機器學習 – 決策樹
決策樹,聽名字就知道跟樹有關,而且很容易猜到是一種類似依靠樹形結構來輔助決策過程的策略。所以重點就是如何構建這個樹,如何依次選取樹的各個節點,以便能在測試集中有較好的表現。
信息熵與信息增益
說到如何選取節點,就要引入信息熵的概念。我以前一看到「熵」這個字就頭疼,以為是跟高深的物理學相關,其實很好理解,簡單說就是純度。假設有一罐混合了氧氣和二氧化碳的氣體:
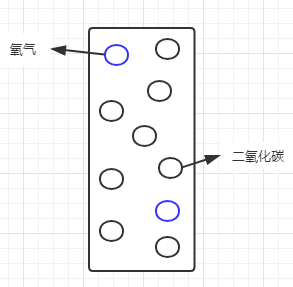
我們通常會說這罐氣體不純,那麼怎麼來度量這個純度呢?假設氧氣佔20%,二氧化碳佔80%,則可以看做是二氧化碳里混入了少量的氧氣,二氧化碳相對純一些;如果看做是氧氣中混入了大量的二氧化碳,那麼這個氧氣也太不純了。我們在這裡所討論的純度,都是針對某一特定對象而言,而又不適用於這個系統里的其他對象。如果把這個罐子當做整個系統的話,信息熵就可以看做是系統級的純度。一般這樣度量信息熵,系統純度越低,信息熵越大,反之,系統純度越高,信息熵越小。如果罐子里只剩一種氣體,則信息熵為0。
信息熵的計算公式如下:
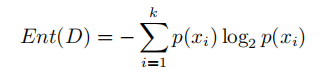
其中k表示系統中特徵的數量,p(xi)表示每個特徵再系統中的佔比。所以我們可以算出此時的信息熵為:

假設由於保存不當,罐子中混入了一種有色氣體(比如二氧化硫):

假設目前三種氣體的佔比為:氧氣15%,二氧化碳50%,二氧化硫35%,根據信息熵的理論,現在整個系統的信息熵應該比原先更大了(純度降低)。我們不妨再算一下此時的信息熵:
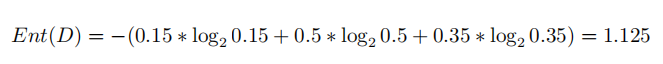
可以看到信息熵增大了,符合之前的理論。那麼如果我們現在要分離這三種氣體,就需要選擇一個標準,或者說,選擇能夠區分這三種氣體的特徵進分離。最直觀的特徵就是有色跟無色:
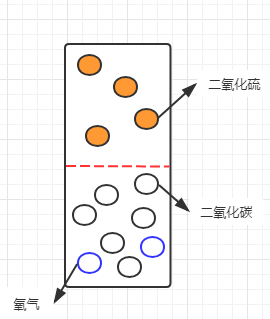
如果按這個特徵對系統進行劃分,則會將系統劃分為有色氣體跟無色氣體兩個子集。劃分後的系統,已經由最初較為混沌的狀態(三種氣體混合)變成了有色跟無色兩部分,所以,此時的信息熵就變成了有色子集的信息熵與無色子集信息熵的加和。但考慮到這兩類氣體在系統中的佔比,需要將佔比作為子集信息熵的權重,所以此時的信息熵為:
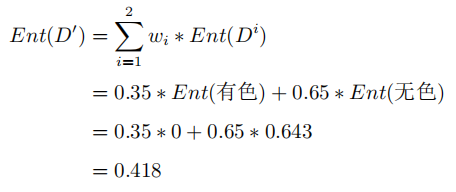
所以經過對氣體顏色這一特徵的劃分,系統的信息熵由1.125變成了0.418,說明系統純度有所提升。為了準確的表示提升的具體情況,就把這個提升空間叫做信息增益。
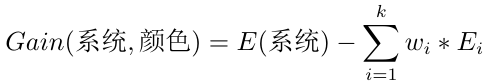
寫成標準式:
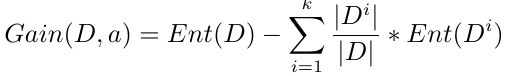
其中,D表示整個樣本數據集,a表示所選的用戶劃分系統樣本的特徵,Ent(D)表示劃分前的信息熵,|Di|表示劃分後的每個子集的樣本個數,|D|表示劃分前的樣本總數,Ent(Di)表示每個子集各自的信息熵。後面一項實際上就是子集信息熵的期望。
從公式可以看出,如果選取不同的特徵,劃分後的信息熵可能會有大小之分,而系統當前的信息熵是不變的,所以劃分後的信息熵如果越小,信息增益就越大,說明系統純度提升的幅度就越大,反之亦然。所以,我們就需要遍歷所有已知特徵,找出能夠提升幅度最大的那個特徵,作為首選的劃分特徵。
