分佈式一致性協議
- 2019 年 10 月 3 日
- 筆記
介紹常見的分佈式一致性協議
一.CAP/BASE
1. CAP理論
CAP理論又稱之為布魯爾定理(Brewer』S theorem),認為在設計一個大規模可擴放的網絡服務時候不能同時兼容:一致性(consistency)、可用性(Availability)、分區容錯(Partition-tolerance)。
一致性:在分佈式系統中的所有數據備份,在同一時刻是否有同樣的值。(等同於所有節點訪問同一份最新的數據副本)
可用性:在集群中一部分節點故障後,集群整體是否還能響應客戶端的讀寫請求。
分區容忍性:以實際效果而言,分區相當於對通信的時限要求。系統如果不能在時限內達成數據一致性,就意味着發生了分區的情況,必須就當前操作在C和A之間做出選擇
CAP理論容易理解,網上也有關於該理論的說明,包括模型的簡易證明;弱條件下模型的成立等。
參考資料:
2. BASE理論
BASE是Basically Available(基本可用)、Soft state(軟狀態)和Eventually consistent(最終一致性)三個短語的簡寫,BASE是對CAP中一致性和可用性權衡的結果,其來源於對大規模互聯網系統分佈式實踐的結論,是基於CAP定理逐步演化而來的,其核心思想是即使無法做到強一致性(Strong consistency),但每個應用都可以根據自身的業務特點,採用適當的方式來使系統達到最終一致性(Eventual consistency)
基本可用:分佈式系統在出現故障的時候,允許損失部分可用性,即保證核心可用。
軟狀態:允許系統存在中間狀態,而該中間狀態不會影響系統整體可用性
最終一致性:系統中的所有數據副本經過一定時間後,最終能夠達到一致的狀態
二.兩階段提交
兩階段提交(Two-phaseCommit)是指,在計算機網絡以及數據庫領域內,為了使基於分佈式系統架構下的所有節點在進行事務提交時保持一致性而設計的一種算法。
在分佈式系統中,每個節點雖然可以知曉自己的操作時成功或者失敗,卻無法知道其他節點的操作的成功或失敗。當一個事務跨越多個節點時,為了保持事務的ACID特性,需要引入一個作為協調者的組件來統一掌控所有節點(稱作參與者)的操作結果並最終指示這些節點是否要把操作結果進行真正的提交。
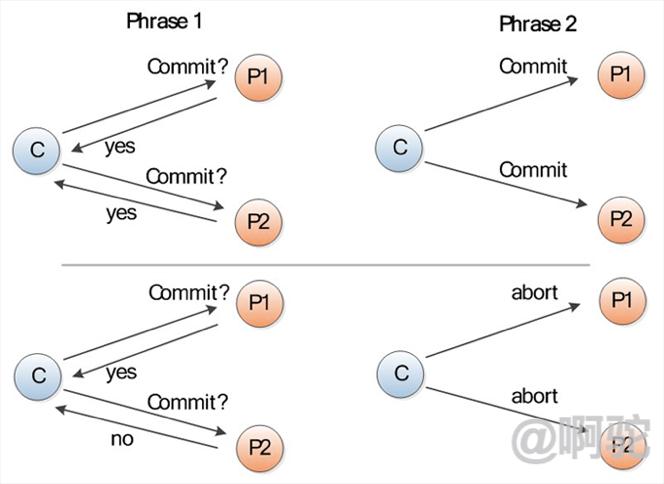
如上圖示,該協議分為兩個階段:
-
請求階段(commit-request phase,或稱表決階段,voting phase)
在請求階段,協調者將通知事務參與者準備提交或取消事務,然後進入表決過程。在表決過程中,參與者將告知協調者自己的決策:同意(事務參與者本地作業執行成功)或取消(本地作業執行故障)。
-
提交階段(commit phase)
在該階段,協調者將基於第一個階段的投票結果進行決策:提交或取消。當且僅當所有的參與者同意提交事務協調者才通知所有的參與者提交事務,否則協調者將通知所有的參與者取消事務。參與者在接收到協調者發來的消息後將執行相應的操作。
二階段提交算法的最大缺點就在於它在執行過程中間,節點都處於阻塞態。即節點之間在等待對方的響應消息時,它將什麼也做不了。特別是,當一個節點在已經佔有了某項資源的情況下,為了等待其他節點的響應消息而陷入阻塞狀態時,當第三個節點嘗試訪問該節點佔有的資源時,這個節點也將連帶陷入阻塞狀態。
另外,協調者節點指示參與者節點進行提交等操作時,如有參與者節點出現了崩潰等情況而導致協調者始終無法獲取所有參與者的響應信息,這時協調者將只能依賴協調者自身的超時機制來生效。但往往超時機制生效時,協調者都會指示參與者進行回滾操作。這樣的策略顯得比較保守。
