Etcd中linearizable read實現
linearizable

有點疑惑,不確定是現在瀏覽的版本沒開發完全,還是沒有按照論文的linearizable來實現。
按照論文所說,在客戶端請求的時候,實際上是一個強一致的 exactly once的過程。
在etcd中,只看到了read的 linearizable ,並且用到的地方是在諸如讀取節點列表,開始事務等操作中。
可以從2個層面來驗證寫與讀一致性
business data which stored in etcd
因為raft只有leader是寫的入口,所以保證數據的順序是可以在leader做處理的。
業務數據的順序,etcd並不能保證順序,因為入口之外的原因太多:
並發,業務方的數據是並發過來的,那麼到達leader的先後性無法保證
業務請求策略,業務數據是並發且被路由到不通的follower,到達leader的先後性也是無法保證的
網絡延遲,那更無法保證絕對的先後性了
所以leader是無法保證業務數據的絕對先後,這是由client或者說使用方來設計的,和數據庫是一樣的道理。
leader能保證的是,進入其內部後數據保存的一致性
所以在業務數據層面,etcd無法保證其先後性,除非提供特殊的協議,事務算半種,要絕對的一致性,得是嵌入或者包裝業務數據的協議。
所以我理解的是,沒有在業務數據層面用寫一致的必要。
application config data of etcd
etcd中實現讀一致的入口全部都是和應用配置相關的,例如節點列表、事務、降級,下圖是使用到的地方
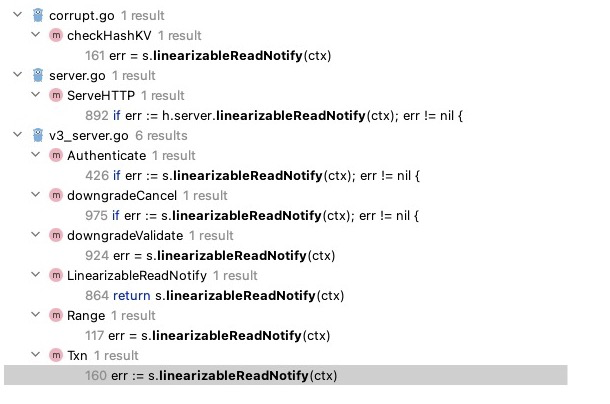
判斷讀一致的邏輯是
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
if isStopped(err) {
return
}
if err != nil {
nr.notify(err)
continue
}
trace.Step("read index received")
trace.AddField(traceutil.Field{Key: "readStateIndex", Value: confirmedIndex})
appliedIndex := s.getAppliedIndex()
trace.AddField(traceutil.Field{Key: "appliedIndex", Value: strconv.FormatUint(appliedIndex, 10)})
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
requestCurrentIndex會返回當前leader正在處理的commitIndex,這裡設計很巧妙,簡單來說是返回commitIndex,然後節點和自己的appiledIndex相比較,直到appliedIndex >= commitIndex ,才算做讀一致完成。
結合讀一致使用的地方以及邏輯這2點,保證的是所有請求時當下leader中在處理的數據在集群內都被處理了,可能後面又變了,例如節點變更了,所以實際上是瞬時一致並且最終一致。
例如txn開啟事務,保證了請求時leader的數據都處理好了,因為leader要處理的數據也包括節點變更的配置數據。
所保證的是臟讀的場景對於單次請求是有效的,即單次請求是不會有臟讀的,但這次請求返回的數據與下次請求返回的數據仍然有可能不一致,所以是最終一致的。
寫一致是否有必要在這裡實現?如果這次的請求要求寫一致,那麼下次請求就要依賴於這次請求的寫一致,這次請求還沒結束,後面的請求全部都要wating,並且無窮級聯下去。所以選擇了最終一致來應對寫一致。這是個典型的base。
結合以上2個層面的分析,寫一致在業務數據層面是由使用方來設計,配置數據層面是由最終一致代替。
讀一致業務數據層面也是由使用方來設計,配置數據層面保證當次請求的讀取沒有臟數據,也由最終一致代替。
Raft log replication flow
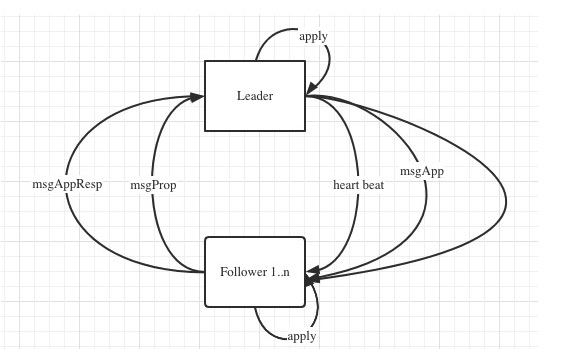
還是得放上這張圖,因為整個通訊過程仍然是遵照raft消息的方式,只不過這裡用的消息類型是 MsgReadIndex,同proposal的區別是沒有commit的過程,僅僅是將MsgReadIndex消息發送給leader,leader會回復ReadIndexResp。
Logic flow
Trigger linearizable read
讀一致的入口在上面已列舉,此處隨意找一個
func (s *EtcdServer) Txn(ctx context.Context, r *pb.TxnRequest) (*pb.TxnResponse, error) {
if isTxnReadonly(r) {
trace := traceutil.New("transaction",
s.Logger(),
traceutil.Field{Key: "read_only", Value: true},
)
ctx = context.WithValue(ctx, traceutil.TraceKey, trace)
if !isTxnSerializable(r) {
err := s.linearizableReadNotify(ctx)
trace.Step("agreement among raft nodes before linearized reading")
if err != nil {
return nil, err
}
}
s.linearizableReadNotify(ctx),等待讀一致處理完成
開始讀一致的邏輯
func (s *EtcdServer) linearizableReadNotify(ctx context.Context) error {
s.readMu.RLock()
nc := s.readNotifier
s.readMu.RUnlock()
// signal linearizable loop for current notify if it hasn't been already
select {
case s.readwaitc <- struct{}{}:
default:
}
// wait for read state notification
select {
case <-nc.c:
return nc.err
