Redis中一個String類型引發的慘案
曾經看到這麼一個案例,有一個團隊需要開發一個圖片存儲系統,要求這個系統能快速記錄圖片ID和圖片存儲對象ID,同時還需要能夠根據圖片的ID快速找到圖片存儲對象ID。我們假設用10位數來表示圖片ID和圖片存儲對象ID,例如圖片的ID為1101021043,它所對應的圖片存儲對象的ID為2301010051,可以看到圖片ID和圖片存儲ID正好是一一對應的,是典型的key-value形式,所以首先會想到直接使用String類型來保存數據。把圖片ID和圖片存儲ID分別作為鍵值對的key和value來保存。但是隨着存儲的數據量越來越大,Redis的內存的使用量也快速上升,結果遇到了大內存Redis實例因為生成RDB而響應變慢的問題。很顯然String類型並不是一種好的選擇,
那有什麼辦法可以降低內存消耗嗎?
String類型的數據結構
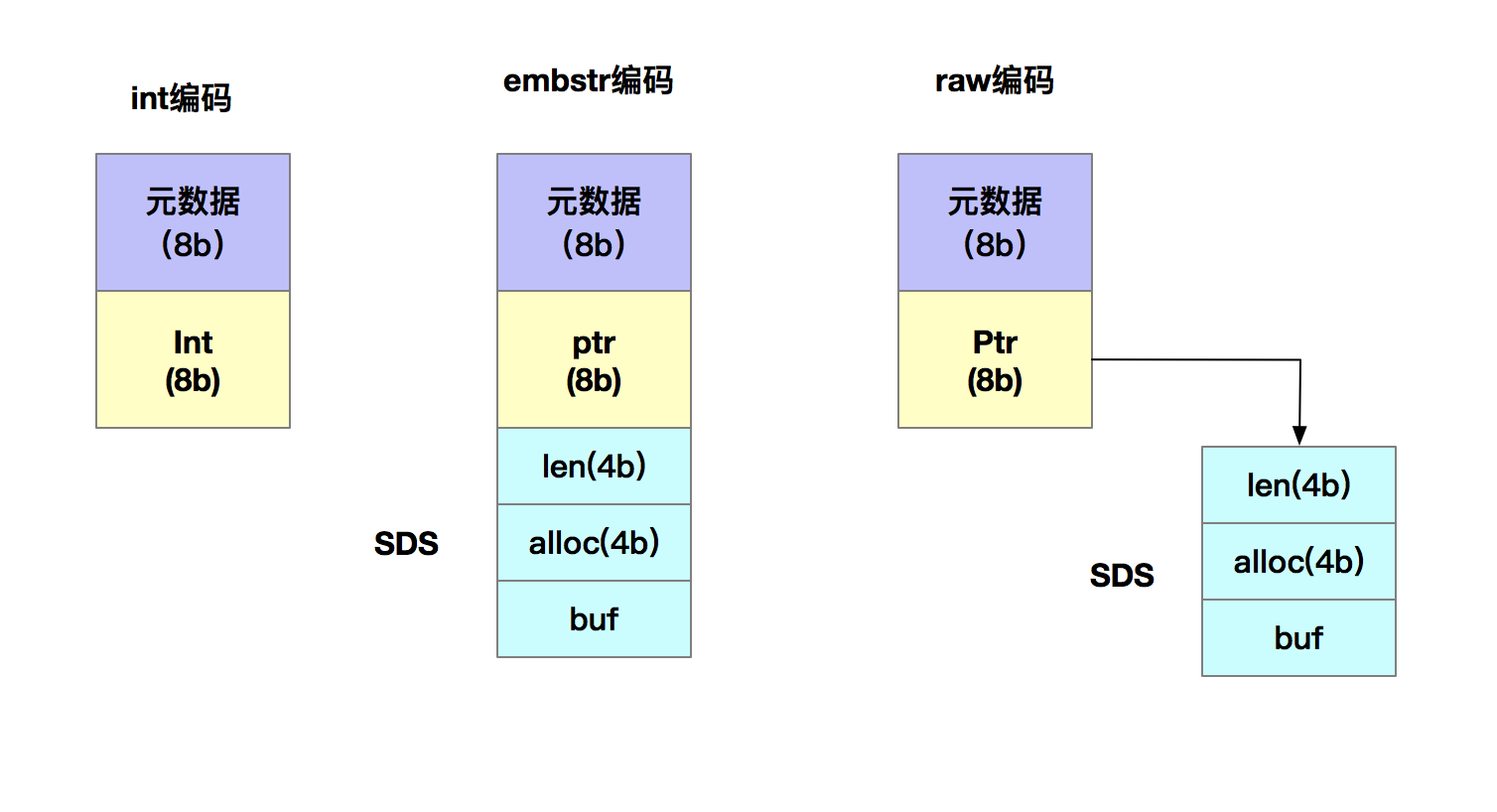
首先我們得先了解為什麼String保存數據時所消耗的內存空間較大。在剛才的案例中,由於圖片ID和圖片存儲對象ID都是10位數,我們可以用兩個8位元組的Long類型來表示這兩個ID。所以一組圖片ID及其存儲對象ID的記錄,實際只需要16位元組就可以了。但是通過對Redis內存分析,一組圖片ID及其存儲對象ID卻佔用了64位元組,那為什麼String類型會用64位元組呢。其實,除了要記錄實際的數據,String類型還需要額外的內存空間來記錄數據的長度、空間使用信息等,這些信息也叫做元數據。當實際保存的數據較小時,元數據的空間開銷就顯的比較大了。我們先來看一下String類型是如何保存數據的。當你保存64位有符號的整數時,String類型會把它保存為一個8位元組的Long類型整數,這種保存方式通常也叫作int編碼方式。但是,當你保存的數據中包含字符時,String類型就會用簡單動態字符串結構體(SDS)來保存。如下圖所示:

-
len:4個位元組,表示buf的已用長度。
-
alloc:4個位元組,表示buf分配的長度,一般大於len。
-
buf:位元組數組,保存實際數據。為了表示數組的結尾,Redis會自動在數組最後添加一個」\0″。