參考資料
三.三階段提交
與兩階段提交不同的是,三階段提交是「非阻塞」協議。三階段提交在兩階段提交的第一階段與第二階段之間插入了一個準備階段,同時對於協調者和參與者都設置了超時機制,使得原先在兩階段提交中,參與者在投票之後,由於協調者發生崩潰或錯誤,而導致參與者處於無法知曉是否提交或者中止的「不確定狀態」所產生的可能相當長的延時的問題得以解決。
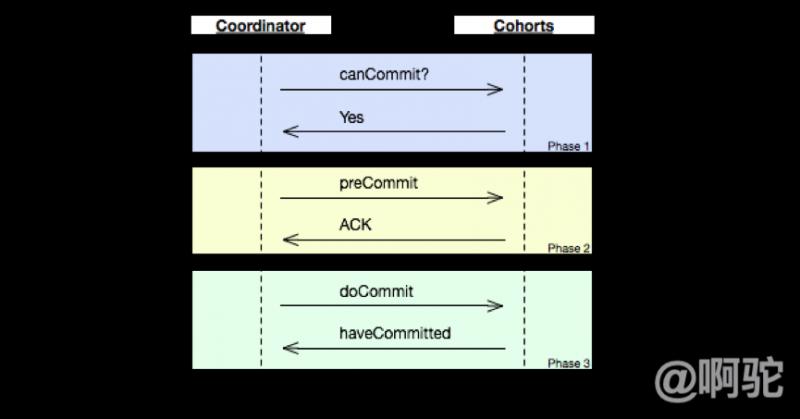
如上圖示,該協議分為三個階段:
- canCommit
協調者向參與者發送commit請求,參與者如果可以提交就返回Yes響應,否則返回No響應。
-
preCommit
協調者根據參與者的反應情況來決定是否可以進行事務的PreCommit操作。根據響應情況,有以下兩種可能.
1) 假如協調者從所有的參與者獲得的反饋都是Yes響應,那麼就會執行事務的預執行。
發送預提交請求,Coordinator向Cohort發送PreCommit請求,並進入Prepared階段。
事務預提交,Cohort接收到PreCommit請求後,會執行事務操作,並將undo和redo信息記錄到事務日誌中。
響應反饋,如果Cohort成功的執行了事務操作,則返回ACK響應,同時開始等待最終指令。
2) 假如有任何一個參與者向協調者發送了No響應,或者等待超時之後,協調者都沒有接到參與者的響應,那麼就執行事務的中斷。
發送中斷請求,Coordinator向所有Cohort發送abort請求。
中斷事務,Cohort收到來自Coordinator的abort請求之後(或超時之後,仍未收到Cohort的請求),執行事務的中斷。
-
doCommit
該階段進行真正的事務提交,也可以分為以下兩種情況:
1) 執行提交
A.發送提交請求。Coordinator接收到Cohort發送的ACK響應,那麼他將從預提交狀態進入到提交狀態。並向所有Cohort發送doCommit請求。
B.事務提交。Cohort接收到doCommit請求之後,執行正式的事務提交。並在完成事務提交之後釋放所有事務資源。
C.響應反饋。事務提交完之後,向Coordinator發送ACK響應。
D.完成事務。Coordinator接收到所有Cohort的ACK響應之後,完成事務。
2) 中斷事務 協調者沒有接收到參與者發送的ACK響應(可能是接受者發送的不是ACK響應,也可能響應超時),那麼就會執行中斷事務。
參考資料:
四. Paxos
1.背景
在常見的分佈式系統中,總會發生諸如機器宕機或網絡異常等情況。Paxos算法需要解決的問題就是如何在一個可能發生上述異常的分佈式系統中,快速且正確地在集群內部對某個數據的值達成一致,並且保證不論發生以上任何異常,都不會破壞整個系統的一致性。這裡某個數據的值並不只是狹義上的某個數,它可以是一條日誌,也可以是一條命令(command)等,根據應用場景不同,某個數據的值有不同的含義。
2.相關概念
在Paxos算法中,有三種角色:
-
Proposer:提案發起者,向集群中的其他節點發一個提案Proposal,該提案中有一個對應的值。
-
Acceptor:提案接受者,負責處理接收到的提議,他們的回復就是一次投票。會存儲一些狀態來決定是否接收一個值。
-
Learners:不參與提案的發起和投票,學習已經被Acceptor接受的提案
3.目標
保證最終有一個value會被選定,當value被選定後,進程最終也能獲取到被選定的value。
4.兩個原則
-
安全性原則:保證不能做錯的事。只能有一個值被批准,不能出現第二個值把第一個覆蓋的情況;每個節點只能學習到已經被批准的值,不能學習沒有被批准的值。
-
