從MySQL大量數據清洗到TiBD說起
從MySQL大量數據清洗到TiBD說起
一、業務場景:
公司主要做的業務是類似貝殼的二手房租售,公司數據庫存了上億級別的房源數據,之前的數據庫使用的是 mysql,後面需要將mysql數據庫切換成了 Tidb,在切換的過程中,需要將老庫的數據經過數據清洗後再存入新庫(因為有一些表的設計變了),其中我處理的一個邏輯就是將房間下業主信息從老庫清洗到新庫,那麼我們需要查詢新庫所有的房間,然後拿着新老庫的房間對應關係,然後到老庫中的對應房間,然後再找到每個房間對應業主信息,然後將業主的不同維度信息清洗到新庫不同的數據表中。下面我就簡單描述一下數據清洗過程中遇到的各種問題已經解決方案,所有問題都會附上真實的案例。
二、從問題入手選定處理方案:
問題:
1、在清洗過程工,我們無法將某個城市的幾百萬甚至上千萬的房間信息一次性查詢出來,再去找所有房間的業主信息,這樣內存肯定會撐爆;
2、數據清洗過程中肯定不能一條一條的新增數據,這樣的話幾百萬(舉例300W)的房間數據,如果有5個維度需要新增數據,那麼就會一條一條的新增300W房間對應維度的數據,就會操作 300W*5 次,效率低下;
3、數據清洗後批量插入新表的時候也不能一次性插入300W(每個表插入300W,5個維度分別插入5個表,即插入5次300W的數據)。
處理方案:
先查詢出需要清洗的數據總量,然後按照某個量(比如:1000條)進行分頁查詢出具體的數據,然後清洗這1000條房間對應維度的數據並插入新庫中,再清洗下一個1000條數據,直到把所有數據清洗完成。