可以看到,在SDS結構體中,除了有保存實際數據的buf,還有len和alloc的額外元數據的開銷。另外對於String類型來說,除了SDS的額外開銷外,還有一個叫做RedisObject結構體的開銷。因為Redis的數據類型有很多,不同的數據類型都有相同的元數據要記錄(例如最後一次訪問時間),所以Redis會採用一個叫做RedisObject結構體來統一記錄這些元數據。一個RedisObject包含了一個8位元組的元數據和一個8位元組的指針,這個指針指向具體數據所在,例如String類型的SDS結構體所在的內存地址。如下圖所示:

為了節省內存空間,Redis對Long類型整數和SDS的內存布局做了專門的設計。一方面,當保存的是 Long 類型整數時,RedisObject 中的指針就直接賦值為整數數據了,這樣就不用額外的指針再指向整數了,節省了指針的空間開銷。另一方面,當保存的是字符串數據,並且字符串小於等於 44 位元組時,RedisObject 中的元數據、指針和 SDS 是一塊連續的內存區域,這樣就可以避免內存碎片。這種布局方式也被稱為 embstr 編碼方式。當字符串大於44位元組時,SDS的數據量就開始變多了,Redis 就不再把SDS 和
RedisObject 布局在一起了,而是會給 SDS 分配獨立的空間,並用指針指向 SDS 結構。這種布局方式被稱為 raw 編碼模式。如下圖所示:
現在我們來計算一下一對圖片ID和圖片存儲對象ID的內存的使用量。由於10位數的圖片ID和圖片存儲對象ID是Long類型整數,所以可以直接用int編碼的RedisObject保存。相對應的RedisObject元數據部分佔8位元組,指針部分被直接賦值為8位元組的整數了。此時,每個ID會使用16位元組,加起來一共是32位元組。但是,另外的 32 位元組去哪兒了呢?
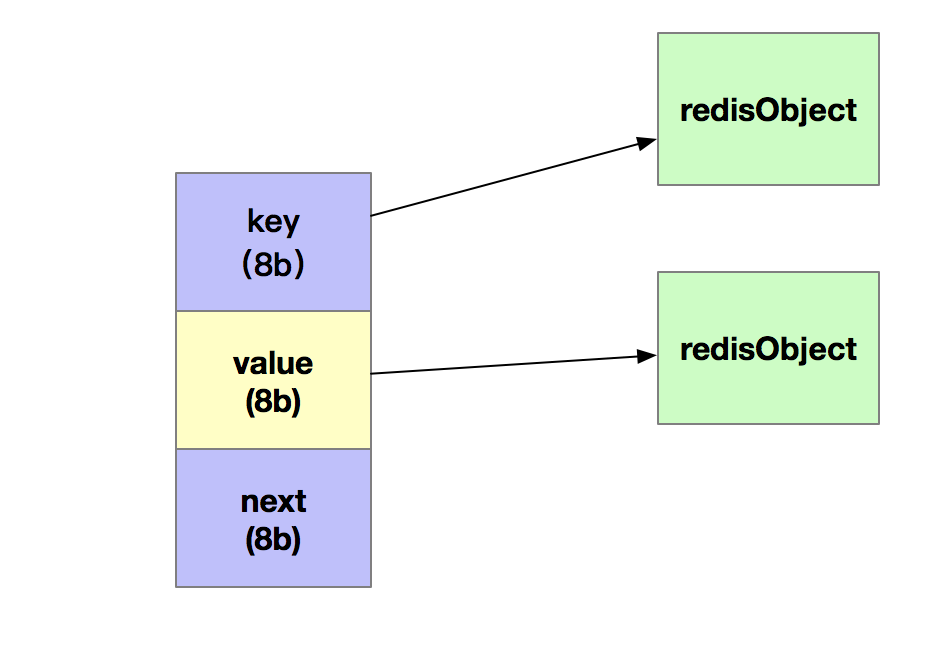
由於Redis是使用全局哈希表來保存所有的鍵值對,哈希表的每一項是一個dictEntity的結構體來指向一個鍵值對。dictEntity由三個8位元組的指針組成,分別來指向key、value以及下一個dictEntity。如下圖所示。
由於Redis使用的內存分配庫為jemalloc,jemalloc在分配內存時,會根據申請的位元組數N,找一個比N大的,最接近N的2的冪次數作為分配的空間。
所以申請一個24位元組的dictEntity,實際會分配32個位元組。
到目前位置,你應該明白了為什麼String類型來保存圖片ID和圖片存儲對象ID會佔用64個位元組了。一個有效信息只有16個位元組,在使用String類型保存時,卻要佔用64個位元組內存空間,有48個位元組用來保存元數據信息了,這是不是極大的浪費了內存空間。那麼有沒有更加節省內存的方法呢?
