寫的代碼一般都會保存在以.py為後綴的文件中。在執行程序時,解釋器逐行讀取源代碼並逐行解釋運行。每執行一次,就重複一次這個過程,這其中耗費了大量的重複性的解釋工作。為了減少這一重複性的解釋工作,Python引入了pyc文件,pyc文件是將py文件的解釋結果保存下來的文件,這樣,下次再運行的時候就不用再解釋了,直接使用pyc文件就可以了,這無疑大大提高了程序運行速度。
對於pyc文件,你必須知道以下幾點:
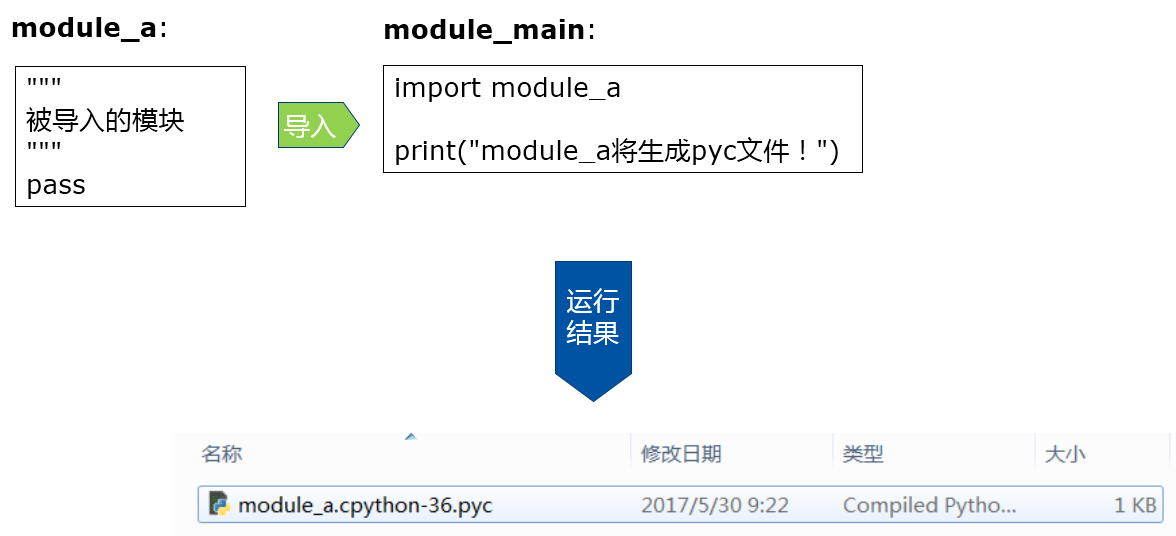
- 對於當前調用的主程序不會生成pyc文件;
- 以import xxx或from xxx import xxx等方式導入主程序的模塊才會生成pyc文件;
- 每次使用pyc文件時,都會根據pyc文件的創建時間和源模塊進行對比,如果源模塊有修改,則重新創建pyc文件,並覆蓋先前的pyc文件,如果沒有修改,直接使用pyc文件代替模塊;
- pyc文件統一保存在模塊所在目錄的__pycache__文件夾內。
如下圖所示,modula_a被module_main導入後會生成對應的pyc文件,但是module_main不會生成pyc文件!!