三、按照上面選定的處理方案,分頁進行清洗數據
在上面處理方案出來後,下面就是在程序開發過程中遇到的一些具體問題,分頁查詢的邏輯其實就是常用的 SQL 的 limit m, n,通過 page 和 pageSize 來進行分頁查詢,再使用 limit m,n 進行分頁查詢的時候又遇到下面幾個問題:
a、分頁查詢查詢和處理新增數據,按照多大的維度來出來,是一次性查詢5000條房間還是1000條房間來處理對應數據的清洗,查詢和處理多少條數據的效率最高效?
b、如果一次性查詢和處理較少的數據量,比如每次分頁查詢出100條數據來進行清洗,如果某城市有800W的數據,分頁查詢需要查詢處理80000次,這個處理次數是否過多?
c、使用常規的 limit m,n 的方式進行分頁查詢,那麼越查詢到靠後的頁數( limit m,n 語句的查詢時間與起始記錄的 m 位置成正比)查詢就會變得越慢,如何處理?
解決方案:
註:下面所有的數據都是在公司的機器上面得出的效率數據,大家在使用的時候以實際為準,這裡只是提供解決思路
1、下面先附上一張我們和DBA的聊天來引出問題:
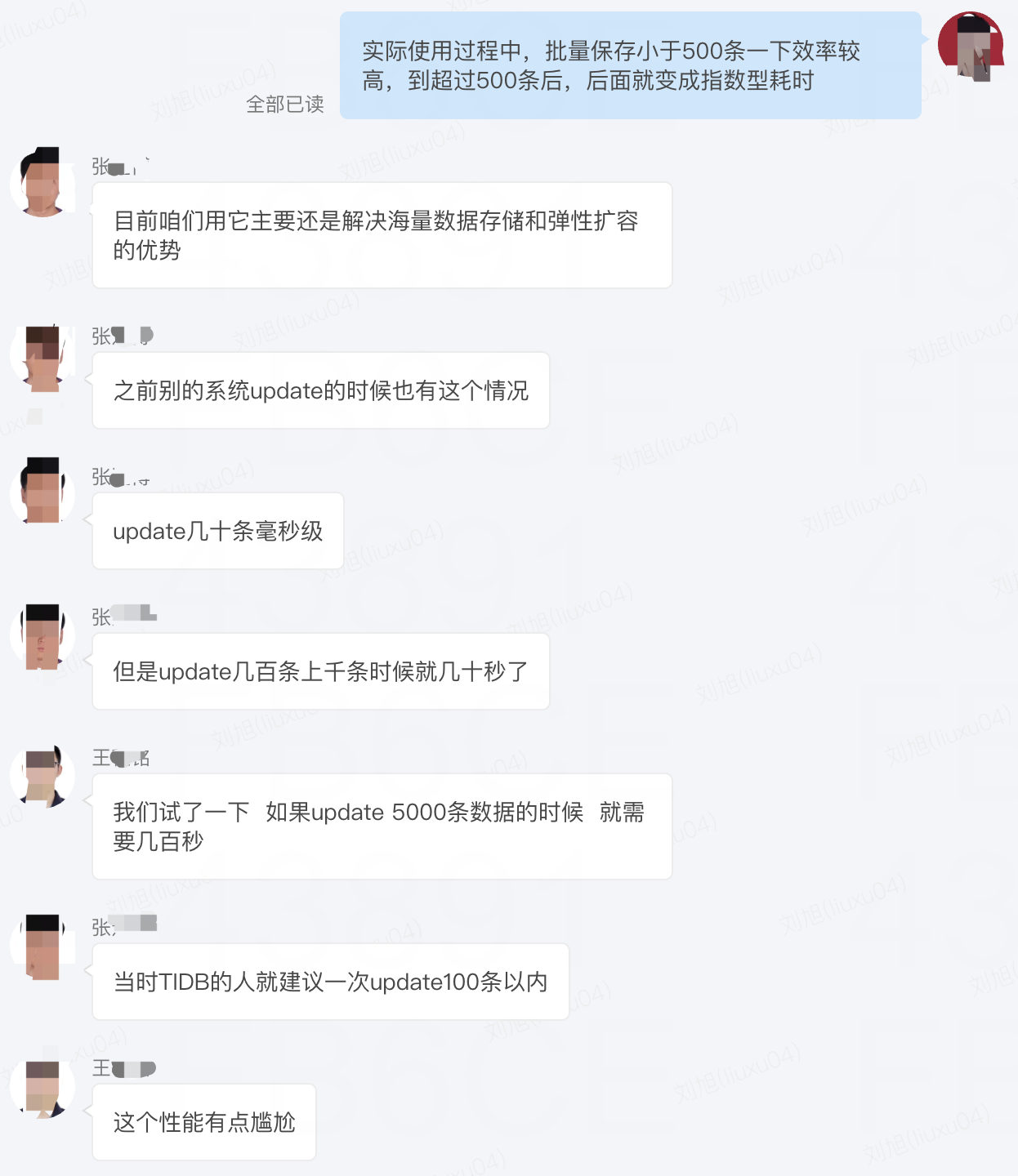
公司大量業務都開始使用TiDB,很多數據都需要從MySQL遷移到TiDB,在遷移過程中,批量新增都會遇到一個問題,就是隨着批量新增的數據量變大,耗時巨慢,DBA說的是100條以內就非常快,那麼這個條數多少條對於我們業務處理是最合理的啦?下面就是一個論證過程?
下面直接上數據,後面會對數據進行說明:
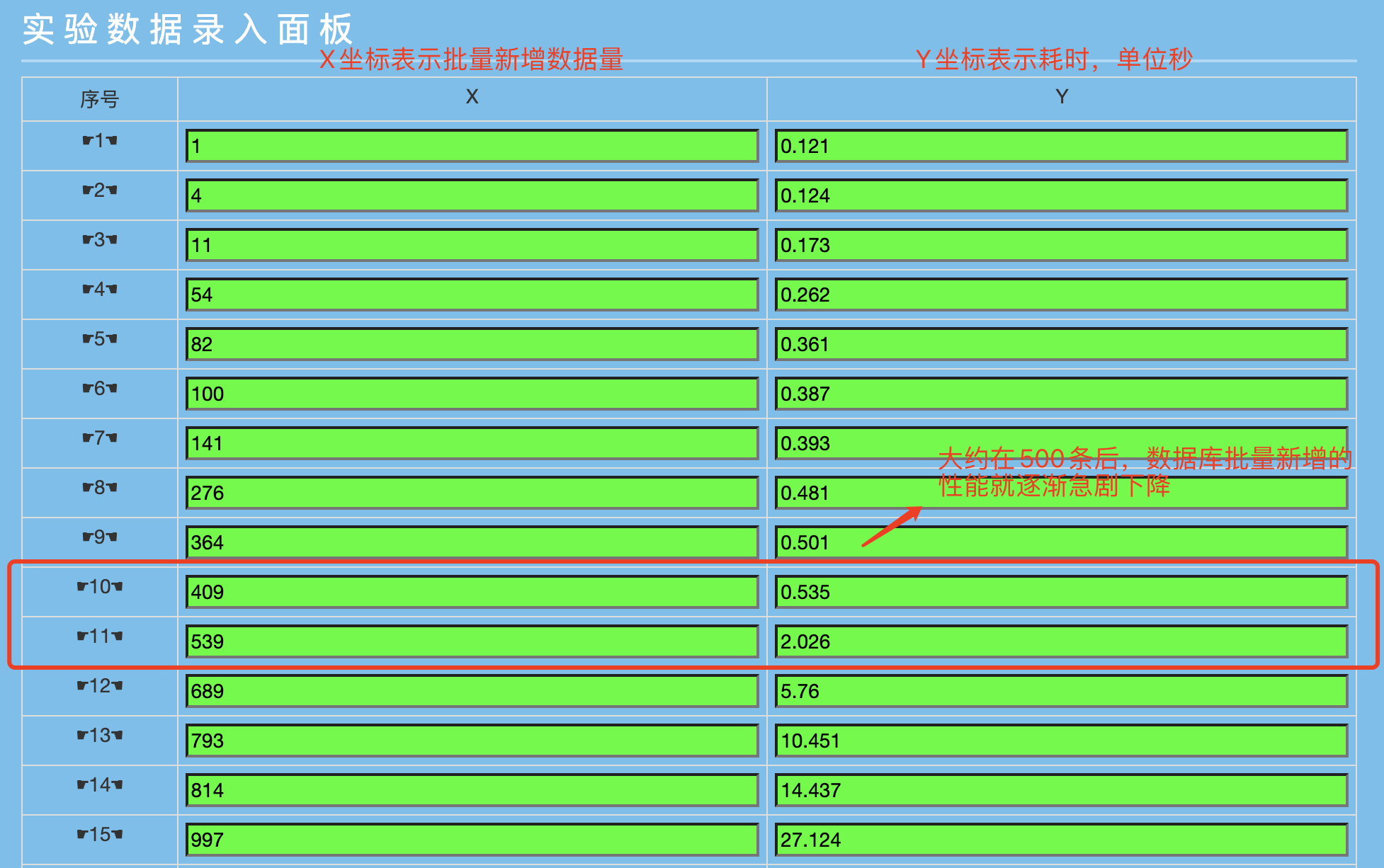