至此,就把信息熵和信息增益的概念介紹清楚了,雖然有點啰嗦,但是應該是比較通俗易懂的。我們上面介紹的這種選取劃分特徵的算法也叫做ID3算法。下面來看西瓜書中對應的例子。
ID3算法
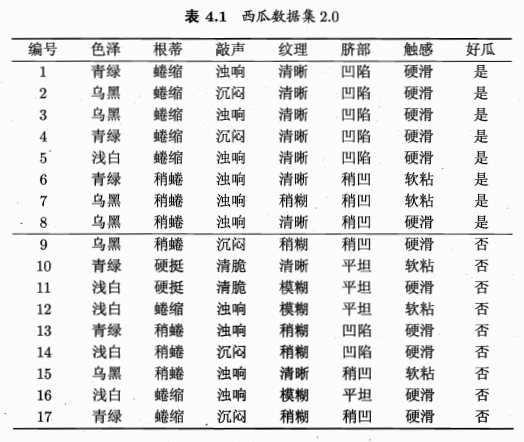
按照上面的套路,我們先取色澤作為劃分特徵,計算一下對應的信息增益。
首先,系統當前有8個好瓜,9個壞瓜,所以對應 信息熵為:
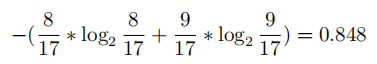
我們再選色澤作為劃分特徵,計算一下子集信息熵的期望:
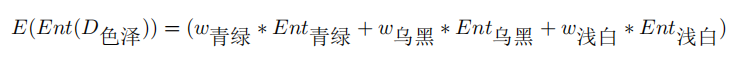
其中:
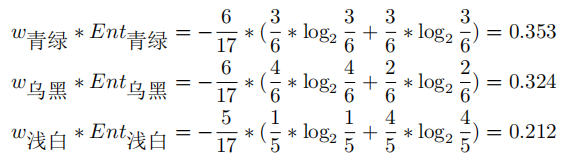
帶入上式,得:

再依次計算出其他特徵對應的信息增益,取信息增益最大的那個特徵作為首選條件,再如此繼續劃分下去,就可以得到一個樹形結構的分支圖,即我們要的決策樹。
退出條件:
1.劃分子集的信息熵為0;
2.無可用特徵,取當前集合佔比最大的作為標籤。
下面我們用Python來實現。首先要把圖4.1的文字轉為csv文件的格式:
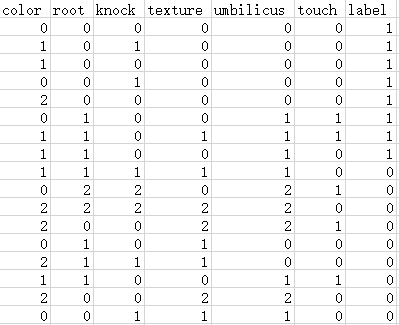
我們只要從csv里讀取數據,就能進行後續的分析了。ID3的Python實現如下:
import numpy as np
import math
class DTree:
def __init__(self, type=0):
self.dataset = ''
self.model = ''
def load_data(self, data):
dataset = np.loadtxt(data, delimiter=',', dtype=str)
self.dataset = dataset
def get_entropy(self, dataset):
# 統計總數及正反例個數
sum_num = len(dataset[1:])
p1 = dataset[1:, -1].astype(int).sum() / sum_num
p2 = 1 - p1
# 如果p1或p2有一個為0,說明子集純度為0,,直接返回0
if p1==0 or p2==0:
return 0
# 使用公式計算信息熵並返回
return -1*(p1*math.log2(p1) + p2*math.log2(p2))
def get_max_category(self, dataset):
pos = dataset[1:, -1].astype(int).sum()
neg = len(dataset[1:, -1]) - pos
return '1' if pos > neg else '0'
def dataset_split(self, dataset, feature, feature_value):
index = list(dataset[0, :-1]).index(feature)
# 遍歷特徵所在列,剔除值不等於feature_value的行
j = 0
for i in range(len(dataset[1:, index])):
if dataset[1:, index][j] != feature_value:
dataset = np.delete(dataset, j+1, axis=0)
j -= 1
j += 1