用壓縮列表節省內存
Redis里有一種叫做壓縮列表的結構,非常節省內存。我們先回顧一下壓縮列表的構成。表頭有三個字段zlbytes、zllen和zltail,分別表示列表的長度、列表尾的偏移量以及列表中entry的個數。壓縮列表表尾有一個zlend,表示列表結束。如下圖所示。

由於壓縮列表採用一系列的entry保存數據,這些entry會挨個兒放置在內存中,不需要再用額外的指針進行連接,這樣就可以節省指針所佔用的空間。每個entry由以下幾部分組成。
-
pre_len:表示前一個entry的長度。prev_len有兩種取值情況:1 位元組或 5 位元組。當上一個 entry 長度小於 254 位元組時,prev_len 取值為 1 位元組,否則,就取值為 5 位元組。
-
len:表示自身的長度,佔4個位元組。
-
encoding:表示編碼方式,佔1個位元組。
-
content:保存實際數據。
假設我們使用entry來保存圖片存儲對象ID(佔8個位元組),此時,每個entry的prev_len佔用1個位元組就行,因為每一個entry的前一個entry的長度小於264位元組。這樣一來,一個圖片對象ID所佔用的內存大小是14(1+4+1+8)個位元組,實際上會分配16個位元組。
Redis里基於壓縮列表實現了List、Hash和Sorted Set集合類型,這樣做的最大好處就是節省了dictEntity的內存開銷。對於String類型來說,一個鍵值對就有一個dictEntity,佔用32個位元組。對於集合類型來說,一個key對應了很多數據,卻只是佔用了一個dictEntity,這樣就節省了內存空間。
如何用集合類型存儲單值的鍵值對的數據
在保存單值鍵值對的數據時,我們可以使用基於Hash類型的二級編碼方式。這裡所說的二級編碼,是指把單值的數據拆成兩部分,前一部分作為Hash的key,後一部分作為Hash的value。 以圖片的ID為1101021043,它所對應的圖片存儲對象的ID為2301010051為例,我們將圖片的ID的前7位(1101021)作為Hash類型的鍵,後3位(043)和圖片存儲對象ID為2301010051作為Hash類型的key和value。我們按照這種設計,在Redis中插入一條記錄,只佔用了16位元組,所以和使用String類型佔用64位元組對比,節省了很多空間。 最後,我們再思考一個問題,為什麼要把圖片ID的前7位作為Hash類型的鍵,後3位作為Hash類型的key呢。我們在Redis存儲結構里介紹過Redis的Hash類型的兩種底層實現結構,分別是壓縮列表和哈希表。Hash 類型設置了用壓縮列表保存數據時的兩個閾值,一旦超過了閾值,Hash 類型就會用哈希表來保存數據了。這兩個閾值分別對應以下兩個配置項:
-
hash-max-ziplist-entries:表示用壓縮列表保存時哈希集合中的最大元素個數。
-
hash-max-ziplist-value:表示用壓縮列表保存時哈希集合中單個元素的最大長度。
在內存節省空間方面,哈希表就沒有壓縮列表那麼高效。我們只用後3位作為Hash類型的key,也就保證哈希集合中元素的個數不會超過1000,同時我們通過設置hash-max-ziplist-entries=1000,來確保Hash類型底層使用的是壓縮列表這種數據結構。
好了,今天的介紹就到這裡。更多硬核知識,請關注公序員學長 。


