什麼樣的代碼是好代碼?
- 2019 年 10 月 3 日
- 筆記

關於什麼是好代碼,軟件行業爛大街的名詞一大堆,什麼高內聚、低耦合、可復用、可擴展、健壯性等等。也有所謂設計6原則 — 迪米特法則(最少知道原則) + SOLID :
即Single Responsibility (單一職責),Open Close(開閉),Liskov Substitution(里氏替換),Interface Segregation(接口隔離),Dependency Inversion(依賴反轉)
詳情可參考: https://www.cnblogs.com/huangenai/p/6219475.html
不喜歡這些抽象名詞,我們搞點簡單明了的。一匹跑得快(運行速度快),少生病(健壯),可以馱載各類貨物(可擴展),容易辨識(容易看懂),病好治(bug好發現),高大英俊的千里汗血馬是也

什麼是好代碼,不好定義,但是關於什麼是代碼里的“壞味道”,比較容易搞清楚。避免代碼里的“壞味道”,離好的代碼就不遠了,壞味道一二三及推薦做法:
- 代碼重複
- 函數太長
如果太長(一般不宜超過200行,但不絕對),你自己都不太容易讀懂,請不要猶豫,拆成小函數吧。筆者剛畢業,參與一個大型複雜的金融軟件,核心業務類,函數1000行算小case,5000多行的不在少數,我的內心是哇涼哇涼的,還好大致邏輯比較清晰
- 類太大
一般不宜超過1000行,同樣不絕對,jdk源碼過千行的不少嘛。還是那個大型複雜的金融軟件,核心的幾個Algo C++文件,2萬到3萬行,我的心在滴血
- 數據泥團
即很多地方有相同的三四項、兩個類中有相同的字段、許多函數簽名中有相同的參數。把這些應該捆綁在一起的數據項,弄到一個新的類里吧。這樣,函數參數列表會變短不少,簡單化了
- 函數參數列表太長
工作中有7個參數的函數調用,搞清楚每個參數的業務含意,和順序有點頭暈。儘管可能有默認函數參數,不小心的時候范過錯誤,後面直接引入一個線上bug,緊張
- 變量名、函數名稱、類名、接口等命名含義不清晰

圖02 程序員最頭疼的事
苦命的天朝程序員,還要把中文翻譯為英文,我也很頭大鴨。函數名能讓人望名知義,看名字就知道函數的功能是啥,以至於幾乎不需要多少comments最好
通常DAO層函數的命令規範是:“操作+對象+通過+啥”,如:updateUserById, insertQuarter,delteteUserByName
- 太多的if else
- 在循環里定義大量耗資源的變量
大對象,如果可以放在循環外,被共享,節省時間空間
- try 塊代碼太長
try塊只包住真的可能發生異常的語句,最小原則,同樣因為try包起來的代碼要有額外開銷
- 不用的資源未及時清理掉,流及時關閉
如IO句柄、數據庫連接、網絡連接等。不清理掉,後果很嚴重,你若不信,軟件就死給你看

- try-finally醜陋,明顯更愛try-with-resources
1)醜陋的
static String firstLineOfFile(String path) throws IOException{ BufferedReader br = new BufferedReader(new FileReader(path)); try { return br.readLine(); } finally { br.close(); } }
2)漂亮的小姐姐
static String firstLineOfFile(String path) throws IOException{ try (BufferedReader br = new BufferedReader(new FileReader(path))) { return br.readLine(); } }
- 循環里字符串的拼接不要用”+“
有改過一個OutOfMemery的bug,字符串拼接用”+“,產生了一百多萬的字符串變量。用Visual VM看程序佔用內存空間比較多,數量最大的,通常都是String,所以用StringBuilder的append吧。
用Java VisualVM截取的一個dump,如下圖:

從中可以看出,字符char和字符串String 實例數和內存大小佔比都比較高。
- 太巨量的循環,看情況用乘除法和移位運算
移位運算吧,通常速度略微快於乘除法。測試代碼如下:
int temp; long before = System.currentTimeMillis(); for (int i = 0; i < 10000000; i++) { temp = 2 * 8; temp = 16 / 8; } long after = System.currentTimeMillis(); System.out.println(after - before); before = System.currentTimeMillis(); for (int i = 0; i < 10000000; i++) { temp = 2 << 3; temp = 16 >> 3; } after = System.currentTimeMillis(); System.out.println(after - before);
運行結果,分別為{269,279 }、 {258, 317} milliseconds,驚不驚喜,意不意外,乘除法比移位運算更快。看了下stackoverflow,具體得看處理器,現代處理器好多對於乘除已作優化。
如果乘除法業務更清晰,就用乘除法。基本上,移位運算不會慢於乘除法,但是移位運算不易理解
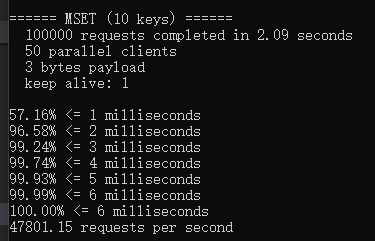
參看redis 源碼(5.05版本)之 “rehashing.c”里hash key計算的代碼片段如下(hash key的計算使用頻率很高):
看下redis-benchmark基準測試的數據,寫Set = 47801/Second,筆者12年的老電腦(Intel i5-2450M, 2.50GHz),速度很可觀,應該是代碼寫的牛逼加C本身執行效率較高
- 避免運行時大量的反射
不知道Java社區為什麼不太關注反射耗時的問題,以前寫C#都會謹慎使用,C#社區有專門討論反射優化。關於反射的不好的地方:
1) 編譯時沒法檢查了
2)反射的代碼冗長和醜陋
3)性能損耗
推薦做法:用反射的方式創建實例,然後通過接口或者其超類在來訪問這些實例
- 基本類型優於裝箱基本類型
基本類型更快,更省空間。避免不經意引起自動裝箱和拆箱。是否相等的比較,”裝箱基本類型”可能會出錯。下面的代碼顯示了無意識的裝箱:
private static long sum() { Long sum = 0L; for (long i = 0;i <= Integer.MAX_VALUE; i++) { sum += i; } return sum; }
我的電腦測出來,運行時間為11906 milliseconds;將“Long sum” 改為” long sum”後,運行時間降低為2027 milliseconds
- 避免創建不必要的對象
String s = new String(“bikini”),每次執行該語句都會創建一個新的String實例,如果在循環或者頻繁調用的方法里,將創建成千上萬多餘的String實例。應改為 String s = “bikini”
又如有些對象的創建成本比其他對象搞得多,又有地方需要反覆調用此“昂貴的對象”,建議緩存之然後重用,例如羅馬數字的判斷:
1)醜陋的
static boolean isRomanNumeral(String s) { return s.matches("^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})" + "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$"); }
2)漂亮的小姐姐
public class RomanNumeral { public static final Pattern ROMAN = Pattern.compile("^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})" + "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$"); static boolean isRomanNumeral(String s) { return ROMAN.matcher(s).matches(); } }
- 未作參數有效性檢查
不搞這個,NullPointerException等妥妥地
- 延遲初始化和懶加載
這個的確是一種優化,即需要用到它的值時,才初始化。如果永遠不用到,就永遠不會被初始化。但要慎用,只有在初始化這個數據域開銷很大的時候才用。在大多數情況下,
正常的初始化要優於延遲初始化。
1)如果出於性能的考慮對靜態域使用延遲初始化,就需要使用 lazy initialization holder class 模式,示例代碼如下:
private static class FieldHodler { static final FieldType field = computeFieldValue(); } private static FieldType getField() { return FileHodler.field; }
2)如果出於性能的考慮對實例域使用延遲初始化,就需要使用雙重檢查模式(double check idiom) 模式,示例代碼如下:
private volatile FieldType field; private FieldType getField() { FieldType result = field; if (result == null) { synchronized (this) { if (field == null) field = result = computeFieldValue(); } } return result; }
- LinkedHashMap、HashMap、ArrayList、HashSet、HashTable等集合類,沒有初始化容量