# 刪除feature所在列
return np.delete(dataset, index, axis=1)
def get_best_feature(self, dataset, E):
feature_list = dataset[0, :-1]
feature_gains = {}
for i in range(len(feature_list)):
# 分別統計在每個特徵值劃分下的信息增益
feature_values = np.unique(dataset[1:, i])
feature_sum = len(dataset[1:, i])
# 累加子集熵
sub_entropy_sum = 0
for value in feature_values:
# 按值劃分子集
subset = self.dataset_split(dataset, feature_list[i], value)
subset_sum = len(subset)
# 計算子集熵
sub_entropy = self.get_entropy(subset)
# 權重
w = subset_sum/feature_sum
# 匯總當前特徵下的子集熵*個數權重
sub_entropy_sum += w*sub_entropy
# 根據算公式計算信息增益
feature_gains[feature_list[i]] = E-sub_entropy_sum
# 返回最大信息增益對應的特徵及索引
max_gain = max(feature_gains.values())
for feature in feature_gains:
if feature_gains[feature] == max_gain:
index = list(feature_list).index(feature)
return feature, index
def build_tree(self, dataset):
# 計算數據集信息熵
E = self.get_entropy(dataset)
# 設置退出條件
# 1.如果集合的信息熵為0,則返回當前標籤
if E == 0:
return dataset[1][-1]
# 2.特徵數為1,說明無可劃分特徵,返回當前集合中佔比最多的標籤
if len(dataset[0]) == 2: # 特徵+標籤
return self.get_max_category(dataset)
# 獲取最佳特徵
feature, index = self.get_best_feature(dataset, E)
# 按特徵劃分子集
tree = {feature:{}}
# 獲取特徵值
feature_values = np.unique(dataset[:, index][1:])
# 按特徵值劃分子集
for value in feature_values:
subset = self.dataset_split(dataset, feature, value)
subtree = self.build_tree(subset)
tree[feature][value] = subtree
return tree
def train(self):
self.model = self.build_tree(self.dataset)
return self.model
def predict(self, tree, testset):
pass