關注(注意橫縱坐標的含義):
批量新增409條數據變成539條數據,耗時卻從0.535變到2.026秒,多了130數據,耗時卻多了1.5秒左右;
批量新增536條數據到689條,多了150條數據,耗時確多了3秒多;
批量新增689條到793條,數據多了104條數據,耗時確多了5秒;
批量新增793條到997條,數據多了204條,耗時確多了17秒。
根據上圖生成的數據耗時性能坐標圖,斜率越低說明性能越好。

從圖中粗略的可以看出,在409到539條之間,應該有一個合理的性能保證值,我們姑且認為大概在批量處理500條的時候,性能是一個分水嶺,即:在批量處理500條房間以內對應的數據,性能較好,超過500條後性能開始按照指數增長的方式下降。(註:為了表明數據的真實性,不是我自己瞎編亂造的數據,附上公司數據清洗的幾張 log 日誌圖,用於說明情況。)

批量處理1條房間對應的數據,耗時0.121秒

批量處理54條房間對應的數據,耗時0.262秒

批量處理276條房間對應的數據,耗時0.481秒

批量處理409條房間對應的數據,耗時0.535秒

批量處理539條房間對應的數據,耗時2.026秒
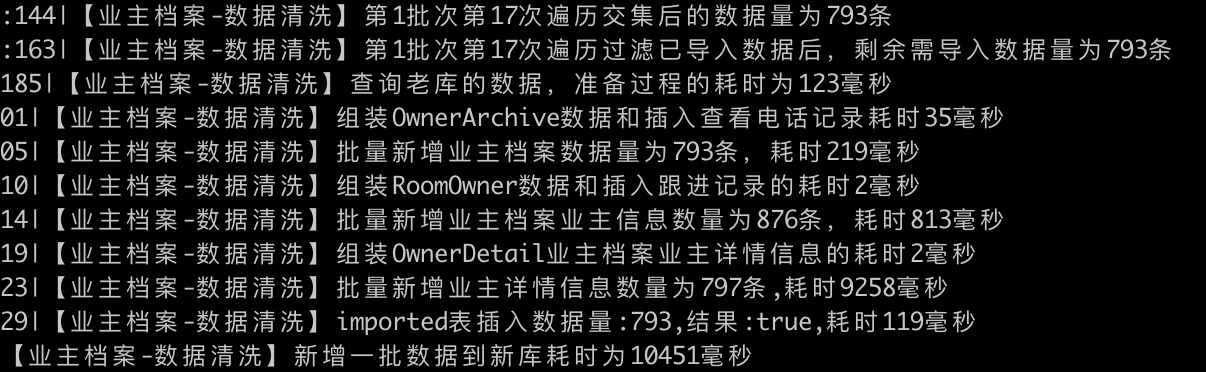
批量處理793條房間對應的數據,耗時10.451秒

批量處理997條房間對應的數據,耗時27.124秒
說明:從日誌可以看出,我們批量新增對應 m 個房間對應的數據,實際上需要處理6個維度(5個業務維度+1個清洗記錄維度)的數據:
1、房間對應【業主檔案維度】;
