Redis為什麼那麼快?
數據庫有很多,為什麼Redis能有如此突出的表現呢?一方面,因為它是內存數據庫,所有操作都在內存上完成。另外一方面就要歸功於他的數據結構。高效的數據結構是Redis快速處理的基礎。今天我們就來聊聊了Redis的數據類型以及對應的數據結構。
首先Redis有5大基本類型:
1.String(字符串)
2.List(列表)
3.Hash(哈希)
4.Set(集合)
5.Zset(Sorted Set 有序集合)
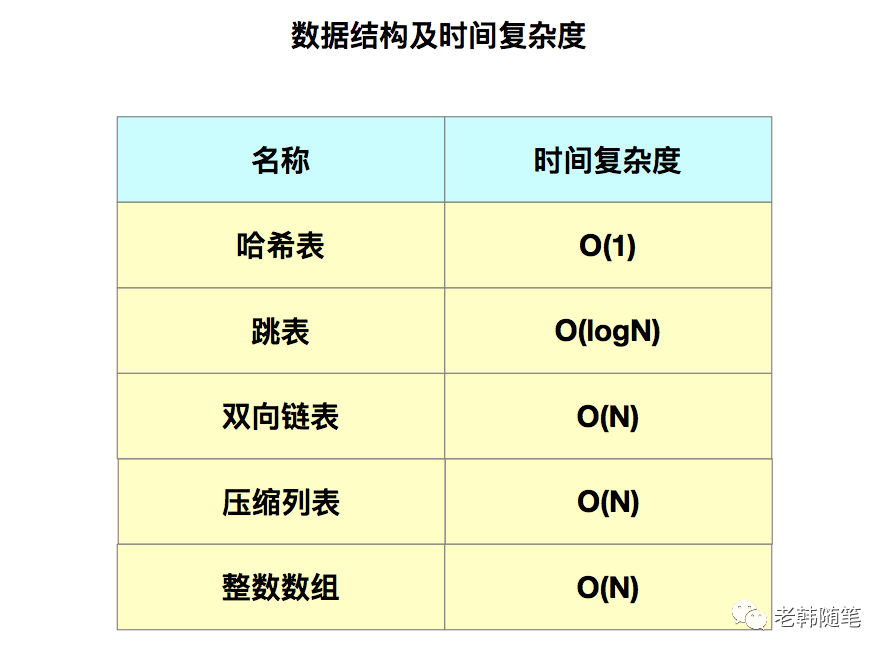
他們的底層實現簡單來說一共有6種,分別是簡單的動態字符串、雙向鏈表、壓縮列表、哈希表、跳錶以及整數數組。他們和數據類型的對應關係如下所示:
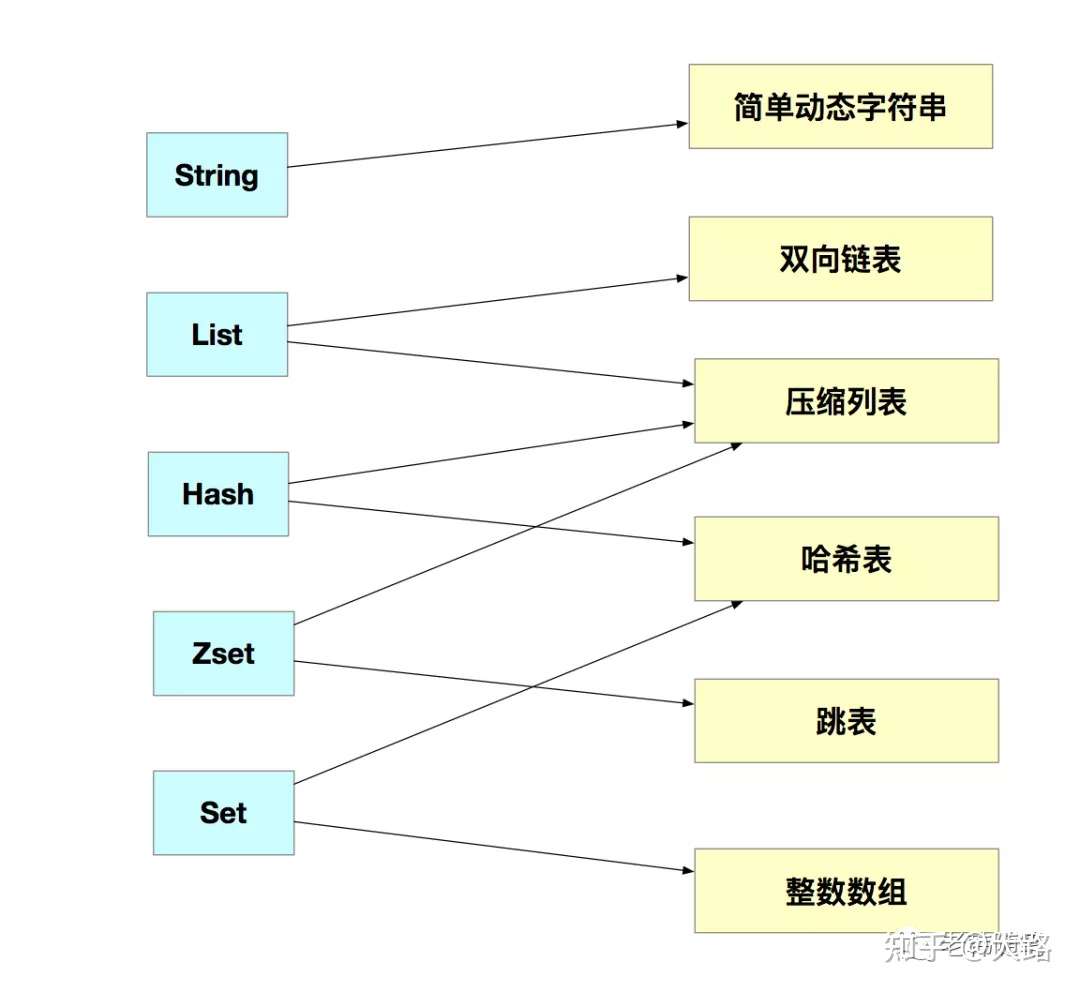
可以看到這些數據結構都是值的底層實現,那鍵和值之間是用什麼數據結構來進行組織的呢?為了實現從鍵到值的快速訪問,Redis使用了一個哈希表來保存所有的鍵值對。
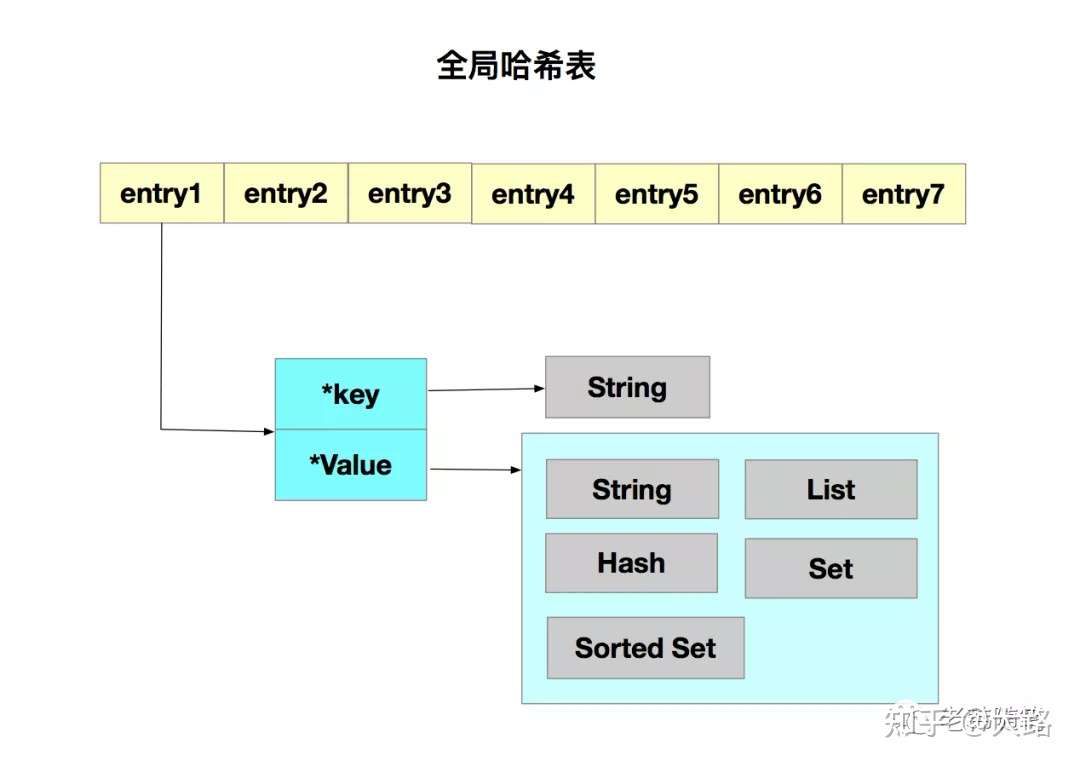
