編程思想與算法leetcode_二分算法詳解
- 2021 年 7 月 30 日
- 筆記
二分算法通常用於有序序列中查找元素:
-
有序序列中是否存在滿足某條件的元素;
-
有序序列中第一個滿足某條件的元素的位置;
-
有序序列中最後一個滿足某條件的元素的位置。
思路很簡單,細節是魔鬼。
二分查找
一.有序序列中是否存在滿足某條件的元素
首先,二分查找的框架:
def binarySearch(nums, target):
l = 0 #low
h = ... #high
while l...h:
m = (l + (h - l) / 2) #middle,防止h+l溢出
if nums[m] == target:
...
elif nums[m] < target:
l = ... #縮小邊界
elif nums[m] > target:
h = ...
return ... #查找結果
其次,最基本的查找有序序列中的一個元素
def binarySearch(nums, target):
l = 0
h = len(nums) - 1
while l <= h :
m = (l + (h - l) / 2)
if nums[m] == target:
return m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m - 1
return -1
循環的條件為什麼是 <=,而不是 < ?
答:要保證能遍歷到數組的第一個元素和最後一個元素。因為初始化 h 的賦值是 len(nums) – 1,即最後一個元素的索引,而不是 len(nums)。
這二者可能出現在不同功能的二分查找中,區別是:前者相當於兩端都閉區間 [l, h],後者相當於左閉右開區間 [l, h),因為索引大小為 len(nums) 是越界的。
我們這個算法中使用的是 [l, h] 兩端都閉的區間。這個區間就是每次進行搜索的區間,我們不妨稱為「搜索區間」(search space)。
此算法有什麼缺陷?
答:至此,你應該已經掌握了該算法的所有細節,以及這樣處理的原因。但是,這個算法存在局限性。
比如說給你有序數組 nums = [1,2,2,2,3],target = 2,此算法返回的索引是 2,沒錯。但是如果我想得到 target 的左側邊界,即索引 1,或者我想得到 target 的右側邊界,即索引 3,這樣的話此算法是無法處理的。
這樣的需求很常見。你也許會說,找到一個 target 索引,然後向左或向右線性搜索不行嗎?可以,但是不好,因為這樣難以保證二分查找對數級的時間複雜度了。
我們後續的算法就來討論這兩種二分查找的算法。
二、尋找一個數(基本的二分搜索)
這個場景是最簡單的,可能也是大家最熟悉的,即搜索一個數,如果存在,返回其索引,否則返回 -1。
def binarySearch([] nums, target):
l = 0
h = len(nums) - 1
while l <= h:
m = (l + (h - l) / 2)
if nums[m] == target:
return m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m - 1
return -1
1. 為什麼 while 循環的條件中是 <=,而不是 < ?
答:因為初始化 h 的賦值是 len(nums) – 1,即最後一個元素的索引,而不是 len(nums)。
這二者可能出現在不同功能的二分查找中,區別是:前者相當於兩端都閉區間 [l, h],後者相當於左閉右開區間 [l, h),因為索引大小為 len(nums) 是越界的。
我們這個算法中使用的是 [l, h] 兩端都閉的區間。這個區間就是每次進行搜索的區間,我們不妨稱為「搜索區間」(search space)。
什麼時候應該停止搜索呢?當然,找到了目標值的時候可以終止:
if nums[m] == target
return m
但如果沒找到,就需要 while 循環終止,然後返回 -1。那 while 循環什麼時候應該終止?搜索區間為空的時候應該終止,意味着你沒得找了,就等於沒找到嘛。
while(l <= h)的終止條件是 l == h + 1,寫成區間的形式就是 [h + 1, h],或者帶個具體的數字進去 [3, 2],可見這時候搜索區間為空,因為沒有數字既大於等於 3 又小於等於 2 的吧。所以這時候 while 循環終止是正確的,直接返回 -1 即可。
while(l < h)的終止條件是 l == h,寫成區間的形式就是 [h, h],或者帶個具體的數字進去 [2, 2],這時候搜索區間非空,還有一個數 2,但此時 while 循環終止了。也就是說這區間 [2, 2] 被漏掉了,索引 2 沒有被搜索,如果這時候直接返回 -1 就可能出現錯誤。
當然,如果你非要用 while(l < h) 也可以,我們已經知道了出錯的原因,就打個補丁好了:
#...
while l < h:
# ...
return nums[l] == target ? l : -1
2. 為什麼 l = m + 1,h = m – 1?我看有的代碼是 h = m 或者 l = m,沒有這些加加減減,到底怎麼回事,怎麼判斷?
答:這也是二分查找的一個難點,不過只要你能理解前面的內容,就能夠很容易判斷。
剛才明確了「搜索區間」這個概念,而且本算法的搜索區間是兩端都閉的,即 [l, h]。那麼當我們發現索引 m 不是要找的 target 時,如何確定下一步的搜索區間呢?