2、房間對應【查看電話記錄信息維度】;
3、房間對應【跟進記錄信息維度】;
4、房間對應【業主基本信息維度】;
5、房間對應【業主詳情信息維度】;
6、房間對應【導入記錄維度】(防止重複導入)。
即:一個房間信息,可能下面沒有聯繫人的信息,所以該房間就沒有業主檔案,也可能有多個聯繫人,那麼這時就會有業主檔案,並且該業主檔案就對應多個業主信息(業主詳情信息要根據查詢看是否存在業主詳情信息),並且該房間下的業主,如果經濟人跟進維護及時,那麼就會有多條查看電話記錄信息和跟進記錄。
所以在查詢1000條的房間信息的時候,實際導入數據的效率取決於我們剩下5個業務維度的數據量,在此次文檔中我們暫且按照1個房間信息分別對應1條業務維度來說明,實際業務可以根據自身實際導入時間來處理。我們來看下面這兩個1000條房間對應998條數據的導入時間:

從上面也可以看出來,處理998條房間時,對應5個業務維度(業務維度數據字段較多)都比較耗時,其中批量新增查看電話記錄耗時10秒+(這個日誌當時沒有記錄插入多少條記錄查看電話記錄數據,後期優化一下以便更加清楚的查看插入數據的耗時情況),而批量新增業主檔案信息也是在1300+條數據,耗時也是在10秒左右。就這個也不難看出,單獨批量插入1000條左右的數據,性能也比較低。
總結如下,在批量新增數據的時候,插入數據的耗時:
(1)和你的業務數據複雜度有關,插入1000條2個字段肯定比你插入1000條同級別類型的20個字段數據快很多(大家這時回看上面的所有日誌,從1條到998條,會發現倒數第二行插入imported表的數據都比較快,都在是