存活原則:只要有多數服務器存活並且彼此間可以通信最終都要做到的事。最終會批准某個被提議的值;一個值被批准了,其他服務器最終會學習到這個值。
5.Basic Paxos
Basic Paxos算法分為兩個階段。具體如下:
階段一:
-
Proposer選擇一個提案編號N,然後向半數以上的Acceptor發送編號為N的Prepare請求。
-
如果一個Acceptor收到一個編號為N的Prepare請求,且N大於該Acceptor已經響應過的所有Prepare請求的編號,那麼它就會將它已經接受過的編號最大的提案(如果有的話)作為響應反饋給Proposer,同時該Acceptor承諾不再接受任何編號小於N的提案。
階段二:
-
如果Proposer收到半數以上Acceptor對其發出的編號為N的Prepare請求的響應,那麼它就會發送一個針對[N,V]提案的Accept請求給半數以上的Acceptor。注意:V就是收到的響應中編號最大的提案的value,如果響應中不包含任何提案,那麼V就由Proposer自己決定。
-
如果Acceptor收到一個針對編號為N的提案的Accept請求,只要該Acceptor沒有對編號大於N的Prepare請求做出過響應,它就接受該提案。
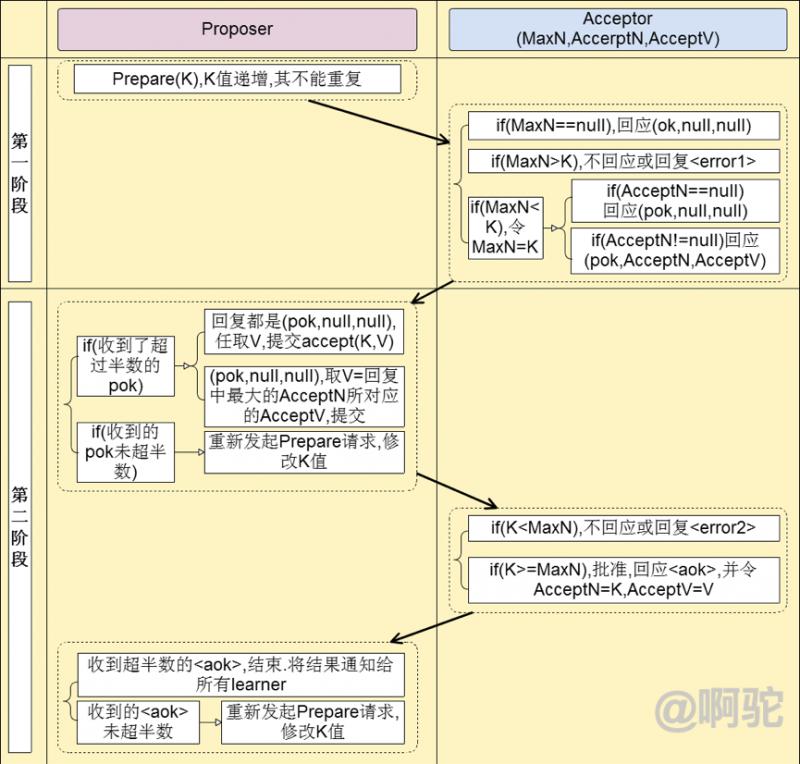
示例過程如下,其中MaxN,AccerptN,AcceptV分別表示Acceptor的最大響應提案編號,接受的最大編號和接受編號對應的值:
6.推導過程
1)只有一個Acceptor,只要Acceptor接受它收到的第一個提案並被選定,則可以保證只有一個value會被選定。 2)多個Acceptor 提案(Propersal) = [value] 即使只有一個Proposer提出了一個value,該value也最終被選定 => P1:一個Acceptor必須接受它收到的第一個提案。 => 如果每個Proposer分別提出不同的value,發給不同的Acceptor, Acceptor分別接受自己收到的value,就導致不同的value被選定。 => 一個提案被選定需要被半數以上的Acceptor接受 => 一個Acceptor必須能夠接受不止一個提案 => 提案(Propersal) = [提案編號,value] => 必須保證所有被選定的提案都具有相同的value值 => P2:如果某個value為v的提案被選定了,那麼每個編號更高的被選定提案的value必須也是v。=> P2a:如果某個value為v的提案被選定了,那麼每個編號更高的被Acceptor接受的提案的value必須也是v。=> 分區不可用不符合 => P2b:如果某個value為v的提案被選定了,那麼之後任何Proposer提出的編號更高的提案的value必須也是v。=> P2c:對於任意的N和V,如果提案[N, V]被提出,那麼存在一個半數以上的Acceptor組成的集合S,滿足以下兩個條件中的任意一個: - S中每個Acceptor都沒有接受過編號小於N的提案。 - S中Acceptor接受過的最大編號的提案的value為V。=> Proposer生成提案,需要先詢問集群中其他的節點,確定可被接受的value。=> Acceptor接受提案,一個Acceptor只要尚未響應過任何編號大於N的Prepare請求,那麼他就可以接受這個編號為N的提案。 7.Multi-Paxos
basic paxos是由client發起的同步過程,在兩階段返回前,client不能得到成功的返回。引用wiki上的流程圖:
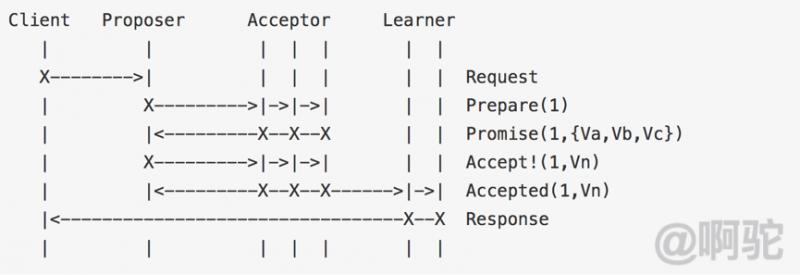
