Serverless架構與資源評估:性能與成本探索
- 2019 年 12 月 24 日
- 筆記
在很多的場合中,Serverless的佈道師常常說Serverless架構和雲主機等區別的時候,都會有類似的描述:
傳統業務開發完成想要上線,需要評估資源使用,根據資源評估結果,購買雲主機,並且需要根據業務發展不斷對主機等資源進行升級維護,而Serverless架構,則不需要這樣複雜的流程,只需要將函數部署到線上,一切後端服務交給運營商來處理,哪怕是瞬時高並發,也有雲廠商為您自動擴縮。
但是,在實際生產生活中,Serverless真的是這樣無需對資源評估么?還是說在Serverless架構下,資源評估的內容或者對象發生了變化,或者說進行了簡化呢?
在騰訊云云函數中,我們創建一個雲函數之後,可以看到在設置頁面有幾個設置項是可以進行設置的:

這兩個設置範圍分別是從64M到1536M,和1-900S,涉及到這樣的設置,我覺得就是涉及到了資源評估。
首先先說超時時間,我們一個項目或者說一個函數,一個Action都是有執行時間的,如果超過某個時間沒執行完就可以評估其為發生了「意外」,可以被「幹掉「了,這個就是超時時間,例如我們有一個簡單請求,是獲取用戶信息的請求,我們預估,如果10S中沒有返回證明已經不滿足業務需求,所以這個時候就可以將超時設置為10S,如果說我們有一個業務,運行速度比較慢,至少要50S才能執行完,那麼這個值設置的時候就要大於50,否則程序可能因為超時被強行停止。
然後再說說內存,內存是一個有趣的東西,可能衍生兩個關聯點。
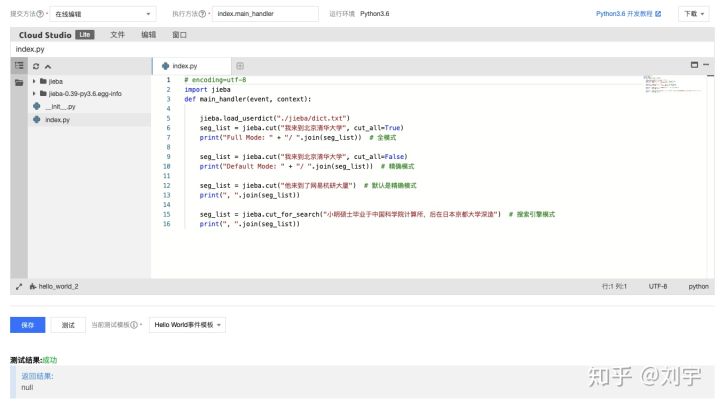
關聯點1: 程序本身需要一定的內存,這個內存要大於程序本身的內存,以Python語言為例:
# encoding=utf-8 import jieba def main_handler(event, context): jieba.load_userdict("./jieba/dict.txt") seg_list = jieba.cut("我來到北京清華大學", cut_all=True) print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我來到北京清華大學", cut_all=False) print("Default Mode: " + "/ ".join(seg_list)) # 精確模式 seg_list = jieba.cut("他來到了網易杭研大廈") # 默認是精確模式 print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造") # 搜索引擎模式 print(", ".join(seg_list))
(對程序代碼的說明,為了讓結果更佳直觀,差距更加大,所以在這裡每次都重新導入了自帶了dict,這個操作本身就是相對浪費時間和內存的。在實際使用中jieba自帶緩存,並且無需手動導入本身的dict)
當我導入一個自定義的dict到jieba中,如果此時我函數內存設置的默認128M內存限制+3S超時限制就會這樣:

此時可以看到,由於在導入自定義dict的時候,內存消耗過大, 默認的額128不足以滿足需求,所以此時我將其修改成最大:

他又提醒我們時間超時,所以我們還需要再修改超時時間為適當的數值(此處設定為10S):
所以說,在關注程序本身的前提下,我們可以認為,我們要把內存設置到一個合理範圍內,這個範圍是>=程序本身需要的內存數值。
關聯點2: 計費相關,在雲函數的文檔中,我們可以看到:
計費方式 – 雲函數 – 文檔中心 – 騰訊雲cloud.tencent.com
雲函數 SCF 按照實際使用付費,採用後付費小時結,以元為單位進行結算。 SCF 賬單由以下三部分組成,每部分根據自身統計結果和計算方式進行費用計算,結果以元為單位,並保留小數點後兩位。 資源使用費用 調用次數費用 外網出流量費用
調用次數和出網流量這部分,都是我們程序或者使用本身相關了,而資源使用費用這則有一些注意點:
資源使用量 = 函數配置內存 × 運行時長 用戶資源使用量,由函數配置內存,乘以函數運行時的計費時長得出。其中配置內存轉換為 GB 單位,計費時長由毫秒(ms)轉換為秒(s)單位,因此,資源使用量的計算單位為 GBs(GB-秒)。 例如,配置為256MB的函數,單次運行了 1760 ms,計費時長為 1760 ms,則單次運行的資源使用量為(256/1024)×(1760/1000) = 0.44 GBs。 針對函數的每次運行,均會計算資源使用量,並按小時匯總求和,作為該小時的資源使用量。
這裡有一個非常重要的公式,那就是函數配置內存*運行時長。
函數配置內存就是我們剛才說的,我們為程序選擇的內存大小,運行時長,就是我們運行程序之後得到的結果:

