7 papers | NeurIPS 2019獲獎論文揭曉;OpenAI刀塔2論文公布
- 2019 年 12 月 23 日
- 筆記
本周既有 NeurIPS 2019 公布的傑出論文獎和經典論文獎論文,也有 MIT 聯合 IBM 推出的使圖像識別 SOTA 模型性能下降 40 多個點的 ObjectNet 數據集以及 OpenAI 擊敗 OG 戰隊的 Dota 2 智能體論文。
目錄:
- Distribution-Independent PAC Learning of Halfspaces with Massart Noise
- Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization
- Reinforcement Learning Upside Down: Don't Predict Rewards — Just Map Them to Actions
- ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
- Dynamic Convolution: Attention over Convolution Kernels
- Dota 2 with Large Scale Deep Reinforcement Learning
- Point-Voxel CNN for Efficient 3D Deep Learning
論文 1:Distribution-Independent PAC Learning of Halfspaces with Massart Noise
- 作者:Ilias Diakonikolas、Themis Gouleakis、Christos Tzamos
- 論文鏈接:https://papers.nips.cc/paper/8722-distribution-independent-pac-learning-of-halfspaces-with-massart-noise
摘要:本文作者研究了分佈獨立的半空間(half-space)下的 PAC 學習問題(在 Massart 噪聲下)。具體而言,給定一組帶標籤樣本(x, y),採樣於 R^d+1 維的分佈 D,如此以來,未帶標籤點 x 上的邊緣分佈是任意的,並且標籤 y 通過一個未知半空間生成,而這個未知半空間被 Massart 噪聲破壞,其中噪聲率η<1/2。現在我們的目的是找出假設 h,它能夠最小化誤分類誤差(misclassification error)

。對於這個問題,作者提出了誤分類誤差為η+ε的 poly (d, 1/ε) 時間算法。此外,他們還提供了證據證明其算法的誤差保證(error guarantee)在計算上可能很難實現。作者表示,在他們的研究之前,即使是針對析取類(class of disjunction)而言,在這個模型中也沒有出現高效的弱(獨立分佈)學習器。這種針對半空間(或甚至於析取而言)的算法在各項研究中一直是懸而未決的問題,從 Solan(1988)、Cohen(1997)到最近的 Avrim Blum 的 FOCS 2003 教程都強調了這一問題。

主要算法 1(with margin)。

主要算法 2(general case)。
推薦:這篇論文榮獲了NeurIPS 2019傑出論文獎,研究了線性閾方程(linear threshold function)在二分類的,有着未知的、有邊界標籤噪聲訓練數據的情況。它解決了一個非常基礎且長期開放的問題,並提出了一個高效的算法用於學習。這是機器學習核心領域的長期開放的問題,而這篇論文做出了巨大的貢獻。其貢獻在於:在 Massart 噪聲下高效地學習半空間(half-space)。
論文 2:Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization
- 作者:Lin Xiao
- 論文鏈接:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/xiao10JMLR.pdf
摘要:經典論文獎的授予原則為「重要貢獻、持久影響和廣泛吸引力」,本屆大會從 2009 年 NIPS 的 18 篇引用最多的論文中選出了持續影響力最高、對研究領域具有傑出貢獻的研究。最終,今年的這一獎項授予 NIPS 2009 論文《Dual Averaging Method for Regularized Stochastic Learning and Online Optimization》及其作者,微軟首席研究員 Lin Xiao。

推薦:Lin Xiao 曾就讀於北京航空航天大學和斯坦福大學,自 2006 年起就職於微軟研究院。
論文 3:Reinforcement Learning Upside Down: Don't Predict Rewards — Just Map Them to Actions
- 作者:Juergen Schmidhuber
- 論文鏈接:https://arxiv.org/abs/1912.02875
摘要:在本文中,通過將傳統 RL 顛倒過來,稱之為 Upside Down RL(UDRL),作者將強化學習(RL)轉換成了一種監督式學習(supervised learning,SL)。標準 RL 預測獎勵(reward),而 UDRL 將獎勵作為任務定義輸入(task-defining input)、時間範圍表示以及歷史和預期未來數據的其他可計算函數。UDRL 學習將這些輸入觀察作為命令進行解讀,並通過過去經驗上的 SL 將它們映射到行動(或行動概率)上。通過「get lots of reward within at most so much time!」等命令,UDRL 可以泛化以實現高獎勵或其他目標。此外,作者還提出了一種簡單但通用的方法來教機械人模擬人類動作。首先錄下模擬機械人當前行為的人類,然後讓機械人通過 SL 學習將視頻(作為輸入命令)映射到這些行為中,最後令機械人泛化和模擬人類執行先前位置行為的視頻。這種模擬-模擬器(Imitate-Imitator)概念或許可以真正地解釋為什麼生物進化導致了父母模擬子女的咿呀語(babbling)行為。

