《數據存儲》之《分庫,分表》
- 2021 年 7 月 20 日
- 筆記
序言
這段時間有很多人問我關於數據量大了,數據庫如何去滿足寫入和查詢速度;
有沒有做過分庫分表結構算法;
其實在之前的文章也寫過類似的文章《net.sz.framework 框架 ORM 消消樂超過億條數據排行榜分析 天王蓋地虎》
當時開心消消樂非常盛興所以寫了一個簡單的分析,其實不一定符合規範,或者符合具體業務需求
只能說是拋磚引玉吧,也希望得到大家更好的推薦;
註解一
我們在開始今天的情況之前,先來看一下在我的架構下處理數據問題
由於這台電腦問題,沒有裝mysql,我們就用sqlite代替;因為其實主要是介紹分庫分表的思路;
想創建一下測試模型代碼類


1 package com.db.test; 2 3 import com.ty.tools.db.struct.DbColumn; 4 import com.ty.tools.db.struct.DbModel; 5 import com.ty.tools.db.struct.DbTable; 6 7 /** 8 * @author: Troy.Chen(失足程序員, 15388152619) 9 * @version: 2021-07-20 10:36 10 **/ 11 @DbTable 12 public class RoleLoginLog extends DbModel { 13 14 @DbColumn(key = true, comment = "主鍵id") 15 private long id; 16 @DbColumn(index = true, comment = "日誌記錄時間") 17 private long logTime; 18 @DbColumn(index = true) 19 private long userId; 20 @DbColumn(index = true) 21 private long roleId; 22 @DbColumn(index = true) 23 private String roleName; 24 25 public long getId() { 26 return id; 27 } 28 29 public RoleLoginLog setId(long id) { 30 this.id = id; 31 return this; 32 } 33 34 public long getLogTime() { 35 return logTime; 36 } 37 38 public RoleLoginLog setLogTime(long logTime) { 39 this.logTime = logTime; 40 return this; 41 } 42 43 public long getUserId() { 44 return userId; 45 } 46 47 public RoleLoginLog setUserId(long userId) { 48 this.userId = userId; 49 return this; 50 } 51 52 public long getRoleId() { 53 return roleId; 54 } 55 56 public RoleLoginLog setRoleId(long roleId) { 57 this.roleId = roleId; 58 return this; 59 } 60 61 public String getRoleName() { 62 return roleName; 63 } 64 65 public RoleLoginLog setRoleName(String roleName) { 66 this.roleName = roleName; 67 return this; 68 } 69 }
View Code
接下來看調用代碼
1 /* 2 todo 自定義的id生成器;我們在寫入日誌或者其他數據, 3 千萬不要去自增id情況,一定要自定義id, 4 只要你保證你的自定義的id是唯一那麼就一定能寫入數據庫 5 */ 6 final static IdFormat idFormat = new IdFormat(); 7 8 public static void main(String[] args) { 9 10 final SqliteDataHelper db1 = createDataHelper("db1"); 11 /*檢查數據庫表結構*/ 12 db1.createTable(RoleLoginLog.class); 13 14 RoleLoginLog roleLoginLog = new RoleLoginLog() 15 .setId(idFormat.getId()) 16 .setUserId(1) 17 .setLogTime(System.currentTimeMillis()) 18 .setRoleId(1) 19 .setRoleName("1"); 20 db1.getBatchPool().replace(roleLoginLog); 21 22 System.out.println(roleLoginLog.toString()); 23 24 } 25 26 public static SqliteDataHelper createDataHelper(String dbName) { 27 SqliteDataHelper dataHelper = new SqliteDataHelper("target/db/sqlite/" + dbName + ".db3", dbName, null); 28 /*設置查看打印*/ 29 dataHelper.getDbConfig().setShow_sql(true); 30 dataHelper 31 /*初始化批量提交參數*/ 32 .initBatchPool("sqlite") 33 /*設置批量提交的量*/ 34 .setCommitSize(10000) 35 /*使用事務*/ 36 .setTransaction(true); 37 return dataHelper; 38 }