以我這個程序為例,我用的是1536MB,則使用量為(1536/1024) * (3200/1000) = 4.8GBs
當然,我此時如果是250MB的話,程序也可以運行:

此時的資源使用量為(256/1024) * (3400/1000) = 0.85GBs
相對比上一次,程序執行時間增加了0.2S,但是資源使用量降低了將近6倍!
產品單價是:
產品定價 – 雲函數 – 文檔中心 – 騰訊雲cloud.tencent.com

雖然說GBs的單價很低很低,但是當我們業務量上來之後,這個數字也是要值得注意的,因為我剛才的只是一個單次請求,如果每天有1000此次請求,那:
(僅計算資源使用量費用,而不計算調用次數/外網流量)
1536MB: 4.8*1000*0.00011108 = 0.5元
256MB:0.85*1000*0.00011108 = 0.09442元
如果不是1000次調用,而是10萬次調用,則就是50元和9元的區別,差距很大,隨着流量越大,差距越大。
當然很多時候函數執行時間不會這麼久,以我個人的某個函數為例:

計費時間均是100ms,每日調用量在6000次左右:

如果按照64M內存來看,單資源費用只要76元一年,而如果內存都設置稱為1536,則一年要1824元!這個費用相當於:

所以說,超時時間,是需要對代碼和業務場景進行評估來進行設置,他可能關係到程序運行的穩定和功能的完整性;內存,則不僅僅在程序使用層面有着不同的需求,在費用成本等方面也佔有極大的比重,所以內存設置還是需要對程序進行一個評估,那麼評估問題來了,我設置多大比較划算呢?同樣是之前的代碼,在本地進行簡單的腳本編寫:
from tencentcloud.common import credential from tencentcloud.common.profile.client_profile import ClientProfile from tencentcloud.common.profile.http_profile import HttpProfile from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException from tencentcloud.scf.v20180416 import scf_client, models import json import numpy import matplotlib.pyplot as plt try: cred = credential.Credential("", "") httpProfile = HttpProfile() httpProfile.endpoint = "scf.tencentcloudapi.com" clientProfile = ClientProfile() clientProfile.httpProfile = httpProfile client = scf_client.ScfClient(cred, "ap-shanghai", clientProfile) req = models.InvokeRequest() params = '{"FunctionName":"hello_world_2"}' req.from_json_string(params) billTimeList = [] timeList = [] for i in range(1,50): print("times: ", i) resp = json.loads(client.Invoke(req).to_json_string()) billTimeList.append(resp['Result']['BillDuration']) timeList.append(resp['Result']['Duration']) print("計費最大時間", int(max(billTimeList))) print("計費最小時間", int(min(billTimeList))) print("計費平均時間", int(numpy.mean(billTimeList))) print("運行最大時間", int(max(timeList))) print("運行最小時間", int(min(timeList))) print("運行平均時間", int(numpy.mean(timeList))) plt.figure() plt.subplot(4, 1, 1) x_data = range(0, len(billTimeList)) plt.plot(x_data, billTimeList) plt.subplot(4, 1, 2) plt.hist(billTimeList, bins=20) plt.subplot(4, 1, 3) x_data = range(0, len(timeList)) plt.plot(x_data, timeList) plt.subplot(4, 1, 4) plt.hist(timeList, bins=20) plt.show() except TencentCloudSDKException as err: print(err)
運行之後會為我們輸出一個簡單的圖像:

從上到下分別是不同次數計費時間圖,計費時間分佈圖,以及不同次數運行時間圖和運行時間分佈圖。通過對256M起步,1536M終止,步長128M,每個內存大小串行靠用50次,統計表:

註:為了讓統計結果更加清晰,差異性比較大,比較明顯,在程序代碼中進行了部分無用操作用來增加程序執行時間。正常使用jieba的速度基本都是毫秒級的:

通過表統計可以看到在滿足程序內存消耗的前提下,內存大小對程序執行時間的影響並不是很大,反而是對計費影響很大。
當然上面是兩個重要指標,一個是超時時間另一個是運行內存,除了這兩者,還有一個參數需要用戶來評估:函數並發量,在項目上線之後,還要對項目可能產生的並發量進行評估,當評估的並發量超過默認的並發量,要及時聯繫售後同學或者提交工單進行最大並發量數值的提升。
綜上所述,Serverless架構也是需要資源評估的,而且資源評估同樣和成本是直接掛鈎的,只不過這個資源評估的對象逐漸發生了變化,相對之前的評估唯獨,難度而言,都是大幅度縮小或者降低的。