算法 A1。

算法 A2。

算法框架:模擬-模擬器(Imitate-Imitator)。
推薦:Juergen 新作表示強化學習不需要設置獎勵。
論文 4:ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
- 作者:Andrei Barbu、David Mayo、Julian Alverio、Julian Alverio 等
- 論文鏈接:https://objectnet.dev/objectnet-a-large-scale-bias-controlled-dataset-for-pushing-the-limits-of-object-recognition-models.pdf
- 項目地址:https://objectnet.dev/
摘要:圖像識別是計算機視覺中最為成熟的領域了。從 ImageNet 開始,歷年都會出現各種各樣的新模型,如 AlexNet、YOLO 家族、到後面的 EfficientNet 等。這些模型都在刷新着各種圖像識別領域的榜單,創造更令人驚訝的表現。而近日,MIT 和 IBM 的研究者發現,在他們建立的一個名為 ObjectNet 的數據集上,即使是現在的 SOTA 模型都會「吃癟」。這一新的數據集能夠讓模型的性能下降了 40 多個點。最終,研究者們公開了這個數據集,並鼓勵人們開發更好的模型來解決問題。這一數據集相關的論文已經被 NeurlPS 2019 大會接收為 Poster 論文,讀者們可以參考這個有趣的研究,看看自己的圖像識別模型性能如何。

ImageNet 圖像(左側)和 ObjectNet 圖像的對比。可以看出 ObjectNet 圖像中的目標有各種奇怪的語義。

在 ImageNet 上訓練,並在 ImageNet 測試集或 ObjectNet 做驗證的結果,很明顯,不同的網絡的性能都會大幅降低。

ResNet-152 在 ImageNet 上做預訓練,並在 ObjectNet – 113 做測試的結果。
推薦:近日,MIT 聯合 IBM 研究團隊提出了一個數據集,在它上面測試的圖像識別 SOTA 模型的性能下降了 40 多個點。
論文 5:Dynamic Convolution: Attention over Convolution Kernels
- 作者:Yinpeng Chen、Xiyang Dai、Mengchen Liu、Dongdong Chen、Lu Yuan、Zicheng Liu
- 論文鏈接:https://arxiv.org/pdf/1912.03458.pdf
摘要:輕量級卷積神經網絡(light-weight convolutional neural network)因其較低的計算預算而限制了 CNN 的深度(卷積層數)和寬度(通道數)而導致性能下降,表示能力也會受到限制。為了解決這個問題,在本文中,微軟的研究者們提出了動態卷積,這種新的設計可以在不增加網絡深度或寬度的情況下增加模型複雜度(model complexity)。動態卷積沒有在每層上使用單個卷積核,而是根據注意力動態地聚合多個並行卷積核,這些卷積核依賴於輸入。得益於小的內核尺寸,集合多個內核不僅在計算上很高效,而且由於這些內核通過注意力以非線性方式進行聚合,因此具有更強的表示能力。通過在 SOTA 架構 MobilenetV3-Small 上簡單地使用動態卷積,ImageNet 分類的 top-1 準確度提高了 2.3%,而 FLOP 僅增加了 4%,在 COCO 關鍵點檢測上實現了 2.9 的 AP 增益。

動態卷積層架構。

DY-CNN(動態卷積神經網絡)和 CNN 在 ImageNet 分類上的結果對比。
推薦:與傳統靜態卷積(每層單個卷積核)相比,本文提出的動態卷積顯著提升了表示能力,額外的計算成本也很小,因而對高效的 CNN 更加友好。這種動態卷積還可以容易地整合入現有 CNN 架構中。
論文 6:Dota 2 with Large Scale Deep Reinforcement Learning
- 作者:Christopher Berner、Greg Brockman、Brooke Chan、Brooke Chan 等
- 論文鏈接:https://cdn.openai.com/dota-2.pdf
摘要:要為這樣複雜的環境創造合適的智能體,關鍵是要將現有的強化學習系統擴展至前所未有的規模,這需要在數以千計的 GPU 上執行幾個月的訓練。為了實現這一目標,OpenAI 構建了一個分佈式的訓練系統,訓練出了名為 OpenAI Five 的 Dota 2 遊戲智能體。2019 年 4 月,OpenAI Five 擊敗了一支 Dota 2 世界冠軍戰隊(OG 戰隊),這是首個擊敗電子競技遊戲世界冠軍的 AI 系統。OpenAI 也將該系統開放給了 Dota 2 社區進行對戰試玩;在超過 7000 局遊戲中,OpenAI Five 的勝率為 99.4%。OpenAI 表示,訓練過程還面臨著另外一個難題:遊戲環境和代碼一直在不斷升級和變化。為了避免在每次變化之後再從頭開始訓練,他們開發出了一套工具,能以最低的性能損失繼續完成訓練——OpenAI 將其稱之為「手術(surgery)」。在超過 10 個月的訓練過程中,OpenAI 大約每兩周執行一次手術。這套工具讓 OpenAI 可以經常性地改進他們的智能體,這隻需要很短的時間——比典型的從頭開始訓練方法要短得多。隨着 AI 系統解決的問題越來越大,越來越難,進一步研究不斷變化的環境和迭代開發就顯得至關重要了。