150毫秒以內,是因為我們imported和業務無關,是用來記錄我們哪些房間數據已經被清洗了,下一次清洗的時候防止重複清洗,所以插入的數據字段較少,性能從1到998變化不大,但不大並不表示沒有,觀察發現隨着數據量增多耗時也在增多,如果單獨統計imported的批量新增性能變化點可能是在5000,也可能是在8000,但是這個對於我們業務沒有意義,也不是我們這個清洗的瓶頸點,所有我們整篇討論是建立處理對應N條房間的維度,而不是某一個業務維度的耗時,因為單個維度耗時對於我們業務是沒有統計意義,也無法對我們整體數據清洗性能優化提供太多的幫助)。
(2)插入的數據在某個值的時候性能會變低,那麼我們在批量新增的時候盡量不要超過這個值,按照我們業務測試來看是在500條左右。
2、上面討論的是每一次處理,即批量處理大概在多少條數據比較合理,下面討論的就是我們在處理分頁查詢的問題。
在分頁查詢時,我們使用普通的 limit m,n 每次查詢1000條房間數據來處理,整個過程如下:
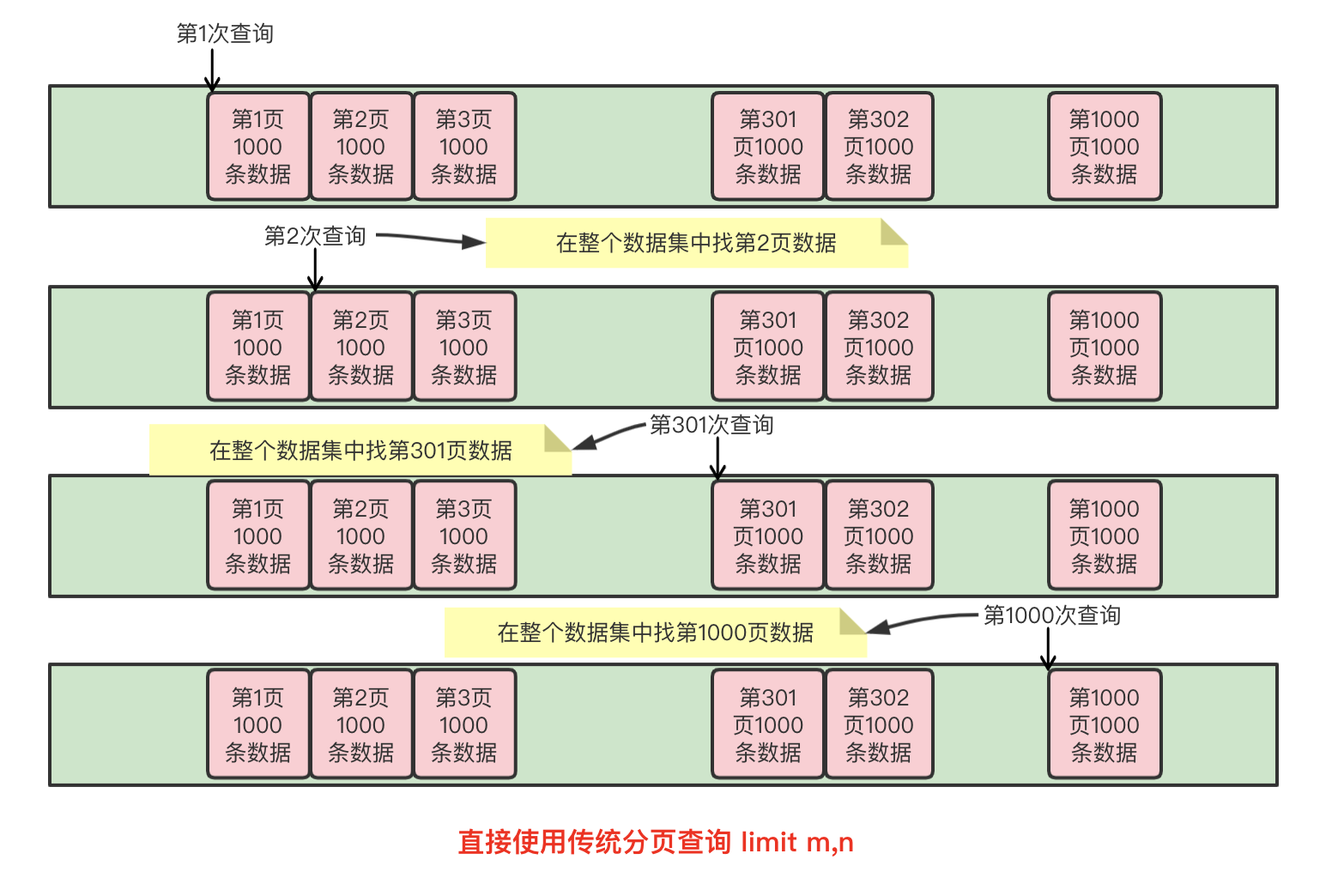
使用常規的 limit m,n 的方式進行分頁查詢,那麼越查詢到靠後的頁數查詢就會變得越慢( limit m,n 語句的查詢時間與起始記錄的 m 位置成正比),日誌分頁查詢變慢截圖如下:
![]()
![]()
![]()
![]()
![]()
從上面幾張圖可以明顯看出,當查詢到後面分頁的數據的時候,耗時明顯增加(這個是最早開始清洗的時候,已經沒有日誌文件了,截圖是之前和DBA聊天的截圖,所以比較模糊,系統只保留最近一個月的日誌記錄,從截圖看查詢速度還比較快,是因為剛開始清洗到系統的房間較少,所以查詢前幾十頁都是幾百毫秒內)。