當然是去搜索 [l, m – 1] 或者 [m + 1, h] 對不對?因為 m 已經搜索過,應該從搜索區間中去除。
3. 此算法有什麼缺陷?
答:至此,你應該已經掌握了該算法的所有細節,以及這樣處理的原因。但是,這個算法存在局限性。
比如說給你有序數組 nums = [1,2,2,2,3],target = 2,此算法返回的索引是 2,沒錯。但是如果我想得到 target 的左側邊界,即索引 1,或者我想得到 target 的右側邊界,即索引 3,這樣的話此算法是無法處理的。
這樣的需求很常見。你也許會說,找到一個 target 索引,然後向左或向右線性搜索不行嗎?可以,但是不好,因為這樣難以保證二分查找對數級的時間複雜度了。
我們後續的算法就來討論這兩種二分查找的算法。
三、尋找左側邊界的二分搜索
直接看代碼,其中的標記是需要注意的細節:
def l_bound(nums, target):
if len(nums) == 0 return -1
l = 0
h = len(nums)
while l < h
m = int(l + (h - l) / 2)
if nums[m] == target:
h = m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m
return l
為什麼 while(l < h) 而不是 <= ?
答:用相同的方法分析,因為初始化 h = len(nums) 而不是 len(nums) – 1 。因此每次循環的「搜索區間」是 [l, h) 左閉右開。
while(l < h) 終止的條件是 l == h,此時搜索區間 [l, l) 恰巧為空,所以可以正確終止。
為什麼沒有返回 -1 的操作?如果 nums 中不存在 target 這個值,怎麼辦?
答:因為要一步一步來,先理解一下這個「左側邊界」有什麼特殊含義:
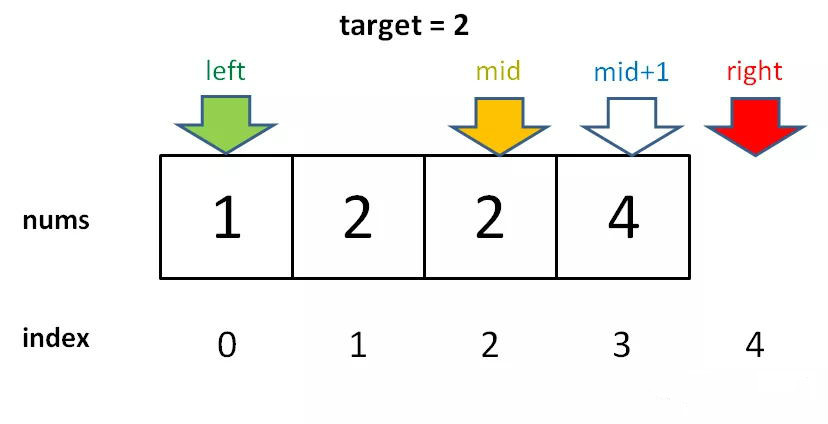
對於這個數組,算法會返回 1。這個 1 的含義可以這樣解讀:nums 中小於 2 的元素有 1 個。
比如對於有序數組 nums = [2,3,5,7], target = 1,算法會返回 0,含義是:nums 中小於 1 的元素有 0 個。如果 target = 8,算法會返回 4,含義是:nums 中小於 8 的元素有 4 個。
綜上可以看出,函數的返回值(即 l 變量的值)取值區間是閉區間 [0, len(nums)],所以我們簡單添加兩行代碼就能在正確的時候 return -1:
while l < h:
#...
# target 比所有數都大
if l == len(nums) return -1
# 類似之前算法的處理方式
return nums[l] == target ? l : -1
3. 為什麼 l = m + 1,h = m ?和之前的算法不一樣?
答:這個很好解釋,因為我們的「搜索區間」是 [l, h) 左閉右開,所以當 nums[m] 被檢測之後,下一步的搜索區間應該去掉 m 分割成兩個區間,即 [l, m) 或 [m + 1, h)。
4. 為什麼該算法能夠搜索左側邊界?
答:關鍵在於對於 nums[m] == target 這種情況的處理:
if nums[m] == target:
h = m
可見,找到 target 時不要立即返回,而是縮小「搜索區間」的上界 h,在區間 [l, m) 中繼續搜索,即不斷向左收縮,達到鎖定左側邊界的目的。
5. 為什麼返回 l 而不是 h?
答:返回l和h都是一樣的,因為 while 終止的條件是 l == h。
四、尋找右側邊界的二分查找
尋找右側邊界和尋找左側邊界的代碼差不多,只有兩處不同,已標註:
def h_bound(nums, target):
if len(nums) == 0 return -1
l = 0
h = len(nums)
while l < h:
m = int((l + h) / 2)
if nums[m] == target:
l = m + 1
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m
return l - 1
1. 為什麼這個算法能夠找到右側邊界?