case <-ctx.Done():
return ctx.Err()
case <-s.done:
return ErrStopped
}
}
這是與 linearizableReadLoop 相互通訊的膠水函數
s.readwaitc 觸發linearizableReadLoop邏輯開始查詢readindex
s.readNotifier 返回信號表明讀一致處理完成
Read loop on server starting
在server 啟動時,會啟動讀一致的自旋,即上面處理讀一致的邏輯
func (s *EtcdServer) linearizableReadLoop() {
for {
requestId := s.reqIDGen.Next()
leaderChangedNotifier := s.LeaderChangedNotify()
select {
case <-leaderChangedNotifier:
continue
case <-s.readwaitc:
case <-s.stopping:
return
}
// as a single loop is can unlock multiple reads, it is not very useful
// to propagate the trace from Txn or Range.
trace := traceutil.New("linearizableReadLoop", s.Logger())
nextnr := newNotifier()
s.readMu.Lock()
nr := s.readNotifier
s.readNotifier = nextnr
s.readMu.Unlock()
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
if isStopped(err) {
return
}
if err != nil {
nr.notify(err)
continue
}
trace.Step("read index received")
trace.AddField(traceutil.Field{Key: "readStateIndex", Value: confirmedIndex})
appliedIndex := s.getAppliedIndex()
trace.AddField(traceutil.Field{Key: "appliedIndex", Value: strconv.FormatUint(appliedIndex, 10)})
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
trace.Step("applied index is now lower than readState.Index")
trace.LogAllStepsIfLong(traceThreshold)
}
}
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
requestId每次都會生成,目的是區分每一次的讀,因為raft在自旋,讀取的操作也可能是並發,所以需要有唯一區分的identity
s.readwaitc,server中專門為讀一致創建的channel,生成完requestId後,會block在這裡,等待signal來觸發讀一致的後續邏輯
s.readNotifier 讀一致通知的channel,appliedIndex >= confirmedIndex 時,通過這個channel通知調用者,讀一致的邏輯已經完成
Request of read current index
func (s *EtcdServer) requestCurrentIndex(leaderChangedNotifier <-chan struct{}, requestId uint64) (uint64, error) {
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
lg := s.Logger()
errorTimer := time.NewTimer(s.Cfg.ReqTimeout())
defer errorTimer.Stop()
retryTimer := time.NewTimer(readIndexRetryTime)
defer retryTimer.Stop()
firstCommitInTermNotifier := s.FirstCommitInTermNotify()
for {
select {
case rs := <-s.r.readStateC:
requestIdBytes := uint64ToBigEndianBytes(requestId)
gotOwnResponse := bytes.Equal(rs.RequestCtx, requestIdBytes)
if !gotOwnResponse {
// a previous request might time out. now we should ignore the response of it and
// continue waiting for the response of the current requests.
responseId := uint64(0)
if len(rs.RequestCtx) == 8 {
responseId = binary.BigEndian.Uint64(rs.RequestCtx)
}
lg.Warn(
"ignored out-of-date read index response; local node read indexes queueing up and waiting to be in sync with leader",
zap.Uint64("sent-request-id", requestId),
zap.Uint64("received-request-id", responseId),
)
slowReadIndex.Inc()
continue
}
return rs.Index, nil
case <-leaderChangedNotifier:
readIndexFailed.Inc()
// return a retryable error.