那麼如何解決這種查詢啦?那麼我們可以通過主鍵來限制每次查詢的數據集,即後一次查詢的查詢範圍應該排除之前已經查詢過的數據,這種思想有點類似於移動游標,每次查詢通過主鍵 rid,查詢的範圍保證 rid> m ,這個 m 是上一次查詢記錄的最大值(所以在查詢的時候需要主鍵排序),於是查詢就變成了where rid > m limit 0 , n ,其中 m 就充當了游標點,通過移動游標,查詢指定 n 條數據,這時游標的作用就有兩個:1、定位查詢的數據 2、縮小查詢數據集範圍。
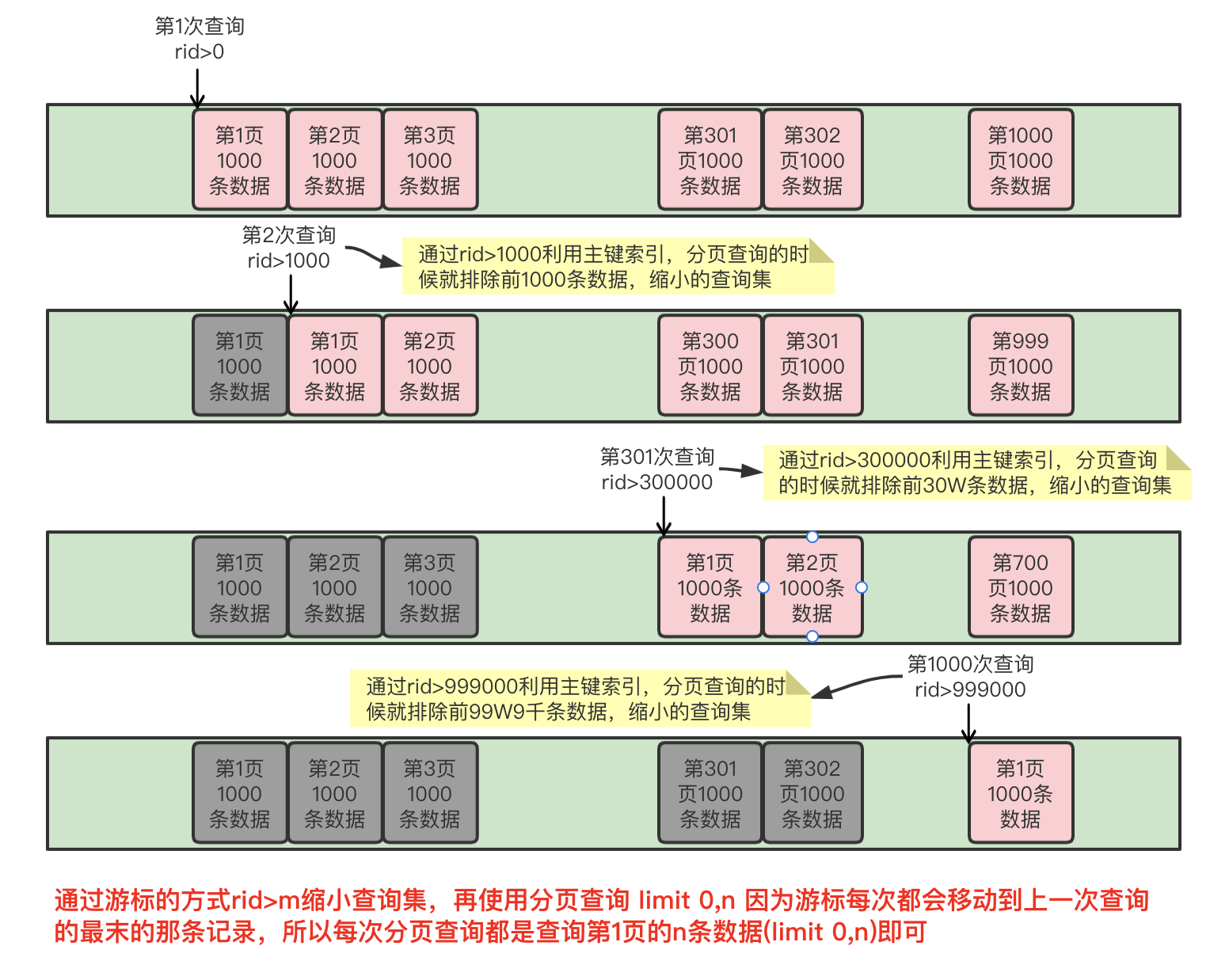
總數據量是3430173條數據,1000條清洗一個批次,需要清洗3431批次,從0開始計數要清洗到3430批次結束

加入游標後查詢的速度加快,日誌截圖如下(查詢的數據最開始是在6秒左右,是因為現在清洗過來的房間數據已經好1000W+的數據,所以大家看到查詢的數據是從6秒開始)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
總結:通過主鍵id值的移動來實現游標的方式控制查詢的數據集的大小,將查詢耗費時間隨着查詢分頁的後移來而變得越來越短。
3、我們雖然優化了分頁查詢效率的問題,但是從上圖我們不難看出,如果100W的數據量進行分頁查詢還是會經理1000次的查詢,那麼我們如何解決多次查詢的問題?我們最早的問題告知我們不能一次性查詢百萬或者千萬條數據,因為這樣內存吃不消,但是我們換種思路,也不是說一次只能查詢最優分頁查詢的數據量(解決方案第1步中統計出來是500條左右),於是有了下面的演進:
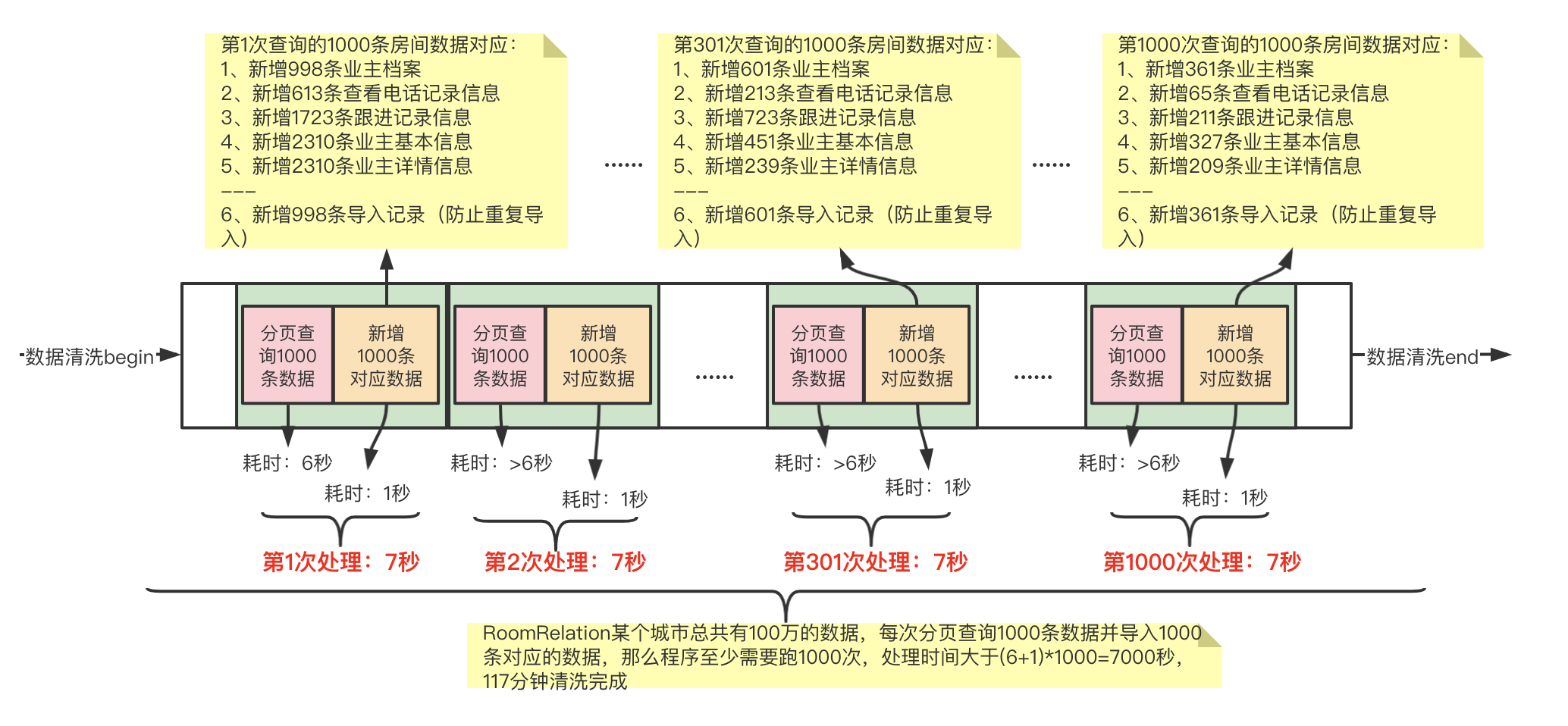
通過內存存儲減少查詢次數,我們給到外部的貌似是1000條一頁一頁的查詢,實際我們會一次查詢大於1000條數據,下面以2W舉例,就是分頁查詢的時候我們是一次性查詢2W條數據,然後遍歷每1000條處理一次,直到2W條數據處理完成,在分頁查詢下一個2W條到內初進行處理,依次類推,直到處理完成。

總結:減少查詢次數,不能一次性查詢出上百萬的數據,那我一次性查詢出1W或者2W的數據,然後利用內存再將這2W的數據進行1000條按照一批次處理,這樣就將20次分頁查詢變成了1次分頁查詢+20次內存運算處理。從而大大加快數據清洗的效率。
四、數據清洗說明
在實際數據清洗過程中,還有很多複雜邏輯,不過都是偏業務層面,沒有分享出來的必要性;其次上面的數據,如各種性能的值需要根據各自業務數據的複雜性自行測試,找到各自性能的最優處理值。
思考:
1、由於我們業主檔案列表分頁查詢,查詢過程因為是以房間為維度,關聯分期、樓棟、業主檔案表(後面還加了7天聯繫記錄)等,從文章的開頭大家都看到過成都、上海的房間數據都超過了700W+的數據,那麼在關聯多個表查詢,固然會存在查詢效率慢的原因,我們除了在SQL層面本身進行優化,是否可以利用到上面的一些思想?