如果大致知道業務場景下這些集合類的數量,初始化個容量吧。如ArrayList默認 DEFAULT_CAPACITY = 10,resize代碼如下:
newCapacity = oldCapacity + (oldCapacity >> 1);
如最終存放100個數據,則最後的容量 = ((10 + 10 * 2) * 2 + 30)) * 2 + 90 = 270, 會有4次重新分配內存和拷貝,費時間啊,我也懶,想耍啊
- 方法和類如果確實有業務場景需求不會被覆蓋、不會被繼承,用final修飾吧
final method在某些處理器下得到優化,跑得更快
參考: https://stackoverflow.com/questions/5547663/java-final-method-what-does-it-promise
- 合理數據庫連接池和線程池
一個減少數據庫連接的建立和斷開(耗時),一個減少線程的創建和銷毀,動態根據請求分配資源,提高資源利用率
- 多用buffer等緩衝提高輸入輸出IO效率及FileChannel.transferTo、FileChannel.transferFrom和FileChannnel.map
1) 諸如 BufferedReader 、BufferedWriter、BufferedInputStream和BufferedOutputStream等
在杭電ACM online judge平台上,對於大數據量的輸入和輸出,BufferedReader和PrintWriter的性能遠高於Scanner和println
參考:http://acm.hdu.edu.cn/faq.php?topic=java
2) FileChannel.transferXXX減少數據從內核到用戶空間的複製,數據直接在內核空間中移動
FileChannel.map按照文件的一定大小塊映射為內存區域,也不用從內核空間向用戶空間拷貝數據 ,只適用於大文件的讀操作
- synchronized修飾符最小作用域
synchronized要耗費性能,因此synchronized代碼塊優於synchronized方法,最小原則
- enum代替int枚舉模式
int枚舉模式不具有類型安全性,也沒有啥子描述性,比較也會出問題
1)醜陋的
public static final int APPLE_FRUIT = 0; public static final int APPLE_PIPPIN = 1; public static final int APPLE_GRANNY_SMITH = 2; public static final int ORANGE_NAVEL = 0; public static final int ORANGE_TEMPLE = 1; public static final int ORANGE_BLOOD = 2;
2)漂亮的小姐姐
public enum Apple { FRUIT, PIPPIN, GRANNY_SMITH } public enum Orange { NAVEL, TEMPLE, BLOOD }
- 合理使用靜態工廠方法代替構造器
如Boolean基本類
public static Boolean valueOf(boolean b) { return (b ? TRUE : FALSE); }
靜態工廠方法,不必在每次調用時都創建一個新的對象;而且相較於構造器,它有名稱便於閱讀和理解;同時可以返回原類型的任意子類型;也可以根據參數不同,返回不同的類對象,如EnumSet
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) { Enum<?>[] universe = getUniverse(elementType); if (universe == null) throw new ClassCastException(elementType + " not an enum"); if (universe.length <= 64) return new RegularEnumSet<>(elementType, universe); else return new JumboEnumSet<>(elementType, universe); }
- 組合優於繼承
因為繼承打破了封裝性,overriding可能導致安全漏洞
- 異常只能用於處理錯誤,不能用來控制業務流程
- 精準的運算,如貨幣運算等不要用float 和 double
正確的做法,用BigDecimal、int和long
- ArrayList對於“隨機訪問較多的場景”性能較高,LinkedListd對於“刪除和插入較多的場景”性能更高
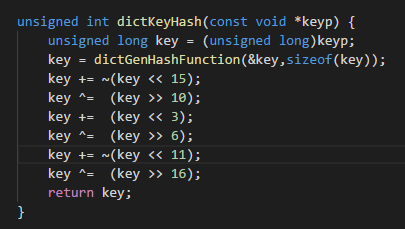
- 使用範圍最小的數據類型,redis源碼里大量使用unsigned int 和 unsigned long,時間和空間效率高於int 和 long
部分源碼截圖如下:

- 將局部變量最小化
推薦在第一次使用局部變量的地方聲明它。不然隔太遠,容易分散注意力,閱讀代碼的人忘記它的類型和初始值了,需要再去找
幾乎每個局部變量的聲明都應該包含一個初始化表達式
未完待續,困了
註:
參考《Effective java》《重構 —— 改善既有代碼的設計》《深入分析JAVA web技術內幕》
*****************************************************************************************************
精力有限,想法太多,專註做好一件事就行
- 我只是一個程序猿。5年內把代碼寫好,技術博客字字推敲,堅持零拷貝和原創
- 寫博客的意義在於鍛煉邏輯條理性,加深對知識的系統性理解,鍛煉文筆,如果恰好又對別人有點幫助,那真是一件令人開心的事
*****************************************************************************************************