dtree = DTree()
dtree.load_data('data4_1.csv')
tree_model = dtree.train()
print(tree_model)
分類結果:
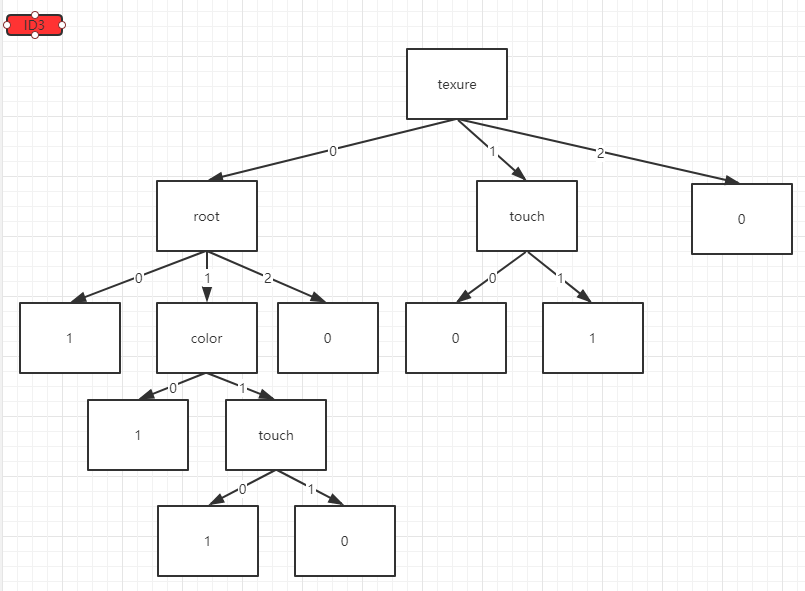
缺點:如果把編號也作為樣本特徵的話,那麼它的信息增益為0.758,大於所有其他特徵的信息增益,說明特徵值種類越多,信息增益趨向于越大。
通過增益率改良後的C4.5算法
C4.5算法旨在消除這種由特徵值種類差異所引起的「不平等待遇」。它引入了特徵的「固有值」的概念,相當於對該特徵的種類及數量計算信息熵。而這種「固有值」也擁有這種「不平等待遇」(種類越多,信息增益越大),所以兩者相除,正好抵消了這種差異:
固有值的計算公式:
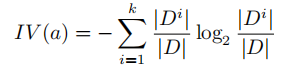
信息增益在C4.5算法下的計算公式:

由於C4.5與ID3的區別只是計算公式的不同,所以在獲取最佳特徵的函數get_best_feature()中稍作修改即可:
def get_best_feature(self, dataset, E):
feature_list = dataset[0, :-1]
feature_gains = {}
for i in range(len(feature_list)):
# 分別統計在每個特徵值劃分下的信息增益
feature_values = np.unique(dataset[1:, i])
feature_sum = len(dataset[1:, i])
# 累加子集熵
sub_entropy_sum = 0
# 累加feature的固有值
intrinsic_value = 0
for value in feature_values:
# 按值劃分子集
subset = self.dataset_split(dataset, feature_list[i], value)
subset_sum = len(subset)
# 計算子集熵
sub_entropy = self.get_entropy(subset)
# 權重
w = subset_sum/feature_sum
# 匯總當前特徵下的子集熵*個數權重
sub_entropy_sum += w*sub_entropy
intrinsic_value += -1*(w*math.log2(w))
# 根據算法類型選擇對應的公式計算信息增益
if self.type == 0:
feature_gains[feature_list[i]] = E-sub_entropy_sum
else:
feature_gains[feature_list[i]] = (E-sub_entropy_sum)/intrinsic_value
# 返回最大信息增益對應的特徵及索引
max_gain = max(feature_gains.values())
for feature in feature_gains:
if feature_gains[feature] == max_gain:
index = list(feature_list).index(feature)
return feature, index
得到的分類結果:
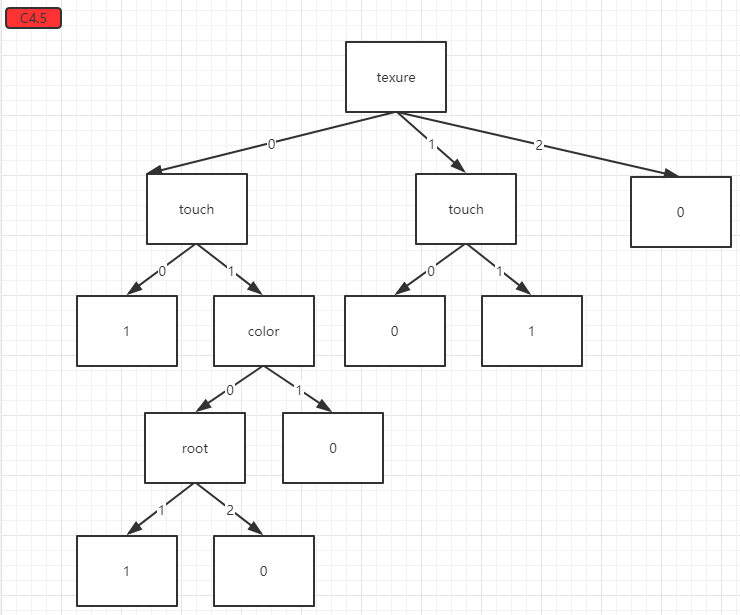
基尼係數和剪枝的內容待補充。。。