multi-paxos 在basic paxos的二階段上引入了一個機制,先運行一次完整的paxos算法選舉出leader,由leader處理所有的讀寫請求,然後省略掉prepare過程,讓自己看起來像一階段一樣。multi-paxos強leader狀態的流程圖:

流程圖中沒有了basic paxos的兩階段,變成了一個一階段的遞交協議:
一階段a:發起者(leader)直接告訴Acceptor,準備遞交協議號為I+1的協議
一階段b:收到了大部分acceptor的回復後(圖中是全部),acceptor就直接回復client協議成功寫入
Multi-Paxos可以簡單的理解為, 經過一輪的Basic Paxos, 成功得到多數派accept的proposer即成為leader(這個過程稱為leader Election), 之後可以通過lease機制, 保持這個leader的身份, 使得其他proposer不再發起提案, 這樣就進入了一個leader任期。在leader任期中, 由於沒有了並發衝突, 這個leader在對後續的日誌進行投票時, 不必每次都向多數派詢問提案, 也不必執行prepare階段, 直接執行accept階段即可。
因此在Multi-Paxos中, 我們將leader Election過程中的prepare操作, 視為對leader任期內將要寫的所有日誌的一次性prepare操作, 在leader任期內投票的所有日誌將攜帶有相同的提案編號. 需要強調的是, 為了遵守Basic Paxos協議約束, 在leader Election的prepare階段, acceptor應答prepare成功的消息之前要先將這次prepare請求所攜帶的提案編號持久化到本地。
參考資料:
-
[https://en.wikipedia.org/wiki/Paxos_(computer_science)](https://en.wikipedia.org/wiki/Paxos_(computer_science)
-
http://www.infoq.com/cn/articles/weinxin-open-source-paxos-phxpaxos
五.Raft
與Paxos不同Raft強調的是易懂(Understandability),Raft和Paxos一樣只要保證n/2+1節點正常就能夠提供服務;眾所周知但問題較為複雜時可以把問題分解為幾個小問題來處理,Raft也使用了分而治之的思想把算法流程分為三個子問題:選舉(Leader election)、日誌複製(Log replication)、安全性(Safety)三個子問題。
1.角色:
在任意的時間,每一個服務器一定會處於以下三種狀態中的一個:Leader、Candidate、Follower。在正常情況下,只有一個服務器是Leader,剩下的服務器是Follower。Follower們是被動的:他們不會發送任何請求,只是響應來自領導人和候選人的請求;Leader來處理所有來自客戶端的請求(如果一個客戶端與追隨者進行通信,追隨者會將信息發送給領導人);Candidate是用來選取一個新的領導人的,在Leader確定後降級為Follower。如下圖為各個角色的轉換流程:
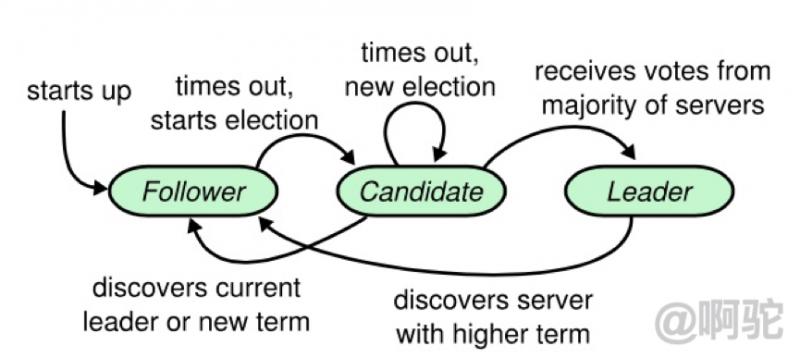
2.Term:
在Raft中使用了一個可以理解為周期(第幾屆、任期)的概念,用Term作為一個周期,每個Term都是一個連續遞增的編號,每一輪選舉都是一個Term周期,在一個Term中只能產生一個Leader:
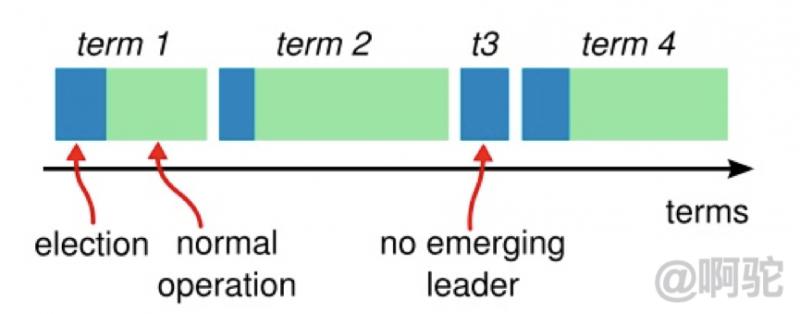