執行可以看到,建庫建表的sql語句已經插入數據的結果
[07-20 12:16:00:706:[ERROR]:[main]:SqlExecute.java.executeScalar():263] select sum(1) `TABLE_NAME` from sqlite_master where type ='table' and `name`= ? ; [07-20 12:16:00:721:[ERROR]:[main]:SqliteDataHelper.java.existsTable():128] 數據庫:db1 表:roleloginlog 檢查結果:無此表 [07-20 12:16:00:730:[WARN ]:[main]:SqlExecute.java.execute():44] 數據庫:db1 CREATE TABLE `roleloginlog` ( `id` bigint NOT NULL PRIMARY KEY, `logTime` bigint, `userId` bigint, `roleId` bigint, `roleName` varchar(255) ); 執行結果:false [07-20 12:16:00:751:[WARN ]:[main]:SqlExecute.java.execute():44] 數據庫:db1 CREATE INDEX roleloginlog_INDEX_logTime ON roleloginlog(logTime); 執行結果:false [07-20 12:16:00:753:[WARN ]:[main]:SqlExecute.java.execute():44] 數據庫:db1 CREATE INDEX roleloginlog_INDEX_userId ON roleloginlog(userId); 執行結果:false [07-20 12:16:00:754:[WARN ]:[main]:SqlExecute.java.execute():44] 數據庫:db1 CREATE INDEX roleloginlog_INDEX_roleId ON roleloginlog(roleId); 執行結果:false [07-20 12:16:00:757:[WARN ]:[main]:SqlExecute.java.execute():44] 數據庫:db1 CREATE INDEX roleloginlog_INDEX_roleName ON roleloginlog(roleName); 執行結果:false --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 當前操作總量:1 條, 當前耗時:24.9069 ms, 當前平均分佈:24.9069 ms/條, 當前性能:40.1495 條/S, 累計操作總量:1 條, 歷史耗時:24 ms, 歷史平均分佈:24.0000 ms/條, 歷史性能:41.6667 條/S, 當前剩餘:0 條未處理 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- { "id":1072012160000000000, "roleName":"1", "logTime":1626754560764, "userId":1, "roleId":1 }
這裡同樣打印了寫入數據的效率;
可能你覺得有點低;是不是?但是批量提交優勢在於當你需要寫入數據多,他才有優勢體現;
接下來我們寫入10萬條數據
1 public static void insert(SqliteDataHelper dataHelper) { 2 RoleLoginLog roleLoginLog = null; 3 for (int i = 0; i < 100000; i++) { 4 roleLoginLog = new RoleLoginLog() 5 .setId(idFormat.getId()) 6 .setUserId(1) 7 .setLogTime(System.currentTimeMillis()) 8 .setRoleId(i) 9 .setRoleName("1_" + i); 10 dataHelper.getBatchPool().replace(roleLoginLog); 11 } 12 }
測試結果