哈希表的最大好處很明顯,就是可以以O(1)的時間複雜度來快速查找到鍵值對。但他有一個潛在的風險點,當你往Redis里寫入大量的數據就會出現哈希表的衝突問題以及rehash帶來的操作阻塞問題。
Redis解決哈希衝突的方式,就是鏈式哈希。鏈式哈希很容易理解,就是指同一個hash桶中的多個元素用一個鏈表來保存。如下圖所示:
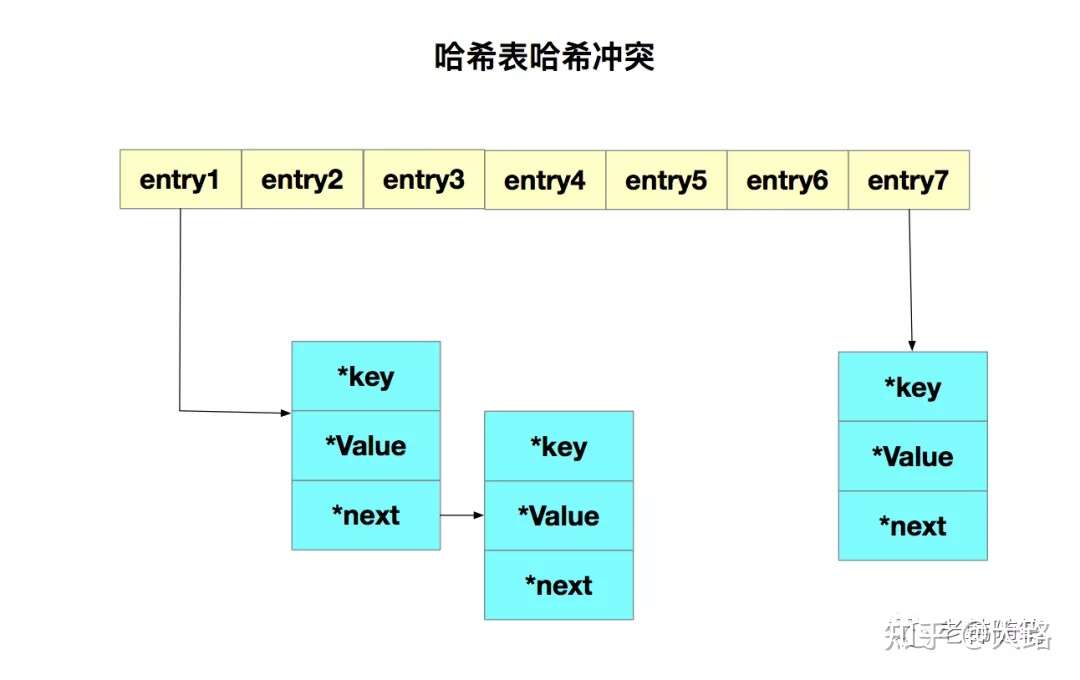
這就出現一個問題,哈希衝突鏈表上的元素只能通過指針逐一查找再操作。如果哈希表裡寫入的數據越來越多,哈希衝突也會越來越多,這就會導致某些哈希衝突鏈過長,進而導致鏈上的元素查找耗時長,效率低。這對求快的redis來說是不能接受的。
所以Redis會對哈希表做rehash操作。rehash也就是增加現有的哈希桶的數量,讓逐漸增多的entry元素能在更多的桶之間分散保存,減少單個桶中的元素個數,從而減少衝突。
為了使rehash更高效,Redis默認使用2個全局哈希表:哈希表1和哈希表2。一開始,當你剛插入數據時,默認使用哈希表1,此時哈希表2並沒有分配空間。隨着數據的增多,Redis開始執行Rehash。主要分為以下3步:
- 給哈希表2分配更大的空間。