每一台服務器都存儲着一個當前Term的數字,這個數字會單調的增加。當服務器之間進行通信時,會互相交換當前Term值;如果一台服務器的當前Term比其它服務器的小,則更新為較大的值。如果一個候選人或者領導人意識到它的Term過時了,它會立刻轉換為Follower狀態。如果一台服務器收到的請求的Term是過時的,那麼它會拒絕此次請求。
3.RPC通信:
-
RequestVote RPC:Candidate在選舉過程中觸發,用於從Follower獲取選票。
-
AppendEntries RPC:Leader觸發的,為的是複製日誌條目和提供一種心跳機制。
4. Leader election
在Leader election中有兩個超時時間,分別為:
-
Election timeout:Follower轉變為Candidate的超時時間,是一個隨機值。在選舉Leader過程中,如果一個Follower沒有在Election timeout時間內收到來自Leader的AppendEntries RPC請求或者Candidate的RequestVote RPC請求的話,則Follower會轉變為Candidate,並發起選舉。
-
Heartbeate timeout:Leader存在時,Follower在Heartbeat timeout時間內沒有接收到Leader的AppendEntires請求,則認為Leader已經下線,自己會轉變為Candidate,發起選舉。
開始時,每個節點都以Follower啟動,在第一輪時,由於沒有收到任何的RPC請求,會觸發Election timeout,節點會自增Term,轉為Candidate,發起選舉,不斷重試,直到滿足以下任一條件:
-
獲得超過半數Server的投票,轉換為Leader,廣播Heartbeat
-
接收到合法Leader的AppendEntries RPC,轉換為Follower
-
選舉超時,沒有Server選舉成功,自增currentTerm,重新選舉
Candidate在等待投票結果的過程中,可能會接收到來自其它Leader的AppendEntries RPC。如果該Leader的Term不小於本地的currentTerm,則認可該Leader身份的合法性,主動降級為Follower;反之,則維持Candidate身份,繼續等待投票結果;Candidate既沒有選舉成功,也沒有收到其它Leader的RPC請求,這種情況一般出現在多個節點同時發起選舉,最終每個Candidate都將超時。為了減少衝突,這裡採取「隨機退讓」策略,每個Candidate重啟選舉定時器(隨機值),大大降低了衝突概率。
5. Log replication
Log Replication主要作用是用於保證節點的一致性,這階段所做的操作也是為了保證一致性與高可用性;當Leader選舉出來後便開始負責客戶端的請求,所有事務(更新操作)請求都必須先經過Leader處理。
正常操作流程:
-
Client發送command給Leader
-
Leader追加command至本地log
-
Leader廣播AppendEntries RPC至Followers
-
一旦收到滿足數量的日誌項committed成功的響應:
1) Leader應用對應的command至本地State Machine,並返回結果至Client
2) Leader通過後續Append EntriesRPC將committed日誌項通知到Follower
3) Follower收到committed日誌項後,將其應用至本地State Machine
6. Safety
安全性是用於保證每個節點都執行相同序列的安全機制, Raft算法保證以下屬性時刻為真:
-