1 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 2 當前操作總量:10000 條, 當前耗時:120.6319 ms, 當前平均分佈:0.0121 ms/條, 當前性能:82896.8203 條/S, 3 累計操作總量:40001 條, 歷史耗時:625 ms, 歷史平均分佈:0.0156 ms/條, 歷史性能:64001.5977 條/S, 4 當前剩餘:60000 條未處理 5 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 6 7 8 9 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 10 當前操作總量:10000 條, 當前耗時:116.97 ms, 當前平均分佈:0.0117 ms/條, 當前性能:85492.0078 條/S, 11 累計操作總量:50001 條, 歷史耗時:741 ms, 歷史平均分佈:0.0148 ms/條, 歷史性能:67477.7344 條/S, 12 當前剩餘:50000 條未處理 13 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 14 15 16 17 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 18 當前操作總量:10000 條, 當前耗時:115.6237 ms, 當前平均分佈:0.0116 ms/條, 當前性能:86487.4531 條/S, 19 累計操作總量:60001 條, 歷史耗時:856 ms, 歷史平均分佈:0.0143 ms/條, 歷史性能:70094.6250 條/S, 20 當前剩餘:40000 條未處理 21 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 22 23 24 25 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 26 當前操作總量:10000 條, 當前耗時:112.8095 ms, 當前平均分佈:0.0113 ms/條, 當前性能:88645.0156 條/S, 27 累計操作總量:70001 條, 歷史耗時:968 ms, 歷史平均分佈:0.0138 ms/條, 歷史性能:72315.0859 條/S, 28 當前剩餘:30000 條未處理 29 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 30 31 32 33 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 34 當前操作總量:10000 條, 當前耗時:106.4188 ms, 當前平均分佈:0.0106 ms/條, 當前性能:93968.3594 條/S, 35 累計操作總量:80001 條, 歷史耗時:1074 ms, 歷史平均分佈:0.0134 ms/條, 歷史性能:74488.8281 條/S, 36 當前剩餘:20000 條未處理 37 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 38 39 40 41 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 42 當前操作總量:10000 條, 當前耗時:102.0073 ms, 當前平均分佈:0.0102 ms/條, 當前性能:98032.1953 條/S, 43 累計操作總量:90001 條, 歷史耗時:1176 ms, 歷史平均分佈:0.0131 ms/條, 歷史性能:76531.4609 條/S, 44 當前剩餘:10000 條未處理 45 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 46 47 48 49 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 50 當前操作總量:10000 條, 當前耗時:128.4668 ms, 當前平均分佈:0.0128 ms/條, 當前性能:77841.1250 條/S, 51 累計操作總量:100001 條, 歷史耗時:1304 ms, 歷史平均分佈:0.0130 ms/條, 歷史性能:76687.8828 條/S, 52 當前剩餘:0 條未處理 53 --------------------------------------------------sqlite-Batch-Thread-異步寫入-----------------------------------------------------------------------
看到了吧,性能差異,批量提交的意義就在於數據量多才能體現出性能優勢;
註解二—–分表
我們在寫入數據的時候可以根據自己的架構設計或代碼需求調整自己的方案;
我的分表思路是根據roleid來進行hash分表;為什麼這麼說呢,因為這樣可以, 無論你是分佈式也好,多進程集群也好,能保證針對單個角色(roleid)數據寫進同一張表
我們來看看剛才roleloginlog表修改方案;我們通過覆蓋父類DbModel的tableName代碼來得到實例model的對應表名
我們只需要改動這裡就能做到數據自動落地到不同的表
1 @Override 2 public String tableName() { 3 /* 4 測試情況,假設我們這個表數據量非常,我們把表拆分成10張 5 但是通常我們為了寫入和查詢方便,保證同一個角色數據在同一張表裏面 6 7 */ 8 long hashcode = roleId % 42 % 10; 9 return "roleloginlog_" + hashcode; 10 }
接下來是初始化創建數據表;
這個地方只是為了表現出如何創建分表;你也可以改成你自己的