比如用戶查詢1、2、3、4…等分頁(假如每頁20展示條)數據,我們是否只需要真實的查詢出第一頁數據(快速響應),然後利用假分頁,如查詢出200條數據放入內存,並設置過期時間,假如用戶翻頁到9頁(一共緩存10頁數據)的時候,提前把下一個200條數據查詢出來?對於客戶來說,他的分頁是正常分頁,而我們在底層代碼通過假分頁和真分頁呈現數據,並且因為我每次只緩存了200條數據,多個用戶操作,不會影響我緩存的內存,其次因為我緩存數據較少,且都設置過期時間,數據實時性也能得以保障。另外如果有統計功能,其實第一頁也是可以通過分析用戶的查詢行為進行定期緩存。這樣就在滿足業務複雜業務需求的同時,保證客戶的使用體驗。
2、數據清洗的動態配置,下面先來兩張圖片說明情況:

這個是某次清洗房間關聯表(新庫房間id和老庫房間id的對應關係)84W+的數據,而其中存在業主檔案的數據量卻只有28974,大概就是每1000個房間有3.4條對應業主檔案可能需要清洗。

而第二張圖是另外一個城市,房間關聯表只有27171條數據,對應的可能存在業主檔案的數據有22635條,就是大於1000條房間數據有833條對應業主檔案可能需要清洗。
因為我們默認是每1000條房間清洗一次,那麼上面第一種情況每一批次1000條數據只有3.4條左右的業主檔案被清洗到新庫中,離性能最優點500差的有點遠,故性能有點浪費。第二種情況每一批次1000條數據又有833條左右的業主檔案需要被清洗到新庫中,離性能最優點500也差的有點遠,這時我們這個每批次清洗1000條對應房間的數據就有點設置不太合理,於是我們可以通過這幾個值動態生成需要清洗每批次的數據量,來保證每批次清洗數據在500條左右,使得每次清洗都可以在最優的效率下執行。