答:類似地,關鍵點還是這裡:
if nums[m] == target:
l = m + 1
當 nums[m] == target 時,不要立即返回,而是增大「搜索區間」的下界 l,使得區間不斷向右收縮,達到鎖定右側邊界的目的。
2. 為什麼最後返回 l – 1 而不像左側邊界的函數,返回 l?而且我覺得這裡既然是搜索右側邊界,應該返回 h 才對。
答:首先,while 循環的終止條件是 l == h,所以 l 和 h 是一樣的,你非要體現右側的特點,返回 h – 1 好了。
至於為什麼要減一,這是搜索右側邊界的一個特殊點,關鍵在這個條件判斷:
if nums[m] == target:
l = m + 1
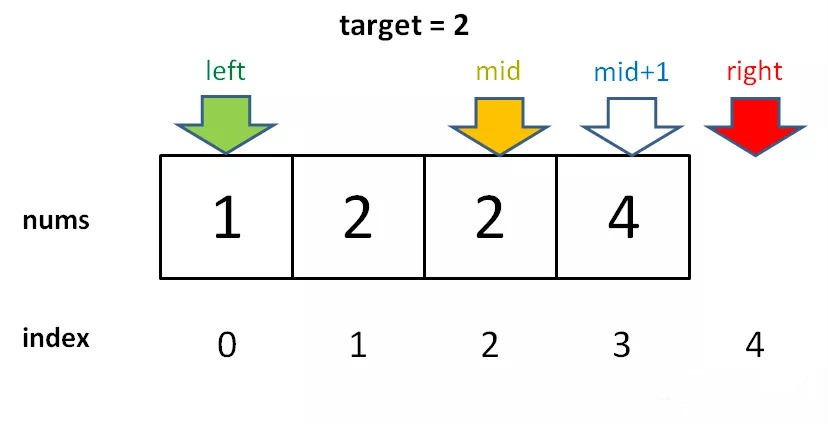
因為我們對 l 的更新必須是 l = m + 1,就是說 while 循環結束時,nums[l] 一定不等於 target 了,而 nums[l – 1]可能是target。
至於為什麼 l 的更新必須是 l = m + 1,同左側邊界搜索,就不再贅述。
3. 為什麼沒有返回 -1 的操作?如果 nums 中不存在 target 這個值,怎麼辦?
答:類似之前的左側邊界搜索,因為 while 的終止條件是 l == h,就是說 l 的取值範圍是 [0, len(nums)],所以可以添加兩行代碼,正確地返回 -1:
while l < h: # ... if l == 0 return -1 return nums[l-1] == target ? (l-1) : -1
五、最後總結
先來梳理一下這些細節差異的因果邏輯:
第一個,最基本的二分查找算法:
因為我們初始化 h = len(nums) - 1
所以決定了我們的「搜索區間」是 [l, h]
所以決定了 while (l <= h)
同時也決定了 l = m+1 和 h = m-1
因為我們只需找到一個 target 的索引即可
所以當 nums[m] == target 時可以立即返回
第二個,尋找左側邊界的二分查找:
因為我們初始化 h = len(nums)
所以決定了我們的「搜索區間」是 [l, h)
所以決定了 while (l < h)
同時也決定了 l = m+1 和 h = m
因為我們需找到 target 的最左側索引
所以當 nums[m] == target 時不要立即返回
而要收緊右側邊界以鎖定左側邊界
第三個,尋找右側邊界的二分查找:
因為我們初始化 h = len(nums)
所以決定了我們的「搜索區間」是 [l, h)
所以決定了 while (l < h)
同時也決定了 l = m+1 和 h = m
因為我們需找到 target 的最右側索引
所以當 nums[m] == target 時不要立即返回
而要收緊左側邊界以鎖定右側邊界
又因為收緊左側邊界時必須 l = m + 1
所以最後無論返回 l 還是 h,必須減一
如果以上內容你都能理解,那麼恭喜你,二分查找算法的細節不過如此。
通過本文,你學會了:
1. 分析二分查找代碼時,不要出現 else,全部展開成 elif 方便理解。
2. 注意「搜索區間」和 while 的終止條件,如果存在漏掉的元素,記得在最後檢查。
3. 如需要搜索左右邊界,只要在 nums[m] == target 時做修改即可。搜索右側時需要減一。
就算遇到其他的二分查找變形,運用這幾點技巧,也能保證你寫出正確的代碼。LeetCode Explore 中有二分查找的專項練習,其中提供了三種不同的代碼模板,現在你再去看看,很容易就知道這幾個模板的實現原理了。