Election Safety:在任意指定Term內,最多選舉出一個Leader
-
Leader Append-Only
-
Log Matching:如果兩個節點上的日誌項擁有相同的Index和Term,那麼這兩個節點[0, Index]範圍內的Log完全一致
-
Leader Completeness:如果某個日誌項在某個Term被commit,那麼後續任意Term的Leader均擁有該日誌項
-
State Machine Safety
一旦某個server將某個日誌項應用於本地狀態機,以後所有server對於該偏移都將應用相同日誌項
7.集群拓撲變化
集群拓撲變化的意思是在運行過程中多副本集群的結構性變化,如增加/減少副本數、節點替換等
。為了防止出現多主的情況,raft使用了兩階段提交來處理。假設在Raft中,老集群配置用Cold表示,新集群配置用Cnew表示,整個集群拓撲變化的流程如下:
-
當集群成員配置改變時,leader收到人工發出的重配置命令從Cold切成Cnew;
-
Leader副本在本地生成一個新的log entry,其內容是Cold∪Cnew,代表當前時刻新舊拓撲配置共存,寫入本地日誌,同時將該log entry推送至其他Follower節點;
-
Follower副本收到log entry後更新本地日誌,並且此時就以該配置作為自己了解的全局拓撲結構;如果多數Follower確認了Cold∪Cnew這條日誌的時候,Leader就Commit這條log entry;
-
接下來Leader生成一條新的log entry,其內容是全新的配置Cnew,同樣將該log entry寫入本地日誌,同時推送到Follower上;
-
Follower收到新的配置日誌Cnew後,將其寫入日誌,並且從此刻起,就以該新的配置作為系統拓撲,並且如果發現自己不在Cnew這個配置中會自動退出;
-
Leader收到多數Follower的確認消息以後,給客戶端發起命令執行成功的消息。
參考資料:
六.Zab
ZAB 協議是為分佈式協調服務 ZooKeeper 專門設計的一種支持崩潰恢復的原子廣播協議。在 ZooKeeper 中,主要依賴 ZAB 協議來實現分佈式數據一致性,基於該協議,ZooKeeper 實現了一種主備模式的系統架構來保持集群中各個副本之間的數據一致性。
1. 相關術語
-
Peer:節點。代表了系統中的進程,往往系統有多個進程,也就有多個節點提供服務
-
Quorum:多數。當有N個Peer,多數就代表Q(Q>N/2)個Peer
-
Leader:主節點,最多存在一個。代表zookeeper系統中主要的工作進程,Leader才是真正處理所有zookeeper寫請求的節點,寫請求會從Leader廣播到Quorum Follower
-
Follower:從節點,可以有多個。如果client對zookeeper發起一個讀請求,Follower可以直接處理。如果client對zookeeper發起一個寫請求,Follower需要轉發到唯一的Leader,再有Leader處理並發起廣播
-
transaction:事務,一次寫請求就代表一次事務
-
zxid:事務id。zk為了保證消息有序性,提出了事務編號這個概念。zxid是一個二元組,e代表選舉紀元,c代表事務的計數,同一紀元內每次出現寫請求,c自增。容易理解,紀元不變時,計數不斷增加,紀元變化時,計數清零。
-
acceptedEpoch:follower 已經接受的 leader 更改紀元的提議。
-
state:節點狀態,目前只有這三種:
election:節點處於選舉狀態
leading:當前節點是 leader,負責協調事務
following:當前節點是跟隨者,服從 leader 節點的命令