- 把哈希表1的數據重新映射並拷貝到哈希表2。
- 釋放哈希表1的空間。
到此我們可以從哈希表1切換到哈希表2,用容量更大的哈希表2來保存更多的數據,而原來的哈希表1留做下一次rehash擴容備用。
可以看到第二步會涉及到大量的數據拷貝,如果一次性把哈希表1全部都遷移完,會造成Redis線程阻塞,無法服務其他請求。為了避免這個問題,Redis採用了漸進式的Rehash。簡單來說就是在第二步拷貝數據時,仍然正常處理客戶端的請求,每處理一個請求,從哈希表1的第一個索引位置開始,順帶着將這個索引位置上的所有entries拷貝到哈希表2中;等處理下一個請求時,再順帶拷貝哈希表1的下一個索引位置的entries。這樣就避免了一次性大量的數據拷貝,保證了數據的快速訪問。
目前為止,你已經了解了Redis的鍵和值是怎麼通過哈希表來組織的了,對於String類型來說,找到哈希桶就能直接增刪改查了,所以哈希表O(1)的時間複雜度就是它的複雜度,但是對於集合類型來說,即使找到哈希桶了,還需要在集合中進一步操作。接下來我們就分別聊聊集合類型的底層數據結構和操作複雜度。
我們在上面已經了解到集合類型的底層結構主要有5種:整數數組、雙向鏈表、哈希表、壓縮列表和跳錶。