return 0, ErrLeaderChanged
case <-firstCommitInTermNotifier:
firstCommitInTermNotifier = s.FirstCommitInTermNotify()
lg.Info("first commit in current term: resending ReadIndex request")
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
retryTimer.Reset(readIndexRetryTime)
continue
case <-retryTimer.C:
lg.Warn(
"waiting for ReadIndex response took too long, retrying",
zap.Uint64("sent-request-id", requestId),
zap.Duration("retry-timeout", readIndexRetryTime),
)
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
retryTimer.Reset(readIndexRetryTime)
continue
case <-errorTimer.C:
lg.Warn(
"timed out waiting for read index response (local node might have slow network)",
zap.Duration("timeout", s.Cfg.ReqTimeout()),
)
slowReadIndex.Inc()
return 0, ErrTimeout
case <-s.stopping:
return 0, ErrStopped
}
}
}
s.sendReadIndex(requestId),包裹requestId,將消息向raft模塊傳遞
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
會將消息下放到raft模塊中stepFunc來處理
如果是follower,會發送至leader
case pb.MsgReadIndex:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping index reading msg", r.id, r.Term)
return nil
}
m.To = r.lead
r.send(m)
如果是leader
case pb.MsgReadIndex:
// only one voting member (the leader) in the cluster
if r.prs.IsSingleton() {
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
return nil
}
// Postpone read only request when this leader has not committed
// any log entry at its term.
if !r.committedEntryInCurrentTerm() {
r.pendingReadIndexMessages = append(r.pendingReadIndexMessages, m)
return nil
}
sendMsgReadIndexResponse(r, m)
return nil
sendMsgReadIndexResponse(r, m) 回復read index給請求者
func sendMsgReadIndexResponse(r *raft, m pb.Message) {
// thinking: use an internally defined context instead of the user given context.
// We can express this in terms of the term and index instead of a user-supplied value.
// This would allow multiple reads to piggyback on the same message.
switch r.readOnly.option {
// If more than the local vote is needed, go through a full broadcast.
case ReadOnlySafe:
r.readOnly.addRequest(r.raftLog.committed, m)
// The local node automatically acks the request.
r.readOnly.recvAck(r.id, m.Entries[0].Data)
r.bcastHeartbeatWithCtx(m.Entries[0].Data)
case ReadOnlyLeaseBased:
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
}
}
可以得知,不論哪種情況,leader都會將 commited index 作為read index 回復給請求者
func (r *raft) responseToReadIndexReq(req pb.Message, readIndex uint64) pb.Message {
if req.From == None || req.From == r.id {
r.readStates = append(r.readStates, ReadState{
Index: readIndex,
RequestCtx: req.Entries[0].Data,
})
return pb.Message{}
}
return pb.Message{
Type: pb.MsgReadIndexResp,
To: req.From,
Index: readIndex,
Entries: req.Entries,
}
}
Response of read current index
當follower接收到 MsgReadIndexResp後
case pb.MsgReadIndexResp:
if len(m.Entries) != 1 {
r.logger.Errorf("%x invalid format of MsgReadIndexResp from %x, entries count: %d", r.id, m.From, len(m.Entries))
return nil
}
r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data})
RequestCtx: m.Entries[0].Data} 這裡放的就是 requestId
回到 request current index
for {
select {
case rs := <-s.r.readStateC:
requestIdBytes := uint64ToBigEndianBytes(requestId)
gotOwnResponse := bytes.Equal(rs.RequestCtx, requestIdBytes)
if !gotOwnResponse {
// a previous request might time out. now we should ignore the response of it and
// continue waiting for the response of the current requests.
responseId := uint64(0)
if len(rs.RequestCtx) == 8 {
responseId = binary.BigEndian.Uint64(rs.RequestCtx)
}
lg.Warn(
"ignored out-of-date read index response; local node read indexes queueing up and waiting to be in sync with leader",
zap.Uint64("sent-request-id", requestId),
zap.Uint64("received-request-id", responseId),
)
slowReadIndex.Inc()
continue
}
return rs.Index, nil
s.r.readStateC 是在 raft Ready裏面傳過來的
if len(rd.ReadStates) != 0 {
select {
case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]:
case <-time.After(internalTimeout):
r.lg.Warn("timed out sending read state", zap.Duration("timeout", internalTimeout))
case <-r.stopped:
return
}
}
因為 read current index中的for循環,直到 requestId相等,返回readIndex至 linearizableReadLoop
再回到 linearizableReadLoop
for {
requestId := s.reqIDGen.Next()
leaderChangedNotifier := s.LeaderChangedNotify()
select {
case <-leaderChangedNotifier:
continue
case <-s.readwaitc:
case <-s.stopping:
return
}
//省略若干
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
}
s.applyWait.Wait(confirmedIndex)
leader雖然返回了read index,但還沒有在本節點apply,一定要apply之後才會通知讀一致完成
因為apply 才會存儲,如果沒有存儲,如果集群出現宕機,仍然會有臟讀的可能。
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
通知讀一致處理完成。
Summary
從follower讀取leader當前的commited index,follower接收到後,直到apply完成,這幾個步驟構成了避免的臟讀的過程。
所以返回的數據是當前時間點內部一致的。