簡化版的 OpenAI Five 模型架構。

系統概況:該訓練系統由 4 種主要類型的機器構成。
推薦:擊敗 OG 戰隊的 Dota 2 智能體究竟是怎樣構建的?OpenAI 公開研究論文。
論文 7:Point-Voxel CNN for Efficient 3D Deep Learning
- 作者:Zhijian Liu、Zhijian Liu、Zhijian Liu、Zhijian Liu
- 論文鏈接:https://arxiv.org/pdf/1907.03739.pdf
摘要:我們發現之前的工作竟需要花 80% 以上的時間進行對數據的不規則訪問以作為卷積運算的準備工作,而實際計算所佔的時間比例卻非常低,這無疑造成了基於點雲的深度學習方法往往比較低效。為解決這樣的問題,我們提出了 Point-Voxel CNN(PVCNN)來實現高效的三維深度學習。PVCNN 利用點雲的形式來存儲數據,以減小內存的消耗,而又選擇柵格化的形式進行卷積,這樣可以避免處理點雲稀疏性所帶來的巨大的非規則數據訪問開銷,很好地提升局部性。這種取長補短的設計使我們的 PVCNN 在內存和計算上都十分高效:我們只用十分之一的內存就可以取得遠高於 volumetric CNN baseline 的準確率,而對比於多個基於點雲直接進行深度學習的方法,我們又可以得到平均 7 倍的實測加速。

在 ShapeNet 數據集上,我們的完整通道數模型可以以 2.7 倍的實測加速達到略好於 PointCNN 的性能,同時我們的內存佔用也減小了 1.6 倍;而即便我們將通道數縮小四倍,我們的模型也可以在達到 PointNet++, DGCNN 等複雜方法性能的同時比 PointNet(此前這個領域中被認為最為精簡、高效的模型)快 1.9 倍、省 1.9 倍內存。
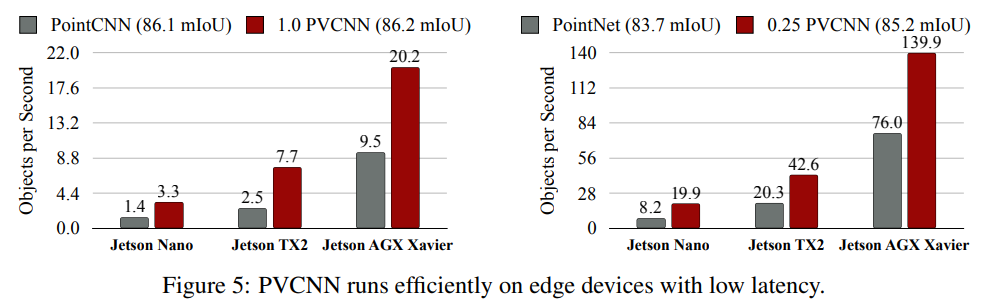
PVCNN 在邊緣設備上以低延遲進行高效地運行。完整的 PVCNN 可以在 NVIDIA Jetson AGX Xaviers 上以每秒 20.2 個物體的速度運行,而四分之一寬度版本的小模型在價格僅 99 美元的 NVIDIA Jetson Nano 上也可以達到接近每秒 20 個物體的速度。
推薦:隨着三維深度學習越來越成為近期研究的熱點,基於柵格化的數據處理方法也越來越受歡迎。但這種處理方法往往受限於高分辨下巨大的內存和計算開銷,因此麻省理工學院 HAN Lab 的研究者提出利用 Point-Voxel CNN 來實現高效的三維深度學習,同時能夠避免巨大的數據訪問開銷並很好地提升了局部性。該論文已被 NeurIPS 2019 接收為 Spotlight Presentation。