其中,哈希表的操作特點我們已經學過;整數數組和雙向鏈表也很常見,主要是通過數組下標和鏈表指針逐個訪問元素,操作複雜度是O(N),操作效率比較低。壓縮列表實際上類似於一個數組,和數組不同的是,壓縮列表在表頭有三個字段zlbytes、zltail和zllen,分別表示列表的長度、列表尾的偏移量和列表中元素的個數;壓縮列表在表尾還有一個zlend表示列表結束。在壓縮列表中,如果我們要查找定位第一個元素和最後一個元素,可以通過表頭直接定位,時間複雜度為O(1)。而查找其它元素時,就沒有那麼高效了,只能逐個查詢,時間複雜度為O(N)。

![]()
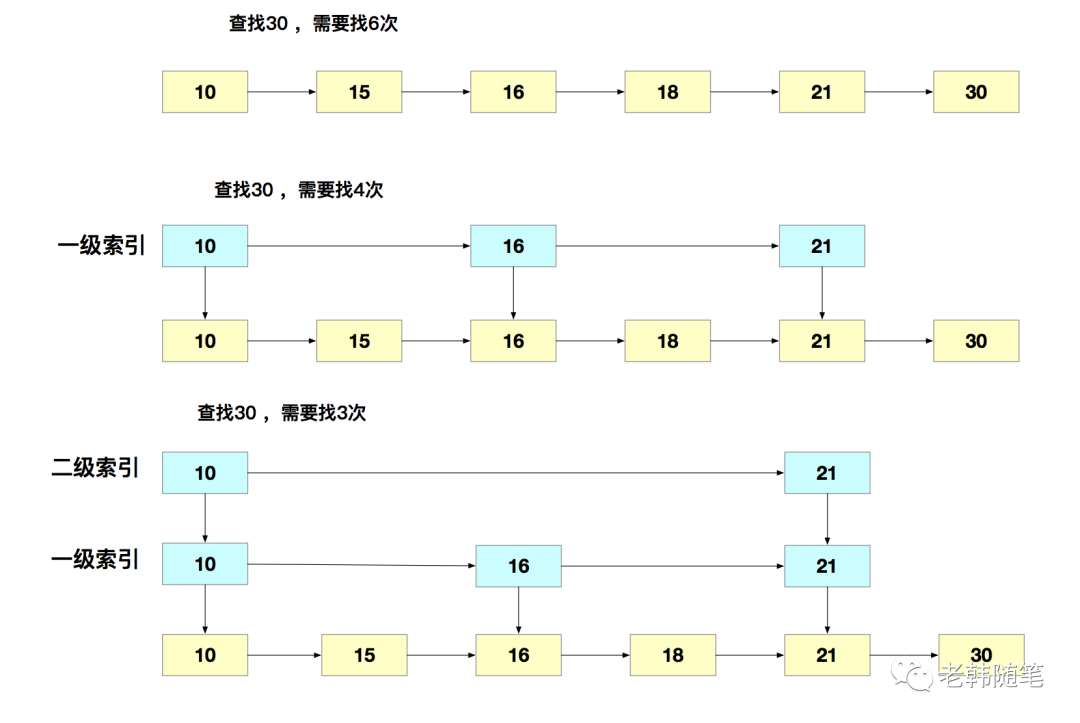
下面我們來重點看一下跳錶。有序鏈表只能逐一查找元素,導致操作起來非常緩慢,於是就出現了跳錶。跳錶是在鏈表的基礎上增加了多級索引,通過索引位置的幾個跳轉,實現數據的快速定位。如圖所示:
![]()
可以看到,這個查找過程就是在多級索引上跳來跳去,最後定位到元素。當數據量很大時,跳錶的查找複雜度是O(logN)。
![]()
好了,今天就分享到這裡,如果有什麼問題,可以在留言區留言。