1 public static void createTable(SqliteDataHelper dataHelper, Class<?> clazz) { 2 /*這個是數據模型映射關係,也就是把模型轉化成sql,把sql結果集轉化成模型*/ 3 SqlDataModelMapping modelMapping = dataHelper.dataWrapper(clazz); 4 final String tableName = modelMapping.getTableName(); 5 try (Connection connection = dataHelper.getConnection()) { 6 for (int i = 0; i < 10; i++) { 7 modelMapping.setTableName(tableName + "_" + i); 8 dataHelper.createTable(connection, modelMapping); 9 } 10 } catch (SQLException sqlException) { 11 throw new ThrowException(sqlException); 12 } 13 14 }
我們可以看到,表已經創建成功了;
接下來我們嘗試寫入數據
還是剛才的10萬條數據代碼;它就會自動分解到不同的表
--------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 當前操作總量:10000 條, 當前耗時:408.4178 ms, 當前平均分佈:0.0408 ms/條, 當前性能:24484.7324 條/S, 累計操作總量:80001 條, 歷史耗時:3700 ms, 歷史平均分佈:0.0462 ms/條, 歷史性能:21621.8906 條/S, 當前剩餘:20000 條未處理 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 當前操作總量:10000 條, 當前耗時:346.221 ms, 當前平均分佈:0.0346 ms/條, 當前性能:28883.2871 條/S, 累計操作總量:90001 條, 歷史耗時:4046 ms, 歷史平均分佈:0.0450 ms/條, 歷史性能:22244.4395 條/S, 當前剩餘:10000 條未處理 --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- --------------------------------------------------sqlite-Batch-Thread-異步寫入----------------------------------------------------------------------- 當前操作總量:10000 條, 當前耗時:327.8309 ms, 當前平均分佈:0.0328 ms/條, 當前性能:30503.5293 條/S, 累計操作總量:100001 條, 歷史耗時:4373 ms, 歷史平均分佈:0.0437 ms/條, 歷史性能:22867.8262 條/S, 當前剩餘:0 條未處理 --------------------------------------------------sqlite-Batch-Thread-異步寫入-----------------------------------------------------------------------
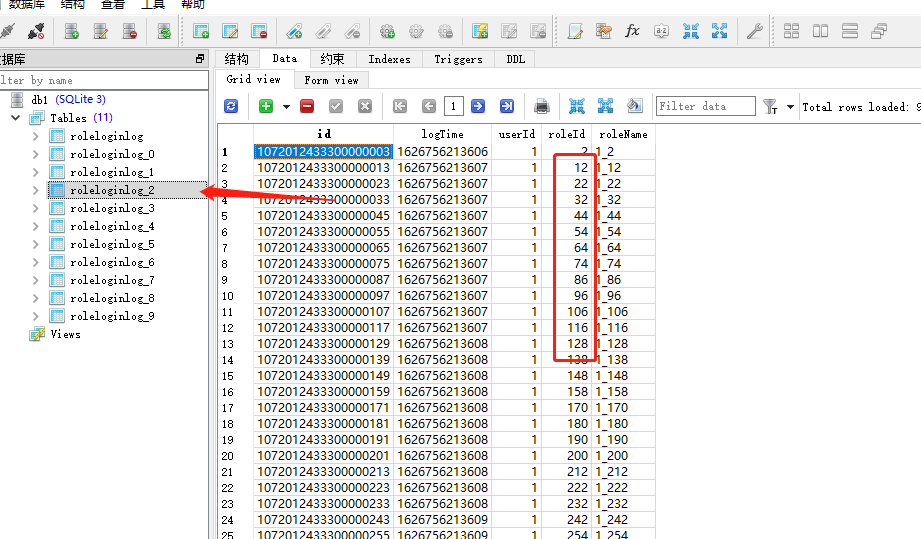

可以很清晰的看到嘛,數據寫入到數據庫了,而且指定的roleid數據寫入表結構;
我們為啥要把指定roleid放在一張表呢,主要是為了讀取數據的時候不需要聯合查詢,多表查詢情況;針對同樣的數據;(當然你可以可以根據你的業務進行二次拆分)
分表,主要解決問題是當你數據量巨大,你預估都會超過千萬級別或者億級別;
這樣我們對數據的寫入和查詢都會變的非常慢;特別是某些表結構索引變的很多的時候,這個性能問題就越加明顯;
我們把數據拆分過後,數據分佈在不同的表裏面,加入說一億條數據拆分之後每張表就是1000萬條數據;
性能對比就不言而喻;
註解三—–分庫
針對分表過後,我們日漸增值的數據集合;只可能越來越大;越來越多;數據級別 GB -> TB -> PB;量級
我們統一按照剛才覆蓋Dbmodel函數方式,覆蓋dbNme方式來落地數據庫折選;
1 @Override 2 public String dbName() { 3 /* 4 測試情況,假設我們這個表數據量非常大,我們不僅需要拆分表,同時還需要拆分數據庫了 5 */ 6 long hashcode = roleId % 27 % 5; 7 return "db" + hashcode; 8 }
這樣我們能看到寫入數據庫數據,徹底被hash到不同的庫裏面;
才有這樣的形式,分佈式數據一致性算法,保證同一個數據條件能完整的唯一處理條件;

可以看到,如果這樣數據拆分之後,我還是假設一億數據數據,拆分5個庫之後一個庫就是2000萬條數據;
每個庫拆分10個表,一個表的數據立馬就變成一張表數據量200萬條數據;
註解四—–查詢
我們分庫分表之後怎麼去查詢呢?
同樣的道理,我們既然數據拆分是roleid進行的,那麼我們拆分的,那麼我們查詢肯定也是以這個roleid查找為方向;
把roleid查詢按照剛才的拆分方式,獲取dbname,和tablename,就能進行查詢處理;