代碼實現中多了一種:observing 狀態,這是 Zookeeper 引入 Observer 之後加入的,Observer 不參與選舉,是只讀節點,跟 ZAB 協議沒有關係節點的持久狀態。
-
history:當前節點接收到事務提議的 log。
-
lastZxid:history 中最近接收到的提議的 zxid (最大的)。
2.協議內容
隨着系統啟動或者恢復,會經歷Zab協議中描述的如下四個階段:
Phase 0:Leader選舉,每個peer從Quorum peer中選出自己心中的准leader。節點在一開始都處於選舉階段,只要有一個節點得到超半數節點的票數,它就可以當選准 leader。這一階段的目的是就是為了選出一個準 leader,然後進入下一個階段。
Phase 1:發現,准leader從Quorum Follower中發現最新的數據,並覆蓋自己的過期數據。在這個階段,followers 跟准 leader 進行通信,同步 followers 最近接收的事務提議。這一階段的主要目的是發現當前大多數節點接收的最新提議,並且准 leader 生成新的 epoch,讓 followers 接受,更新它們的 acceptedEpoch。
Phase 2:同步,准leader採用二階段提交的方式將自己的最新數據同步給Quorum Follower。完成這個步驟,准leader就轉為正式leader。同步階段主要是利用 leader 前一階段獲得的最新提議歷史,同步集群中所有的副本。只有當 quorum 都同步完成,准 leader 才會成為真正的 leader。follower 只會接收 zxid 比自己的 lastZxid 大的提議。
Phase 3:廣播,Leader接受寫請求,並通過二階段提交的方式廣播給Quorum Follower。到了這個階段,Zookeeper 集群才能正式對外提供事務服務,並且 leader 可以進行消息廣播。同時如果有新的節點加入,還需要對新節點進行同步。ZAB 提交事務並不像 2PC 一樣需要全部 follower 都 ACK,只需要得到 quorum (超過半數的節點)的 ACK 就可以了。
3.實現
真正apache zookeeper在實現上提出設想:優化leader選舉,直接選出最新的Peer作為預備Leader,這樣就能將Phase 0和Phase 1合併,減少網絡上的開銷和多流程的複雜性。
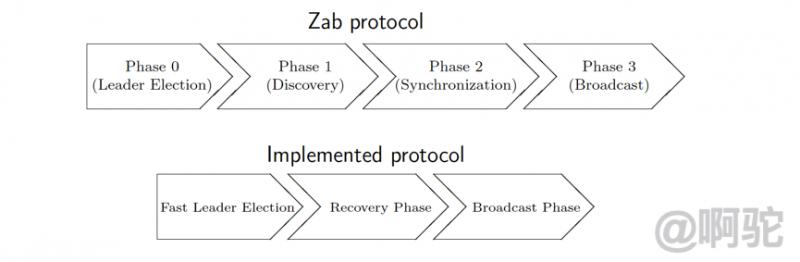
實現上,協議被簡化為三個階段
Fast Leader Election:從Quorum Peer中選出數據最新的peer作為leader。該階段會選舉擁有最新提議歷史(lastZixd最大)的節點作為 leader,這樣就省去了發現最新提議的步驟。這是基於擁有最新提議的節點也有最新提交記錄的前提。成為 leader 的條件:選epoch最大的;epoch相等,選 zxid 最大的;epoch和zxid都相等,選擇myid最大的。節點在選舉開始都默認投票給自己,當接收其他節點的選票時,會根據上面的條件更改自己的選票並重新發送選票給其他節點,當有一個節點的得票超過半數,該節點會設置自己的狀態為 leading,其他節點會設置自己的狀態為 following。
Recovery Phase:Leader將數據同步給Quorum Follower。
Broadcast Phase:Leader接受寫請求,並廣播給Quorum Follower。
對於選舉和恢復階段,zab算法需要確保兩件事:
-
已經處理過的提案不能被丟棄。
-
已經丟棄的提案不能被重複處理。
參考資料:

個人公眾號:啊駝
